

目录标题
前言
跟着博主从0到1学习K8s! 我行,你也行!
该文章是我的系列专栏的第一篇文,首先一下 Kubernetes ,然后进行pob 的详细讲解。
🐳 Kubernetes到底是什么?
下列介绍部分来自网络,如有侵权,告知删除!谢谢
🐬 K8s 的由来
大家或许听过 K8s,其实他就是 Kubernetes 的简称。那么这个简称是如何得来的呢?他的前世到底是什么?
其实这个简称的由来非常简单,我这种专职摸鱼户非常喜欢这种偷懒的方式,K 就是 Kubernetes 的首字母,s 是 Kubernetes 的末尾字母,数字8则是表明在 K 和 s 之间的字符 ‘ubernete’ 个数为8。所以我们简称其为K8s
🐬K8s 的工作方式
那么K8s为什么会被创造出来呢?
在他诞生之前,传统的应用部署方式是通过插件或脚本来安装应用。但是这种做法不利于应用的升级更新/回滚等操作,虽然我们可以通过虚拟机进行实现某些功能,但是移植性不强。
至此,我们的K8s应运而生!
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
(1) K8s 通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
(2) 容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更“透明”,这更便于监控和管理。
🐬 K8s 主要组件
在K8s的整体框架中,包含Master 组件、Node 组件,Master组件是提供集群的管理控制中心。节点组件运行在Node,提供Kubernetes运行时环境,以及维护Pod。
🐋Master 组件
Master 组件里面都有什么呢?
- kube-apiserver (统一的服务访问入口)
- ETCD (写入集群信息)
- kube-controller-manager
- cloud-controller-manager
- kube-scheduler
- 插件 addons 6.1 DNS (创建域名对应解析) 6.2用户界面 6.3容器资源监测 6.4Cluster-level Logging
🐋Node 组件
Node 组件里面都有什么呢?
- kubelet (直接与容器引擎交互 实现生命周期管理)
- kube-proxy (写入规则 、实现服务映射访问)
- docker
- RKT
- supervisord
- fluentd
至此对于 Kubernetes 的初步认识就告一段落了,接下来我们详细讲解一下 “ pod ”
🐳 pod 是什么?
🐬pod 的概念
博主比较倾向的pod的分类是自主式 pod 和控制器管理的 pod
自主式 pod 字面意思就是自由的pod,可以将不受控制器管理的pod称为自由式 pod,这里的自由就是存在与否不会被在意,消失后也不会被控制器增加,多了也不会被消除。
pod是有生命周期的,如过时间过长是会死亡的!具体后续会讲到
那么控制器管理的pod的意思就呼之欲出了!即为受控制器管理的pod。被控制器拿捏的妥妥的 (ง •_•)ง
🐬控制管理器
接下来我们介绍一下pod内各个容器与pause的关系。

