
Hadoop介绍
Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
狭义上说,Hadoop指Apache这款开源框架,它的核心组件有:
HDFS(分布式文件系统):解决海量数据存储
YARN(作业调度和集群资源管理的框架):解决资源任务调度
MAPREDUCE(分布式运算编程框架):解决海量数据计算
hadoop集群的搭建即为在集群中安装以上的3个组件。
Hadoop优点
1、扩容能力(Scalable)****:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计的节点中。
2、成本低(Economical):Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。
3、高效率(Efficient):通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
4、可靠性(Rellable):能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
服务器集群环境基本配置
1、在VMware上创建3个虚拟机,用以模拟集群环境
- 1 登录并在命令行中输入ifconfig查看IP地址
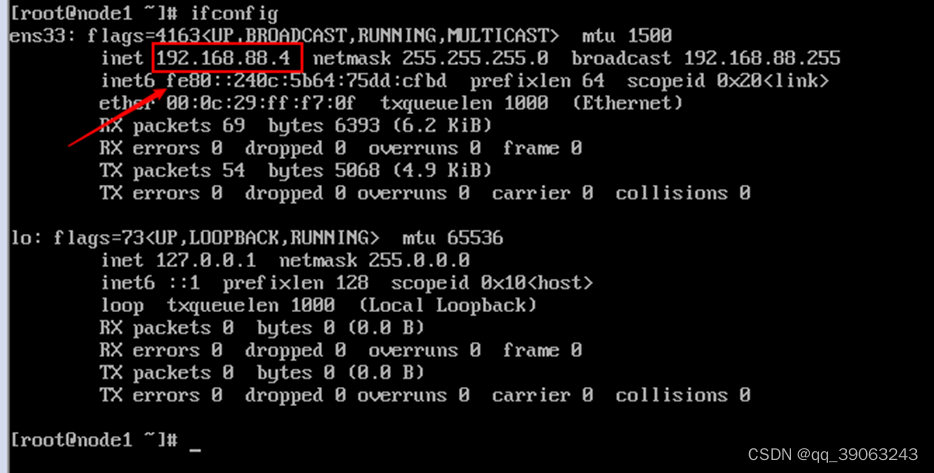
这个ip地址是自动分配的,后边我们需要将ip设置为静态的。
- 2 虚拟机网络配置
编辑虚拟机的网络编辑器
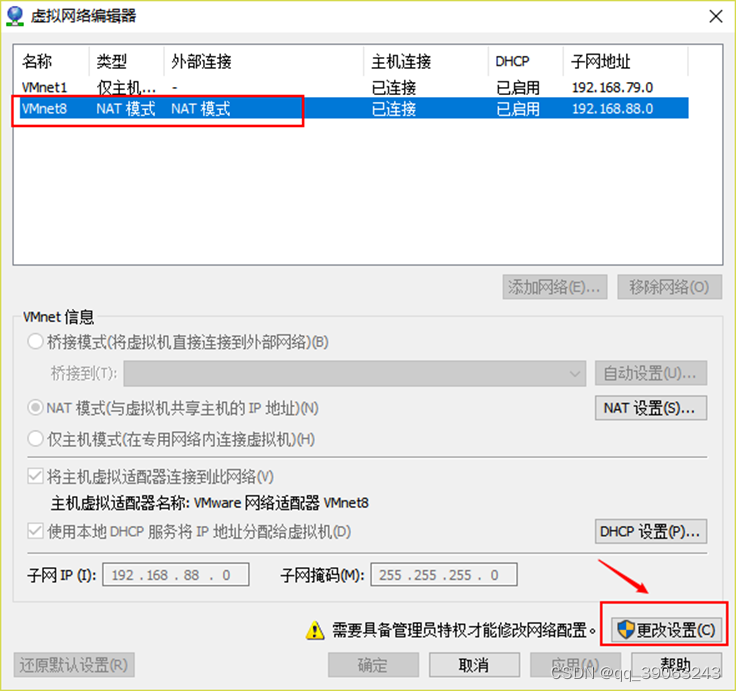
