
文章目录
前言
大家好,又见面了,我是沐风晓月,本文是专栏【云原生实战】专栏的第2篇文章,主要讲解prometheus监控远程主机实战。
专栏地址:【云原生实战】 , 此专栏是沐风晓月对Linux常用命令的汇总,希望能够加深自己的印象,以及帮助到其他的小伙伴😉😉。
如果文章有什么需要改进的地方还请大佬不吝赐教👏👏。
🏠个人主页:我是沐风晓月
🧑个人简介:大家好,我是沐风晓月,双一流院校计算机专业😉😉
💕 座右铭: 先努力成长自己,再帮助更多的人 ,一起加油进步🍺🍺🍺
💕欢迎大家:这里是CSDN,我总结知识的地方,喜欢的话请三连,有问题请私信😘
一. 实验环境
本次的实验环境见下表:
操作系统服务器IPhostnamecentos7.6192.168.1.41mufengrow41centos7.6192.168.1.42mufenggrow42
如何查看相应的参数:
- 查看操作系统:
[root@mufenggrow ~]# cat /etc/redhat-release
CentOS Linux release 7.6.1810(Core)
- 查看hostname
## 修改hostname[root@mufenggrow ~]# hostnamectl set-hostname mufenggrow41[root@mufenggrow ~]# bash# 查看hostname[root@mufenggrow41 ~]# hostname
mufenggrow41
- 查看ip
[root@mufenggrow41 ~]# ifconfig |grep inet |awk 'NR==1{print $2}'192.168.1.41
本文中的master服务器,也就是prometheus已经安装好,如果你还未安装,可以参考上一篇文章:prometheus安装及使用入门
二. 安装node_exporter
2.1 node_exporter的介绍
官网给提供了数据采集的组件: node_exporter, prometheus只能拉取数据,而Exporter是Prometheus的指标数据收集组件。
它负责从目标Jobs收集数据,并把收集到的数据转换为Prometheus支持的时序数据格式。
和传统的指标数据收集组件不同的是,它只负责收集数据,并不向Server端发送数据,而是等待Prometheus Server 主动抓取。
node-exporter 默认的抓取url地址:http://ip:9100/metrics
如果想要让node_exporter推送数据,可以借助于工具 pushgetway组件,这个组件可以推送node_exporter的指标数据到你安装好的prometheus服务器上。
node-exporter用于采集node的运行指标,包括node的cpu、load、filesystem、meminfo、network等基础监控指标,类似于zabbix监控系统的的zabbix-agent
2.2 node_exporter的安装
1. 上传node_exporter
2. 解压并启动
- 解压node_exporter
[root@mufenggrow42 ~]# tar xf node_exporter-1.5.0.linux-amd64.tar.gz #包的名字太长,这里改的短一点[root@mufenggrow42 ~]# mv node_exporter-1.5.0.linux-amd64 node_exporter[root@mufenggrow42 ~]# cd node_exporter[root@mufenggrow42 node_exporter]#
- 关于启动exporter的参数
上面我们已经解压了,如果要安装,我们需要使用node_exporter --help来查看完成的参数:
[root@mufenggrow42 node_exporter]# ./node_exporter --help
usage: node_exporter [<flags>]
Flags:-h,--help Show context-sensitive help(also try--help-longand--help-man).--collector.arp.device-include=COLLECTOR.ARP.DEVICE-INCLUDE
Regexp of arp devices to include (mutually exclusive to device-exclude).--collector.arp.device-exclude=COLLECTOR.ARP.DEVICE-EXCLUDE
Regexp of arp devices to exclude (mutually exclusive to device-include).--collector.bcache.priorityStats
Expose expensive priority stats....(省略)
默认情况下, node_exporter 在端口 9100 上运行,并在路径 /metrics 上暴 露指标,此处也可以修改,比如:
可以通过–web.listen-address 和 --web.telemetry-path 参数来设置端口和路径:
[root@mufenggrow42 node_exporter]# ./node_exporter --web.listen-address=":9800"
修改端口为9800.
