
前言:
这是一个Flink自定义开发的基础教学。本文将通过flink的DataStream模块API,以kafka为数据源,构建一个基础测试环境;包含一个kafka生产者线程工具,一个自定义FilterFunction算子,一个自定义MapFunction算子,用一个flink任务的代码逻辑,将实时读kafka并多层处理串起来;让读者体会通过Flink构建自定义函数的技巧。
一、Flink的开发模块分析
Flink提供四个基础模块:核心SDK开发API分别是处理实时计算的DataStream和处理离线计算的DataSet;基于这两个SDK,在其上包装了TableAPI开发模块的SDK;在Table API之上,定义了高度抽象可用SQL开发任务的FlinkSQL。在核心开发API之下,还有基础API的接口,可用于对时间,状态,算子等最细粒度的特性对象做操作,如包装自定义算子的ProcessWindowFunction和ProcessFunction等基础函数以及内置的对象状态StateTtlConfig;
FLINK开发API关系结构如下:

二、定制化开发Demo演示
2.1 场景介绍
Flink实时任务的的通用技术架构是消息队列中间件+Flink任务:
将数据采集到Kafka或pulser这类队列中间件的Topic,然后使用Flink内置的kafkaSource,监控Topic的数据情况,做实时处理。
- 这里提供一个kafka的生产者线程,可以自定义构建需要的数据和上传时间,用于控制写入kafka的数据源;
- 重写两个DataStream的基础算子:FilterFunction和MapFunction,用于让读者体会,如何对FLINK函数的重新包装,后续更基础的函数原理一样;我这里用String数据对象做处理,减少对象转换的SDK引入,通常要基于业务做数据polo的加工,这个自己处理,将对象换成业务对象;
- 然后使用Flink将整个业务串起来,从kafka读数据,经过两层处理,最终输出需要的结果;
2.2 本地demo演示
2.2.1 pom文件
这里以flink1.14.6+scala1.12版本为例:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.example</groupId>
<artifactId>flinkCDC</artifactId>
<version>1.0-SNAPSHOT</version>
</parent>
<artifactId>flinkStream</artifactId>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink-version>1.14.6</flink-version>
<scala-version>2.12</scala-version>
<hadop-common-version>2.9.1</hadop-common-version>
<elasticsearch.version>7.6.2</elasticsearch.version>
<target.java.version>1.8</target.java.version>
<scala.binary.version>2.12</scala.binary.version>
<maven.compiler.source>${target.java.version}</maven.compiler.source>
<maven.compiler.target>${target.java.version}</maven.compiler.target>
<log4j.version>2.17.1</log4j.version>
</properties>
<repositories>
<repository>
<id>apache.snapshots</id>
<name>Apache Development Snapshot Repository</name>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
</snapshots>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink-version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala-version}</artifactId>
