
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握Kafka的消息流处理;
⚪ 掌握Kafka的索引机制;
⚪ 掌握Kafka的消息系统语义;
一、Kafka消息流处理
1. Producer 写入消息
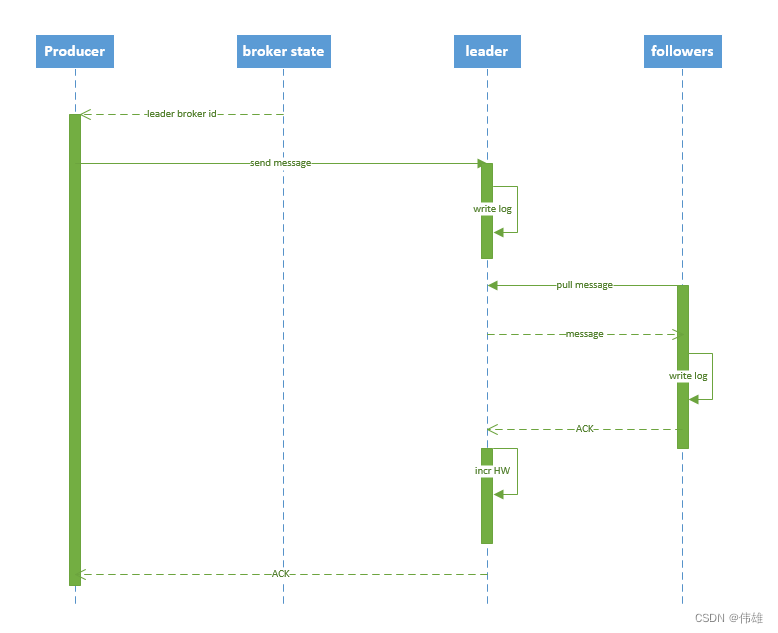
流程说明:
- producer 要向Kafka生产消息,需要先通过 zookeeper 的 "/brokers/.../state" 节点找到该 partition 的 副本leader的位置信息。
- producer 将消息发送给该 leader。
- leader 收到消息后,将消息写入到分区目录下的本地 log 文件中。
- followers 从 leader pull 同步消息,将消息写入到分区目录下的 log 中。如果同步成功(将消息写入log文件成功),则向 leader 返回 ACK(确认机制)。
细节补充:
Kafka引入了一个ISR机制(概念),在Follower和Leader数据同步的过程中,
比如:
①副本-Follower
②副本-Leader
③副本-Follower
在数据同步过程中,①②同步,③出故障没有跟上。
此时①②是同一组ISR成员,③不是。
如果后续Leader挂掉了,则Kafka会从Leader的ISR组中随机选择一个Follower成为Leader。
Kafka底层有一个同步超时的时间(10s),即一个Follower在超时时间内没有反馈ACK,则人为同步失败。
由写入流程可知ISR里面的所有replica都跟上了Leader,只有ISR里面的成员才能选为Leader。对于 f+1 个replica,一个partition可以在容忍 f 个replica失效的情况下保证消息步丢失。
比如:一个分区由5个副本,挂掉4个,剩下一个副本,依然可以工作。
注意:Kafka的选举不同于zookeeper,用的不是过半选举。
- leader 收到所有 ISR 中的 repli
本文转载自: https://blog.csdn.net/u013955758/article/details/132155891
版权归原作者 伟雄 所有, 如有侵权,请联系我们删除。
版权归原作者 伟雄 所有, 如有侵权,请联系我们删除。