从上图中我们可以看出,pod中的 container可以有很多个( n>=1 ),但是有一点,他们共用 pause 的地址段,即为地址资源共享。
在一个pod里面,既共享地址段又共享存储卷。
那么接下来我们介绍一下受控制器管理的 pod。首先我们需要了解这个控制管理。
🐟 控制管理–ReplicationController
ReplicationController是一种Kubernetes资源,可确保它的pod始终保持运行状态。他是用来确保容器应用副本的数量始终保持在用户定义的副本数。如果pod异常退出或者因任何原因消失(例如节点从集群中消失或由于该pod被从节点中逐出),则ReplicationController会注意到缺少了pod并创建替代pod。
我用接下来的两幅图来解释一下这个过程。
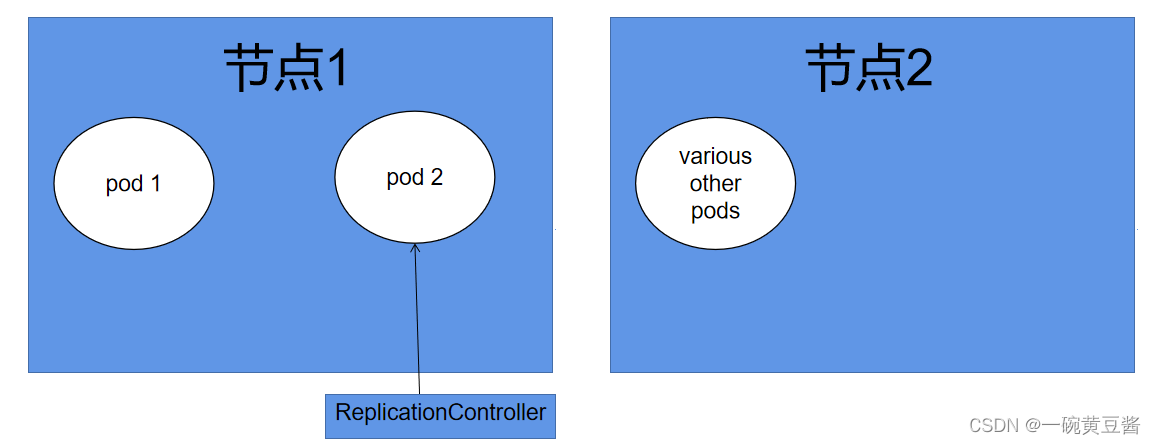
假设上述为正常运行的节点1和节点2,我们节点1中的pod 2是受控制器控制的,而pod 1没有。
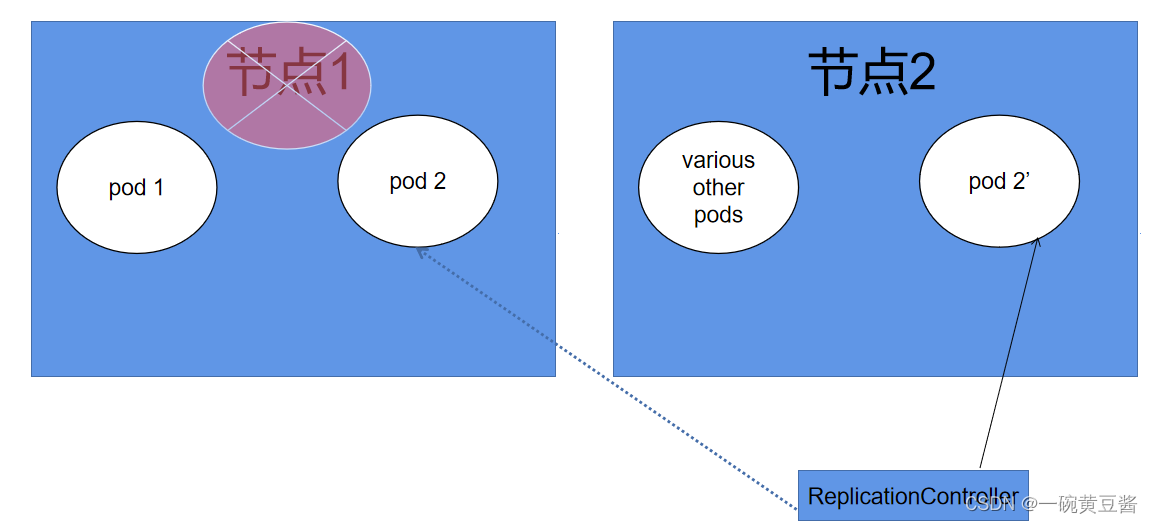
此时,节点 1出现问题了,那么属于自由式pod 的pod 1只能仍其消失,但是pod 2就不同了,他是被控制器控制的,当节点 1连带着pod 2消失后,ReplicationController 会自动在节点2生成pod 2’ 的替代,使得用户设定的副本数保持不变。
在新版本Kubernetes 中,建议使用ReplicaSet来代替ReplicationController
虽然ReplicaSet可以独立使用,但是一般还是使用Deployment来自动管理ReplicaSet,因为这样不需要关系兼容问题。(比如ReplicaSet不支持滚动更新,但是Deployment支持)
在此介绍一个概念:滚动更新(rolling-update)
当我们想要更新一个 pod 时,我们可以先建立一个新的 pod,因为需要保持副本数一定,所以我们需要删除一个 pod ,这时我们将旧的 pod 删除,即可实现更新。
接下来博主用下列图像讲解Deployment是如何实现自动管理

