
启动停止命令
启动服务
cd /data/soft/hadoop/sbin
hadoop-daemon.sh start journalnode
./start-all.sh
mapred --daemon start historyserver
yarn--daemon start timelineserver
停止服务
cd /data/soft/hadoop/sbin
hadoop-daemon.sh stop journalnode
./stop-all.sh
mapred --daemon stop historyserver
yarn--daemon stop timelineserver
HA 概述
HA 即高可用,在 Hadoop 中,只有 NN 和 MR 会出现单点故障。所以只需要对 NN 和 MR 做 HA
HA 原理就是额外起一台机子作冗余备份,当主机挂了,就让备机顶上。按照该想法会存在以下问题:
- 主备间如何同步 Edit?
- 如何检测主机下线?
- 如何做故障转移?
对于问题一:Hadoop 引入 JournalNode 解决
对于问题二:使用 ZK 来检测机器状态变化
对于问题三:Hadoop 引入 DFSZKFailoverController 解决
引入新的部件,为了防止这些也是是单点的,所以也得给他们起多个
集群规划
按照以上分析,便有以下集群规划
node01node02node03NameNodeNameNodeNameNodeDFSZKFailoverControllerDFSZKFailoverControllerDFSZKFailoverControllerJournalNodeJournalNodeJournalNodeDataNodeDataNodeDataNodeZKZKZKResourceManagerResourceManagerResourceManagerNodeManagerNodeManagerNodeManager
ZK 集群搭建
参考
ZooKeeper集群安装
Hadoop安装
Hadoop下载地址:
:::info
- https://hadoop.apache.org/releases.html
- https://archive.apache.org/dist/hadoop/common/(历史版本) ::: 将hadoop安装包"hadoop-3.4.0.tar.gz",拷贝到CentOS中将Hadoop压缩包,解压缩到安装目录下 :
tar-zxvf /data/soft/hadoop-3.3.6.tar.gz
mv hadoop-3.3.6 hadoop
chown-R root:root ./hadoop
打开"/etc/profile"配置文件,配置hadoop环境变量(注意,标点符号全都要是英文半角):
exportHADOOP_HOME=/data/soft/hadoop
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
exportHADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
exportHADOOP_CLASSPATH=`hadoop classpath`#export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
执行"/etc/profile",让配置生效:
source /etc/profile
测试hadoop安装:
hadoop version
修改配置
hadoop-env.sh
修改hadoop-env.sh文件,设置运行环境变量及运行用户
exportJAVA_HOME=/data/soft/sdkman/candidates/java/current
exportHDFS_NAMENODE_USER=root
exportHDFS_DATANODE_USER=root
exportHDFS_SECONDARYNAMENODE_USER=root
exportYARN_RESOURCEMANAGER_USER=root
exportYARN_NODEMANAGER_USER=root
exportHDFS_JOURNALNODE_USER=root
exportHDFS_ZKFC_USER=root
core-site.xml
注意:
HA集群名称要和hdfs-site.xml中的配置保持一致
修改存储路径
Zookeeper集群的地址和端口
<configuration><!-- HA集群名称,自定义,该值要和hdfs-site.xml中的配置保持一致 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- 指定hadoop运行时产生文件的存储路径 --><property><name>hadoop.tmp.dir</name><value>/data/apps/hadoop</value></property><!-- 设置HDFS web UI访问用户 --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><!-- ZooKeeper集群的地址和端口--><property><name>ha.zookeeper.quorum</name><value>master:2181,slave1:2181,slave2:2181</value></property><!-- 配置该root允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><!-- 配置该root允许代理的用户所属组 --><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property><!-- 配置该root允许代理的用户 --><property><name>hadoop.proxyuser.root.users</name><value>*</value></property></configuration>
hdfs-site.xml
注意:
检查节点之间是否可以免密登录
集群名称和core-site中保持一致
集群相关节点及属性name cluster名称记得替换
