
相关软件下载链接:
Xshell:家庭/学校免费 - NetSarang Website
Xftp:家庭/学校免费 - NetSarang Website
Xshell与Xftp官网:XSHELL - NetSarang Website
Jdk:百度网盘 请输入提取码 提取码:jdhp
Hadoop:百度网盘 请输入提取码 提取码:jdhp
需要配置好的虚拟机与相关环境的,可以点击我的这篇文章获取:Hadoop大数据平台搭建环境 提供虚拟机相关配置_Crazy.宥思的博客-CSDN博客
1、在原来虚拟机的基础上再克隆两台虚拟机
(1)右键点击虚拟机,点击管理,点击克隆,此步骤重复两次
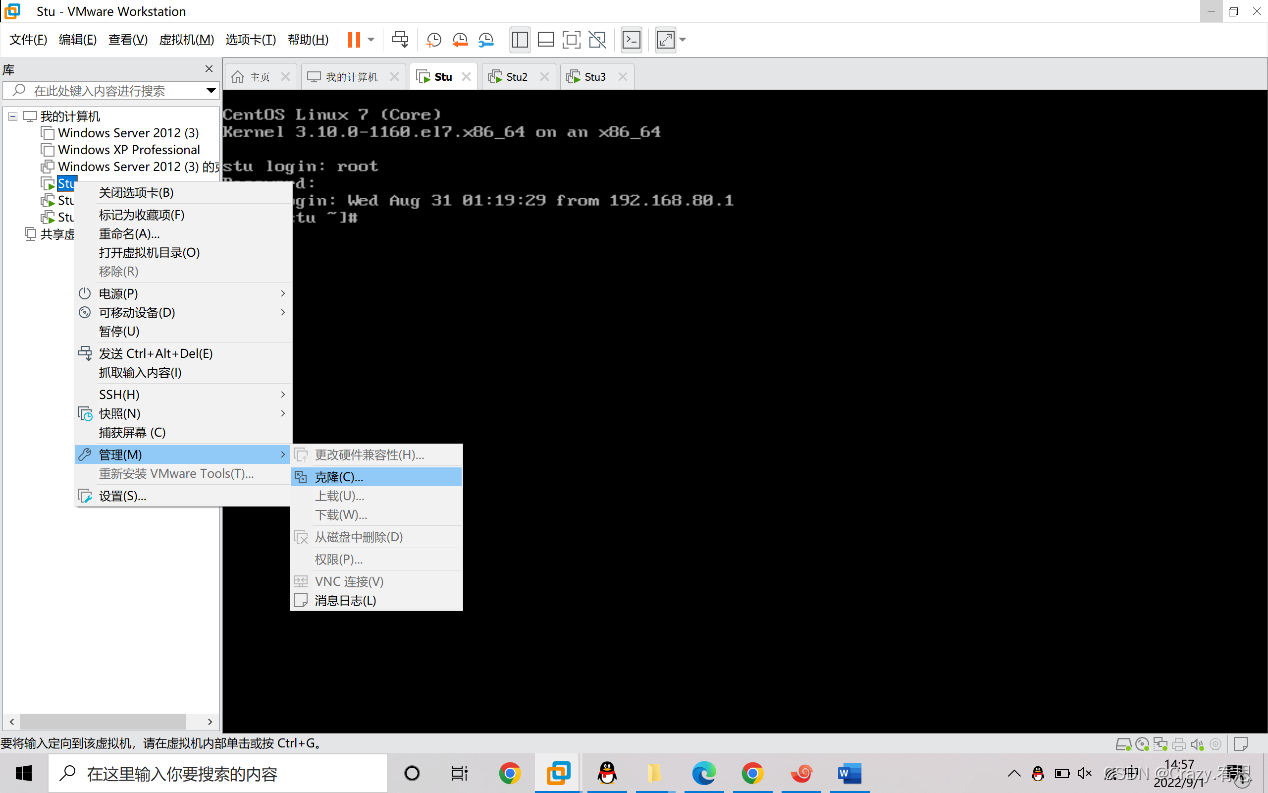
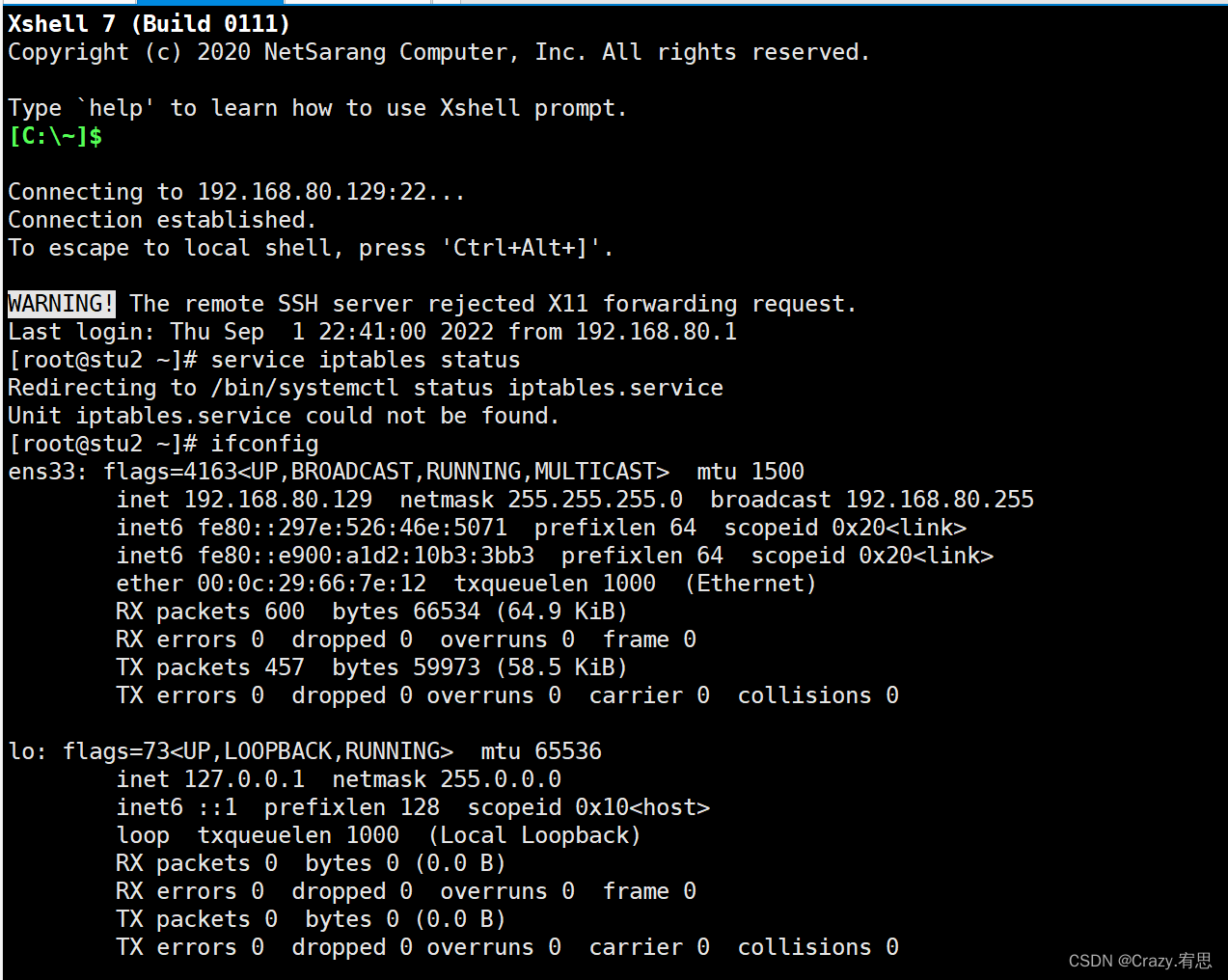
(2)检查克隆机的ip地址是否与原虚拟机不同,若不同则要修改,我这里在克隆的时候就自动变化了ip地址,故不需要修改

