
文章目录
一、自动化测试
1、什么是自动化测试?
程序测试程序、代码代替思维、脚本代替人工
核心:质量和效率

作用:降低成本、节省人力时间、推动CI和DevOps、准确性和可靠性、模拟人工难以实现的手段、快速持续迭代发布能力、衡量产品的质量、提升测试效率、提高测试覆盖率
2、手工测试 vs 自动化测试


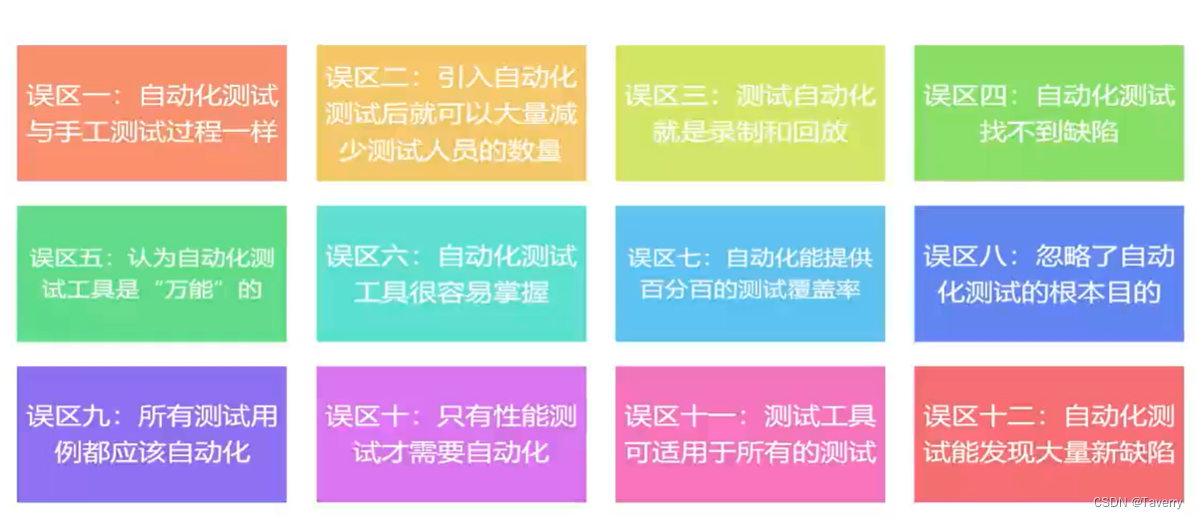
3、自动化测试常见误区
4、自动化测试的优劣


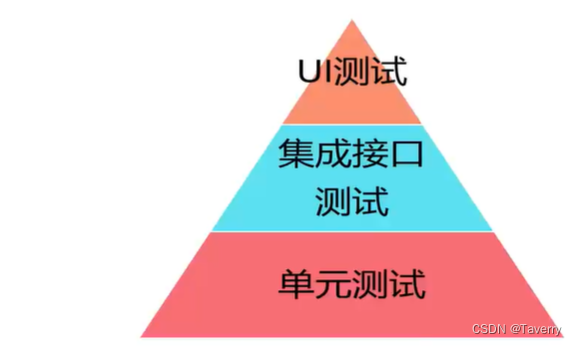
5、自动化测试分层
6、什么项目适合自动化测试
1、项目变动少
2、项目周期足够
3、项目资源足够
4、产品型项目
5、需要频繁运行测试
6、多次重复、机械性动作
7、回归测试
8、能够自动编译、自动发布的系统
二、Selenuim
是一个用于web应用程序测试的工具
特点:
1、开源软件:源代码开放可以根据需求来增加工具的某些功能
2、跨平台:Linux,windows,mac
3、核心功能:就是可以在多个浏览器上进行自动化测试
4、多语言:Java,python,C#,JavaScript,Ruby等
5、成熟稳定:目前已经被google,百度,腾讯等公司广泛使用
6、功能强大:能够实现类似商业工具的大部分功能,因为开源性,可实现定制化功能
1、小例子
import time
from selenium import webdriver
# 获取浏览器对象
driver = webdriver.Chrome('D:/chromeDriver/chromedriver.exe')
url ="https://www.baidu.com/"
driver.get(url)
time.sleep(5)
driver.quit()
2、用法
# 导入 webdriverfrom selenium import webdriver
# 要想调用键盘按键操作需要引入keys包from selenium.webdriver.common.keys import Keys
# 调用环境变量指定的PhantomJS浏览器创建浏览器对象
driver = webdriver.PhantomJS()# 如果没有在环境变量指定PhantomJS位置# driver = webdriver.PhantomJS(executable_path="./phantomjs"))# get方法会一直等到页面被完全加载,然后才会继续程序,通常测试会在这里选择 time.sleep(2)
driver.get("http://www.baidu.com/")# 获取页面名为 wrapper的id标签的文本内容
data = driver.find_element_by_id("wrapper").text
# 打印数据内容print(data)# 打印页面标题 "百度一下,你就知道"print(driver.title)
# 生成当前页面快照并保存
driver.save_screenshot("baidu.png")# id="kw"是百度搜索输入框,输入字符串"长城"
driver.find_element_by_id("kw").send_keys("尚学堂")# id="su"是百度搜索按钮,click() 是模拟点击
driver.find_element_by_id("su").click()# 获取新的页面快照
driver.save_screenshot("页面1.png")# 打印网页渲染后的源代码print(driver.page_source)# 获取当前页面Cookieprint(driver.get_cookies())# ctrl+a 全选输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'a')# ctrl+x 剪切输入框内容
driver.find_element_by_id("kw").send_keys(Keys.CONTROL,'x')# 输入框重新输入内容
driver.find_element_by_id("kw").send_keys("python爬虫")# 模拟Enter回车键
driver.find_element_by_id("su").send_keys(Keys.RETURN)# 清除输入框内容
driver.find_element_by_id("kw").clear()# 生成新的页面快照
driver.save_screenshot("python2.png")# 获取当前urlprint(driver.current_url)# 关闭当前页面,如果只有一个页面,会关闭浏览器# driver.close()# 关闭浏览器
driver.quit()
3、页面操作
获取
页面的一个表单输入框:
