
来自微信公众号:车端软件开发,大佬讲的很好,在此整理补充做个笔记
QNX介绍
** QNX成立于1980年,是全世界第一个类UNIX的符合POSIX标准的微内核的硬实时操作系统**,在过去的几十年中广泛的应用在汽车、工业自动化、国防、航空航天、医疗、核电和通信等领域,提供以嵌入式操作系统为核心的中间件和基础软件解决方案。
到目前为止,世界上几乎所有的主机厂都采用了基于QNX操作系统的软件技术。**全球top 25家电动汽车厂家,其中24家在使用QNX的软件操作系统**,例如,中国的小鹏汽车自动辅助驾驶系统Xpilot3.0和Xpilot3.5基于QNX通过TUV莱茵ISO26262 ASIL D功能安全的硬实操作系统,合众新能源汽车的哪吒S采用QNX Hypervisor打造其全新科技感智能座舱,并在其全栈自研的TA PILOT 3.0智能驾驶系统中搭载QNX OS for Safety操作系统,实现多种场景下的智能辅助驾驶,又如零跑汽车在其量产的第三代高端纯电SUV—零跑C11和智能纯电桥车C01中均采用了QNX Neutrino实时操作系统和QNX Hypervisor,旨在为中国消费者带来更个性化与舒适的驾驶体验。除此之外,高合即将发布的豪华纯电超跑HiPhi Z的自动辅助驾驶平台使用的是英伟达Orin-X芯片和 QNX 嵌入式硬实时操作系统。
QNX特点
QNX是嵌入式硬实时的微内核操作系统
有硬实时、微内核、模块化、弱耦合、分布式的特点,从1980年诞生之初就是基于SOA架构设计,基于Client-Server的模型,具体表现为:
- 硬实时:任何切换时间和中断时延速度快,所有的任务响应均为确定性deterministic行为。
- 微内核:除调度、进程管理、中断及操作系统核心的功能外,其余部分都处于用户态,包括驱动、协议栈、文件系统及功能模块等。
- 模块化:操作系统的各个功能单元都模块化设计,内存保护,并且相互隔离,可按照需要动态加载或卸载,基于消息机制通信,按照Client-Server的架构设计。
- 弱耦合:模块与模块之间互不影响,都在独立的虚拟地址空间运行。
- 分布式:局域网内的QNX系统对于用户角度可以认为是一台QNX系统,资源可以复用。
微内核则和宏内核结构相反,它提倡内核中的功能模块尽可能的少。内核只提供最核心的功能,比如任务调度,中断处理等等。其他实际的模块功能如进程管理、存储器管理、文件管理……这些则被移出内核,变成一个个服务进程,和用户进程同等级,只是它们是一种特殊的用户进程。
QNX是类UNIX操作系统
遵循POSIX的最高级别PSE54标准(注:POSIX标准有四个等级PSE51, PSE52, PSE53和 PSE54, 在RTOS实时操作系统的世界里,只有QNX操作系统是PSE54标准的,因为QNX诞生之初就是类UNIX系统按照POSIX标准编写),因此基于开源的应用程序以及一些开源的中间件都可以无缝的移植到QNX系统之上。QNX Microkernel和Process Manager组成QNX最小系统Procnto,其他如驱动程序、协议栈、文件系统、应用程序都作为一个独立的模块运行在QNX系统之上。
POSIX(Portable Operating System Interface,**可移植操作系统接口**)是一个IEEE标准,旨在提高各种UNIX操作系统上运行的软件的可移植性和兼容性。它**定义了操作系统应该为应用程序提供的接口标准**,使得遵循POSIX标准的软件能够在不同的操作系统上运行,而无需进行大量的修改。 POSIX标准有四个等级:PSE51、PSE52、PSE53和PSE54。这些等级代表了不同的兼容性和功能级别,其中PSE54是最高级别。在RTOS(实时操作系统)的世界中,QNX操作系统是唯一一个符合PSE54标准的系统。这是因为QNX从诞生之初就是基于类UNIX系统并按照POSIX标准编写的,因此它具有高度的兼容性和可移植性。遵循POSIX最高标准(PSE54)意味着QNX操作系统完全遵循了POSIX定义的所有接口和功能要求。这使得基于开源的应用程序以及一些开源的中间件,只要它们也遵循POSIX标准,就可以无缝地移植到QNX系统之上。换句话说,这些应用程序和中间件无需进行大量的修改或重新编写,就可以直接在QNX系统上运行,从而大大简化了移植过程并提高了效率。
QNX Microkernel和Process Manager组成QNX的最小系统Procnto,为系统提供了基本的内核和进程管理功能。其他如驱动程序、协议栈、文件系统、应用程序等都作为独立的模块运行在QNX系统之上。这种模块化设计使得QNX系统非常灵活和可扩展,可以根据不同的需求添加或删除模块。
总的来说,POSIX最高标准(PSE54)为QNX操作系统提供了高度的兼容性和可移植性,使得基于POSIX标准的应用程序和中间件可以无缝地移植到QNX系统上。这种特性使得QNX在RTOS领域具有独特的优势,能够满足各种复杂的实时应用需求。
QNX是功能安全和信息安全的操作系统