(关于启动时候的一些参数,我们在后面的文章中详细介绍,本文只启动node_exporter,实现监控远程主机即可)
- 开始启动node_exporter
[root@mufenggrow42 node_exporter]# nohup ./node_exporter &[1]19459
启动并设置在后台运行,这里nohup命令,主要用于在系统后台不挂断地运行命令,退出终端不会影响程序的运行。
nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下,如果当前目录的 nohup.out 文件不可写,输出重定向到 $HOME/nohup.out 文件中。
- 查看启动情况 我们可以查看端口是否启动:
[root@mufenggrow42 ~]# lsof -i:9100
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
node_expo 19459 root 3u IPv6 59483 0t0 TCP *:jetdirect (LISTEN)
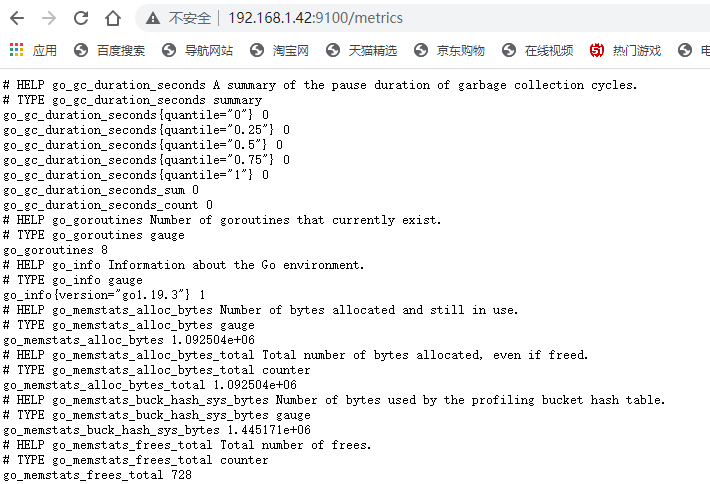
- 查看监控信息: 我们从网页端查看监控信息:
三. 在prometheus服务端配置监控远程主机
3.1 在server端配置拉取node的信息
找到我们的配置文件:
打开配置文件进行设置:
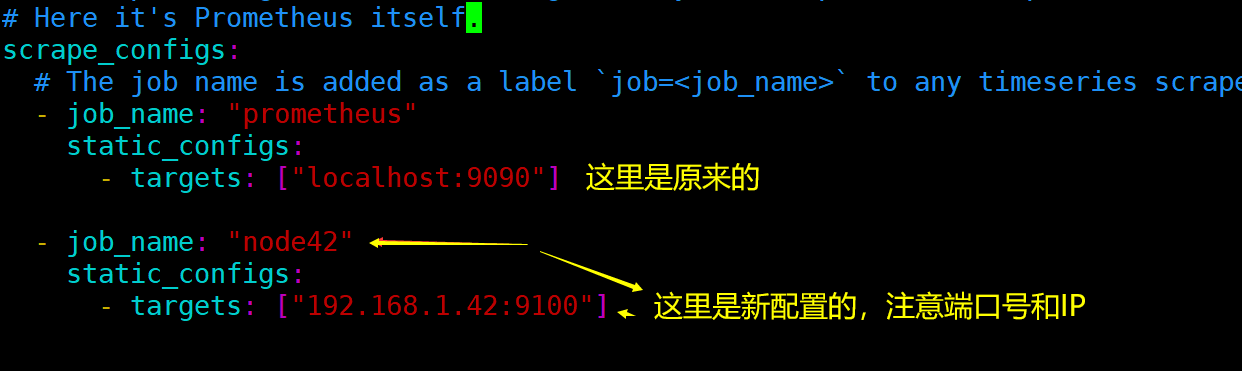
在最后面添加node的信息:
scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name:"prometheus"
static_configs:- targets:["localhost:9090"]- job_name:"node42"