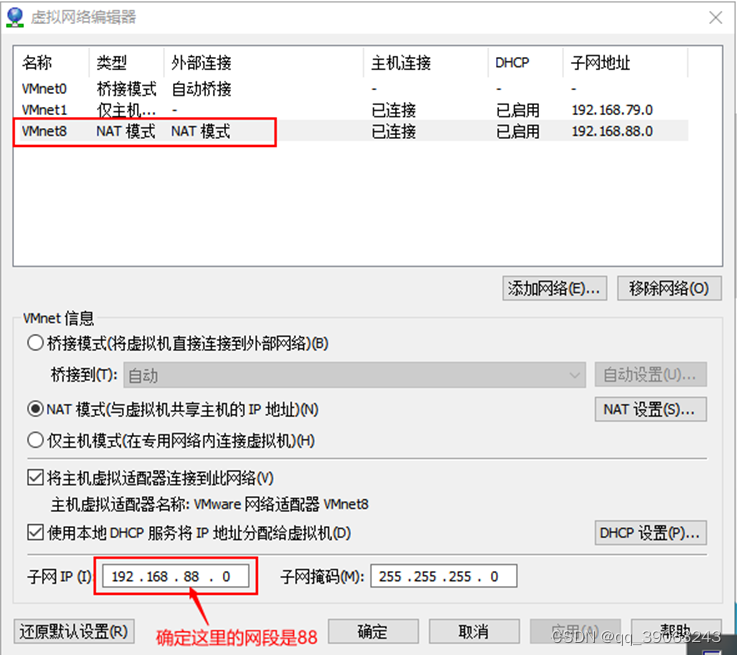
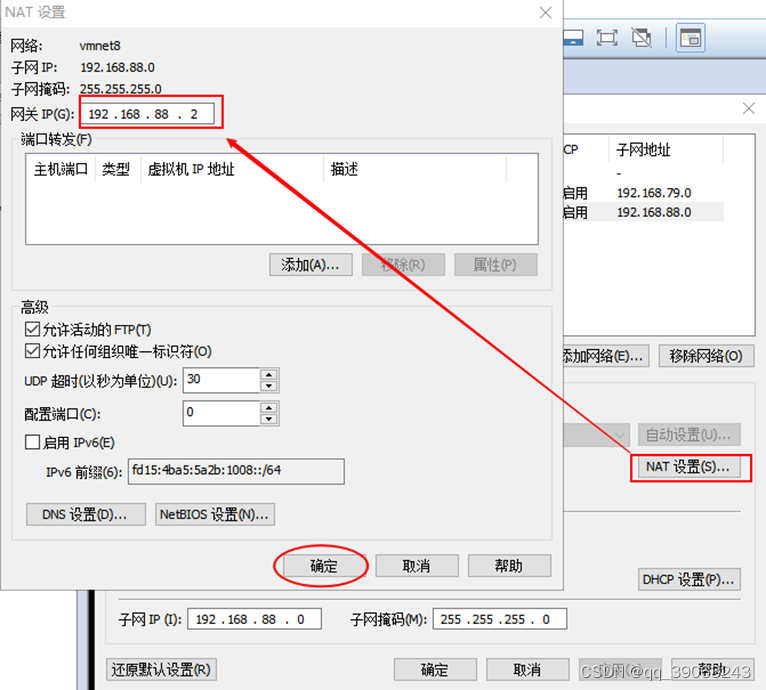
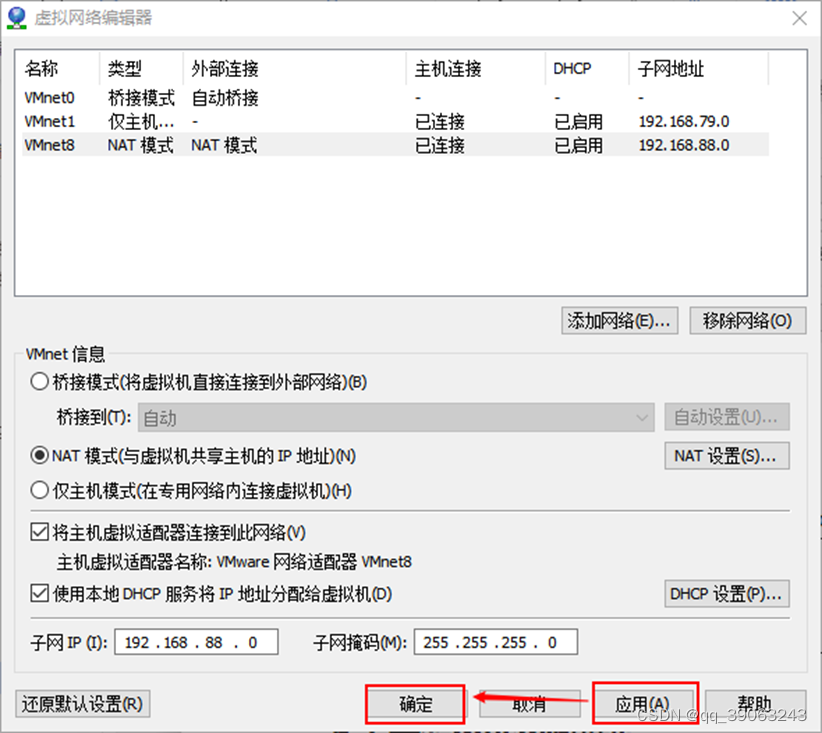
1.3 修改IP地址为静态
编辑修改网卡IP地址的配置文件
vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改以下的红色部分
TYPE**=**"Ethernet"
PROXY_METHOD**=**"none"
BROWSER_ONLY**=**"no"
BOOTPROTO="static"
DEFROUTE**=**"yes"
IPV4_FAILURE_FATAL**=**"no"
IPV6INIT**=**"yes"
IPV6_AUTOCONF**=**"yes"
IPV6_DEFROUTE**=**"yes"
IPV6_FAILURE_FATAL**=**"no"
IPV6_ADDR_GEN_MODE**=**"stable-privacy"
NAME**=**"ens33"
UUID**=**"dfd8991d-799e-46b2-aaf0-ed2c95098d58"
DEVICE**=**"ens33"
ONBOOT**=**"yes"
IPADDR="192.168.88.161"
GATEWAY="192.168.88.2"
NETMASK="255.255.255.0"
DNS1="8.8.8.8"
DNS2="114.114.114.114"
IPV6_PRIVACY="no"