QNX通过功能安全TUV莱茵ISO 26262 ASIL D最高等级道路车辆最高功能等级安全认证,包括QNX 操作系统、QNX Hypervisor虚拟化和Graphic Monitor图形监控子系统以及QNX IPC通讯机制black channel,同时黑莓是网络信息安全标准ISO/SAE 21434 委员会基础软件组唯一成员。
QNX其他特性
1. QNX调度算法及策略
QNX调度算法有很多种,本质上基于优先级抢占式。QNX的线程优先级是一个0-255的数字,数字越大优先级越高。在QNX上有三种基本调度策略,可以单独使用也可以组合使用,包括基于时间片轮询Round Robin、优先级抢占式FIFO和基于时间Budget的Sporadic算法。同时QNX还提供APS自适应分区调度算法,在CPU满负荷的场景下保证低优先级的任务有调度的机会,不被“饿死”。
2. QNX IPC通讯机制
QNX除了支持Native的IPC机制如Massage passing、Signal等,同时还提供POSIX标准的IPC例如MessageQ、Piple、Shared Memory等IPC通讯方式,多种IPC方式供用户在不同的应用场景下进行选择。
3. QNX 的IDE集成开发环境
QNX提供基于Eclipse的Momentics IDE集成开发环境,供用户进行基于以太网Software GDB的代码级的编译调试或系统性能分析,可实时以图形化的方式,查看进程资源、系统日志、CPU占用情况,内存使用情况,进程间通信以及Coredump等。
中国自动辅助驾驶领域基础平台软件所遇到的问题
近年来自动辅助驾驶领域非常火爆,许多国内外的主机厂都逐步在量产项目中开发以及发布L2+的功能,当我们回顾这几年来快速发展会发现,大多数的自动辅助驾驶的人才都来自于Robotaxi,自动驾驶算法初创公司或大学研究机构,特别是算法人才。这就有个显著的特点,在这些公司里面的大多数项目,最初都是基于工控机+英伟达显卡(大多数用英伟达的GPU,少数用AMD的)+开源的操作系统+来自于开源的算法,其实和汽车电子的安全性本身毫无关系,唯一的好处就是快,容易尽早演示,尽快融资。
这些算法人才加入主机厂之后,更倾向于用以前最熟悉的开发方式,这样好尽快的出演示成果,也就是英伟达的SOC+开源的操作系统+来自于开源的算法。另一方面,在自动辅助驾驶项目中,一般主机厂会把控制器平台即硬件和平台软件外包给外部的Tier1来做,类似于一台PC电脑,而自己开发应用和算法。
一般主机厂也有平台组,负责部分的驱动及驱动以上的中间件的整合,系统组负责系统设计统筹,功能安全团队负责整体的功能安全,而算法团队负责算法应用的开发和实现,那么问题就来了,除纯算法团队外,一般国外的主机厂都会有一个成建制的叫算法嵌入式工程实现的团队,负责算法在非工控机的嵌入式环境和实时操作系统的优化实现落地,这样的团队即要懂一点算法架构,又要懂嵌入式软件的开发和硬件特性,又要对操作系统有足够的理解。
而在中国的许多主机厂,没有看到有这样一个团队,甚至这样的人才存在。因此不少项目由于开发周期紧,人员不具备嵌入式系统开发的经验,会采用更接近于robotaxi的方式开发,即英伟达SOC中的处理器(类似工控机),SOC中的GPU(类似显卡)和开源操作系统+未经优化的各种开源算法,在满足基本功能和有限性能的前提下,功能安全团队的建议通常会被直接忽略,因为要满足极短的量产时间,在国内主机厂军备竞赛中领先才是最重要的,这在欧美的主机厂是不可想象的。在这一点上,中国也有许多人才储备充足并且付责任的主机厂做的非常好,特别是有专门的经验丰富的算法工程实现的团队负责优化落地。期待在不久的将来,能够有更多的主机厂重视起这个问题,在中国有更多的行业人才能够填补这一空白。
QNX算法移植以及性能优化举例
QNX提供ADAS reference平台产品,里面涵盖了Sensor Framework,networking,open source modules,第三方的SDK以及一些参考设计,其中sensor Framework提供了ADAS的一些基本库。
算法移植
自动辅助驾驶以开源的算法居多,由于QNX符合POSIX PSE54标准,API兼容基本一致,因此各类开源算法可以很方便的移植到QNX的平台上,使用QNX的工具链进行编译并运行,但是虽然API是一致的,但由于实时操作系统的特性,表现的行为会有所差异,需要对系统进行优化调整。
QNX有专门的team来根据roadmap以及客户需求移植一些开源软件,比如ROS/ROS2,比如OpenCV和vSomeIP,我们也会负责后期的维护。
分享常见的QNX性能优化项
IPC优化
