
一、背景
重复工作,代码规范:B端前端代码开发过程中开发者总会面临重复开发的痛点,很多CRUD页面的元素模块基本相似,但仍需手动开发,将时间花在简单的元素搭建上,降低了业务需求的开发效率,同时因为不同开发者的代码风格不一致,使得敏捷迭代时其他人上手成本较高。
AI代替简单脑力:AI大模型的不断发展,已经具备简单的理解能力,并可以进行语言到指令的转换。对于基础页面搭建这样的通用指令可以满足日常基础页面搭建的需要,提升通用场景业务开发效率。
二、生成链路一览
B端页面列表、表单、详情都支持生成,链路大概可分为以下几个步骤。

- 输入自然语言
- 结合大模型按照指定规则提取出相应搭建信息
- 搭建信息结合代码模板与AST输出前端代码
三、表达需求
图形化配置
辅助代码生成第一步是告诉它开发出怎样的界面,提到这里,我们首先想到的是页面配置,即目前主流的低代码产品形式,用户通过一系列的图形化配置对页面进行搭建,如下图:

以上配置方式对于通用场景(如后台逻辑较为简单的CURD页面)或是特定的业务场景(如会场搭建)有较好的提效作用 。而对于需要不断迭代逻辑相对复杂的需求来说,由于是通过图形化操作的方式进行配置,对于交互设计要求较高,并且具备一定的上手成本,并且随着需求的复杂度越来越高,配置表单交互越来越复杂,维护成本也越来越高。因此,页面配置的方式前端领域的使用是相对克制的。
AI直接生成代码
AI生成代码在工具函数场景下应用较多,但对于公司内部特定业务场景的需求,可能需要考虑以下几点:
- 生成定制化:公司团队内部有自己的技术栈与重型通用组件,需要将这些知识进行预训练,目前对于长文本的预训练内容仅支持单次会话注入,token数消耗较高;
- 准确度:AI生成代码的准确度挑战是比较大的,加上预训练包含大段prompt,因为代码输出的内容细节过多,加上模型幻觉,目前来看业务代码的失败率是较高的,而准确度是考量辅助编码的核心指标,如果这一点无法解决,辅助编码效果将大打折扣;
- 生成内容残缺:由于GPT单次会话的存在限制,对于复杂需求,代码生成有一定几率被截断,影响生成成功率。
自然语言转指令
GPT其实还有个很重要的能力,那就是自然语言转指令,指令即行动,举个例子:我们假设一个函数方法实现,输入是自然语言,结合GPT与内置的prompt,让其稳定的输出某几个单词,我们是不是就可以通过对这些单词输出做出进一步的行动?这相对于图形化配置有以下几个优点:
- 学习门槛低:因为自然语言本身就是人类的原生语言,你只需要根据你的想法描述页面即可,当然描述的内容是需要遵循一些规范的,但相对于图形化配置来说效率是有明显提升的;
- 复杂度黑盒:图形化配置的复杂度会随着配置页面复杂度的上升而上升,而这样的复杂度会一览无余地展示在用户面前,用户可能会迷失在复杂的配置页面交互中,配置成本逐步上升;
- 敏捷迭代:如果要在用户端新增一个页面配置功能,基于大模型的交互方式可能只需要新增几个prompt,但图形化配置需要开发复杂表单以便于快速输入。
这里大家可能会有个疑问:
生成的指令信息不也会出现大模型幻觉吗?如何保证每次生成指令信息是稳定且一致的呢?
自然语言转指令可行大致有以下几个原因:
- 由长文本转关键信息属于总结内容,大模型在总结场景下的准确度远高于扩散型场景;
- 由于指令信息只是提取需求中的关键信息,不需要做代码技术栈上的预训练,因此prompt存在很大的可优化空间,通过优化完善prompt内容可以有效提升输出准确度;
- 准确性可验证,对于每一个场景不同表述需求输入,可以通过单测预测输出验证准确性,当出现badCase,我们在优化后针对该badCase接入单测。保证准确度不断提高。
让我们来看最终的信息转化结果:
对于代码辅助来说,基于用户的需求描述,经过PROMPT处理,可以拿到这样的信息。为代码生成提供基础信息。

四、信息转化为代码
通过大模型拿到自然语言对应可编码的信息(即上面例子中的JSON)后,我们就可以基于这个信息转化代码了。对于一个有明确场景的页面而言,一般情况下可分为主代码模板(列表、表单、描述框架)+ 业务组件。
转化流程

