
zk 多叉树
临时节点和watch机制实现注册中心自动注册和发现,数据都在内存,nio 多线程模型;
cp注重一致性,数据不一致时集群不可用
分布式协调系统,资源的统一管理
事务请求处理方式
1.all事务由唯一服务器处理
2.将客户端事务请求转成proposal分发followers
3.等待半数ack,再commit
对事务性支持依赖
zoo_create_op_int / zoo_delete_op_init / zoo_set_op_init /zoo_check_op_init
每个函数在客户端初始化operation,准备好事务所有操作后,zoo_multi提交所有操作,如果一个失败 则返回第一个失败操作的状态信号,通过版本号维持同一原子性操作
zab
支持崩溃恢复的原子广播协议,
领导选举:leader(写)维护follower列表,FIFO zxid
数据同步:所有节点数据要和leader保持一致,高可用分区容错,follower本地事务日志
请求广播:leader收到写请求,两阶段提交(事务proposal形式)广播写请求,一半ack=成功
模式:崩溃恢复 消息广播
消息广播
所有请求由leader转成proposal分发给其他服务follower
过半follower反馈信息,leader广播commit,将之前的proposal提交
崩溃恢复
被leader提交的proposal最终被follower服务提交
- 新选举的leader节点含最大的zxid
丢弃被leader提出但未被提交的proposal
- 被选举出来的leader不能有未提交的proposal
leader网络中断 崩溃退出 重启 ,选新leader后过半机器该leader完成同步 进入广播模式
新加入的机器 先恢复模式然后同步完广播
保证消息有序
1.先分配全局递增id(zxid) 每个follower分配单独FIFO队列(异步解耦) 发送proposal广播
2.follower接到写本地事务,返回ack
leader收半数以上follower的ack响应消息,广播commit消息 自身完成事务提交
3.follower接收到commit消息 将上一条事务提交
数据同步
完成leader选举,leader先确认事务日志所有proposal已被集群过半服务器commit
确保follower能接收每条事务的**proposal:**能将提交的事务应用到内存返ack响应,完成后才加入到真正的follower列表
写请求直接发送给observer节点,observe直接更新本地内存
掉头发版本
也没有那么夸张啦;三个参数对比大小,选对应的数据同步方式
peerLastZxid:learner/follower/observer服务器 最后处理的zxid
minCommittedLog:leader服务器proposal缓存队列commitedLog中最小的zxid
maxCommittedLog:
四类数据同步:
diff差异化同步:peerlastZxid介于min max间
trunc+diff先回滚在差异化同步:leader服务器发现learner含一条自己没有的,回滚
trunc:回滚 peerlastZxid大于max,leader要求learner回滚到zxid为max对应的事务 什么人这是
snap:全量同步,peerlastZxid小于min
proposal
zxid 64位
低32位单增计数器针对每一个请求
高32位leader周期的**epoch编号**:当前集群所处年代/周期 leader变更+1
新的leader中取**本地事务日志最大编号的proposal的zxid**解析epoch编号+1,低32归零
节点状态
following随从 / leading领导者
election或looking选举状态正在找leader / observing观察只读节点
投票再同一轮,logicalClock标识标记轮数 开始前先清空上一轮投票情况
选举:
投票箱:zxid sid,维护自己和其他节点的投票信息,改票时广播
zxid:任期term 事务id ;sid 手动指定
初始化,all都是follower 随机超时 变成candidate 发起选举
follower在election timeout内没有收到l心跳 发起选举
term:任期,每个节点维持着,是递增的, 存储在log的entry中
每次rpc通信传递该任期号,大于本地切换为follower,小于报错
通信:
requestVote RPC 负责选举(lastindex lastTerm)
appendEntries RPC负责数据交互
日志序列:每个节点维持着持久化log,一致性协议算法 每个节点log一致 顺序存放
选举:增加term切换到candidate 最多投一票 多数则leader发送心跳
watch:观察者模式
znode设置,一次性触发器;3.6可递归触发多次
角色:客户端线程 / 客户端的watchManager / zk服务器
客户端向zk服务器注册watcher监听,监听信息存储到客户端zkWatchManager中
zk节点变化通知客户端,客户端调用相应watcher到回调
** 串行同步顺序性(w放队列**中)
流程:串行同步
各创建watchManager
事件触发服务端查询节点的路径信息watch事件,通知客户端
客户端收到,查本地manager得watch调回
客户端实现:
- 标记会话带有watch事件
- dataWatchRegistration类保存watcher事件和节点对应关系
- 客户端请求服务端,请求封装为packet,添加到outgoingQueue中
- sendThread的readResponse接收服务端回调,finishPacket将watch注册到zkWatchManager,sendThread发送path路径和watcher=true,到server注册watch事件
zkWatchManager存类Map<String,Set<Watcher>> dataWatchers添加key为path的本地事件; Map<String,Set<watcher>> existsWatchers Map<String,Set<Watcher>> childrenWatchers
服务端实现:
- 收到请求是否带watch事件,finalRequestProcessor的processRequest
- 对应的watch事件存储到watchManager : HashMap<String,HashSet<Watcher>> watchTable,key为path wathcer客户端网络连接封装socket,节点变化时通知对应连接,(连接心跳保持)
服务器端触发:
- 调用watchManager中的方法 触发数据变更事件
- 封装具有**会话状态 事件类型 数据节点 **watchedEvent对象,查询该节点注册的watch事件,为空无,存在添加到定义的watchers集合中,在watcherManager删除,调用process客户端发送通知
客户端回调:
- sendThread.redResponse
- 反序列化转换成watcherEvent对象,调eventThread.queueEvent交给eventThread
- zkWatcherManager查询注册过的watch,查到了删!