QNX支持绝大部分主流POSIX系统常见的IPC方式,同时也有其独特的原生IPC方式,Message-passing。在自动辅助驾驶方案设计中,常有公司会将UDS、DDS做为软件通信总线的架构方案原封不动地从Linux照搬到QNX上。从功能上看,这样的跨平台方案可以使得代码重用并且功能没有区别。但从性能角度考虑,由于QNX独特内核架构,这并不是高效的解决方案。不同于Linux的宏内核架构,QNX为了安全性和实时性采用了微内核架构,绝大部分的系统服务,比如网络协议栈,它是完全运行在内核之外以服务(Resource Manager)的方式运行。如果采用UDS(Unix Domain Socket)这用基于网络服务(严格意义上讲,UDS并不需要经过网络协议栈,但也是需要经过QNX的网络服务io-pkt支持)的通讯方式,那么所有的数据报都需要经过网络服务中转,相比直接通讯多了一次IPC,这就带来了系统资源的浪费。建议的优化方案是采用更高效的IPC方式,一般情况下,中小量的数据量传输建议使用message-passing,特别大的数量使用shared memory方式。另外,一些开源软件也会大量使用FIFO,PIPE等IPC,尽管QNX支持这类使用,但是我们也建议改成更高效的message passing方式,以减少单次IPC的开销。
IPC(Inter-Process Communication,进程间通信)是操作系统中不同进程之间共享信息和通信的机制。在自动辅助驾驶方案设计中,IPC的性能优化对于确保系统的实时性和效率至关重要。 QNX操作系统支持多种主流的POSIX系统常见的IPC方式,如Unix Domain Socket(UDS)、DDS等。同时,它还有自己独特的原生IPC方式,即消息传递(Message-passing)。在跨平台方案设计中,尽管将UDS、DDS等从Linux照搬到QNX上可以实现代码重用和功能无差异,但从性能角度来看,这并不是最优的选择。 针对IPC的优化,建议在QNX中采用更高效的通信方式。对于中小量的数据量传输,建议使用message-passing方式。Message-passing是QNX原生支持的IPC方式,具有高效、灵活的特点,能够减少单次IPC的开销。对于特别大的数据量传输,则建议使用共享内存(Shared Memory)方式。共享内存允许不同进程直接访问同一块内存区域,从而实现高效的数据共享和通信。 此外,尽管QNX支持FIFO、PIPE等IPC方式,但在实际应用中,也建议将这些方式替换为更高效的message passing方式。这样可以进一步减少单次IPC的开销,提高系统的整体性能。
编译选项优化
QNX采用GCC的框架,出于安全性的考虑,QNX的编译器版本更新相比没有开源社区激进,相比会慢一些。比如SDP 7.0采用的是GCC 5.4.0,SPD 7.1采用的GCC 8.3.0,即将推出的SDP Moun会采用GCC 11.X。有时候会发现,运行同样一个算法库,QNX性能会比开源低,那很有可能是由于编译版本或编译优化选项差异的原因。因为在Linux系统上默认的ARMv8的编译优化选项是满级的,而QNX默认不打开ARMv8的优化选项,因此程序编译时候需要打开相关编译选项才能获得最佳性能,因为QNX基于安全性考虑某些编译选项在默认编译的时候并没有打开会导致性能问题。
QNX采用GCC的编译框架,意味着其源代码通过GCC(GNU Compiler Collection)进行编译,生成可执行文件。GCC是一个广泛使用的开源编译器,支持多种编程语言和平台。
驱动级别优化
如网络/存储设备驱动,根据以往的经验,大部分的性能问题的瓶颈在设备驱动这层。特别是新的硬件、新的驱动,要注意根据QNX系统服务层做好适配,驱动的好坏,往往是除硬件本身之外最主要的性能影响因素。我们遇到非常多的来自驱动层面的空等,忙等,最终导致系统机能的冗余浪费。
网络协议栈优化
除了网络驱动的优化,QNX的网络协议栈io-pkt本身也提供了丰富的参数,可以根据具体使用的应用场景来达到性能的最优化。另外,使用QNX SDP 7.1及后续版本的用户,可以使用最新的版本网络协议栈io-sock,它对多核CPU的利用和大并发小包数据的处理能力有显著地提升。两个协议栈各有千秋,实际上大量的案例证明,用户并没有达到io-pkt的性能瓶颈,socket buffer 不足导致丢包,typed memory pool分配的不够导致收发阻塞等等,这些都可以通过配置以及API层面的优化达到性能提升。
系统API优化
如memory allocation,memory copy等,QNX提供jemalloc根据实际应用场景提供额外内存泄漏手段,提供更多的功能,jemalloc比default的malloc效率更高,特别是对于大量线程高并发调用的场景。
用户接口优化
QNX 提供的底层接口,尤其是一些自有API,是有不少细微差别的,比如sendmsg()和sendmmsg(), 用户往往会比较熟悉前者,用于socket的发包,但是后者提供了message 队列来实现不增加IPC的基础上提高了整体的吞吐率。又比如mmap(),我们提供了一些QNX独有的flag来应对不同的memory mapping 场景,如MAP_ANON与MAP_PHYS的配合,才代表申请物理连续memory region而MAP_LAZY 更会延迟内存的申请分配。了解并熟悉每个接口的参数配置以及相近命名接口的应用场景会对开发帮助很大。
QNX提供Momentics IDE环境对算法进行性能分析
