
主要是使用selenium-chrome-driver和jsoup两个框架来实现本地爬虫
话不多说直接上代码
作者这里使用的是谷歌浏览器,所以我们需要一个谷歌浏览器的驱动chromedriver.exe(之后源码中会有)
ChromeOptions options =newChromeOptions();//创建浏览器参数//设置从ChromeDriver中获取属性(处理反爬机制)//设置谷歌浏览器用户数据目录
options.addArguments("--user-data-dir="+"D:\\Users\\Administrator\\AppData\\Local\\Google\\Chrome\\User Data");
options.addArguments("--disable-gpu");
options.addArguments("start-maximized");
options.addArguments("enable-automation");
options.addArguments("--no-sandbox");
options.addArguments("--disable-infobars");
options.addArguments("--disable-dev-shm-usage");
options.addArguments("--disable-browser-side-navigation");
options.addArguments("--proxy-server="+ proxyServer);
这里重点说明一下两个参数
1、–user-data-dir,这个参数指的是读取你本地谷歌浏览器的用户数据,指定了这个参数浏览器可以获取用户之前的浏览信息如:登录信息。
2、–proxy-server=,这个参数可以指定你本地的一个梯子。
ChromeDriver driver =newChromeDriver(options);
创建一个谷歌浏览器的driver
当运行这一行代码的时候,会打开一个谷歌浏览器
driver.get("xxxx");
这一行执行就好比你在浏览器中输入了一个网址。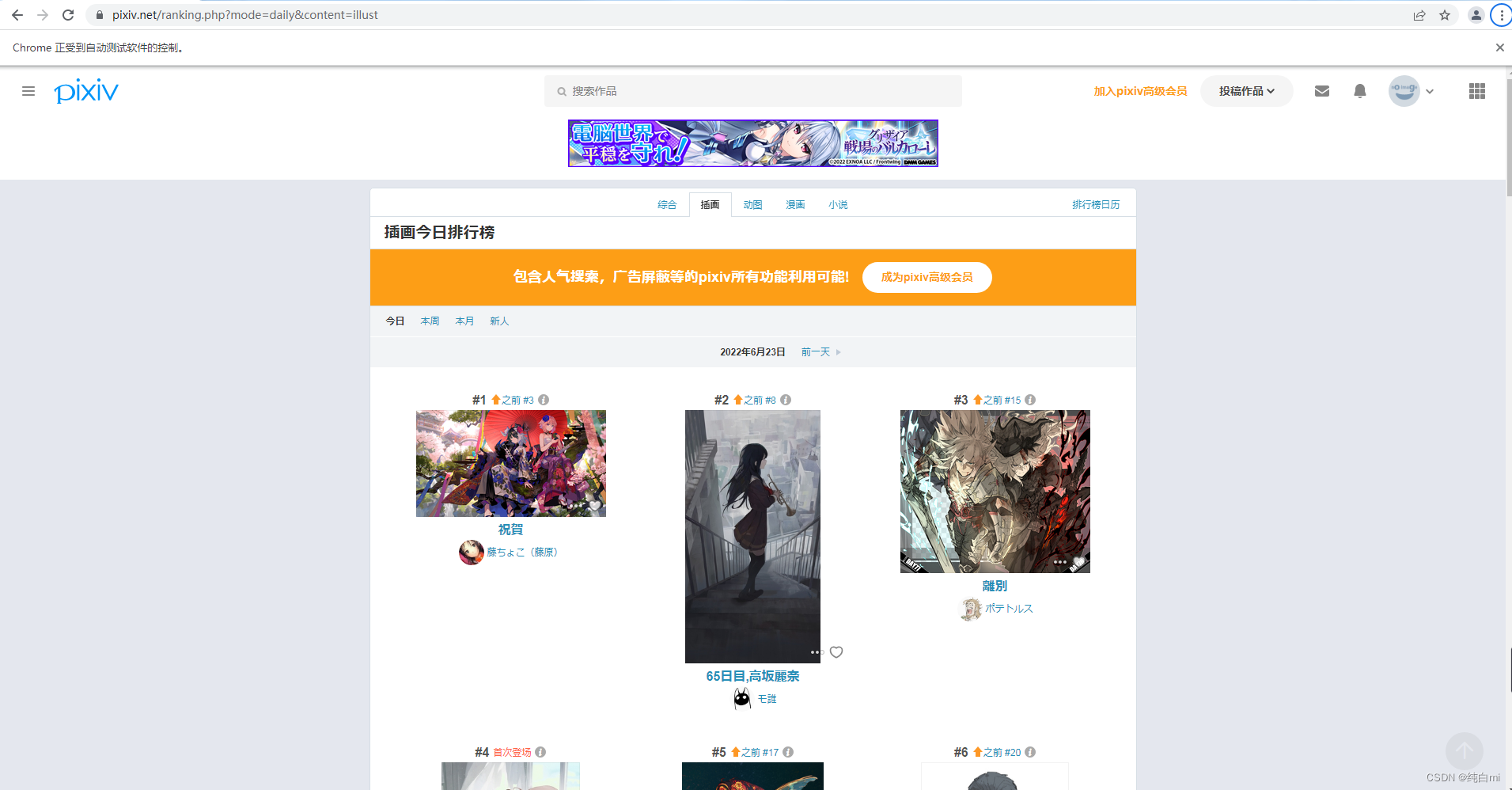
我们这里以Pivix图片网站为例
在通过Jsoup可以操作页面元素
//使用Jsoup来解析页面Document document =Jsoup.parse(driver.getPageSource());//根据class来获取也没上的元素Elements elements = document.body().getElementsByClass("ranking-item");
获取到Elements 之后就可以读取到图片的url地址了,之后就是下载图片到本地,这里就不做过多的代码解释(后面会提供源码)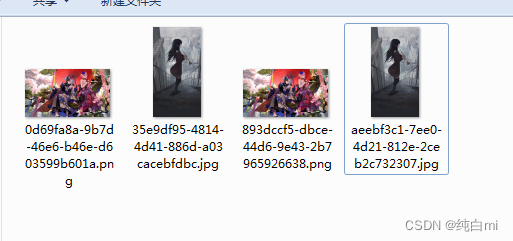
这是下载后的图片,每个图片有一个原图和一个压缩图可以下载。
大致流程是这样,后面在介绍一下如何让浏览器自动下拉到底部加载更多
privatestaticvoiddoDropDown(ChromeDriver driver){//下拉加载更多String height = driver.executeScript("return document.body.scrollHeight;").toString();// 按下键盘的END键滑动键盘,下拉页面Actions actions =newActions(driver);
actions.sendKeys(Keys.END).perform();}
driver可以直接执行js脚本,通过脚本获取页面的高度,也可以直接指向下滑的操作。
源码地址
本文转载自: https://blog.csdn.net/u010736165/article/details/125444378
版权归原作者 纯白mi 所有, 如有侵权,请联系我们删除。
版权归原作者 纯白mi 所有, 如有侵权,请联系我们删除。