
- 首先,需要准备maven的环境配置,我的idea是2021版本,(新版应该差不多)
下载maven的版本包,建议去官网下载Maven – Maven Releases History (apache.org)
建议下载版本是3.8.8
然后进入settings里的maven界面
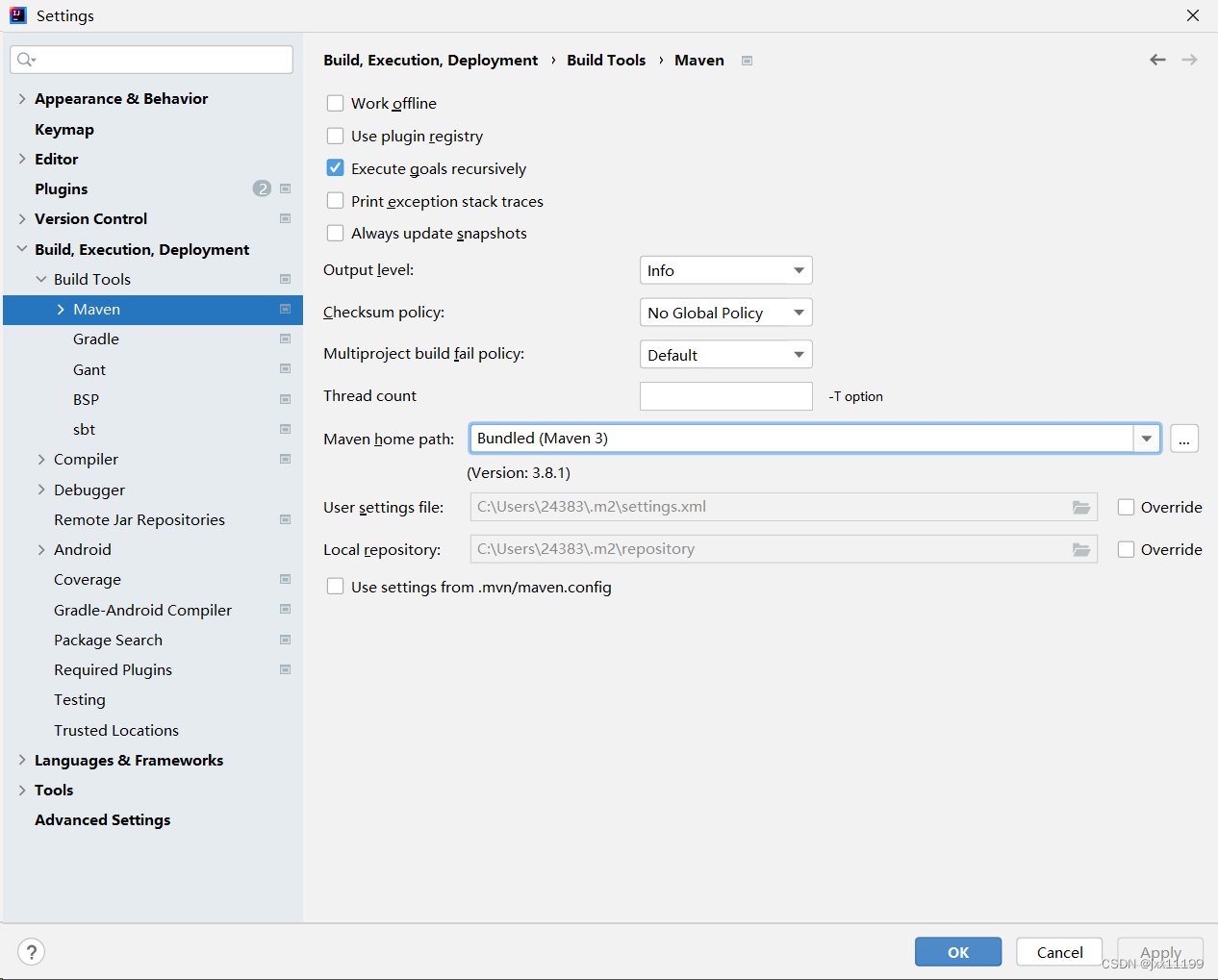
将maven home path 设置为你下载的路径:
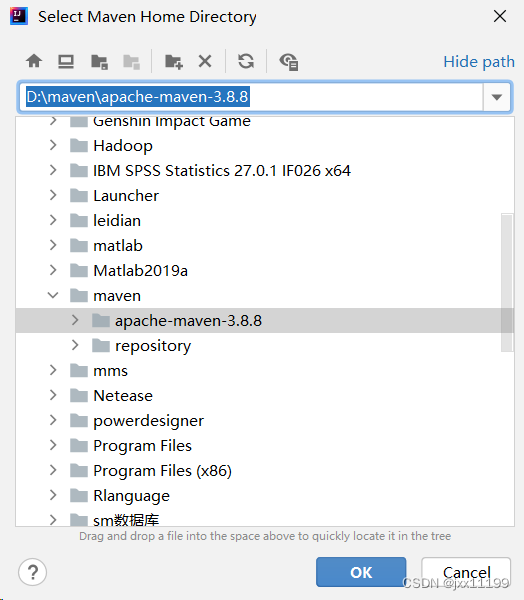
此时下面的version会改变
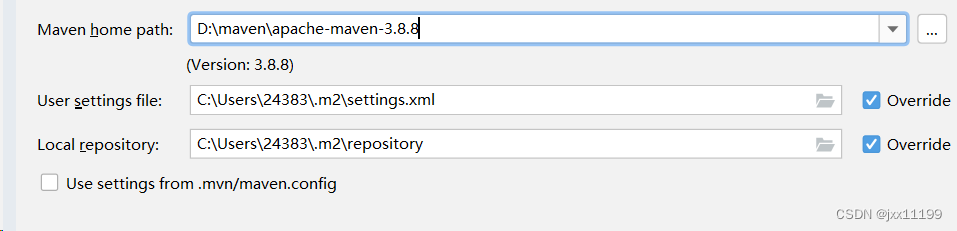