如memory leak,application profile等,同时提供kernel trace进行分析,在抓取的时间段中可以获得每个时间点的事件、中断响应,给出优化建议。我们也支持自定义的kernel 事件,来让用户可以精确的了解代码片段的运行情况。
QNX提供了onboard debug也支持应用程序调用栈的实时保存及相应的GDB,在调查一些忙等的现场会有很大的帮助。
最后总结一下,**即便作为ISO26262 ASIL-D安全认证的硬实时性操作系统,QNX在系统性能上也并没有落后宏内核系统。只要合理地使用和优化,它的性能表现同样非常优秀,同时占用更低系统资源。QNX有着丰富的算法移植和优化经验能给到用户,同时QNX提供一系列的手段和工具去定位算法性能的瓶颈。 **
QNX调度算法
作为一个硬实时操作系统,QNX是一个基于优先级抢占的系统。这也导致其基本调度算法相对比较简单。因为不需要像别的通用操作系统考虑一些复杂的“公平性”,只需要保证“优先级最高的线程最优先得到 CPU”就可以了。
基本调度算法
调度算法,是基于优先级的。QNX的线程优先级,是一个0-255的数字,数字越大优先级越高。所以,优先级0是内核中的idle线程。同时,优先级64是一个分界岭。就是说,优先级1 – 63 是非特权优先级,一般用户都可以用,而64 – 255必须是有root权限的线程才以设。这个“优先级64”分界线,如果有必要,还可以通过启动Procnto时传 –P <priority> 来改变。
内核中的idle线程是Linux系统在初始化时为每个CPU创建的一个线程。idle线程的目的是在不影响性能的前提下,尽可能减少功耗。一般来说,idle线程的优先级被设置为很低,这是因为它只在没有其他进程需要运行时才运行,用以降低功耗
调度算法的对像是线程,而线程在QNX上,有大约20个状态。(参考 /usr/include/sys/states.h)在这许多状态中,跟调度有关的,其实只有 STATE_RUNNING和STATE_READY两个状态。STATE_RUNNING是线程当前正在使用CPU,而STATE_READY是等着被执行(被调度)的线程。其他状态的线程,处于某种“阻塞”状态中,调度算法不需要关注。
所以在调度算法看来,整个系统里的线程像这样:

图 1 有两个CPU的系统里的线程
这是一个有两个CPU的系统,所以可以看到有两个RUNNING线程;对于 BLOCK THREAD,它们不参于调度,所以不需要考虑它们的优先级。
调度策略
在QNX上实质上只有三种基本调度策略,“轮询”(Round Robin),“先进先出”(First in first out)和"零星调度”(Sporadic) 算法。虽然形式上还有一个“其他”,但“其他”跟“轮询”是一样的。这些调度策略,在 /usr/include/sched.h 里有定义。(SCHED_FIFO, SCHED_RR, SCHED_SPORADIC, SCHED_OTHER)
先进先出(FIFO)
在FIFO策略中,一个线程可以一直占用CPU,直到它执行完。这意味着如果一个线程正在做一个非常长的数学计算而且没有其他更高优先级的线程就绪,这个线程就会一直执行下去。拥有相同优先级的线程会怎么样呢?它们会一直等待,当然更低优先级的线程也得不到执行。如果运行中的线程退出或者自愿放弃CPU的使用权,此时内核会寻找其他拥有相同优先级的就绪线程。如果没有这样的线程,内核会继续寻找更低优先级的就绪线程。自愿放弃CPU有以下两种情况。如果线程进入sleep,或被信号量阻塞,此时更低优先级的线程可以运行。另外一个是一个系统调用sched_yield(),仅仅让渡CPU给相同优先级的线程。如果一个线程调用了sched_yield(),而且没有相同优先级的线程就绪,此时会继续执行调用sched_yield()的线程。
轮询(Round Robin)
Round Robin的调度策略和FIFO类似,但是如果有相同优先级的线程就绪的话,当前线程不会永远执行下去。当前线程只执行一个系统定义好的时间片的时长,时间片的长度可以使用函数sched_rr_get_interval()获取。时间片的长度通常是4ms,不过实际上是ticksize的4倍,ticksize的值可以通过ClockPeriod()查询。
内核启动一个RR线程的时候会开始计时,RR线程运行一段时间后分配给它的时间片将会用完。此时内核会检查是否有**相同优先级的线程处于就绪状态**,如果有,内核会让该线程开始执行,否则内核会继续让之前的线程执行并会再分配一个时间片给该线程。
强调一下,调度策略只限于在READY队列里的线程,**优线级最高的线程有不止一个时**,才会用到。如果线程不再 READY,或是有别的更高优先级的线程 READY了,那就高优先级线程获取CPU,没有什么策略可言。
“轮询调度”(Round Robin)跟平时生活里排队的情形差不多,晚到的人排在队尾,早到的人排在队首,等到叫号(调度)的时候,队首的人会被先叫到 。如下图所示:
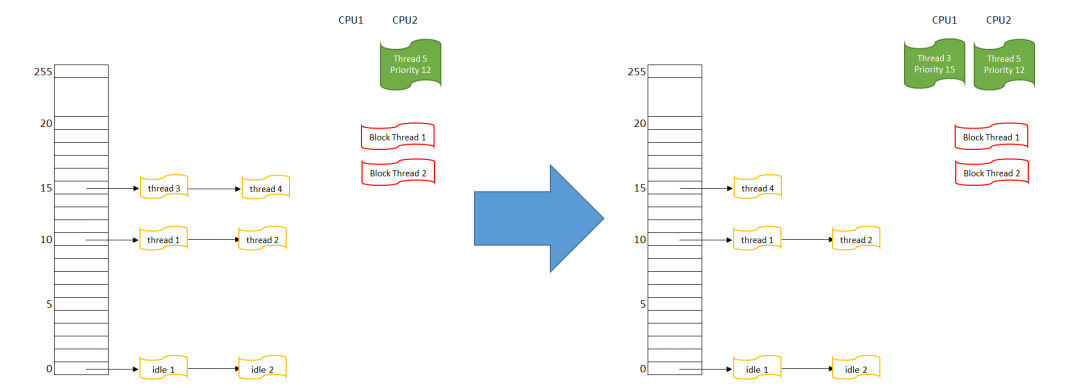
图 2 论询调度示意
- 首先在CPU 1上运行的线程4,被挪入优先级15的队列末尾