- watcher存储到waitingEvent队列中,调用eventThread.run循环取出waitingEvents队列等待的watcher事件
观察者机制observer节点
动态扩展zk集群,不降低写性能
不参与投票,只获取投票结果,可处理读写请求,写转leader
负责接收leader同步过来的提交数据,直接同步
数据一致性模型 cp
cap 强一致,更新操作完 多个后续进程访问返回最新的更新过的值
弱一致:系统数据写入后 不一定立即读取最新写入数据
最终一致性:所有数据副本 经过一段时间的同步后 最终能够达到一致的状态
因果一致性:因果关系的操作顺序得到保证
会话一致性:对系统数据的访问过程框定在一个会话中
强制数据同步,先调用sync函数再读取数据
follower可能是之前的老数据,要是立即获取leader新数据则先sync
paxos强一致:同步数据
角色:
proposer提议者:发出的提案被多数acceptor接受,该提案value被选定
acceptor接受者:只要acceptor接受了某个提案,acceptor该提案的value被选定
learners记录员:acceptor告诉learner哪个value被选定,learner认为哪个value被选定
阶段:
1.proposer收到client请求或发现本地有未提交的值,选择提案编号n,发送prepare请求
2.acceptor收到编号n的prepare请求,如已有提交的value对比编号,大于n则拒绝回应 否返v和号
无提交记录,判断是否有编号n1,n1>n 拒绝响应,否则n1改为n,响应prepare
3.proposer收到多数acceptor发出n的响应,[n,v]提案的accept请求给半数以上的acceptor
4.acceptor收到accept请求,对比本地的编号 =< n 接受该值 提交记录value 否则拒绝请求
5.proposer收到大多数acceptor,选定value 同步给leader
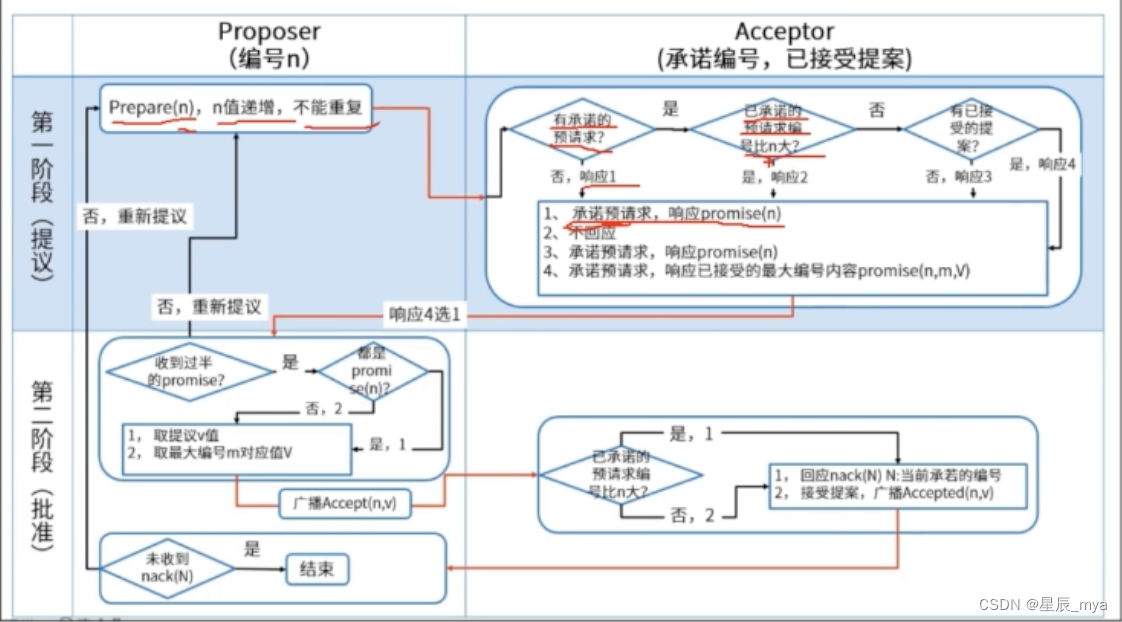
活锁:accept一直被拒绝,加n,另一个proposer也这么操作,accept一致失败
multi-paxos:确定多个值,接收accept请求后,一定时间内不再accept其他节点的请求,保证后续编号不需要prepre
通信:
requestVote RPC 负责选举(**lastindex lastTerm**)zxid myid
appendEntries RPC负责数据交互
日志序列:每个节点维持着持久化log,一致性协议算法 每个节点log一致 顺序存放
数据模型:树形结构
客户端会话session 数据节点dataNode信息
内存dataTree数据结构,path到dataNode映射, dataNode间树状层级关系
事务日志 快照文件 落盘
znode文件/目录,路径标识 存储数据
增删改查原子操作(节点相关的所有数据)ACL访问控制列表 规定用户权限
>1m,斜杠开头 唯一
持久节点: 一直存储zk上
临时节点:会话超时/异常 删除
有序节点:单调递增的数字作为后缀追加
节点内容
二进制数组byte data: 存储节点的数据 ACL访问控制 子节点数据 自身信息的stat
stat+节点路径:状态信息
czxid创建节点的事务id; ctime创建时间 ;