随后打开路径中的maven包,选择conf文件夹,选择settings.xml,用vscode打开
找到<mirror>镜像设置,注释掉原来的,添加阿里云的镜像(去浏览器搜索aliyun maven即可复制)
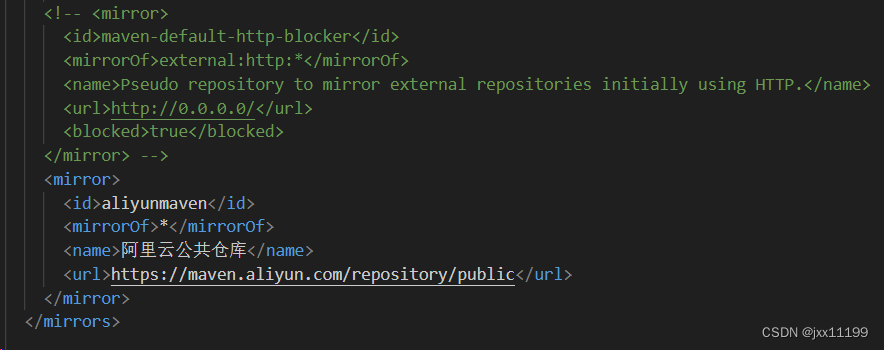
配置完成后在文件夹外多创建一个repository文件夹

回到idea,点击右侧的override重写

然后打开文件目录,第一个选择你刚刚配置的settings,第二个选择你创造的repository文件夹,
点击apply(一定要点击!!!)