- 然后重新搜索可执行的最高优先级线程,这里有优先级15队列上的线程3和4
- 线程3因为在队列最前端,它被选择得到CPU,线程3的状态变为RUNNING,在CPU1上执行
可以预期,当下一次调度发生时,线程3会被挪入优先级15队列末尾,而线程4会被调度执行,这样线程3和4会分别得到CPU1.
“先进先出”(First in first out)调度则刚好相反,后来的人插在队首,然后在叫号的时候被先叫到。看下图:
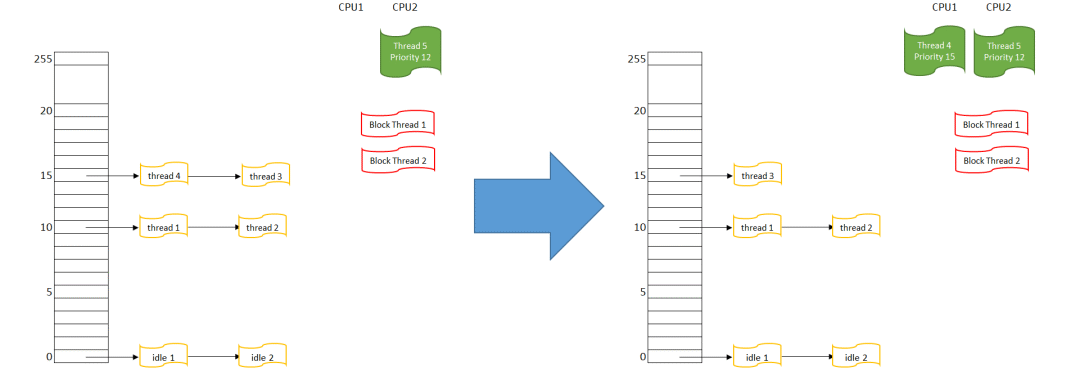
图 3 先进先出调度示意
- 首先在CPU 1上运行的线程4,被挪入优先级15的队列队首
- 然后重新搜索可执行的最高优先级线程,这里有优先级15队列上的线程4和3
- 线程4因为在队列最前端,它被选择得到CPU,线程4的状态变为RUNNING,在CPU1上执行
可以看到,在这个调度算法下,如果没有别的状态发生,事实上线程4就会一直占据CPU1。
如果在优先级15上的线程3和线程4都是FIFO会怎样?按上面的描述,线程3还是始终无法获得CPU1,因为线程4每次都会插在3的前面,再调度就又是4获得CPU1。除非线层4进入了阻塞状态(从而不在READY队列里了),那么线程3才能获得CPU。
零星调度(Sporadic)
“零星调度”(Sporadic)算法比较特殊,它比较适合长时间占用CPU的线程。它的基本设计思想是给一个线程准备两个优先级,“前台”优先级比较高,“后台”优先级稍微底一点。如果线程在高优先级连续占用CPU超过一定时间后,线程会被强行降到“后台”低优先级上(这时线程能不能占用CPU取决于系统中有没有比“后台”优先级高的别的线程了);然后线程在低优先级上经过了一段时间后,会重新被调回高优先级。
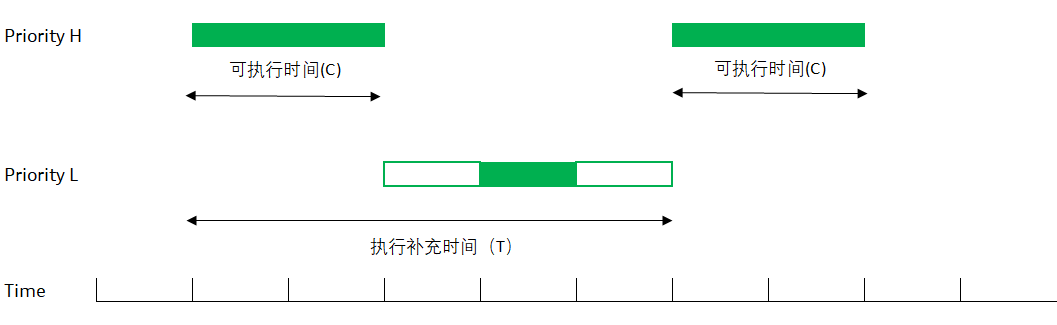
图 4 零星调度示意
上图是一个零星调度线程的示意。
- 开始的时候,线程在比较高的(正常)优先级 H 上运行,一直到把预先分配给零星调度的时间用完(sched_ss_init_budget)
- 这时,线程会被自动调整为低优先级L(sched_ss_low_priority);一旦被调低,线程也可能运行(如果优先级L依然是系统里最高优先级的线程),也可能无法运行呆在READY队列里(系统里有比L更高的优先级)
- 不管线程有没有执行,从最开始运行时间点算起,当线程“执行补充时间"(sched_ss_repl_period)过了以后,线程的优先级被重新提到优先级H,并试图取得CPU来。
“零星调度”看上去比较“公平”,但是实际在用QNX的项目中,这个调度算法很少被用户用到。主要是因为一般来说在QNX上很少有线程能够“连续占用CPU”的。而且当系统变得复杂,线程数成百上千后,这种上下调优先级的做法,很容易出现别的后遗症。
什么时候会发生调度?
上面介绍了QNX支持的几个调度算法。那么,什么时候才会发生调度呢?
QNX的设计目标是一个硬实时操作系统,所以,保证最高优先级的线程在第一时间占据CPU是很重要的。考虑到线程的状态都是在内核中进行变化的(都是因为线程进行了某个内核调用后变化的),所以QNX在每次从内核调用退出时,都会进行一次线程调度,以保证最高优先级的线程可以占据CPU。
得益于微内核结构,QNX的内核调用通常都非常短,或者说,每一个内核调用,都能够比较确定地知道要花多少时间。而且,因为微内核系统的基本就是进程间通信,所以在QNX上,一段程序非常容易进入内核并进行线程状态切换,很少能有长时间占满CPU的,在实际系统上测,现实上很少能有线程执行完整个时间片的。
举个例子,哪怕程序里只写一个 printf("Hello World!\n"); 可是在libc库里,最后这个会变成一个IO_WRITE消息,MsgSend() 给控制台驱动;这时,在MsgSend()这个内核调用里,会把printf() 的线程置为阻塞状态(REPLY BLOCK),同时会把控制台驱动的信息接收线程(从RECEIVE BLOCK)改到 READY状态,并放入 READY 队列。当退出MsgSend() 内核调用时,线程调度发生,通常情况下(如果没有别的线程READY 的话)控制台驱动的信息接收线程被激活,并占据CPU.
如果用户写了一个既不内核调用,也不放弃CPU的线程会怎么样?那时候,时钟中断会发生,当内核记时到线程占据了一整个时间片(QNX上是4ms)后,内核会强制当前线程进入 READY,并重新调度。如果同一优先级只有这一个线程(这是优先级最高线程),那么调度后,还是这个线程获取CPU。如果同一优先级有别的线程存在,那么根据调度算法来决定哪个线程获得CPU。
另一种常见情况是,由于某些别的原因导致高优先级线程被激活,比如网卡驱动中断导致高优先级驱动线程READY,所设时钟到达导致高优先级线程从阻塞状态返回READY状态了,当前线程开放互斥锁之类的线程同步对象,导致别的线程返回READY状态了。这些,都会在从内核调用退出时,进行调度。
中断与优先级
上面提到如果用户线程长期占有CPU,时钟中断会打断用户线程。细心的读者或许会有疑问,那中断的优先级是多少呢?
