
一.Hadoop与Hive兼容版本选择
正常来说,Hadoop与Hive版本不兼容会出现很多问题导致hive安装失败,可以先确定HIve的版本,比如:要用Hive3.1.2版本,该如何确定使用Hadoop的版本呢,需要我们在hive源码中找到对应Hadoop版本。
下载hive对应版本源码
apache-hive-3.1.2-src
或者其他版本下载:需要下载src.tar.gz 结尾的压缩包
https://archive.apache.org/dist/hive/
解压之后,打卡pom.xml文件,查找“hadoop.version”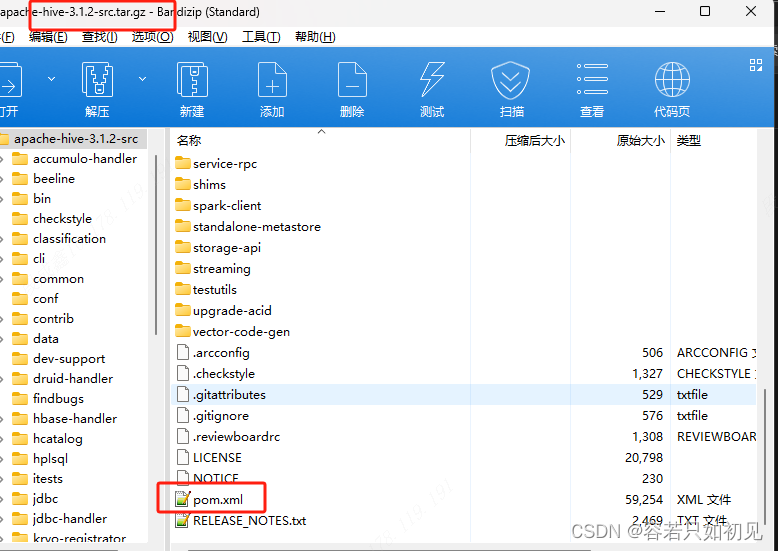
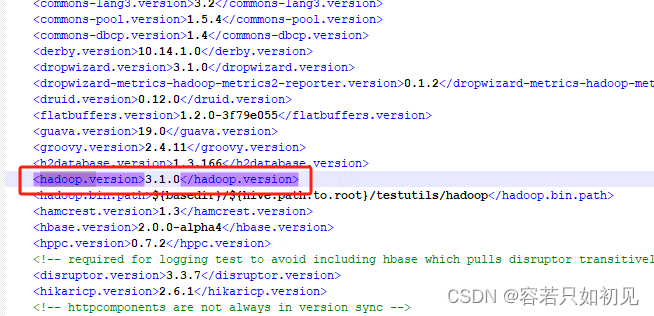
对应去下载这个版本的Hadoop即可。
二、在Hive安装过程中,工具连接MySQL8报错
DBeaver连接MySQL提示"Public Key Retrieval is not allowed(不允许进行公钥检索。)"问题解决方式。
1.右键连接失败的数据连接,点击“编辑连接”;
2.在“连接设置”中选择“驱动属性”,将“allowPublicKeyRetrieval”值改为“TRUE”,点击确定,再次连接即可。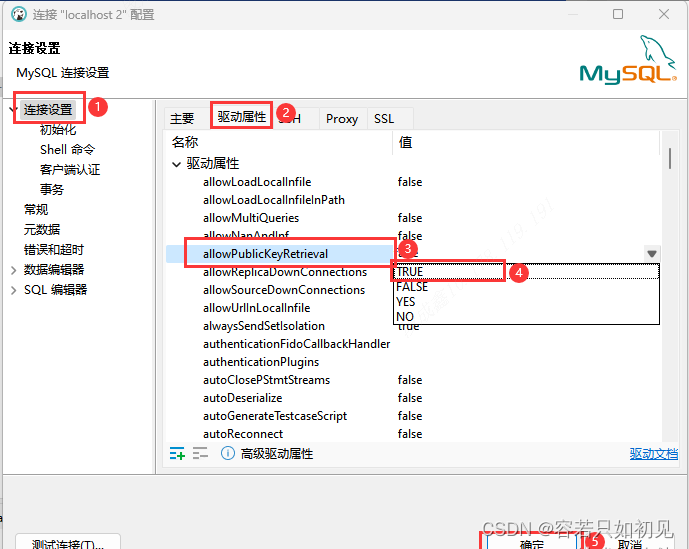
3.mysql出现错误提示:Communications link failure The last packet sent successfully to the server was 0 mi…
无论是在mysql客户端连接,或者是代码连接中,都会出现该错误,特别是在mysql8.0+这个问题更常见,采取的解决办法如下:
进入mysql,执行以下命令:
//下面这个wait timeout默认好像是28800(8h)showglobal variables like'wait_timeout';//然后把时间设置长点(7day)setglobal wait_timeout=604800;setglobal interactive_timeout=604800;
若在新建MySQL8的连接,且指定连数据库时,报错Public Key Retrieval is not allowed的解决方法,数据库名后面添加?allowPublicKeyRetrieval=true 即可.