<version>${flink-version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala-version}</artifactId>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
<version>${flink-version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${target.java.version}</source>
<target>${target.java.version}</target>
</configuration>
</plugin>
<!-- We use the maven-shade plugin to create a fat jar that contains all necessary dependencies. -->
<!-- Change the value of <mainClass>...</mainClass> if your program entry point changes. -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
<artifactSet>
<excludes>
<exclude>org.apache.flink:flink-shaded-force-shading</exclude>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>org.apache.logging.log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>myflinkml.DataStreamJob</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!-- This improves the out-of-the-box experience in Eclipse by resolving some warnings. -->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<versionRange>[3.1.1,)</versionRange>
<goals>
<goal>shade</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
<pluginExecution>
<pluginExecutionFilter>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<versionRange>[3.1,)</versionRange>
<goals>
<goal>testCompile</goal>
<goal>compile</goal>
</goals>
</pluginExecutionFilter>
<action>
<ignore/>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
2.2.2 kafka生产者线程方法
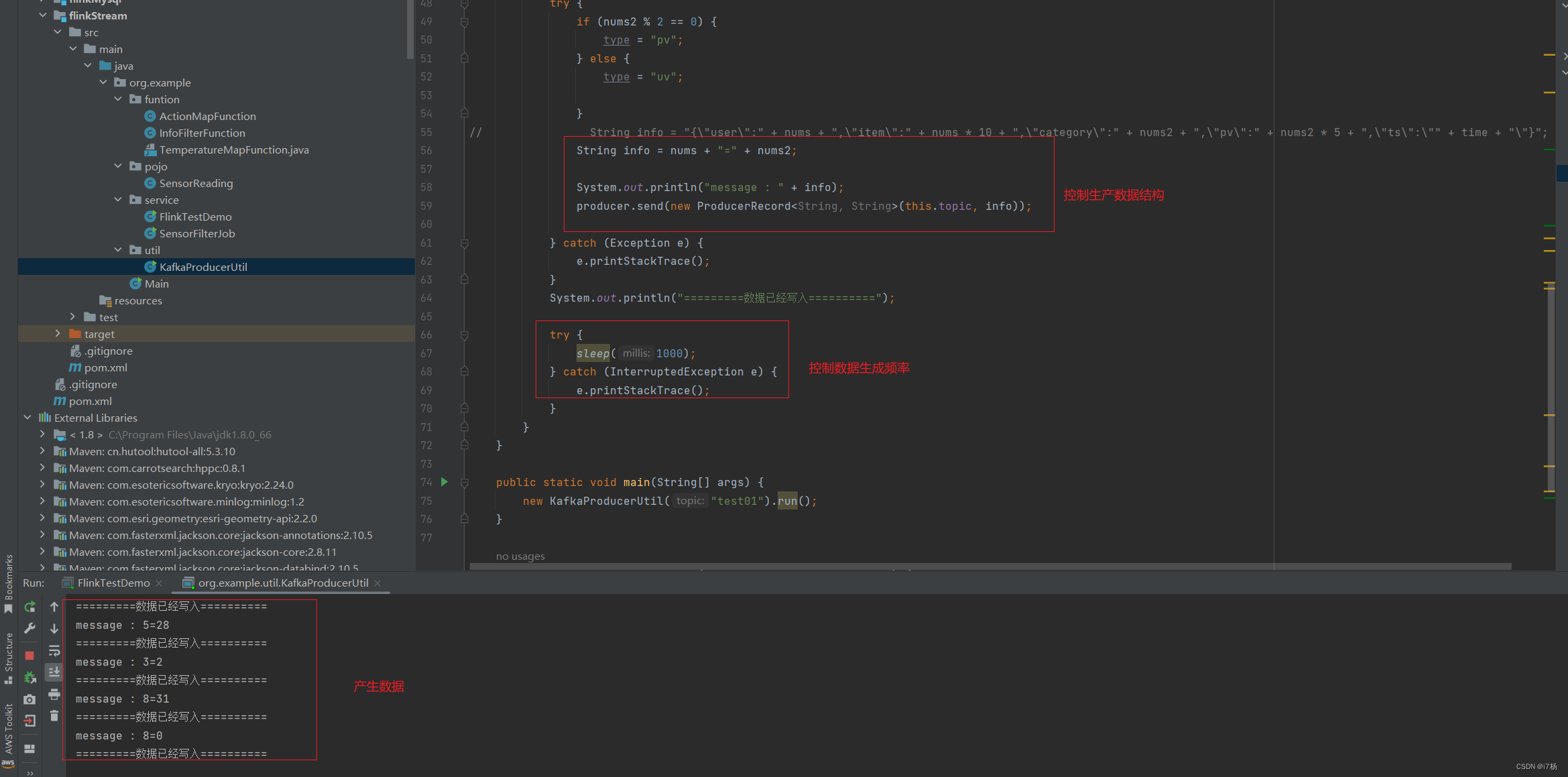
package org.example.util;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.*;
/**
* 向kafka生产数据
*
* @author i7杨
* @date 2024/01/12 13:02:29
*/
public class KafkaProducerUtil extends Thread {
private String topic;
public KafkaProducerUtil(String topic) {
super();
this.topic = topic;
}
private static Producer<String, String> createProducer() {