mzxid最后一次被更新的事务id ;mtime最后更新时间
version版本号; pzxid子节点最后一次被修改的事务id ;
cversion子节点版本 ; averson:acl版本号
ephemeralOwner创建节点的; sessionId 持久节点 值为0
dataLenght数据内容长度 ; numChildren子节点个数
session会话管理:
客户端连接分片 分配sessionId,客户端配置timeout ,zk据此计算下一次超时时间点
按分桶策略分开存放,isClosing 检测到超时
状态:connecting connected reconnecting reconnected close
SessionTracker 会话的创建 管理 清理
- sessionWithTimeout:concurrentHashMap 管理超时时间
- sessionById:hashMap 维护sessionid到session映射
- sessionSets:hashMap 会话超时后归档,恢复和管理
据expiractionTime = currentTime+sessionTimeout 将session分桶管理,安装一定间隔定期检查
客户端读写可改session的超时时间,分桶迁移;没有读写请求 发送ping心跳链接 否则清除
会话清理:
isClosing关闭,无法处理新请求;会话关闭且同步集群
收集需清理的临时节点,先获取内存中临时节点集,有删除请求则移除;与创建请求则提添加
添加删除事务,节点删除事务添加到outstandingChanges中,触发watch
删除临时节点 移除会话 关闭连接
连接端口客户端重连,session未过期,重新变成connected
时间超sessionTimeout 会话清理工作,客户端才恢复连接,收到state为expired的watchedEvent,断开与服务器连接,反正就是过期了 不搭理了 后悔去吧
重连:断开后更新服务器链接,reconnecting 将会话迁移到新连接到服务器上
命名服务
指定名字获取资源或服务地址,zk创建全局唯一的路径,路径可作为名字
机器 服务地址 远程对象 据特定名字获取资源的实体 服务地址 提供者信息
配置管理
配置信息保存到znode,改变时watcher通知
集群管理
监控和控制,机器挂了 对应临时目录删除 被感知
应用场景
发布/订阅:配置中心
负载均衡:提供服务者列表
命名服务:服务名到服务地址映射
分布式协调/通知:watch机制和临时节点,任务进度
集群管理:临时节点 加入 退出
分布式锁:思想
创建锁节点 下一个个 临时顺序节点
自己不是第一个,监听上一个节点
上一个释放锁,自己排到前面,排队机制
分布式队列:
eureka:区别
本质java服务;用于服务注册发现;各节点平等,客户端如果连接失败 自动切换其他节点
euraka发现85%以上服务没有心跳,先自省:自己网络出现问题,不再进行内容同步
eurekaClient客户端(需要注册到eureka上的服务)会缓存服务信息
EurekaAutoServiceRegistration类的start完成注册,本身是一个bean
状态页和健康检查 eureka.client.healthcheck.enabled=true
Actuator监视器,监控中心,调用shutdown方法实现优雅关机
版权归原作者 星辰_mya 所有, 如有侵权,请联系我们删除。