若是在jdbc中就需要在url后面添加即可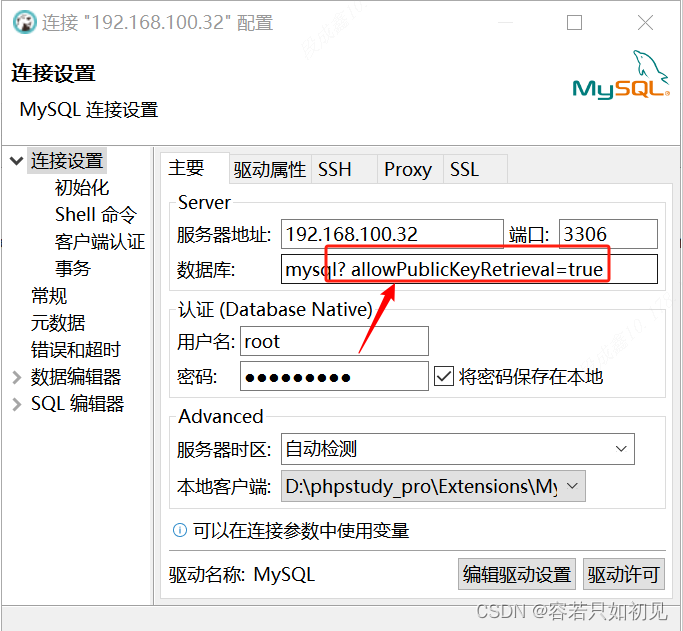
点测试链接,提示内部驱动错误,如下图: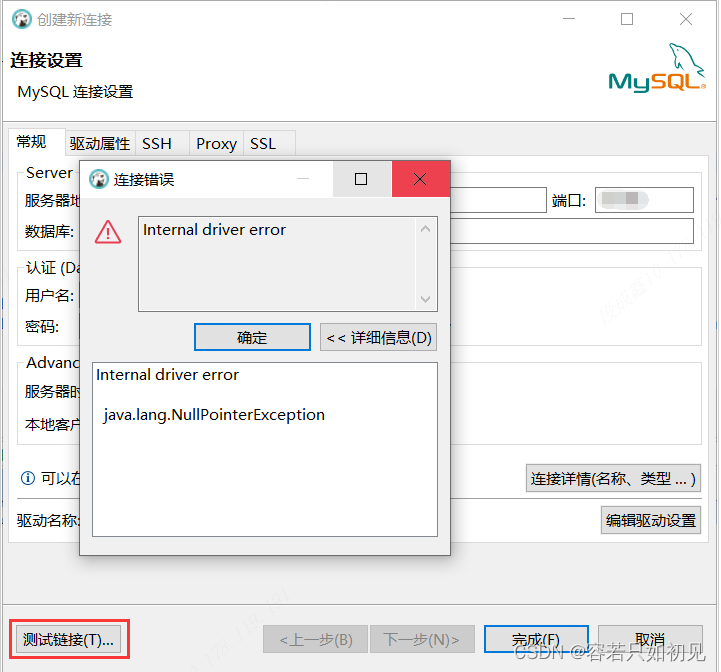
解决方法:创建连接时,需要设置服务器时区,可设置东八区:Etc/GMT-8,如下图。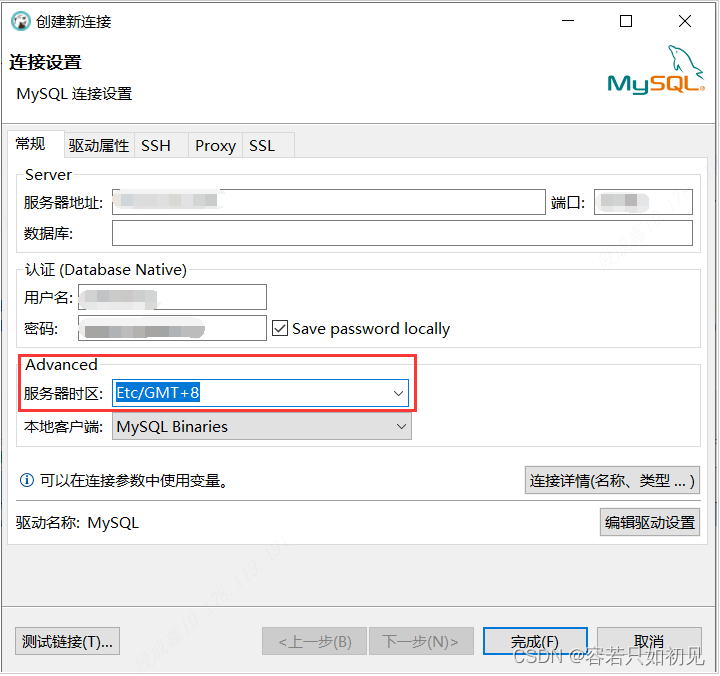
测试链接成功,但是点开对应数据库,看不到表,如下图: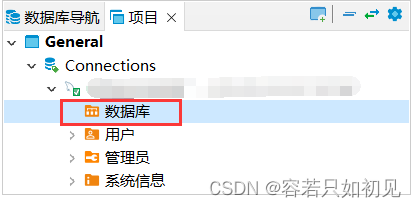
解决方法:右键链接 -> 编辑 连接 -> 连接属性 -> 客户端认证,勾选“禁用客户端身份识别”即可。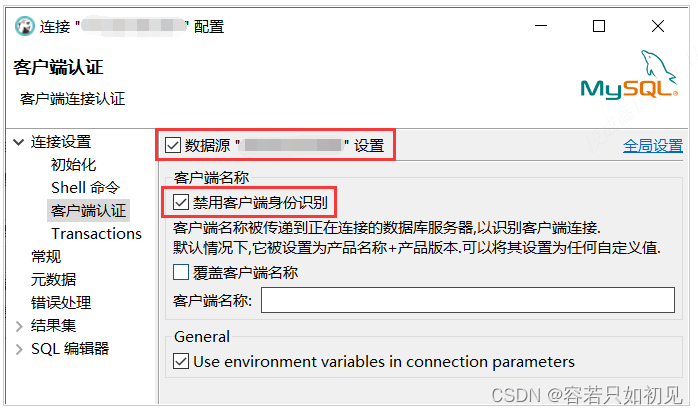
三、beeline或者其他客户端工具连接Hive报错:org.apache.hadoop.security.authorize.AuthorizationException
在hive安装完成,并使用客户端工具连接时,报错:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException):User: xx is not allowed toimpersonate xx
解决办法:
1.在hive安装目录下:conf/hive-site.xml中添加配置:
<property><name>hive.metastore.sasl.enabled</name><value>false</value><description>Iftrue, the metastore Thriftinterface will be secured withSASL. Clients must authenticate withKerberos.</description></property><property><name>hive.server2.enable.doAs</name><value>false</value></property><property><name>hive.server2.authentication</name><value>NONE</value></property>