然后你的maven就配置好了,最好是在最开始的idea界面配置,别打开任何的工作空间。
就是在这个界面,选择customize的all settings:
然后创建新的project,选择maven,建立新的工作空间即可。
2.配置hadoop环境变量
由于windows与hadoop不兼容,建议去下载winutils。
项目概览 - winutils - GitCode
下载zip,选出hadoop-3.0.0版本(建议)
点击我的电脑-属性-高级系统设置-环境变量,在系统变量里新建一个系统变量,如下图: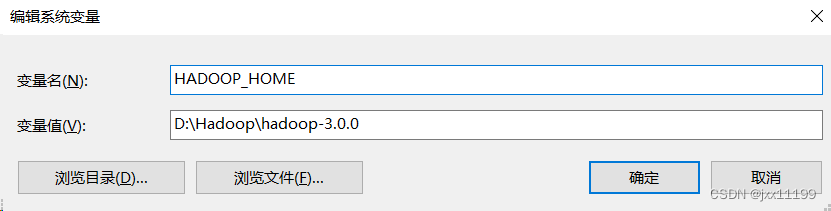
然后进入Path(系统变量里的),新建一个:
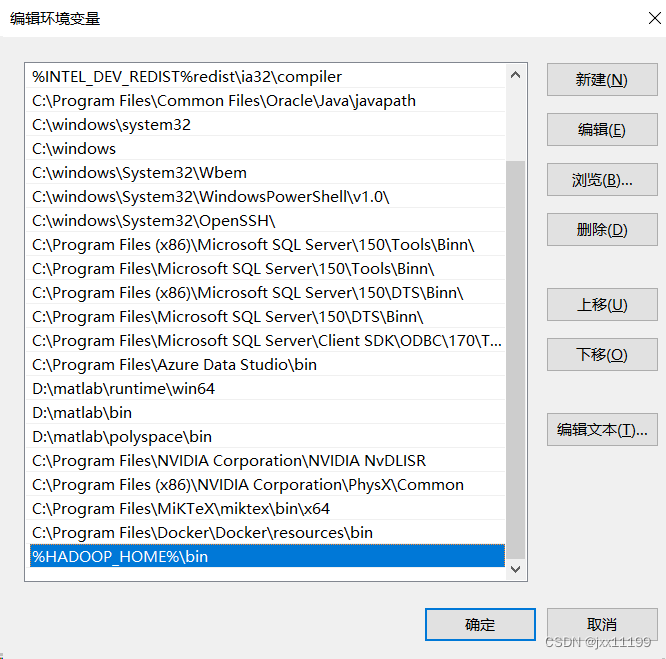
hadoop环境变量配置完成
3.spark jars包的配置
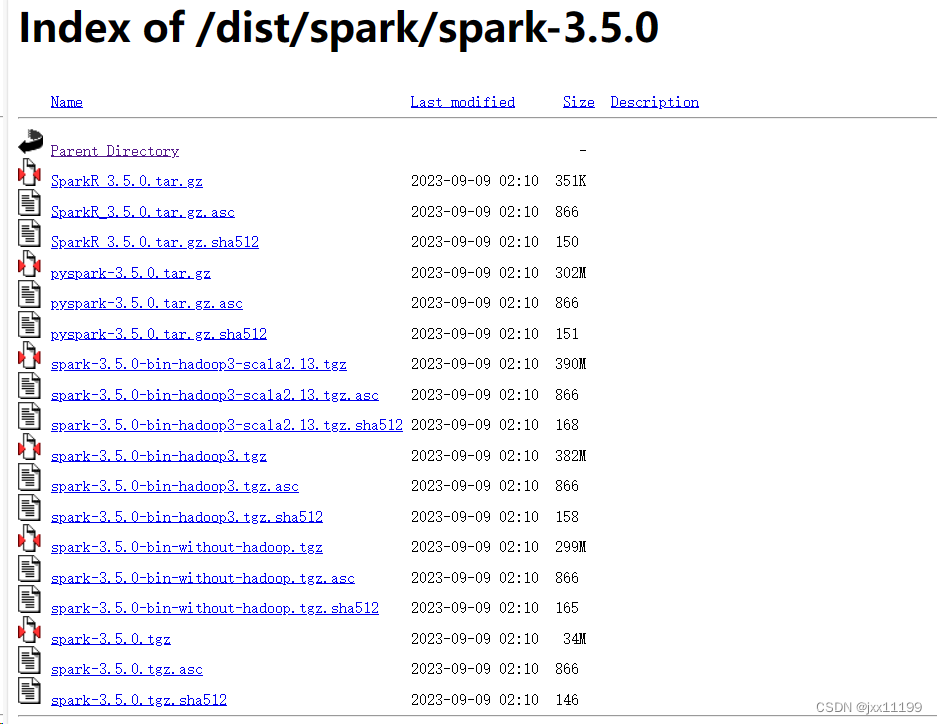
去官网下载spark的3.5.0版本(建议)
Index of /dist/spark (apache.org)
选择3.5.0-hadoop3-scala.2.13的tgz
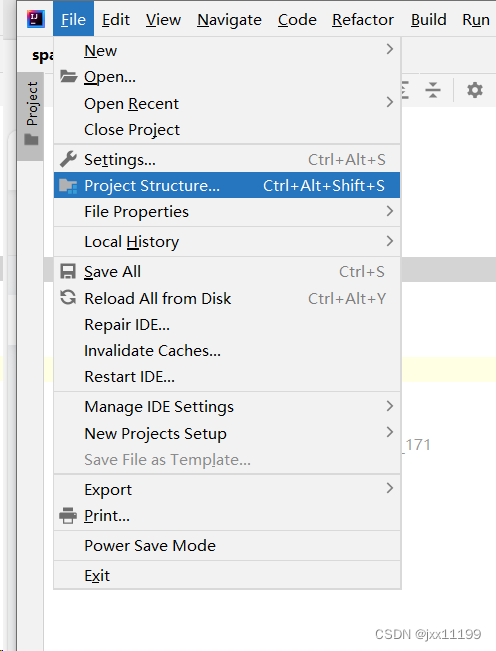
下载完成后解压,随后进入idea的新project里面,打开file-project structure:
点击library中的加号:
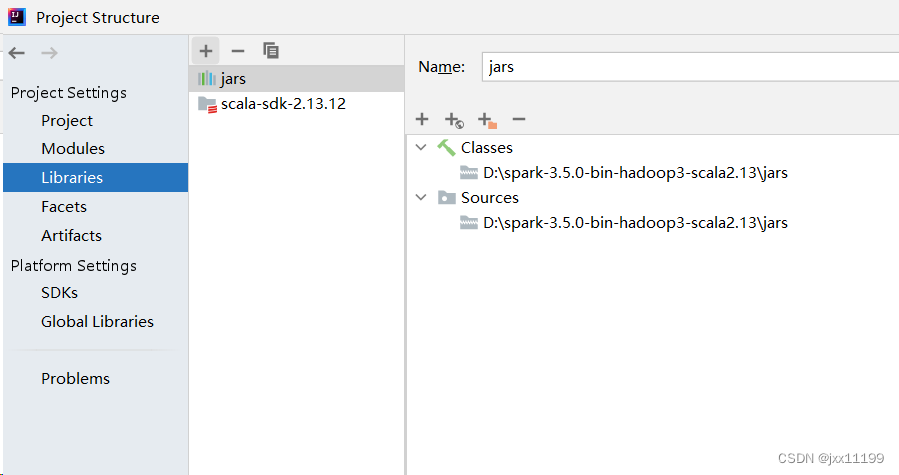
先选择scala sdk,2.13.12版本:

然后添加spark的jars包(记得选中jars文件夹):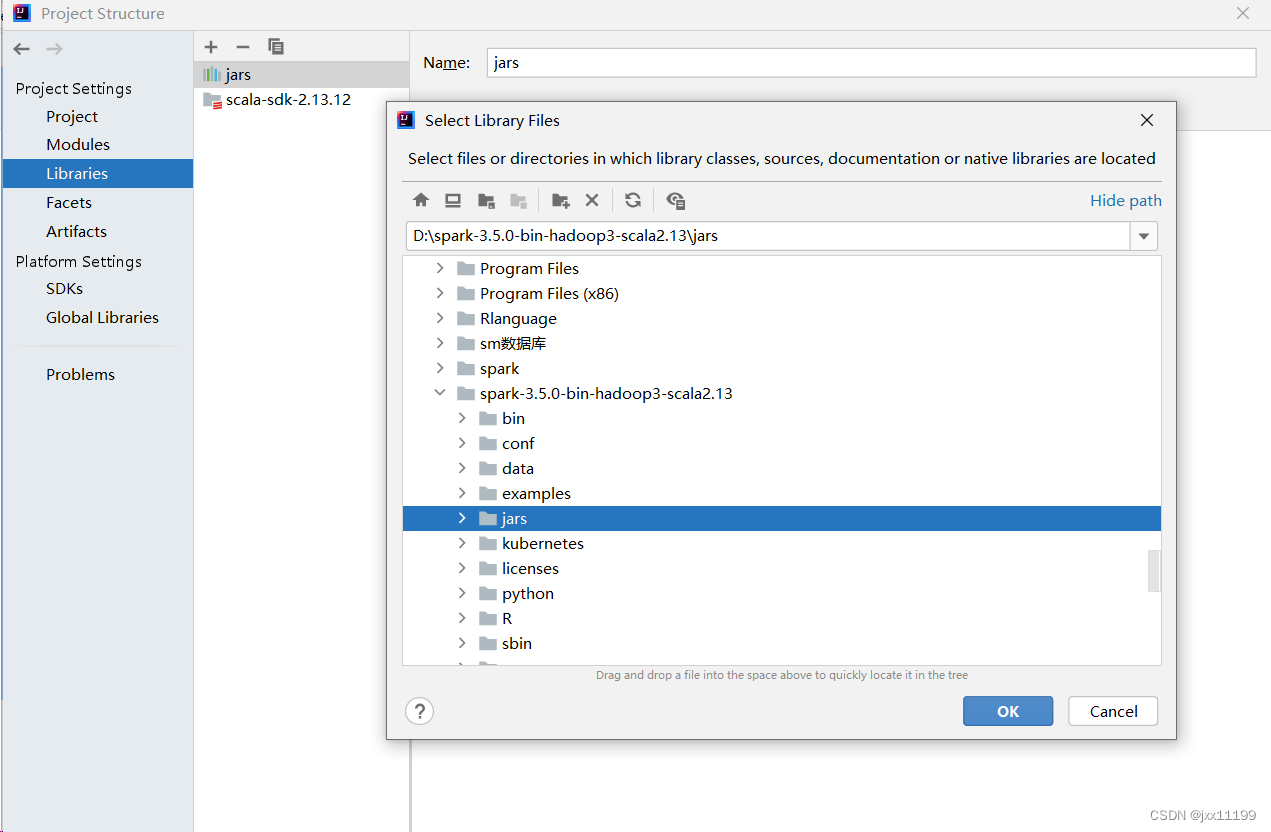
然后再modules的dependencies勾选刚刚添加的两个libraries:
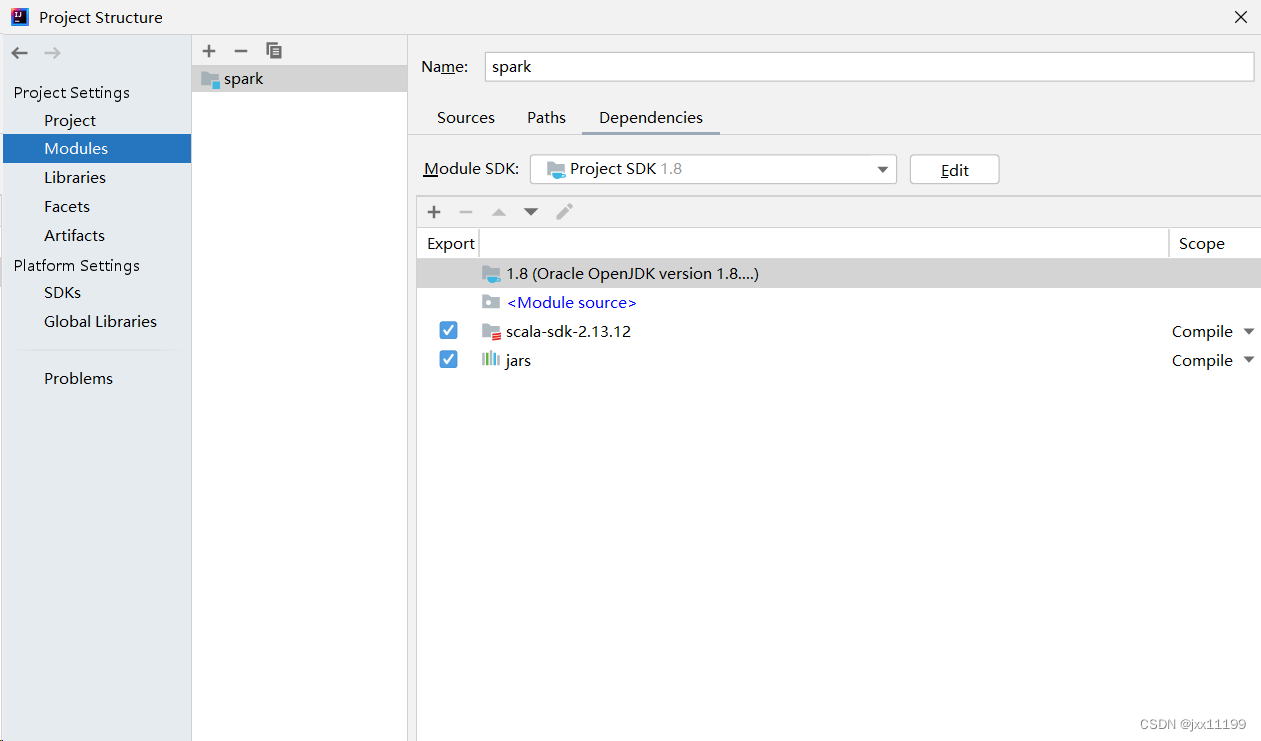
点击apply(一定!!!),随后点ok退出
这样就完成所有步骤了,编写spark独立应用程序吧。
版权归原作者 Ra1n70 所有, 如有侵权,请联系我们删除。