// 通过Properties类设置Producer的属性
Properties properties = new Properties();
// 测试环境 kafka 配置
properties.put("bootstrap.servers", "ip2:9092,ip:9092,ip3:9092");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return new KafkaProducer<String, String>(properties);
}
@Override
public void run() {
Producer<String, String> producer = createProducer();
Random random = new Random();
Random random2 = new Random();
while (true) {
int nums = random.nextInt(10);
int nums2 = random.nextInt(50);
// double nums2 = random2.nextDouble();
String time = new Date().getTime() / 1000 + 5 + "";
String type = "pv";
try {
if (nums2 % 2 == 0) {
type = "pv";
} else {
type = "uv";
}
// String info = "{\"user\":" + nums + ",\"item\":" + nums * 10 + ",\"category\":" + nums2 + ",\"pv\":" + nums2 * 5 + ",\"ts\":\"" + time + "\"}";
String info = nums + "=" + nums2;
System.out.println("message : " + info);
producer.send(new ProducerRecord<String, String>(this.topic, info));
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("=========数据已经写入==========");
try {
sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
new KafkaProducerUtil("test01").run();
}
public static void sendMessage(String topic, String message) {
Producer<String, String> producer = createProducer();
producer.send(new ProducerRecord<String, String>(topic, message));
}
}
2.2.3 自定义基础函数
这里自定义了filter和map两个算子函数,测试逻辑按照数据结构变化:
自定义FilterFunction函数算子:阈值小于40的过滤掉
package org.example.funtion;
import org.apache.flink.api.common.functions.FilterFunction;
/**
* FilterFunction重构
*
* @author i7杨
* @date 2024/01/12 13:02:29
*/
public class InfoFilterFunction implements FilterFunction<String> {
private double threshold;
public InfoFilterFunction(double threshold) {
this.threshold = threshold;
}
@Override
public boolean filter(String value) throws Exception {
if (value.split("=").length == 2)
// 阈值过滤