最后使用systemctl restart network重启网络并使用ifconfig查看ip地址是否改变。
- 4 设置主机名和域名映射
配置每台虚拟机主机名,分别编辑每台虚拟机的hostname文件,直接填写主机名,保存退出即可。
vim**/etc/**hostname
第一台主机主机名为:node1
第二台主机主机名为:node2
第三台主机主机名为:node3

配置每台虚拟机域名映射,分别编辑每台虚拟机的hosts文件,在原有内容的基础上,增加以下内容:
注意:不要修改文件原来的内容,三台虚拟机的配置内容都一样。
vim**/etc/**hosts
192.168.88.161 node1
192.168.88.162 node2
192.168.88.163 node3
- 5 关闭三台虚拟机的防火墙和Selinux
关闭每台虚拟机的防火墙,在每台虚拟机上分别执行以下指令:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
关闭之后,查看防火墙状态:
systemctl status firewalld.service
关闭每台虚拟机的Selinux,编辑每台虚拟机的Selinux的配置文件
vim**/etc/selinux/**config
将Selinux工作模式关闭:

- 6 三台机器机器免密码登录
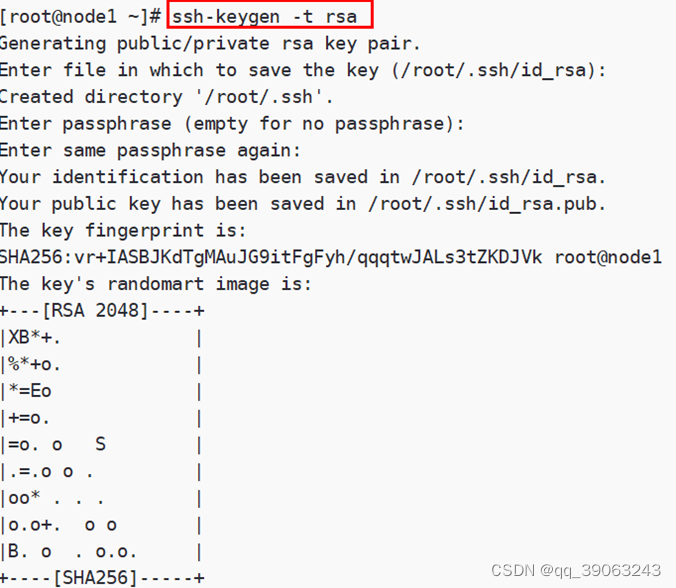
** **第一步:三台机器生成公钥与私钥,在三台机器执行以下命令,生成公钥与私钥。
ssh-keygen -t rsa