2、修改机器名
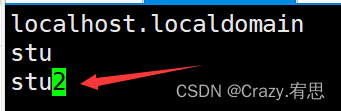
(1)在下图红箭头处输入修改名:stu2
命令:vi /etc/hostname
(2)另外两台虚拟机也照此操作即可
(3)重启这三台虚拟机
命令:reboot
改完以后这三台虚拟机的名字分别为:stu、stu2、stu3
3、关闭防火墙
(1)查看防火墙是否关闭

由于初始虚拟机上防火墙就已关闭,所以另外两台克隆机的防火墙也处于关闭状态
4、配置三台主机免密登录
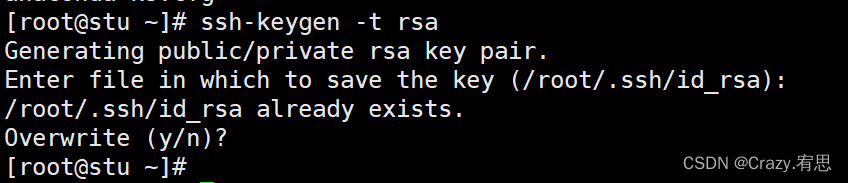
(1)首先在stu(stu2、stu3)上,生成ssh密匙
命令:ssh-keygen -t rsa
回车,在接下来的提示中一直回车,不用输入内容
stu:
stu2:
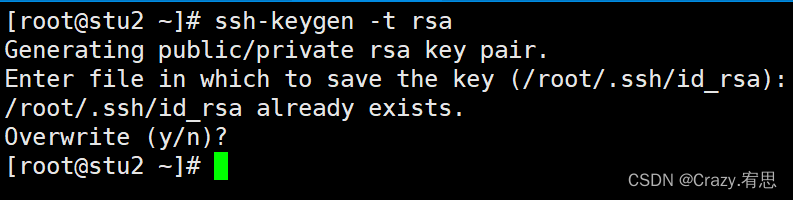
stu3:
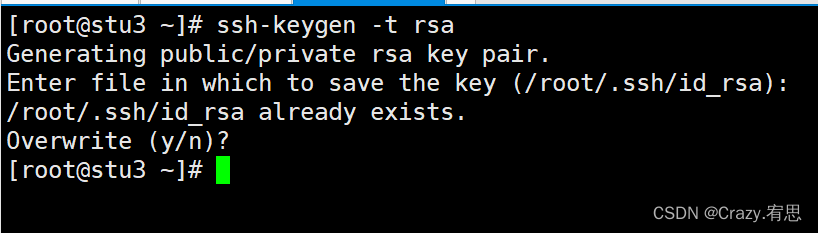
在家目录下的.ssh目录中出现以下两个密钥文件:
stu:

stu2:

stu3:

(2)在stu(stu2、stu3)机器上,将目录切换到.ssh目录下
命令:cd ~/.ssh
(3)在.ssh目录下新建文件authorized_keys文件
命令:touch authorized_keys
(4)将id_rsa.pub文件内容拷贝到authorized_keys文件中
命令:cat id_rsa.pub >> authorized_keys
(5)查看authorized_keys文件中的内容
命令:cat authorized_keys

(6)将stu上.ssh目录下的authorized_keys文件发送到stu2相应的目录下
命令:scp authorized_keys 192.168.80.129:$PWD
在提示后面输入yes,回车
然后输入密码,回车,完成传输
(7)切换到stu2机器上,进入~/.ssh目录中
命令:cd ~/.ssh
(8)将stu2上.ssh目录中id_rsa.pub文件内容拷贝到authorized_keys文件中
命令:cat id_rsa.pub >> authorized_keys
(9)将stu2上.ssh目录中的authorized_keys文件发送到stu3相应的目录下
命令:scp authorized_keys 192.168.80.130:$PWD
在提示中输入yes,回车,然后输入密码
(10)切换到stu3机器上,进入~/.ssh目录中
命令:cd ~/.ssh
(11)将stu3上.ssh目录中id_rsa.pub文件内容拷贝到authorized_keys文件中
命令:cat id_rsa.pub >> authorized_keys
(12)将stu3上.ssh目录中authorized_keys文件回传给stu1和stu2
命令:scp authorized_keys 192.168.80.128:$PWD
scp authorized_keys 192.168.80.129:$PWD
(13)验证(在stu上)
命令:ssh 192.168.80.130

5、建立主机名与IP地址的映射
(1)打开/etc/hosts文件(在stu上)
命令:vi /etc/hosts
在文件中添加:
192.168.80.128 stu
192.168.80.129 stu2
192.168.80.130 stu3

修改完毕后按ESC键,保存退出
(2)将stu上/etc/hosts文件分别分发到stu2、stu3上。
命令:scp /etc/hosts 192.168.180.129:/etc/
scp /etc/hosts 192.168.180.130:/etc/
(3)验证,在stu上ping stu2和stu3
命令:ping 192.168.80.129
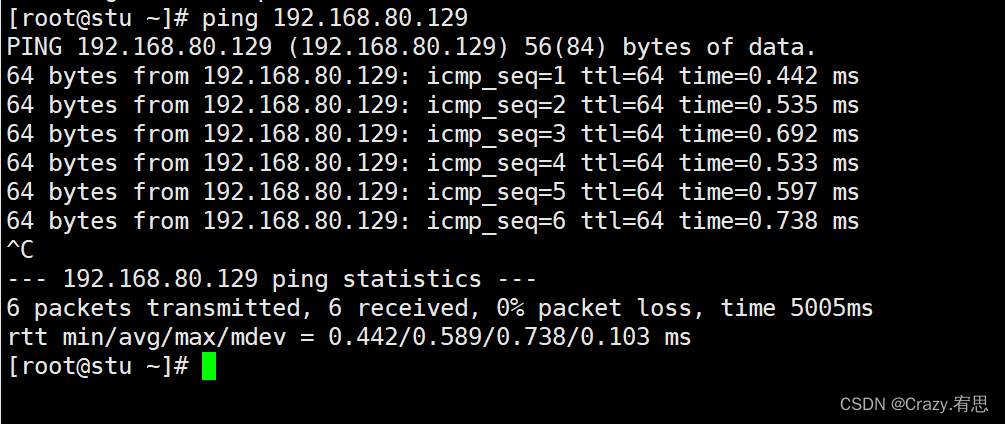
命令:ping 192.168.80.130