<inputtype="text" name="passwd"id="passwd-id"/>
element = driver.find_element_by_id("passwd-id")
element = driver.find_element_by_name("passwd")
element = driver.find_elements_by_tag_name("input")
element = driver.find_element_by_xpath("//input[@id='passwd-id']")
注意:在用 xpath 的时候还需要注意的如果有多个元素匹配了 xpath,它只会返回第一个匹配的元素。如果没有找到,那么会抛出 NoSuchElementException 的异常
单个元素选取
- find_element_by_id
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
多个元素选取
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
利用 By 类来确定哪种选择方式
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//button[text()="Some text"]')
driver.find_elements(By.XPATH, '//button')
By 类的一些属性如下
- ID = “id”
- XPATH = “xpath”
- LINK_TEXT = “link text”
- PARTIAL_LINK_TEXT = “partial link text”
- NAME = “name”
- TAG_NAME = “tag name”
- CLASS_NAME = “class name”
- CSS_SELECTOR = “css selector”
输入内容
element.send_keys("some text")
模拟点击
element.send_keys("and some", Keys.ARROW_DOWN)
清空文本
element.clear()
元素拖拽
要完成元素的拖拽,首先你需要指定被拖动的元素和拖动目标元素,然后利用 ActionChains 类来实现
element = driver.find_element_by_name("source")
target = driver.find_element_by_name("target")from selenium.webdriver import ActionChains
action_chains = ActionChains(driver)
action_chains.drag_and_drop(element, target).perform()
frame切换
# 切换
driver.switch_ro.frame('frame_name')# 切换回原始的
driver.switch_to.default_content()
窗口切换/标签页切换
# 获取所有
driver.window_handles
# 获取单个
driver.current_window_handle
# 切换
driver.switvh_to.window(handle)
截图
driver.get_screenshot_as_file(保存路径)
历史记录
driver.forward()# 前进
driver.back()# 后退
4、等待
隐式等待
到了一定的时间发现元素还没有加载,则继续等待我们指定的时间,如果超过了我们指定的时间还没有加载就会抛出异常,如果没有需要等待的时候就已经加载完毕就会立即执行
from selenium import webdriver
url ='https://www.guazi.com/nj/buy/'
driver = webdriver.Chrome()
driver.get(url)
driver.implicitly_wait(100)print(driver.find_element_by_class_name('next'))print(driver.page_source)
显示等待
指定一个等待条件,并且指定一个最长等待时间,会在这个时间内进行判断是否满足等待条件,如果成立就会立即返回,如果不成立,就会一直等待,直到等待你指定的最长等待时间,如果还是不满足,就会抛出异常,如果满足了就会正常返回
url ='https://www.guazi.com/nj/buy/'
driver = webdriver.Chrome()
driver.get(url)
wait = WebDriverWait(driver,10)