<configuration><!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- NameNode 数据存储目录 --><property><name>dfs.namenode.name.dir</name><value>file://${hadoop.tmp.dir}/name</value></property><!-- DataNode 数据存储目录 --><property><name>dfs.datanode.data.dir</name><value>file://${hadoop.tmp.dir}/data</value></property><!-- JournalNode 数据存储目录 --><property><name>dfs.journalnode.edits.dir</name><value>${hadoop.tmp.dir}/jn</value></property><!-- mycluster下面有3个NameNode,分别是nn1,nn2,nn3 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2,nn3</value></property><!-- nn1的RPC通信地址, http通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>master:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>master:9870</value></property><!-- nn2的RPC通信地址, http通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>slave1:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>slave1:9870</value></property><!-- nn3的RPC通信地址, http通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn3</name><value>slave2:8020</value></property><property><name>dfs.namenode.http-address.mycluster.nn3</name><value>slave2:9870</value></property><!-- 指定NameNode的edits元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 指定该集群出故障时,哪个实现类负责执行故障切换 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 避免脑裂,配置隔离机制方法,即同一时刻只能有一台服务器对外响应--><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用sshfence隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property></configuration>
mapred-site.xml
<configuration><!-- 指定mr框架为yarn方式 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><!-- 历史服务器端地址 --><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><!-- 历史服务器 web 端地址 --><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property></configuration>
yarn-site.xml
<configuration><!-- 开启RM高可用 --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定RM的cluster id --><property><name>yarn.resourcemanager.cluster-id</name><value>yrc</value></property><!-- 指定RM的名字 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2,rm3</value></property><!-- 分别指定RM的地址 --><!-- 指定 rm1 的主机名, web 端地址, 内部通信地址, 申请资源地址, NM 连接的地址 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>master</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>master:8088</value></property><property><name>yarn.resourcemanager.address.rm1</name><value>master:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm1</name><value>master:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm1</name><value>maste:8031</value></property><!-- 指定 rm2 配置, web 端地址, 内部通信地址, 申请资源地址, NM 连接的地址 --><property><name>yarn.resourcemanager.hostname.rm2</name><value>slave1</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>slave1:8088</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>slave1:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>slave1:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm2</name><value>slave1:8031</value></property><!