执行该命令之后,按下三个回车即可,然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥),默认保存在/root/.ssh目录。
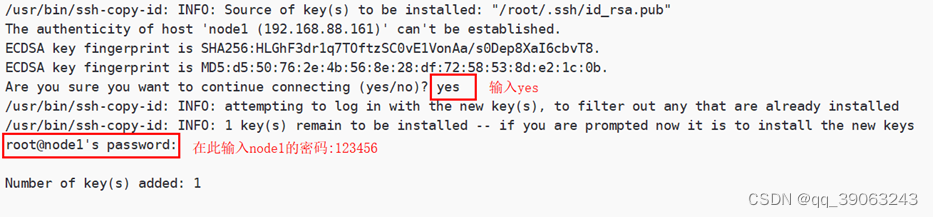
第二步:将三台机器的公钥拷贝到第一台机器,三台机器执行命令:
ssh-copy-id node1
在执行该命令之后,需要输入yes和node1的密码:
第三步**:**复制第一台机器的认证到其他机器,在第一台机器上指行以下命令
scp **/root/.ssh/authorized_keys node2:/root/.**ssh
scp **/root/.ssh/authorized_keys node3:/root/.**ssh
执行命令时,需要输入yes和对方的密码
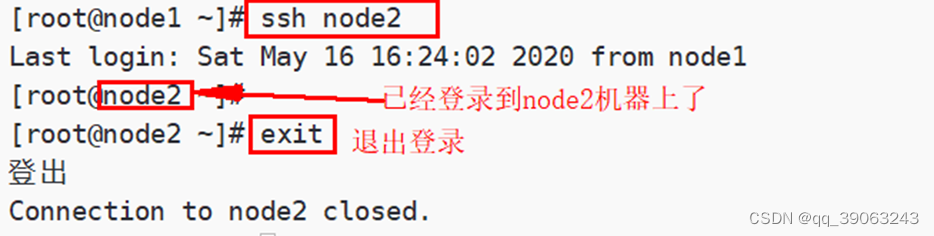
第四步**:测试SSH**免密登录
可以在任何一台主机上通过ssh 主机名命令去远程登录到该主机,输入exit退出登录
例如:在node1机器上,免密登录到node2机器上
ssh node1
exit
执行效果如下:
- 7三台机器时钟同步
通过网络连接外网进行时钟同步,必须保证虚拟机连上外网,启动定时任务。
crontab -e
随后在输入界面键入以下内容,每隔一分钟就去连接阿里云时间同步服务器,进行时钟同步
/1*****************/usr/sbin/ntpdate ntp4.aliyun.com;**
版权归原作者 qq_39063243 所有, 如有侵权,请联系我们删除。