2.在Hadoop安装目录下配置文件 core-site.xml加入配置
<property><name>hadoop.proxyuser.xx.hosts</name><value>*</value></property><!-- 允许被Oozie代理的用户组 --><property><name>hadoop.proxyuser.xx.groups</name><value>*</value></property>
3.若是集群则所有节点都需要配置,配置完成后需要重启节点,否则不生效。
ps:
可能需要关闭Hadoop和Hive后:
删除hadoop集群下的所有data/ logs/文件夹
以及格式化namenode,命令:hdfs namenode -format
四、DBeaver连接Hive报错
1.如果hive 表里使用map数据结构,hive执行select操作是可能报错
java.lang.IncompatibleClassChangeError:Classcom.google.common.collect.ImmutableSortedMap does not implement the requested interfacejava.util.NavigableMap
原因:
hadoop 里面使用的 guava 版本太低,保持 hive 和 hadoop 的 guava 版本一致
解决方法:
停止hadoop和hive, 把 hive 中的 guava.xx.jar包拷贝到 hadoop 的 share\hadoop\common\lib的目录下,即可正常运行

2.hive更新分区表更新分区表操作报错
问题描述:
could only be written to0 of the 1 minReplication nodes. There are 1datanode(s) running and 1 node
在使用 hive insert overwrite 更新分区表时 或者 将文件同步到HDFS时,出现这个报错信息。表明没有可使用的DataNode。
解决方案:
(1)namenode节点与其他datanode节点的VERSION中的clusterD的值不一致
方法:删除所有节点(包括namenode)节点的hdfs-site.xml中dfs.namenode.name.dir中指定的文件夹即name和data文件夹,然后使用hadoop namenode -format命令重新格式化各个节点。