static_configs:- targets:["192.168.1.42:9100"]
如图所示:
3.2 重启prometheus
两种方法重启:
- 方法一: 直接使用pkill杀死进程,然后重启
#杀死promethues[root@mufenggrow41 prometheus]# pkill prometheus# 再次启动[root@mufenggrow41 prometheus]# ./prometheus &
- 方法二: 后台运行prometheus的方式重启
1)配置prometheus server的systemd文件
# vim /usr/lib/systemd/system/prometheus.service[Unit]
Description=Monitoring system and time series database
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Restart=on-failure #表示当进程以非零退出代码退出,由信号终止;#当操作(如服务重新加载)超时;以及何时触发配置的监视程序超时时,服务会自动重启。
WorkingDirectory=/apps/prometheus/#工作目录,路径根据需求修改
ExecStart=/apps/prometheus/prometheus --config.file=/apps/prometheus/prometheus.yml
#/apps/prometheus/prometheus:二进制启动文件#--config.file #配置文件的路径,启动prometheus指定要读取那个配置文件。(配置文件路径根据需求修改)
User=prometheus #启动用户[Install]
WantedBy=multi-user.target
- 添加prometheus用户
useradd -M -r -s /usr/sbin/nologin prometheus
此命令的解释:
-M:创建用户时不创建该用户的家目录,也就是在/home目录中没有该用户的目录。(该选项可选择性添加)
-r:创建的用户为系统用户。(该选项可选择性添加)
-s:指定用户的shell。
3)给prometheus二进制文件修改所属主和所属组
# chown -R prometheus.prometheus /apps/prometheus-2.37.5.linux-amd64
4) 启动prometheus
#重新读取所有的service文件# systemctl daemon-reload #该命令有启动prometheus和设置prometheus开机的作用# systemctl enable --now prometheus # ps -ef | grep prometheus
3.3 通过浏览器查看prometheus
打开prometheus的地址:
输入访问地址: 192.168.1.41:9090
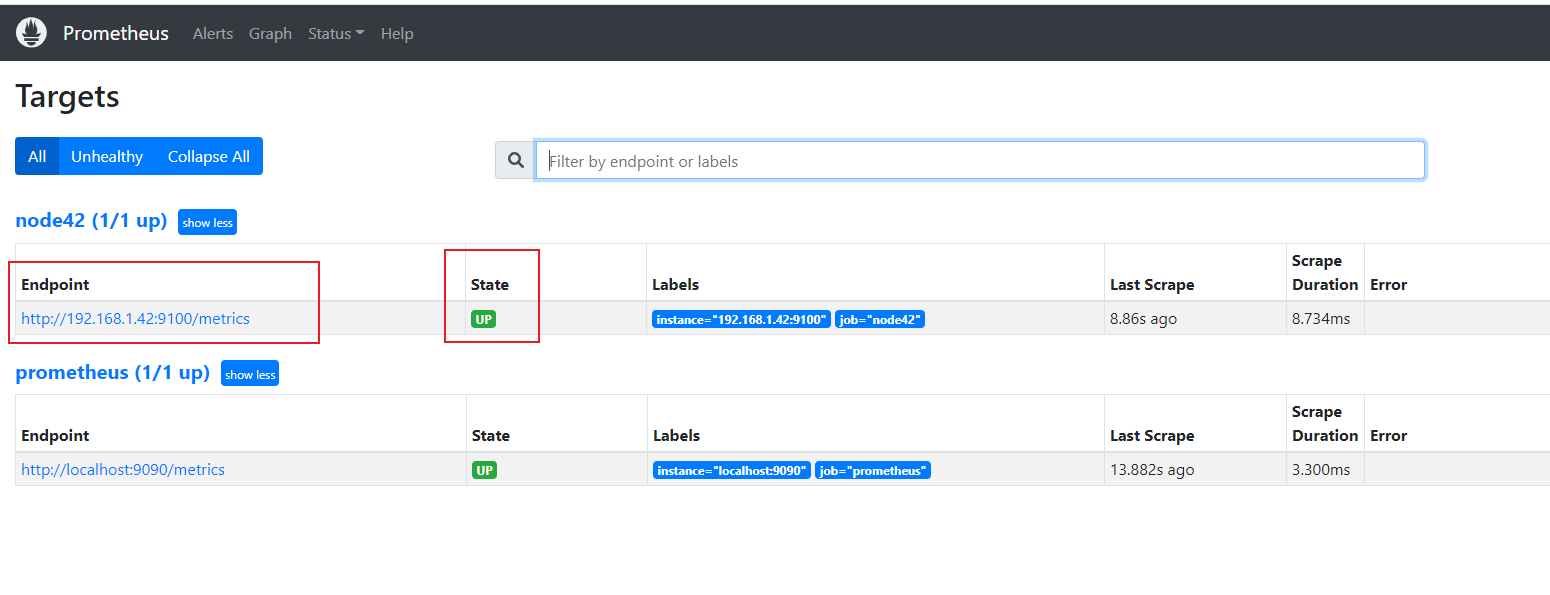
可以看到,已经监控到了远程主机的信息
从下图可以看到监控的详细参数:
比如我们查看cpu的使用时间:
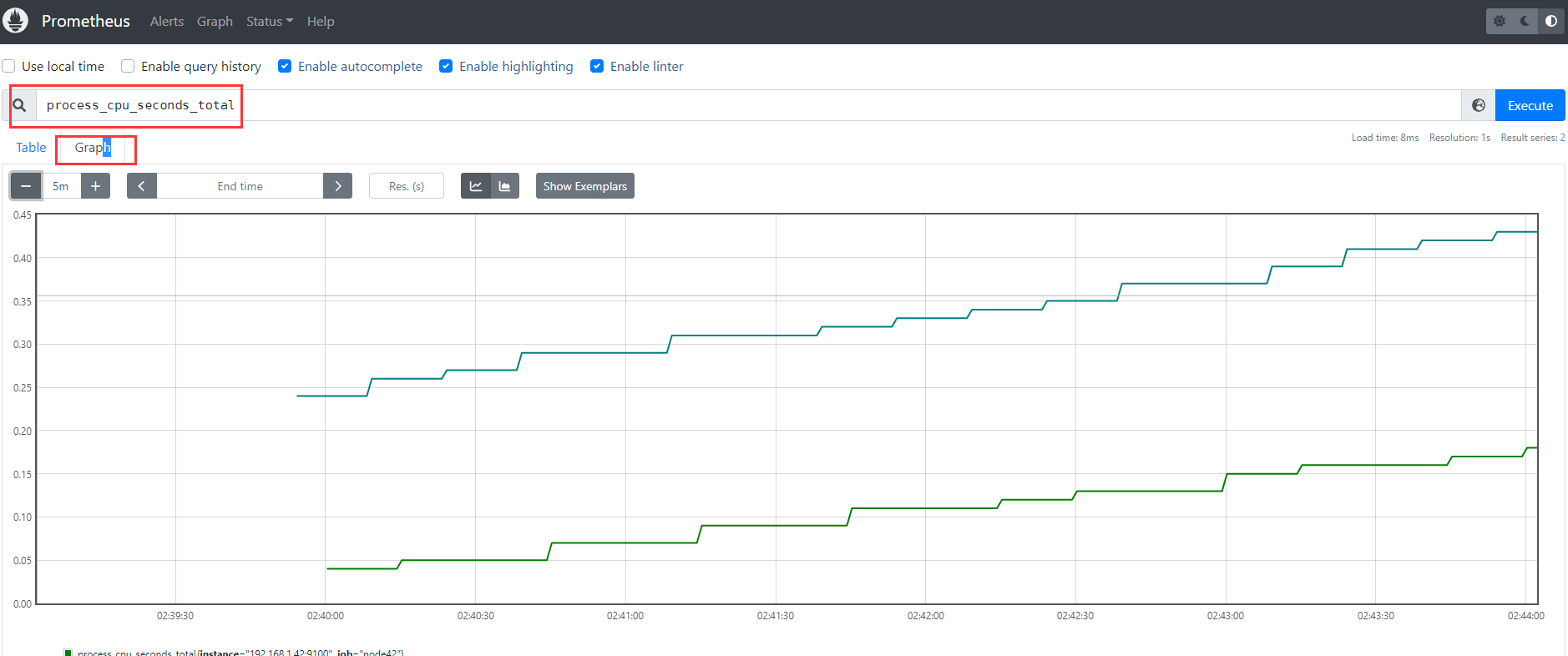
注:
process_cpu_seconds_total 用户和系统的总cpu使用时间
总结
以上就是使用prometheus监控远程linux服务器实战,欢迎点赞收藏哦。
💕💕💕 好啦,这就是今天要分享给大家的全部内容了,我们下期再见!✨ ✨ ✨
🍻🍻🍻如果你喜欢的话,就不要吝惜你的一键三连了~
版权归原作者 我是沐风晓月 所有, 如有侵权,请联系我们删除。