wait.until(EC.presence_of_element_located((By.CLASS_NAME,'next')))print(driver.page_source)
- presence_of_element_located - 元素加载出,传入定位元组,如(By.ID, ‘p’)
- presence_of_all_elements_located - 所有元素加载出
- element_to_be_clickable - 元素可点击
- element_located_to_be_selected - 元素可选择,传入定位元组
强制等待
使用 time.sleep
5、处理滚动条
当页面上的元素超过一屏后,想操作屏幕下方的元素,是不能直接定位到,会报元素不可见的。这时候需要借助滚动条来拖动屏幕,使被操作的元素显示在当前的屏幕上。滚动条是无法直接用定位工具来定位的。selenium里面也没有直接的方法去控制滚动条,这时候只能借助J了,还好selenium提供了一个操作js的方法:execute_script(),可以直接执行js的脚本
控制滚动条高度
1、滚动条回到顶部:
js="var q=document.getElementById('id').scrollTop=0"
driver.execute_script(js)
2、滚动条拉到底部
js="var q=document.documentElement.scrollTop=10000"
driver.execute_script(js)
可以修改scrollTop 的值,来定位右侧滚动条的位置,0是最上面,10000是最底部
以上方法在Firefox和IE浏览器上上是可以的,但是用Chrome浏览器,发现不管用。Chrome浏览器解决办法:
js = "var q=document.body.scrollTop=0"
driver.execute_script(js)
横向滚动条
1、有时候浏览器页面需要左右滚动(一般屏幕最大化后,左右滚动的情况已经很少见了)
2、 通过左边控制横向和纵向滚动条scrollTo(x, y)
js = "window.scrollTo(100,400)"
driver.execute_script(js)
元素聚焦
虽然用上面的方法可以解决拖动滚动条的位置问题,但是有时候无法确定我需要操作的元素在什么位置,有可能每次打开的页面不一样,元素所在的位置也不一样,怎么办呢?这个时候我们可以先让页面直接跳到元素出现的位置,然后就可以操作了
同样需要借助JS去实现。 具体如下:
target = driver.find_element_by_xxxx()
driver.execute_script("arguments[0].scrollIntoView();", target)
参考代码
from selenium import webdriver
from lxml import etree
import time
url ="https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC&enc=utf-8&wq=%E7%AC%94%E8%AE%B0%E6%9C%AC&pvid=845d019c94f6476ca5c4ffc24df6865a"# 加载浏览器
wd = webdriver.Firefox()# 发送请求
wd.get(url)# 要执行的js
js ="var q = document.documentElement.scrollTop=10000"# 执行js
wd.execute_script(js)
time.sleep(3)# 解析数据
e = etree.HTML(wd.page_source)# 提取数据的xpath
price_xpath ='//ul[@class="gl-warp clearfix"]//div[@class="p-price"]/strong/i/text()'# 提取数据的
infos = e.xpath(price_xpath)print(len(infos))# 关闭浏览器
wd.quit()
6、警告框
通过js中的alert、confirm、prompt方法弹出的框
前提:已获取警告框
1、切换警告框
alert=driver.switch_to.alert
2、关闭警告框
适用于三种警告框:alert.dismiss()3、确认(也会自动关闭)
适用于confirm、prompt:alert.accept()4、输入文字
适用于prompt:alert.send_keys()5、获取警告框中的文字
alert.text
补充: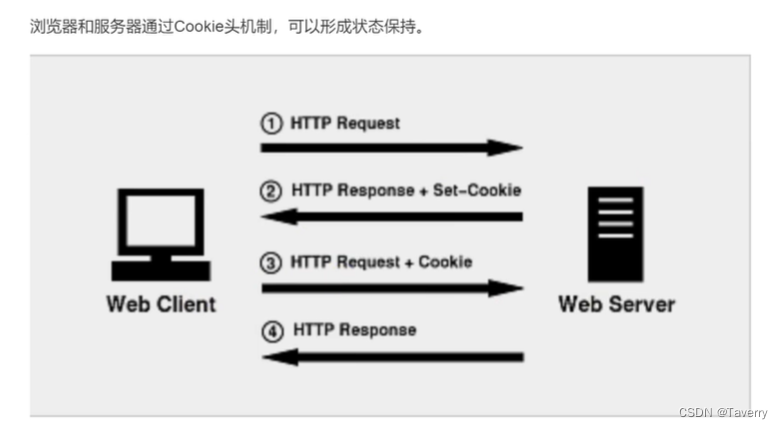
版权归原作者 Taverry 所有, 如有侵权,请联系我们删除。