6、安装JDK(三台机器都需要安装JDK,以stu为例,其它两台操作是一样的)
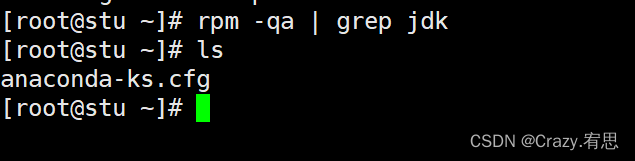
(1)首先检查系统中是否自带JDK
命令:rpm -qa | grep jdk
(2)用xftp软件将jdk上传到linux的用户家目录下
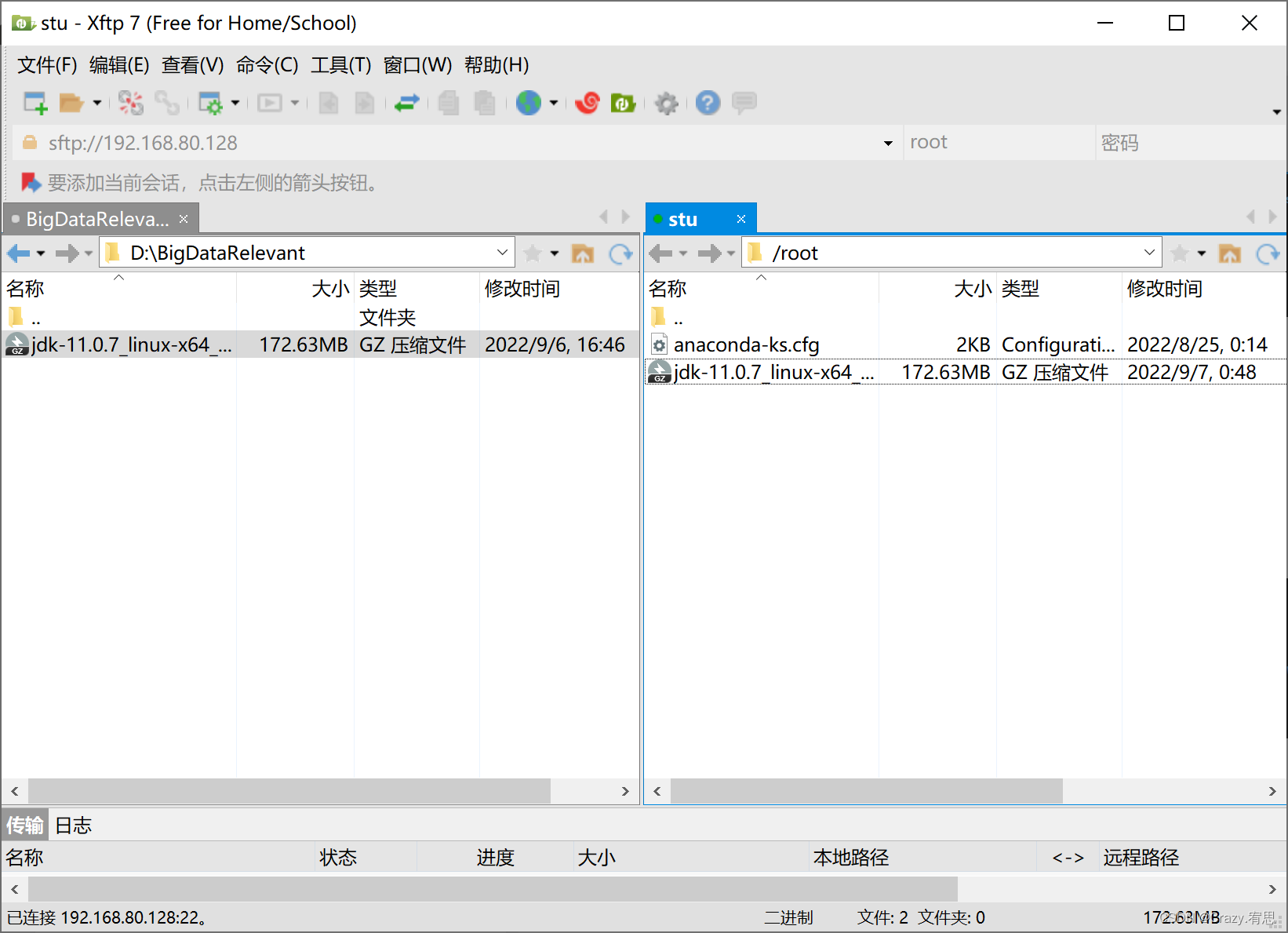
(3)在根目录下建服务器软件服务目录
命令:mkdir -p /exports/servers

(4)将家目录下的jdk解压到/exports/servers目录下
命令:tar -zxvf jdk-11.0.7_linux-x64_bin.tar.gz -C /exports/servers
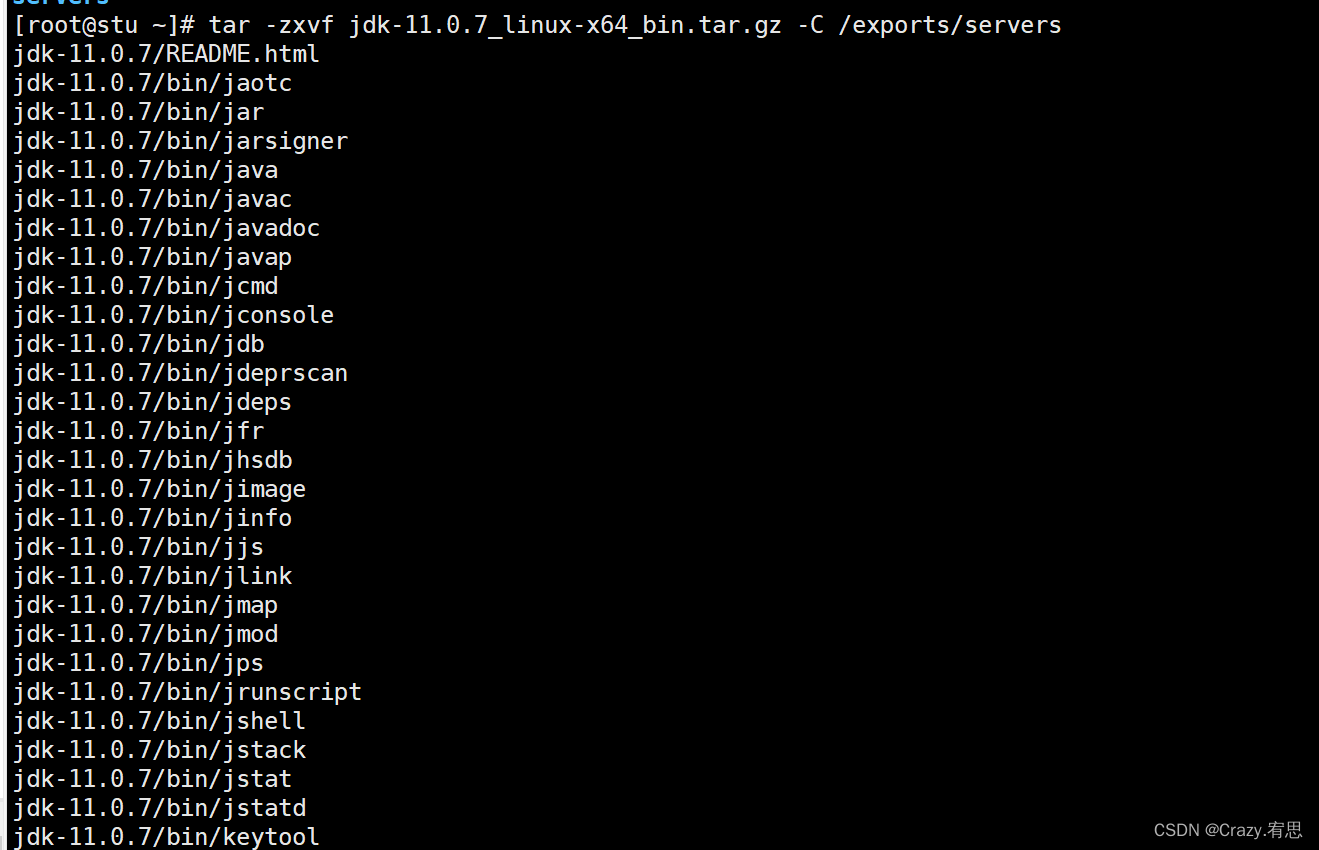
(5)查看/exports/servers目录下是否有解压后的文件
命令:ls /exports/servers