我们如何开发代码的?
其实这一步很像我们自己开发代码,我们拿到需求后,大脑中会提取其中的关键信息,即上方提到的自然语言转指令,然后我们会在vscode中创建一个文件,然后会进行以下操作:
首先一定是创建代码模板,然后根据场景引入对应重型组件,如列表就引入ProTable,表单就引入ProForm。
基于ProTable等重型组件并向其中添加一些属性,如headerTitle、pageSize等列表相关信息。
根据需求描述引入组件,比如识别到筛选项中存在类目选择,会在useColumns新增业务组件,识别到需求描述中存在导入导出组件,会在页面的指定位置新增导入导出业务组件。
拿到mock链接,新增请求层,在页面指定位置引入。
对于以上常用的代码插入场景都可以封装进JSON中,然后通过代码模板结合AST插入或字符串模板替换的方式生成对应代码。
五、源码生成
定位
源码辅助主要帮助开发者减少重复的工作,提升编码效率,和低代码页面搭建属于完全不同的赛道,低代码重在特定场景下搭建完整的页面,并且页面功能数量是可枚举的,业界低代码搭建也有很优秀的实践。而源码辅助工具旨在帮助用户尽可能多的初始化业务需求代码,后面的修改维护在代码层面交给用户,提升新增页面的开发效率。
具体的功能架构见下方:
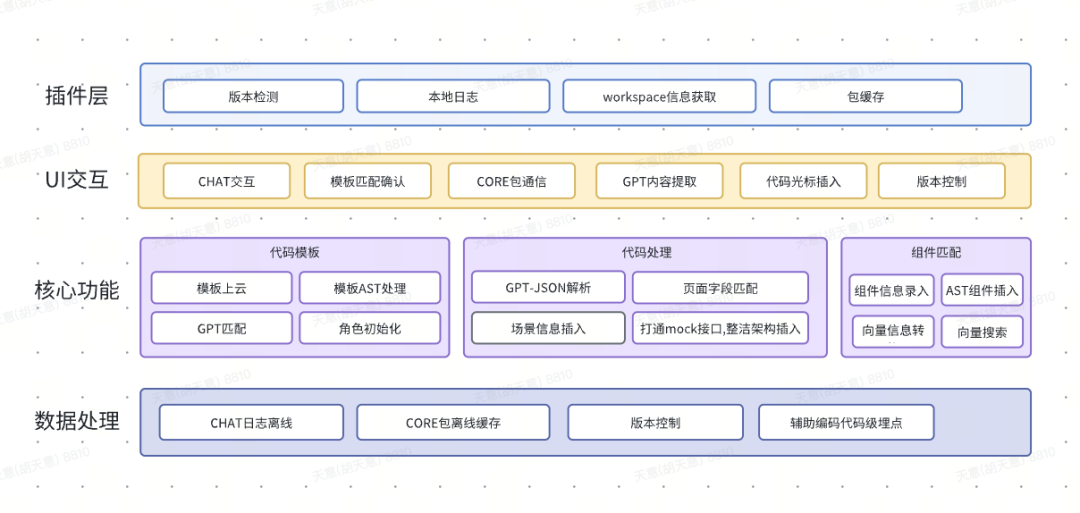
六、组件向量搜索与嵌入
对于前端开发来说,提效的本质是少开发代码,更快的页面生成是一方面,良好的组件抽离是相当重要的一环,我们结合向量对组件的引入链路进行了优化,在初始化模板与存量代码中快速搜索定位组件。
组件向量引入链路
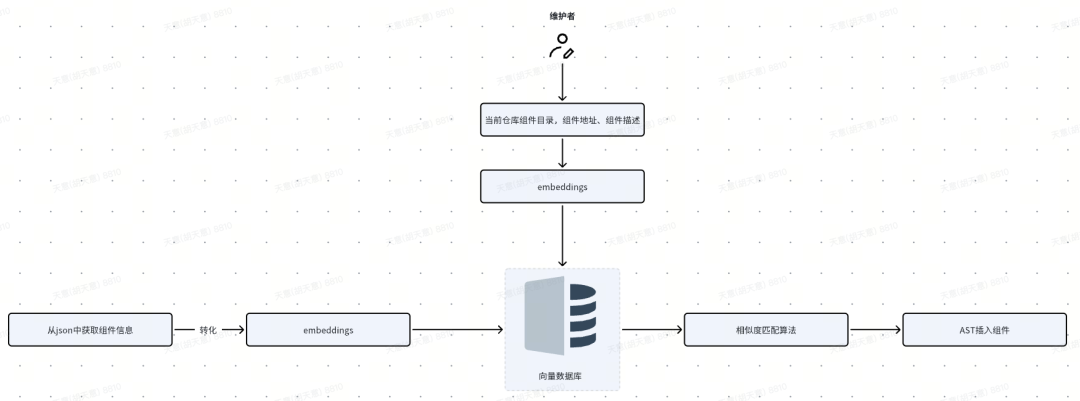
组件信息录入
支持快速获取组件的描述内容与组件引入范式,一键录入组件,组件描述会转化为向量数据存入向量数据库。

组件向量搜索
用户输入描述后,会将描述转化为向量,基于余弦相似度与组件列表进行比对,找到相似度最高的组件TOP N。

组件快速插入
用户可以在存量代码中快速通过描述搜索匹配度最高的组件,回车进行插入。
七、未来展望
- 组件嵌入模板:目前组件已支持向量搜索,通过结合源码页面生成,支持动态匹配组件并嵌入模板;
- 存量代码的编辑生成:目前仅支持新增页面的源码生成,后续将支持存量页面的局部代码新增;
- 代码模板流水线:AST的代码操作工具化,将自然语言与代码写入进一步打通,提升场景拓展效率。
** *文/**天意
本文属得物技术原创,更多精彩文章请看:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!
版权归原作者 得物技术 所有, 如有侵权,请联系我们删除。