答案是在QNX这样的实时操作系统里,**“硬件中断”永远高于任何线程优先级**,哪怕你的线程优先级到了255,只要有中断发生,都要让路,CPU会跳转去执行中断处理程序,执行完了再回归用户线程。事实上,**能够快速稳定地响应中断处理,是一个实时操作系统的硬指标**。
我们这里说的是“硬件中断”,就是说,当外部设备,通过中断控制器,向CPU发出中断请求时,无论当时CPU上执行的线程优先级是什么,都会先跳转到内核的中断处理程序;中断处理程序会去中断控制器找到具体是哪一个源发生了中断(中断号),并据此,跳转到该中断号的中断处理程序(通常是硬件驱动程序 通过 InterruptAttach() 挂接的函数)**。在这个过程中,如果当前CPU正在处理另一个中断,那么这时,会根据中断的优先级来决定是让CPU继续处理下去(当前中断进入等待);或者发生中断抢占,新中断的优先级比旧中断高,所以跳转新中断处理。**
当然,实际应用中,特别是微内核环境下,考虑中断其实只是中断设备给出的一个通知,对这中断的响应并不需要真的在中断处理中进行,驱动程序可以选择在普通线程中处理,QNX上有InterruptAttachEvent() 就是为了这个设计的。通常这里的“事件”会是一个“脉冲”,也就是说,当硬件中断发生,内核检查到相应中断绑定了事件。这时,不会跳转到用户中断处理程序,而是直接发出那个脉冲,以激活一个外部(驱动器中)线程,在这线程中,做设备中断所需要的处理。这样做,虽然稍微增加了一些中断延迟,但也带来了不少好处。首先,这个外部线程同普通的用户线程一样,所以可以调用任何库函数,而中断服务程序因为执行环境的不同,有好多限制。其次,因为是普通用户线程,就可以用线程调度的方法规定其优先级(脉冲事件是带优先级的),使不同的设备中断处理,跟正常业务逻辑更好地一起使用。
在QNX这样的微内核环境下,中断处理的方式确实有其独特之处。首先,我们要明确中断本质上只是设备向系统发出的一种通知,告知系统某个特定事件已经发生,需要相应的处理。但并不意味着中断处理必须在中断发生的即时上下文中完成。 QNX提供的InterruptAttachEvent()机制允许驱动程序选择在一个普通的用户线程中处理中断,而不是传统的在中断服务程序中直接处理。这种设计思路有几个关键的优势。
首先,当硬件中断发生时,内核会检测到相应的中断,并检查是否有与该中断绑定的事件(通常是一个“脉冲”)。此时,内核不会直接跳转到用户的中断处理程序,而是发出这个脉冲。这个脉冲的作用类似于一个信号,用于激活一个在驱动程序中定义的外部线程。这个外部线程随后会执行设备中断所需要的处理逻辑。
这样做虽然可能稍微增加了一些中断的延迟,但带来的好处是显著的。由于这个外部线程是一个普通的用户线程,它拥有与普通用户线程相同的执行环境和能力。这意味着它可以调用任何库函数,使用任何可用的系统资源,而不会受到中断服务程序通常存在的诸多限制。 此外,由于它是一个普通的用户线程,我们可以使用线程调度的方法来规定其优先级。这意味着不同的设备中断处理可以根据需要设置不同的优先级,从而更好地与正常的业务逻辑协同工作。例如,对于实时性要求较高的设备中断,我们可以将其处理线程的优先级设置得较高,以确保其得到及时响应。
多CPU上的线程调度
现在同步多处理器(SMP)已经相当普及了。在SMP上,也就是说当有多个CPU时,我们的调度算法有什么变化呢?比如一个有2个CPU的系统,首先肯定,系统上可执行线程中的最高优先级线程,一定在2个CPU上的某一个上执行;那,是不是第二高优先级的线程就在另一个CPU上执行呢?
虽然直觉上我们觉得应该是这样的(系统里的第一,第二高优先级的线程占据CPU1和CPU2),但事实上,第二高优先级的线程占据CPU2这件事,并不是必要的。实时抢占系统的要求是最高优先级”必须“能够抢占CPU,但对第二高优先级并没有规定。拿我们最开始的双CPU图再看一眼。
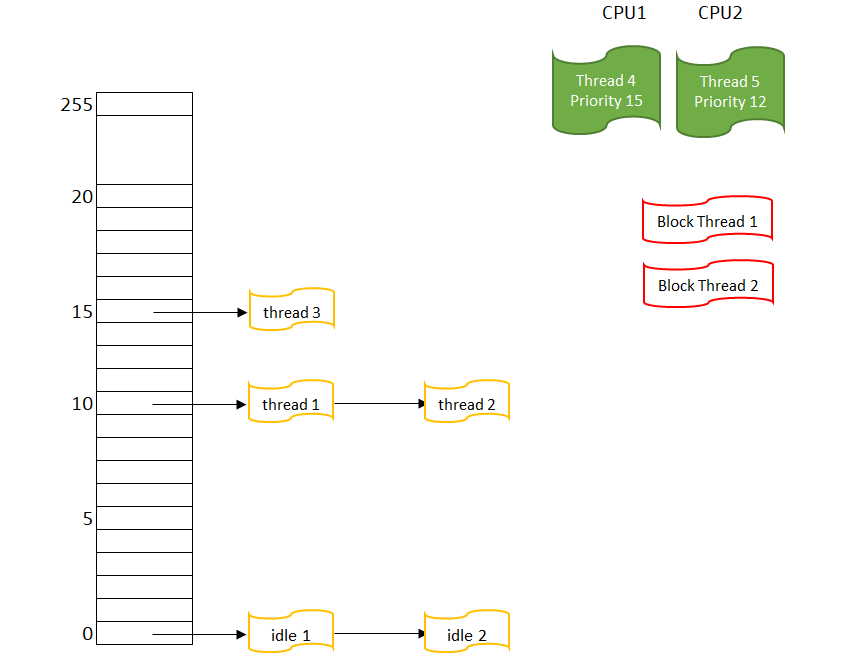
图 5 有两个CPU的系统里的线程
线程4以优先级15占据CPU1这是毫无疑问的,但线程5只有优先级12,为什么它可以占据CPU2,而线程3明明也有优先级15,但只能排队等候,这是不是优先级倒置了?其实并没有,如上所述,系统确实保证了“最高优先级占据CPU”的要求,但在CPU2上执行什么线程,除了线程本身的优先级以外,还有一些别的因素可以权衡,其中一个在SMP上比较重要的,就是“线程跃迁”。
“线程跃迁”指的是一个线程,一会儿在CPU1上执行,一会儿在CPU2上执行。在SMP系统上,线程跃迁而导致的缓存清除与重置,会给系统性能带来很大的影响。所以在线程调度时,尽量把线程调度到上次执行时用的CPU,是SMP调度算法里比较重要的一环。上述例子中,很有可能就是线程3上一次是在CPU1上执行的,而线程5虽然优先级比较低,很有可能上一次就是在CPU2上执行的。
实际应用中,因为QNX的易于阻塞的特性,其实大多数情况下,还是符合“第一,第二高优先级线程在CPU上执行”的。只是,如果你观察到了上述情形,也不需要担心,设计上确实有可能不是第二高优先级的线程在运行。