(6)配置环境变量
1)将JDK的根目录复制下来,将目录切换到JDK的根目录下
命令:cd /exports/servers/jdk-11.0.7/
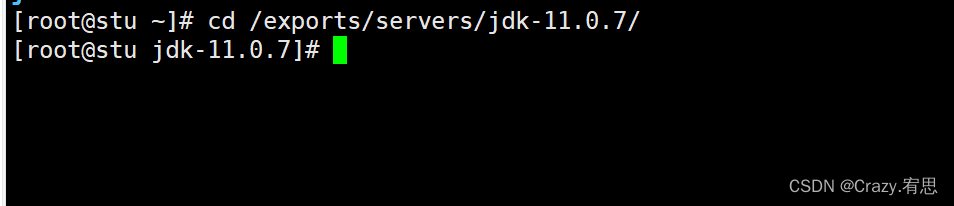
2)复制出现的路径
命令:pwd

3)打开环境变量配置文件
命令:vi /etc/profile
4)在文件末尾添加:
export JAVA_HOME=/exports/servers/jdk-11.0.7
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
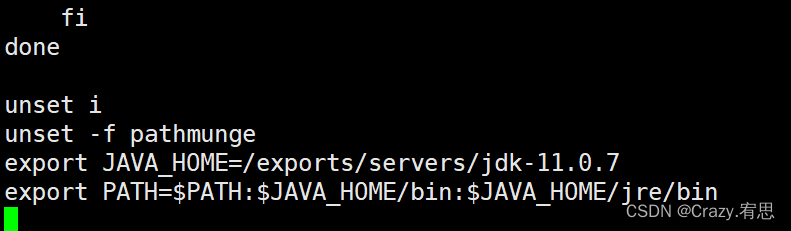
5)保存并退出
(6)重启配置文件并验证环境变量是否配置成功
命令:source /etc/profile
命令:java -version