-- 指定 rm3 配置, web 端地址, 内部通信地址, 申请资源地址, NM 连接的地址 --><property><name>yarn.resourcemanager.hostname.rm3</name><value>slave2</value></property><property><name>yarn.resourcemanager.webapp.address.rm3</name><value>slave2:8088</value></property><property><name>yarn.resourcemanager.address.rm3</name><value>slave2:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm3</name><value>slave2:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm3</name><value>slave2:8031</value></property><!-- 指定 zookeeper 集群的地址 --><property><name>yarn.resourcemanager.zk-address</name><value>master:2181,slave1:2181,slave2:2181</value></property><!-- 启用自动恢复 --><property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 --><property><name>yarn.resourcemanager.store.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- YARN 节点管理器将使用 MapReduce Shuffle 作为其辅助服务 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
修改workers
master
slave1
slave2
同步配置到节点
scp -r /data/soft/hadoop root@slave1:/data/soft
scp -r /data/soft/hadoop root@slave2:/data/soft
启动集群
启动Zookeeper
启动集群各个节点的Zookeeper服务
cd /data/soft/zookeeper/bin
./zkServer.sh start
./zkServer.sh status
启动JournalNode
启动集群每个节点监控NameNode的管理日志的JournalNode
cd /data/soft/hadoop/sbin
hdfs --daemon start journalnode
[root@master sbin]# jps33816 Jps
33785 JournalNode
4506 QuorumPeerMain
注意:
启动后需要等待全部的子节点进程全部启动完成,否则格式化目录报错
格式化目录
格式化HDFS(仅需执行格式化一次),在master节点的终端窗口中,执行下面的命令:
hdfs namenode -format
成功示例
注:如果因为某些原因需要从头重新配置集群,那么在重新格式化HDFS之前,先把各节点Haoop下的dfs目录删除。 这个目录是在hdfs-site.xml文件中自己指定的,其下有两个子目录name和data,重新格式化之前必须删除它们
启动进程,同步元数据信息
在master节点的启动namenode
hdfs --daemon start namenode
在slave1和slave2上,同步master节点的元数据信息
hdfs namenode -bootstrapStandby
启动slave1和slave2的namenode进程
hdfs --daemon start namenode
初始化ZKFC
ZKFC用于监控active namenode节点是否挂掉,通知其它节点上的ZKFC强行杀死自己ZKFC节点上的namenode(防止其假死状态产生集群namenode脑裂的发生),然后选举出其他namenode为active节点。在Master节点执行
hdfs zkfc -formatZK
主节点上启动HDFS和Yarn
start-dfs.sh会自动启动DFSZKFailoverController
start-dfs.sh
start-yarn.sh
手动在standby上手动启动备份的 resourcemanager
yarn-daemon.sh start resourcemanager
HA测试
测试访问web界面
master:9870
slave1:9870
slave:9870
#yarn集群地址
master:8080/cluster
集群操作是否正常
hdfs dfsadmin -report
hadoop fs -mkdir /test01
hadoop fs -put workers /test01
hadoop fs -ls /test01
验证namenode工作状态
namenode主备之间同时只能有一个主对外提供服务即active可以操作,standby不可以操作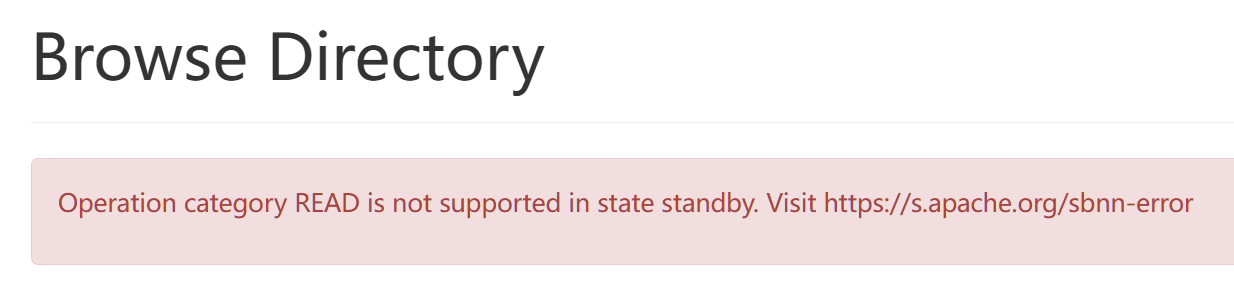
验证namenode故障转移
杀死namenode active节点进程
jps |grep-i namenode
kill50305#重新启动
hdfs --daemon start namenode
当前active节点Slave2无法打开,查看节点2,可以看到节点2切换到active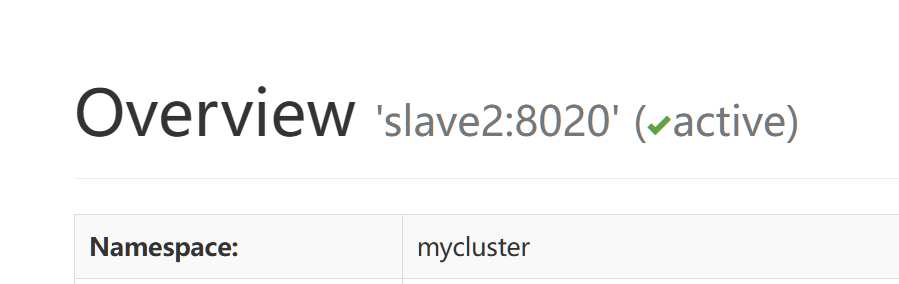
如果未正常切换可以查看节点hadoop-root-zkfc-{node_name}.log日志报错
补充说明
hadoop脚本分析
start-all.sh
- libexec/hadoop-config.sh
- start-dfs.sh
- start-yarn.sh
Hadoop脑裂介绍
https://blog.csdn.net/alphonse_10/article/details/135593142
错误解决
NameNode全部为StandBy状态
:::info
集群配置了自动切换需要配置sshfence隔离机制,所以hdfs-site.xml中配置不能少
:::
集群active节点停止后无法自动切换到standby节点
查看hadoop-root-zkfc-{node_name}.log日志发现:
org.apache.hadoop.ha.SshFenceByTcpPort: Unable to create SSH session
com.jcraft.jsch.JSchException: invalid privatekey: [B@1610a65d
:::info
密钥的时候使用的openssh版本过高导致,其生成的密钥类似如下,而jsch版本低,解析不了高版本的openssh生成的秘钥
:::
版权归原作者 2Casiku 所有, 如有侵权,请联系我们删除。