另一个多处理器上常见的应用,是线程绑定。在正常情况下,把可执行线程调度到哪一个CPU上,是由操作系统完成的。当然操作系统会考虑“线程跃迁”等情形来做决定。但是,QNX的用户也可以把线程绑定到某一个(或者某几个)CPU上,这样操作系统在调度时,会考虑用户的要求来进行。绑定是通过ThreadCtl() 修改线程的 “RUNMASK” 来进行的,如果你有0,1,2,3 总共4个CPU,那么 0x00000003意味着线程可以在CPU0和CPU1上执行,具体例子可以参考ThreadCtl()函数说明。更简单的办法,是通过QNX特有的 on 命令的 –C 参数来指定,这个指定的 runmask,还会自动继承。所以你可以简单的如下执行:
# on –C 0x00000003 Navigation &
# on –C 0x00000004 Media &
# on –C 0x00000008 System &
这样来把不同的系统部署到不同的CPU上。
这样做的好处当然是可以减少比如因为系统繁忙而对导航带来的影响,但不要忘了,另一面,如果所有 Media 线程都处于阻塞状态,上述绑定也限制了导航线程使用CPU2的可能,CPU2这时候就会空转(执行内核 idle 线程)。
自适应分区调度算法
前面我们提到过,在讨论优先级调度时,只是讨论当有多个优先级相同的线程时,系统怎样取舍。优先级不一样时,肯定是优先级高的赢。但是“高出多少”并不是一个考量因素。两个线程,一个优先级10,另一个优先级11的情况,和一个10,另一个40的情况是一样的。并不会因为10和40差距比较大而有什么不同。
假如我们有红蓝两个线程,它们的优先级一样,调度策略是RR,两个线程都不阻塞,那么在10时间片的区间里,我们看到的就是这样一个执行结果:

也就是说,各占了50%的CPU。但只要把蓝色线程提高哪怕1,执行结果就成了下面这样。

这种“非黑即白”的情形,是实时系统的基本要求(高优先级抢占CPU)。但是当然,现实情况有时候比较复杂。比如 “HMI渲染” 是需要经常占据CPU的一个任务(这样画面才会顺畅),但“用户输入”也是需要响应比较快的(不然用户的点击就会没有反应)。如果“用户输入”的优先级太高的话,那用户拖拽时,画面就会卡顿甚至没有反应?反之,如果”HMI 渲染“的优先级太高,那么有用户输入时,因为处理程序优先级低而造成用户输入反应慢。通常情况下,需要有经验的系统工程师不断调整这两个任务的优先级(因为优先级继承与传统,一个任务可能涉及到多个线程),来达到系统的最优。那么,有没有别的办法呢?
分区调度
传统上,有一种“分区调度”的方法,今天还有一些Hypervisor采取这个办法。这个想法很简单,就是把CPU算力隔成几个分区,比如70%,30%这样,然后把不同线程分到这些分区里,当分区里的CPU预算被用完以后,那个分区里所有可执行线程都会被”停住“,直到预算恢复。
假设我们把红线程放入70%红色分区,蓝线程放入30%蓝色分区,然后以10个时间片为预算滑动窗口大小,各线程具体就会如下图占据CPU:

图 6 分区调度算力全满示意
在前6个时间片中,蓝红分区分别占据CPU,注意在第7个时间片时,虽然蓝分区中线程跟红分区中线程有相同的优先级,虽然调度策略是轮回,应该轮到蓝线程上了,但是因为蓝线程已经用完了10个时间片里的3个,所以系统没有执行蓝线程,而是继续让红线程占据CPU,一直到第8第9和第10个时间片结束。
10个时间片结束后,窗口向右滑动,这时我们等于又多了一个时间片的预算,在新的10个时间片中,蓝线程只占了两个(20%),这样,新的第11个时间片,就分给了蓝分区。
同理再滑动后,第12个时间片,分给红线程;一直到17个时间片时,同样的事情再度发生,蓝分区线程又用完了10个时间片里的3个,而被迫等待它的预算重新补充进来。
综上,在任意一个滑动窗口中,蓝色分区总是只占30%,而红色分区却占了70%。QNX的自适应分区调度,跟上面这个是类似的。只是传统的分区调度,有一个明显的弱点。
想一下这个情况,如果红线程因为某些情况被阻塞了,会发生什么呢?

图 7 分区调度算力有富余示意
对,蓝线程是唯一可执行线程,所以它一直占据CPU。但是,当3个时间片轮转之后,因为蓝分区只有30%的时间预算,它将不再占据CPU,而因为红线程无法执行,接下来的7个时间片CPU处于空转状态(执行Idle线程)。
一直到时间窗口移动,那时,因为蓝分区只占用了20%的算力,所以它再次占据CPU……
所以你也看到了,在传统的分区调度里,当一个分区的算力有富裕的时候,CPU就被浪费了。
自适应分区调度
QNX在传统的分区调度上,增加了“自适应”的部份。其基本思想是一样的,给算力加分区,然后把不同的线程分到分区里。这样,当所有的线程都忙起来时,你会发现情况跟图7是一样的。但是当分区算力有富裕时,“自适应“允许把多出来的算力”借“给需要更多算力的分区。

图 8 自适就分区算力有富裕示意
如上,当蓝色分区里的线程消耗完了他自己的分区预算后,自适应分区会把有富裕算力的红色分区的预算,借给蓝色分区,蓝分区内线程得以继续在CPU上运行。注意,在第8个时间片时,红色分区需要使用CPU,蓝色分区立即让路,把CPU让给红色分区。而当红色分区里的线程被阻塞住以后,蓝色分区线程继续使用CPU。
自适应分区似乎确实带来了好处,但是也带来了一些潜在的问题,需要在系统设计的时候做好决定。
自适应分区调度与线程优先级
你可能会好奇,在分区调度的系统里,线程的优先级代表了什么?