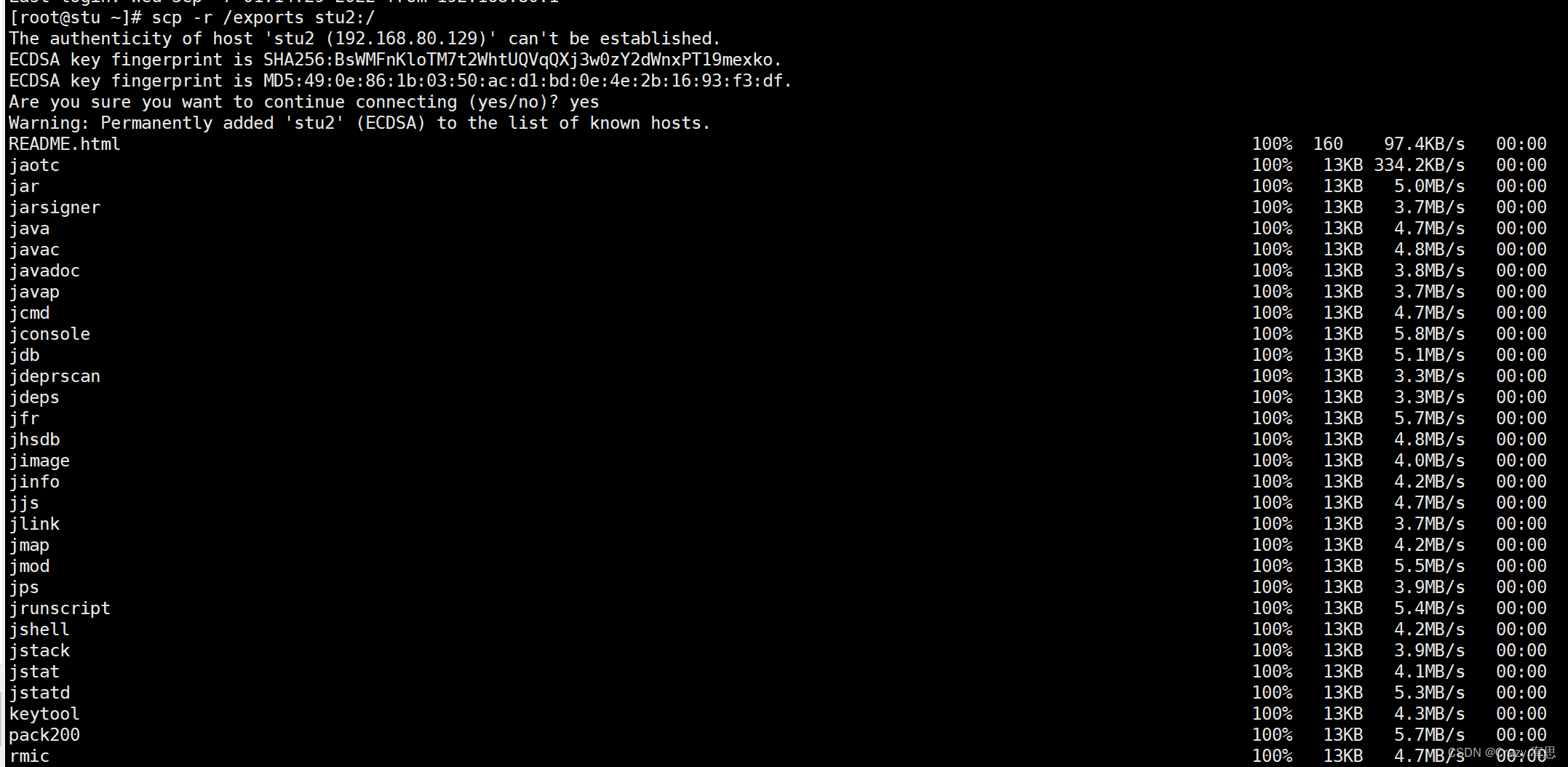
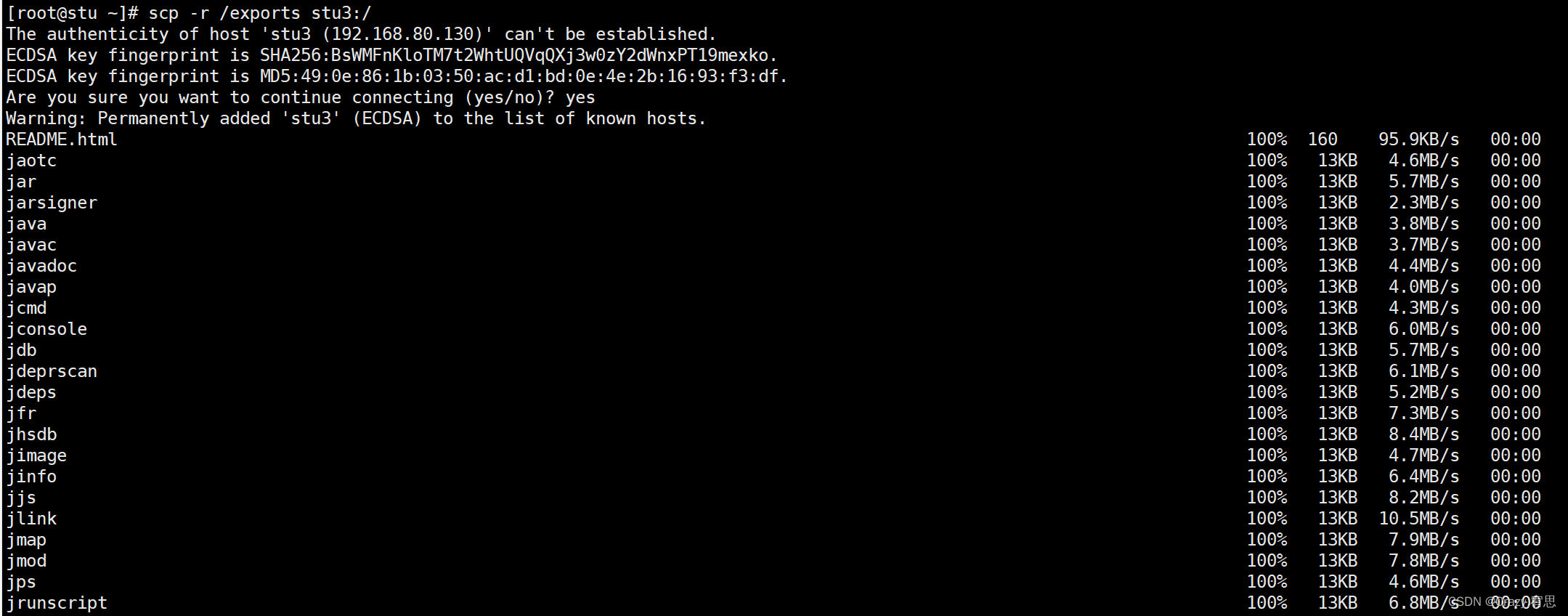
(7)将stu上的/exports目录的内容分别传输到stu2和stu3上
命令:scp -r /exports stu2:/
scp -r /exports stu3:/
(8)将stu上的/etc/profile环境变量配置文件分别发送到stu2和stu3上
命令:scp /etc/profile stu2:/etc/
scp /etc/profile stu3:/etc/
(9)在stu2和stu3上分别执行 source /etc/profile 命令
(10)分别验证stu2和stu3上的环境变量是否配置成功
stu2:
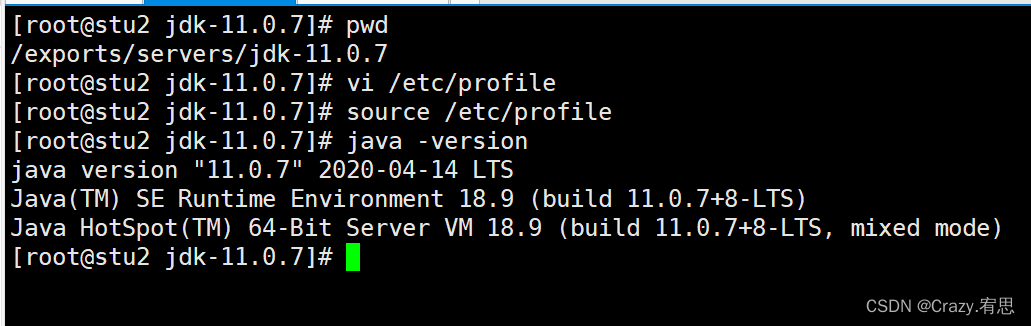
stu3:

7、安装Hadoop(三台机器都需要安装Hadoop,操作都一样,以stu操作为例)
(1)通过传输软件将hadoop-2.7.2.tar.gz上传到stu的root的家目录下