return Double.valueOf(value.split("=")[1]) > threshold;
else return false;
}
}
自定义MapFunction函数:后缀为2的,添加上特殊信息
package org.example.funtion;
import org.apache.flink.api.common.functions.MapFunction;
public class ActionMapFunction implements MapFunction<String, String> {
@Override
public String map(String value) throws Exception {
System.out.println("value:" + value);
if (value.endsWith("2"))
return value.concat(":Special processing information");
else return value;
}
}
2.2.4 flink任务代码
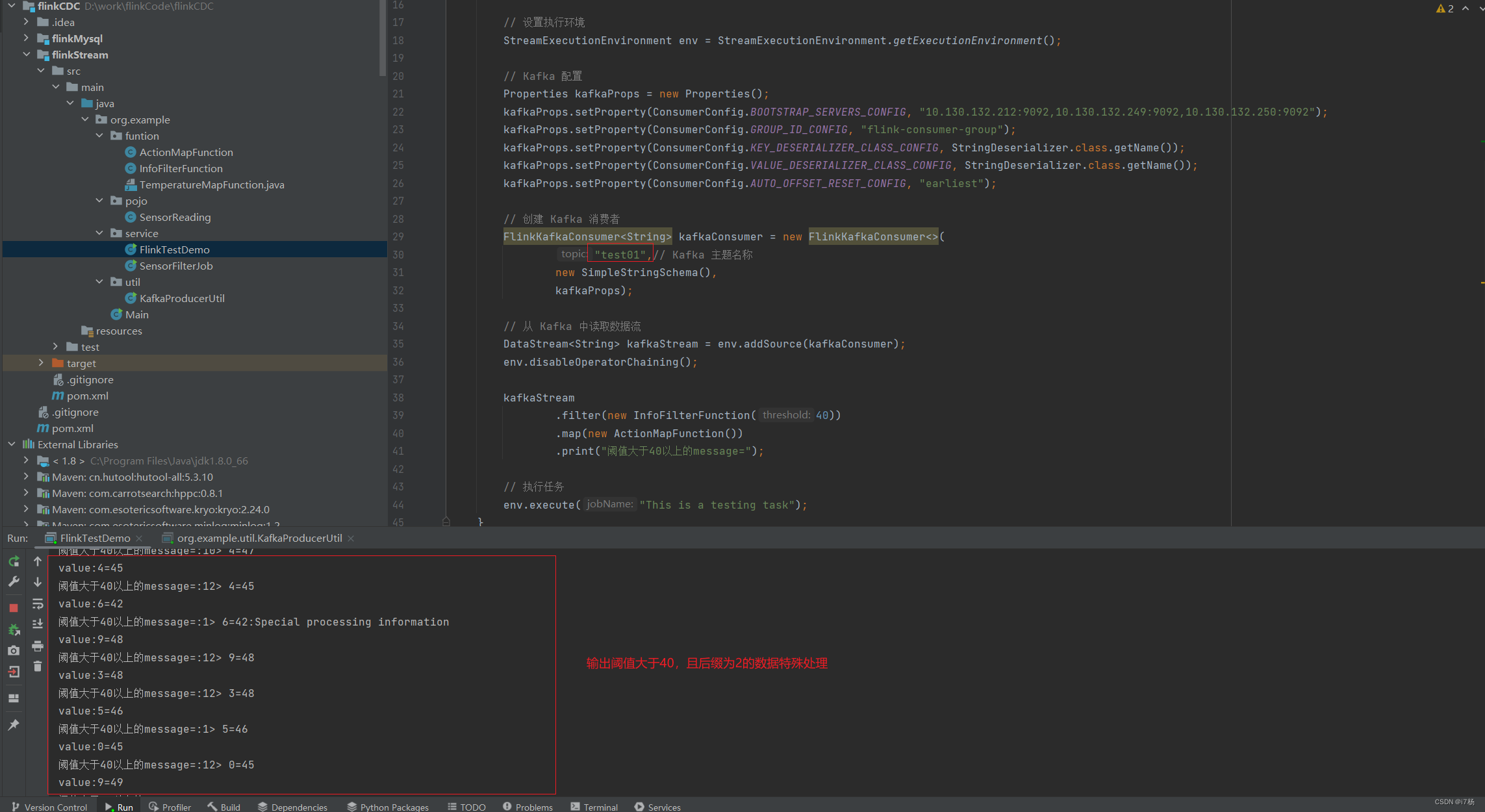
任务逻辑:使用kafka工具产生数据,然后监控kafka的topic,讲几个函数串起来,输出结果;
package org.example.service;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.example.funtion.ActionMapFunction;
import org.example.funtion.InfoFilterFunction;
import java.util.*;
public class FlinkTestDemo {
public static void main(String[] args) throws Exception {
// 设置执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Kafka 配置
Properties kafkaProps = new Properties();
kafkaProps.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "ip1:9092,ip2:9092,ip3:9092");
kafkaProps.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink-consumer-group");
kafkaProps.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kafkaProps.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kafkaProps.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 创建 Kafka 消费者
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
"test01",// Kafka 主题名称
new SimpleStringSchema(),
kafkaProps);
// 从 Kafka 中读取数据流
DataStream<String> kafkaStream = env.addSource(kafkaConsumer);
env.disableOperatorChaining();
kafkaStream
.filter(new InfoFilterFunction(40))
.map(new ActionMapFunction())
.print("阈值大于40以上的message=");
// 执行任务
env.execute("This is a testing task");
}
}
运行结果:
本文转载自: https://blog.csdn.net/weixin_42049123/article/details/135561586
版权归原作者 i7杨 所有, 如有侵权,请联系我们删除。
版权归原作者 i7杨 所有, 如有侵权,请联系我们删除。