此时我们有版本1的两个pod(此时ReplicaSet为旧版本) ,我们想要将其滚动更新为版本2,更新过程如下

首先根据滚动更新概念,我们先创建一个新的ReplicaSet 2,然后新建一个V2版本的 pod,然后删除旧版本。
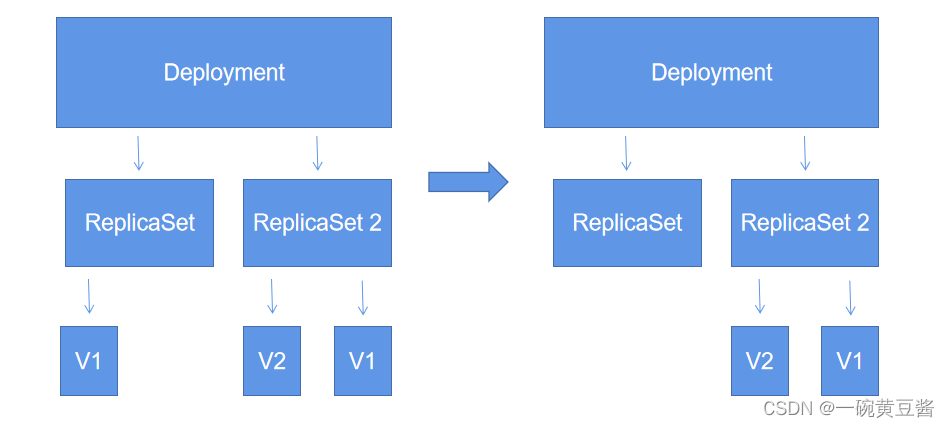
和上述步骤一致,将另一个 pod 新建后,删除旧的 pod
其实因为存在回滚机制,pod 并不是删除消失,更贴切的说法是停用
🐟 控制管理–HPA(Horizontal Pod Autoscaling)
Horizontal Pod Autoscaling仅适用于Deployment 和 ReplicaSet 。在V1中支持 pod 的 cpu 利用率进行扩缩容,在vlalpha中支持根据内存以及用户定义的 metric 进行扩缩容。
接下来,依旧是通过图解来介绍这个控制过程 🐼
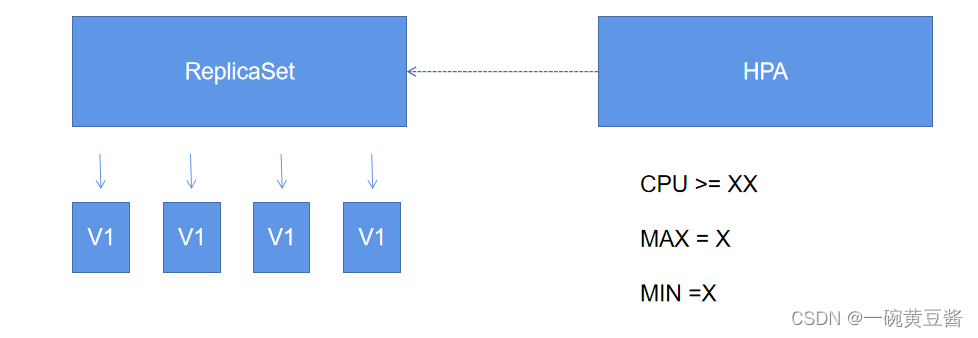
上述我们看到HPA控制了RS( ReplicaSet ),他的控制过程是什么呢?
我们在HPA中设定CPU利用率的一个阈值XX,以及最大pod数MAX(X)和最小pod数MIN(X)
这里的XX表示任意数,是人为设定的
那么这个CPU利用率的阈值是如何影响HPA的控制呢,当我们的CPU利用率太高时,超过设定的XX阈值,那么说明计算机忙不过来了,我们需要新建pod来分担压力。所以此时HPA会控制RS新建pod,当然如果CPU利用率第于阈值,RS会回收pod
这个MAX和MIN是如何控制呢?
当CPU利用率高于阈值,我们需要新建pod,但是不能无限制新建,所以这个MAX就是最大pod数,同理我们回收也不可以小于MIN最小值。
综上所述,我们可以利用HPA实现自动水平扩缩!
🐟 StatefulSet
StatefulSet是为了解决有状态服务的问题,因为在此之前Deployments和ReplicaSets是为无状态服务而设计,他的应用场景如下:
- 稳定的持久化存储,就是 Pod在重新调度后还是能访问到相同的持久化数据
- 稳定的网络标志,就是 Pod 重新调度后其 PodName和 HostName 不变,基于Headless Service来实现
- 稳定的持久化存储,就是Pod重新调度后还是能访问到相同的持久化数据
- 稳定的网络标志,就是Pod 重新调度后其PodName和主机名不变
🐟 DaemonSet
DaemonSet是为了确保节点上运行一个 Pod 的副本。当有节点加入集群时,会为他们新增一个 Pod 。当有节点从集群移除时,这些 Pod 也会被回收。删除DaemonSet 将会删除它创建的所有Pod。就相当于DS(DaemonSet)是一个管理员,负责节点上不能没有pod,当然如果DS这个管理员被删除的话,他的小弟pod也会被回收。
使用DaemonSet 的一些典型用法:
🐟 Job
Job有点像是批量化管理pod,我们可以设定pod正常执行次数,只有当pod正常执行次数达标后才允许Job结束。
Cron Job 是其中基于时间管理的,基于时间去管理pod。
🐬客户端(Client)— pod
Client是通过访问service的IP加端口,然后由service连接pod。(利用好service我们可以进行pod-pod的交流)
一般来讲都是 负载+缓存+程序+数据库
总结
此篇只是进行入门介绍,等后续文章进行后续讲解,期待关注阿酱,收藏专刊喔!超级干货等你来看!

版权归原作者 一碗黄豆酱 所有, 如有侵权,请联系我们删除。