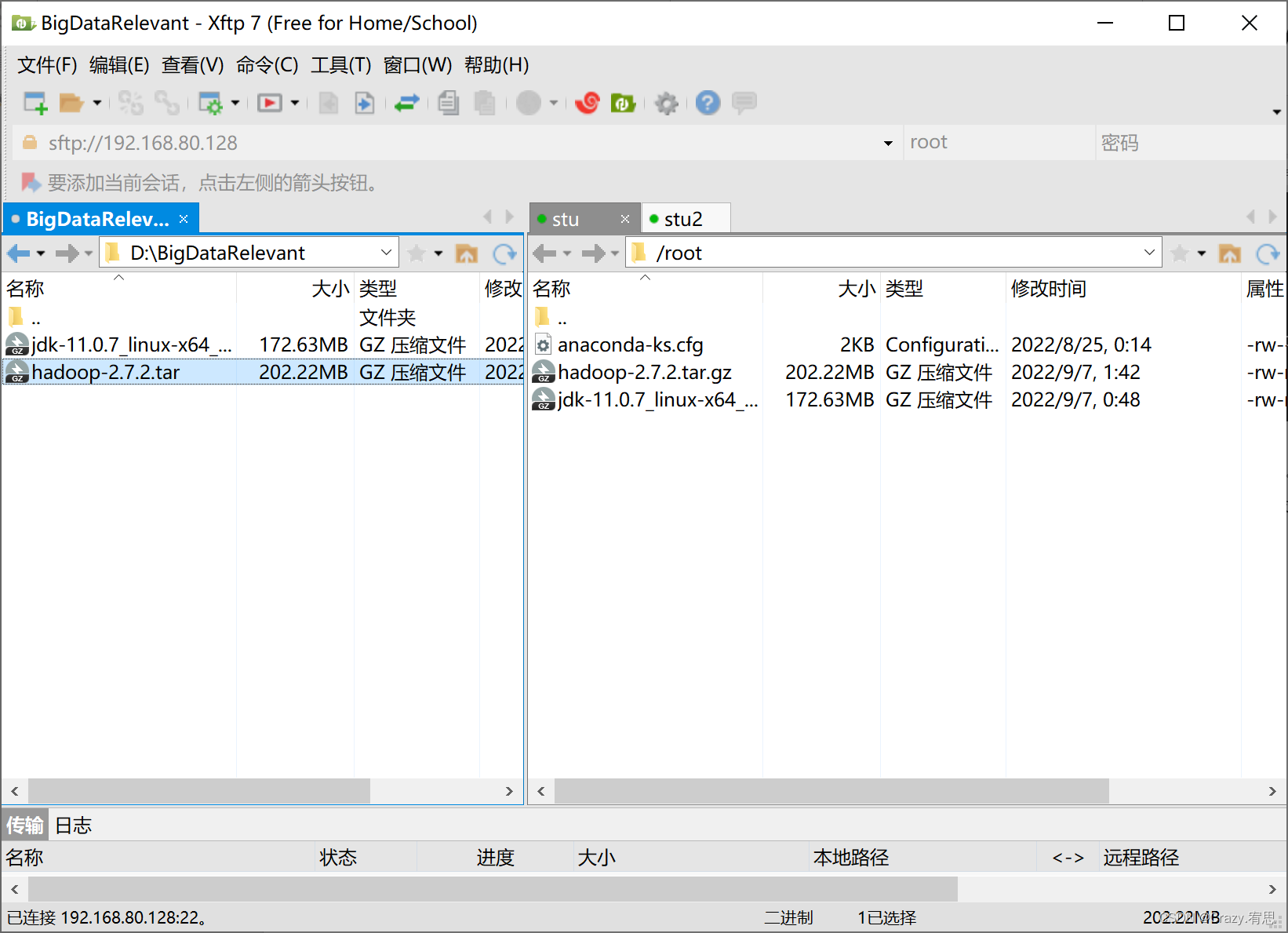
(2)将hadoop-2.7.2.tar.gz解压到/exports/servers目录下
命令:tar -zxvf hadoop-2.7.2.tar.gz -C /exports/servers/
(3)切换到/exports/servers/hadoop-2.7.2目录下
命令:cd /exports/servers/hadoop-2.7.2
(4)在Hadoop的根目录下新建datas目录
命令:mkdir datas
(5)配置Hadoop
进入etc/hadoop目录下,
命令:cd /exports/servers/hadoop-2.7.2/etc/hadoop/
依次修改本目录下的:hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml以及slaves文件:
- 修改hadoop-env.sh文件,在该文件中主要就是配置JAVA_HOME
命令:vi hadoop-env.sh