答案取决于各个分区对各自算力的消耗情况。我们假设蓝色分区里的线程优先级比较高,红色的优先级比较低,当两个分区都有预算时,内核会调度(所有分区里的)最高优先级线程执行。如果系统一直不是很忙,那么不论分区,永远是有最高优先级的线程得到CPU,这个,跟一个标准的实时操作系统是一致的。
当两个分区中某一个有预算时(意味着那个分区中所有的线程都不在执行状态),那么多出来的CPU算力会被分给另一个分区,另一个分区中的最高优先级线程(虽然用完了自己分区的预算,但得到了别的分区的算力),继续占据CPU。这个,也是跟实时操作系统是一致的。
比较特殊的情况是,当两个分区都没有预算,都需要占据CPU时,这时,蓝色线程虽然有较高的优先级,但因为分区算力(30%)被用完,面且没有别的算力可以“借”,所以它被留在READY队列中,而比它优先级低的红色线程得以占据CPU。
自适应分区调度富裕算力分配
我们上面的例子只有两个分区,考虑这样一个例子。假设我们现在有A (70%),B (20%),C (10%) 三个分区,A分区没有可执行线程,B分区有个优先级为10的线程,C分区有个优先级为20的线程。我们知道A分区的70%会分配给B和C,但具体是怎么分配的呢?
如上所述,当预算有富裕时,系统挑选所有分区中,优先级最高的线程执行,也就是说C分区中的线程得到运行。在一个窗口以后,你会发现A的CPU使用率是0%,B是20%,C则达到了80%。也就是说A所有的富裕算力,都给了C分区(因为C中的线程优先级高)。
也许,在某些时候,这个不是你所期望的。也许C中有一些第三方程序你无法控制,你也不希望他们偷偷提高优先级而占用全部富裕算力。QNX提供了SchedCtl()函数,可以设SCHED_APS_FREETIME_BY_RATIO 标志。设了这个标志后,富裕算力会按照各分区的预算比例分配给各分区。上面的例子下,最后的CPU使用率会变成 A 是0%, B是65%,而C是35%。A分区富裕的70%算力,按照大约 2: 1的比例,分给了分区B和C。
“关键线程”与“关键分区”
在实际使用中,有一些重要任务,可能需要响应,不论其所在的分区还有没有算力。比如一个紧急中断服务线程,不管分区是不是还有预算,都需要响应。为了解决这种情况,在QNX的自适应分区调度里,除了给分区分配算力预算以外,还允许有权限的用户为分区分配“关键响应时间”,并把特定线程定义为“关键线程”。
当一个“关键线程”需要执行时,如果线程所在分区有预算,它就直接使用所在分区预算就好,如同普通线程;如果所在分区没有预算了,但是别的分区还有预算,那么“自适应”部份会把别分区的预算拿过来,并用于关键线程,这个跟普通的自适应分区调度一样。
只有当系统里所有分区都没有预算了,而有一个关键线程需要运行,而且线程所在的分区已经预先分配了关键响应预算,那么线程允许“突破”分区的预算,使用“关键响应预算”来执行。在QNX里,一个关键线程消耗的时间,从退出RECEIVE_BLOCK开始,到下一次进入RECEIVE_BLOCK。而且,关键线程的属性是可传递的,如果关键线程在执行中,给别的线程发送了消息,那个线程也会变成关键线程。
总的来说,关键线程是用来保证关键任务不会因为系统太忙而无法取得CPU时间。即使所有的分区都被占满了,至少还有“关键响应时间”可供关键线程来使用。当然,一个系统里不应该有太多的关键线程和关键响应时间。理论上,假设所有的线程都是关键线程,那么整个系统其实就变成了一个普通的按优先级调度的实时系统,所有的分区和预算都不起作用了。
在最紧急的情况下,关键线程可以使用“关键响应时间”来完成它的任务。如果“关键响应时间”还是不够,会怎么样?这个是系统设计问题,在设计系统的时候,你就应该为关键线程分配它能够完成任务所需要的最大时间。如果依然发生“关键响应时间”不够的状况(被称为“破产”状态),这个就是一个设计错误了。
关键线程的破产
如上所述,关键线程的破产是一个设计问题。或者线程完成的任务并不那么“关键”,或者设计时给出的预算不够。这种情况下需要重新审视整个系统设计(因为系统在某些情况下无法保证关键任务在预定时间内完成)。QNX在自适应分区里提供了侦测到关键线程破产时的多种响应办法,可以是强行忽视,或者重启系统,或者由自适应分区系统自动调整分区的预算。
自适应分区继承
想像这个场景,文件系统在System分区里,但另一个Others分区里的第三方应用拼命调用文件系统,很有可能造成System分区的预算耗尽;这样,首先可能导致别的应用无法使用文件系统;更严重的,可能是System分区里别的系统,比如Audio也无法正常工作。这个,显然是自适应分区系统带来的安全隐患。
解决办法,就是跟优先级在消息传递上可以继承一样,分区也是可以继承的。文件系统虽然分配在System系统里,但根据它响应的是谁的请求,时间被记到请求服务的线程分区里。这样,如果一个第三方应用拼命调用文件系统,最多能做的,也只是消耗它自己的分区,当他自己分区的预算被耗尽时,影响它自己的CPU占用率。
自适应分区的小结
自适应分区有一些有趣的用法,比如我们常常被要求“系统需要保留30%的算力”。有了自适应分区,就可以建一个有30%预算的分区,在里面跑一个 for (;;); 这样的死循环。这样,剩下的系统就只有70%的算力了,可以在这个环境下检验一下系统的性能和稳定性。
自适应分区的具体操作方法,可以参考QNX的文档。不同版本的QNX有稍微不同的命令行,但基本设计是一样的。这篇文章只是介绍了自适应分区的基本概念,实际使用上,还是有许多细节需要考虑的,真的要使用,还是需要详细参考QNX对应文档。
版权归原作者 千天夜 所有, 如有侵权,请联系我们删除。