(2)有节点的防火墙未关闭
方法: 使用命令:
systemctl stop firewalld.service
(3)hdfs空间被占满
hive在执行的时候会往/tmp下读写大量的临时数据,由于没有空间而报错。
默认情况下,hive脚本执行完之后会自动清理掉这些临时文件。
但是可能有多次没等hive脚本执行完就Ctrl+C终止,会有大量临时文件未清理。
方法:在所有hive脚本都运行结束后,删除掉这些没用的临时文件,腾出空间。
3.使用DBeaver连接Hive的jdbc驱动
这可能是个意识性问题,潜意识会认为连接hive用hive-jdbc-3.1.2.jar驱动,其实使用客户端连接的驱动并不是它,使用它会报错如下:
org.apache.hive.service.rpc.thrift.TCLIService$Iface
或者
org.apache.thrift.TException------------------------------------------------------------------Unexpected driver error occurred while connecting tothe database
org/apache/hive/service/rpc/thrift/TCLIService$Iface
org/apache/hive/service/rpc/thrift/TCLIService$Ifaceorg.apache.hive.service.rpc.thrift.TCLIService$Ifaceorg.apache.hive.service.rpc.thrift.TCLIService$Iface
这里选择的驱动不是hive-jdbc-3.1.2.jar, 而是hive-jdbc-3.1.2-standalone.jar,这个jar包是在hive安装目录的jdbc下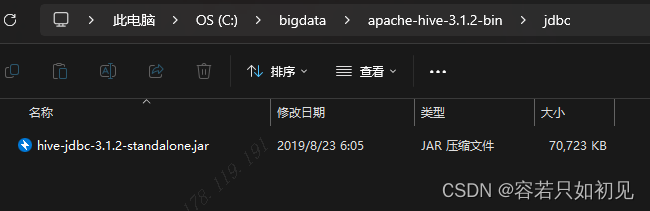
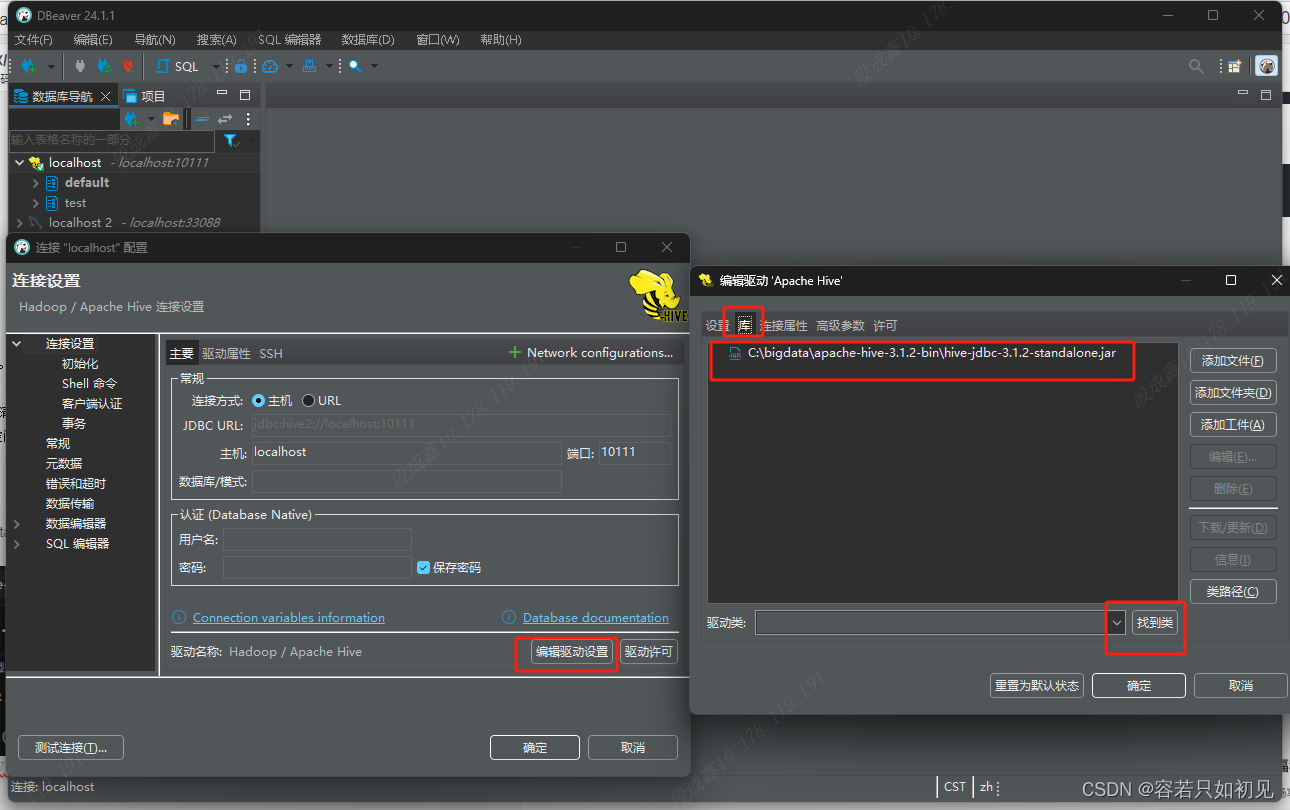
这样才能连接上hive。
版权归原作者 容若只如初见 所有, 如有侵权,请联系我们删除。