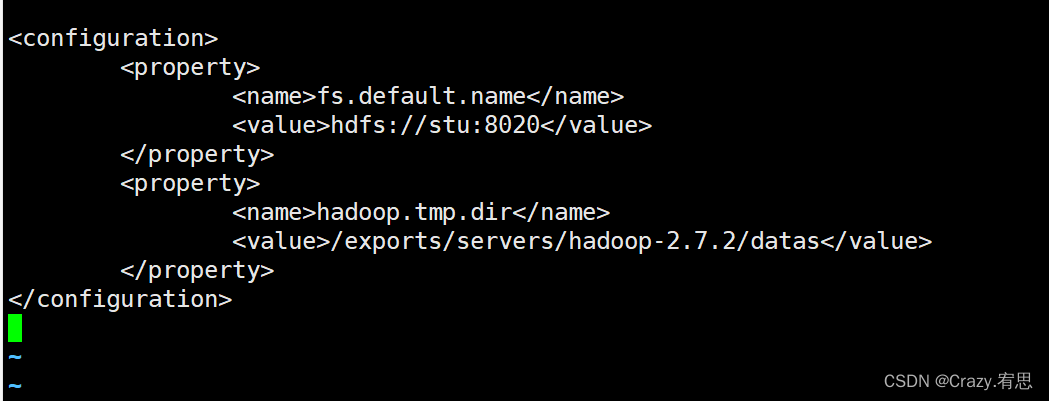
- 修改core-site.xml
命令:vi core-site.xml
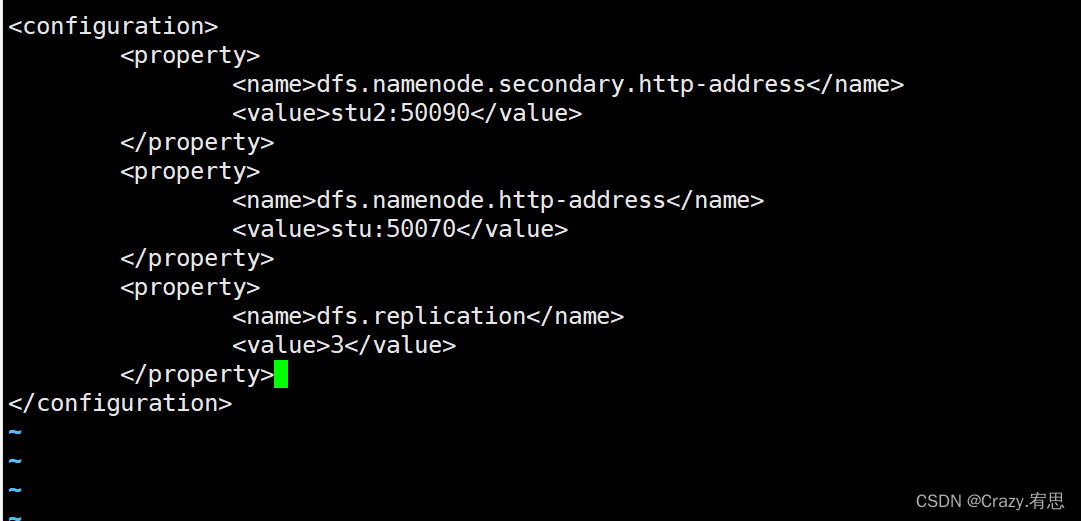
- 修改hdfs-site.xml
命令:vi hdfs-site.xml
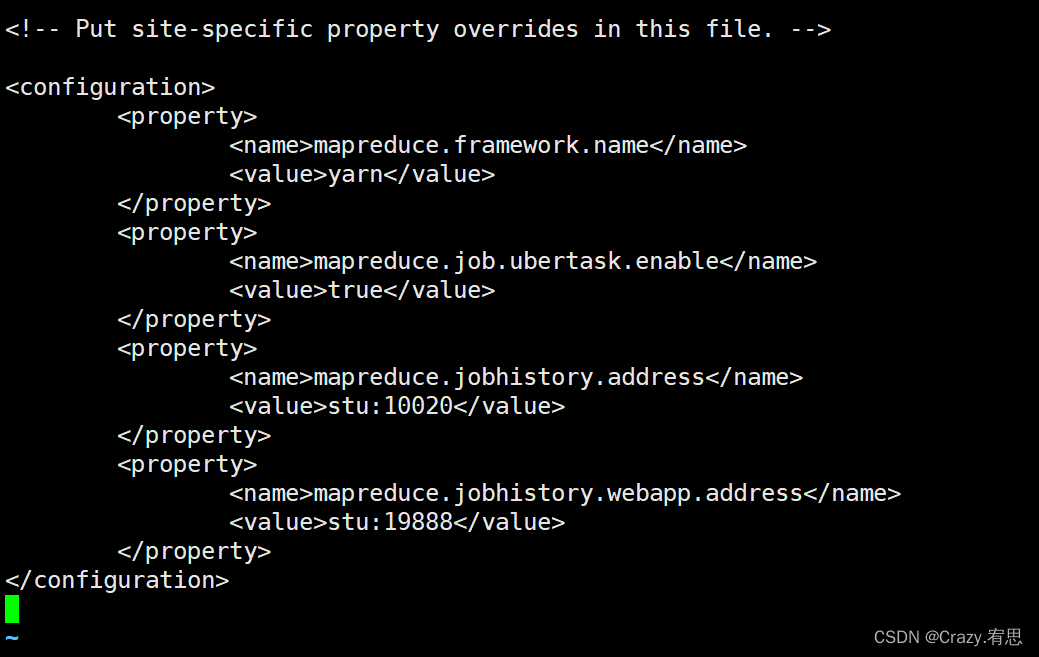
- 修改mapred-site.xml文件
- 在hadoop下没有mapred-site.xml文件,我们需要将mapred-site.xml.template文件修改为mapred-site.xml
命令:cp mapred-site.xml.template mapred-site.xml
打开mapred-site.xml文件
命令:vi mapred-site.xml
- 修改yarn-site.xml
命令:vi yarn-site.xml 
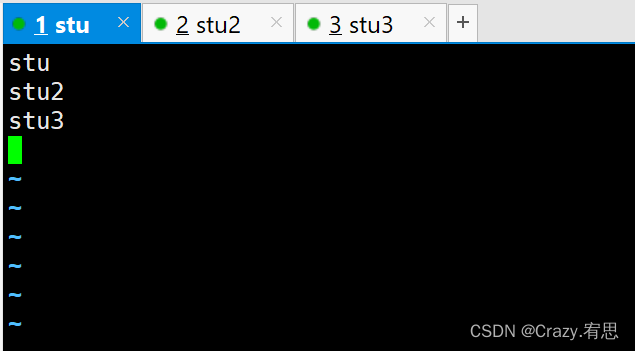
- 配置slaves文件
命令:vi slaves
删除localhost,在文件中加入以下内容:
stu
stu2
stu3
- 将hadoop根目录下的bin中命令加入系统PATH中
命令:vi /etc/profile
加入以下内容
最终文件如下:
export HADOOP_HOME=/exports/servers/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
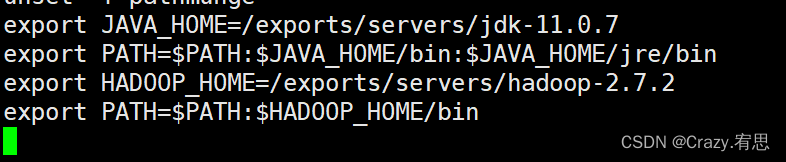
- 验证hadoop
命令:hadoop version
出现如下界面,证明hadoop命令的环境变量配置成功

- 将/exports/servers下hadoop-2.7.2目录中的内容复制到stu2和stu3上
命令:scp -r /exports/servers/ hadoop-2.7.2/ stu2:/exports/servers/
scp -r /exports/servers/ hadoop-2.7.2/ stu3:/exports/servers/
- 将stu上的/etc/profile文件复制到stu2和stu3中
命令:scp /etc/profile stu2:/etc/
scp /etc/profile stu3:/etc/
在stu2和stu3上分别执行命令:source /etc/profile,让环境变量立即生效
8、启动和验证hadoop集群
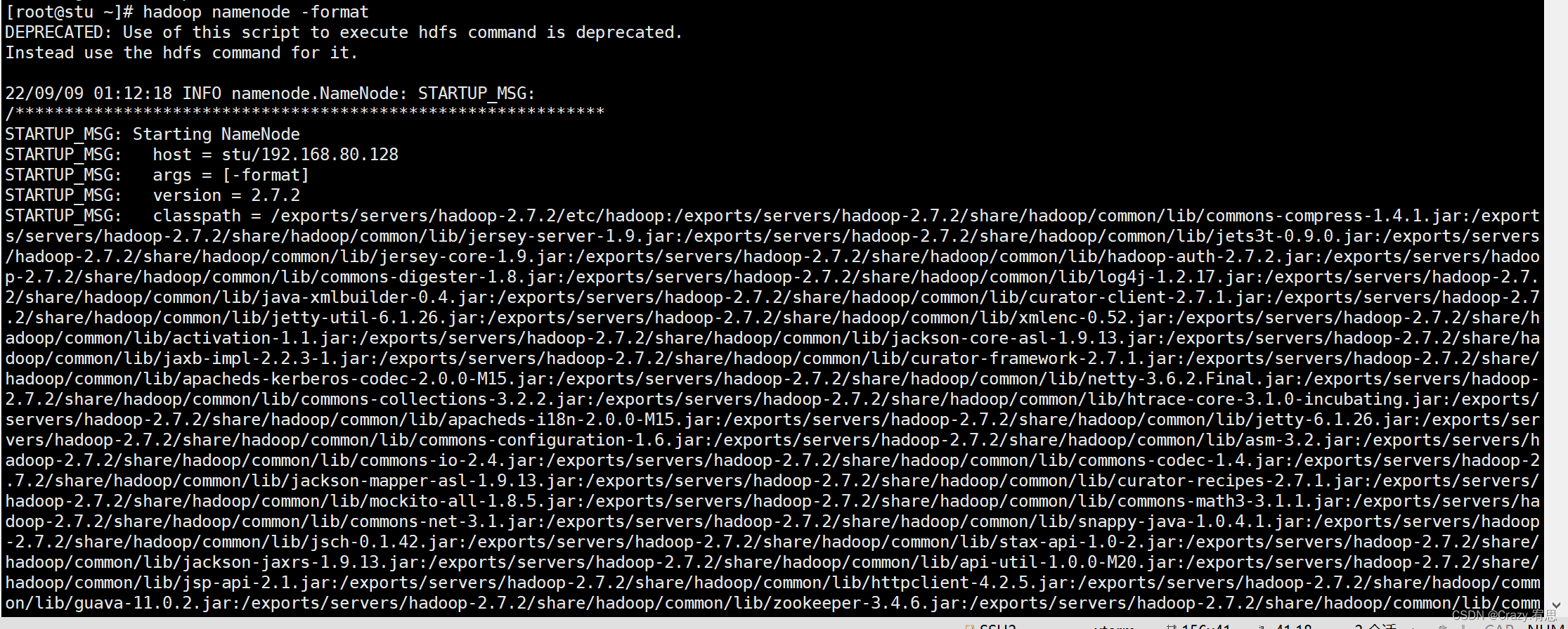
(1)格式化namenode(stu上执行)
命令:hadoop namenode -format
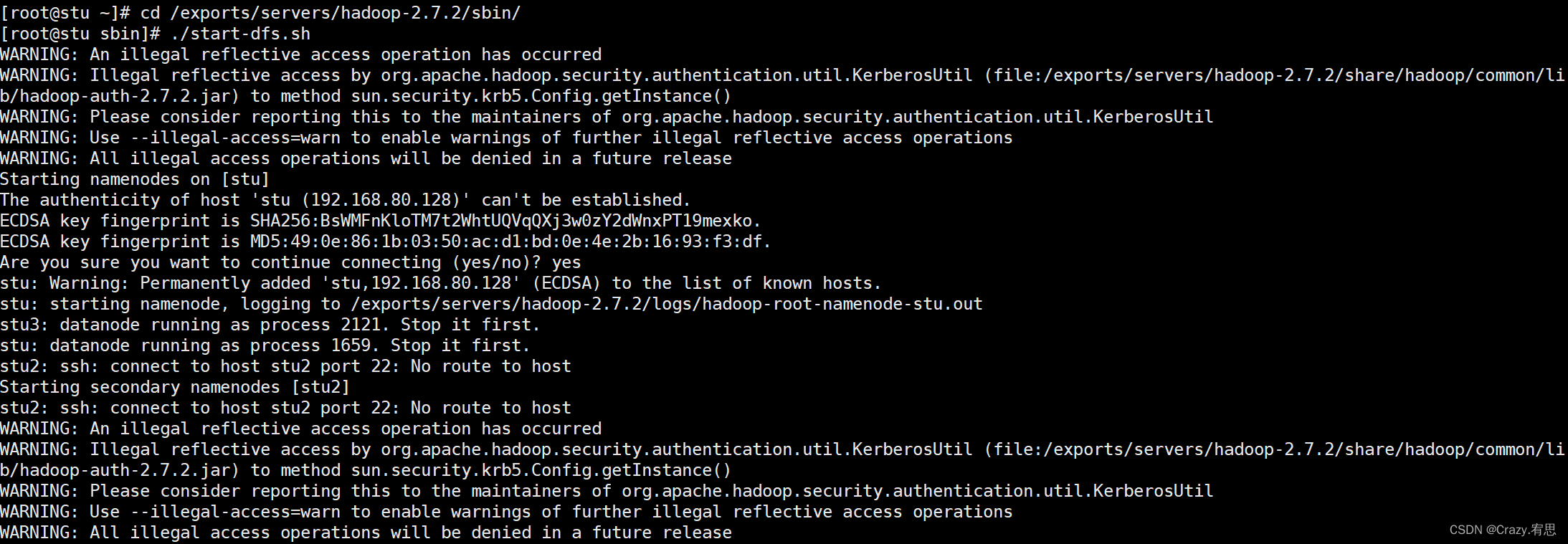
(2)启动集群(stu上执行)
将目录切换到hadoop的sbin目录下:
命令:cd /exports/servers/hadoop-2.7.2/sbin/
执行命令:./start-dfs.sh
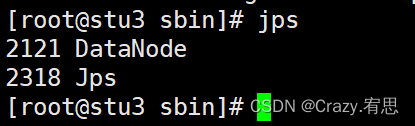
(3)验证集群是否启动成功
命令:jps
stu:
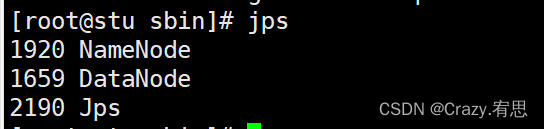
stu2:
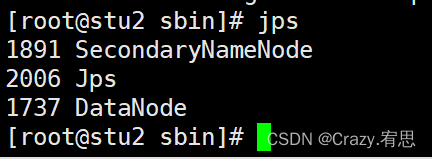
stu3:
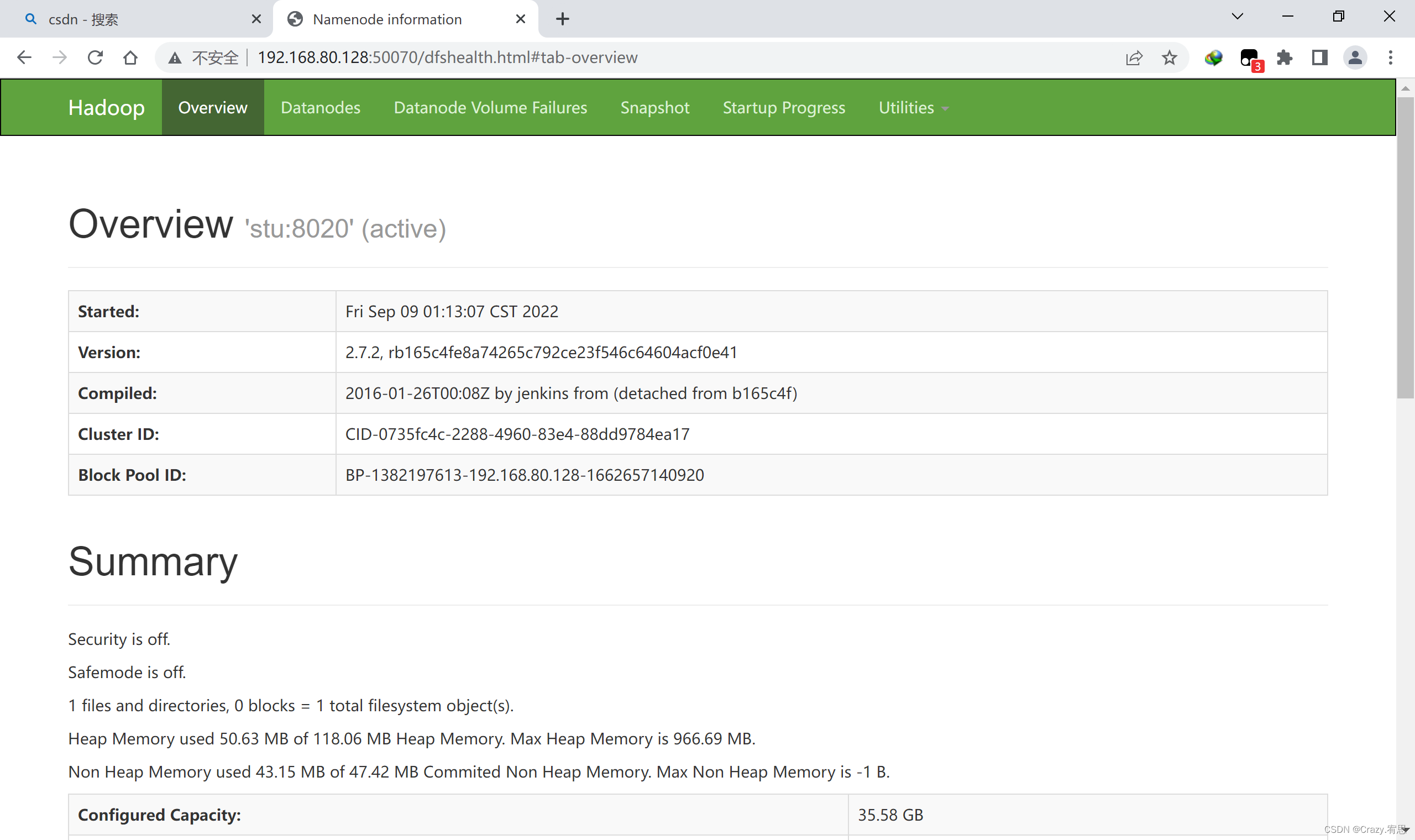
(4)打开浏览器,在浏览器中输入http://192.168.80.128:50070/
版权归原作者 Crazy.宥思 所有, 如有侵权,请联系我们删除。