
正则表达式
概念
正则表达式是用于匹配字符串中字符组合的模式。在 JavaScript中,正则表达式也是对象。这些模式被用于 RegExp 的 exec 和 test 方法, 以及 String 的 match、matchAll、replace、search 和 split 方法。
创建正则表达式
两种方法:字面量方式、构造函数方式
//字面量方式,其由包含在斜杠之间的模式组成,如下所示:var re =/ab+c/;//构造函数方式,调用RegExp对象的构造函数,如下所示:var re =newRegExp("ab+c");
正则表达式常用方法
- 校验数据
test(字符串)
测试字符是否满足正则表达式规则,如果测试到有,则返回true;没有则返回flase
语法:正则表达式.test(字符串) 正则表达式提供的方法
var reg=/[123]/var str='1'var result=reg.test(str)
console.log(result)//flase
search(正则表达式)
search() 方法执行正则表达式和 String 对象之间的一个搜索匹配。
语法:字符串.search(正则表达式) 字符串提供的方法
var reg=/\d///匹配阿拉伯数字var str="abcdefg3sgbh"var res=str.search(reg)
console.log(res)//7//验证方法 找到返回下标 找不到返回-1//在字符串中找到满足正则表达式的那一部分
区别:
.test()方法是正则表达式提供的,.search()是字符串提高的,
.test()方法返回布尔值,search()返回下标
- 提取数据
正则表达式.exec(字符串)
exec() 方法在一个指定字符串中执行一个搜索匹配。返回一个结果数组或 null。 正则表达式提供的方法
var reg=/\d/var str="abcd456efg"var res=reg.exec(str)
console.log(res)//返回一个数组,内容是4//字符串中满足正则表达式的部分提取出来//遇到满足条件的就返回,所以只返回4
字符串.match(正则表达式)
match() 方法检索返回一个字符串匹配正则表达式的结果。 字符串提供的方法
var reg=/\d/var str="abcd456efg"var res=str.match(reg)//字符串中满足表达式的部分提取出来
console.log(res)
区别:
正则表达式.exec(字符串),正则表达式提供的方法
字符串.match(正则表达式) 字符串的方法
相同:
都返回一个数组,只要匹配到符合规则的数据就返回
- 替换数据
字符串.replace(正则表达式,新的内容)
replace() 方法返回一个由替换值(replacement)替换部分或所有的模式(pattern)匹配项后的新字符串。模式可以是一个字符串或者一个正则表达式,替换值可以是一个字符串或者一个每次匹配都要调用的回调函数。如果pattern是字符串,则仅替换第一个匹配项。字符串提供的方法
var reg=/\d/var str="11123bcd"var res=str.replace(reg,"a")//将数字换为a
console.log(res)//a1123bcd 只要匹配到符合规则的就返回
断言

范围类
在[]组成的类内部是可以连写的
let text ='a1B2d3X4Z5'let reg=/[a-zA-Z]/
text.replace(reg,'Q')//Q1Q3Q4Q5
字符类

字符类取反
很多时候碰到这么一种情况,即不想匹配某些字符,其他都匹配。此时,可以使用字符类取反——使用元字符^,创建反向类,即不属于某类的内容。
[^abc]表示不是字符a或b或c的内容
let reg=/[^abc]/glet text='a1b2c3d4e5'
console.log(text.replace(reg,'X'))//输出aXbXcXdXeX
修饰符
在正常情况下,正则匹配到第一个匹配项则停止,并且默认大小写敏感,如果想修改默认选项,则需要修饰符。
g:global全文搜索
var reg=newRegExp('l');var a='hello'.replace(reg,'f')
console.log(a)//输出结果为:heflo
var reg=newRegExp('l','g');//加上g标签表示全文搜索var a='hello'.replace(reg,'f')
console.log(a)//输出结果为:heffo (所有的 l 都换成了 f )
i:ignore case 忽略大小写
var reg=newRegExp('l','g');var a='helloHELLO'.replace(reg,'f')
console.log(a)//输出结果为:heffoHELLO
var reg=newRegExp('l','gi');//加上i标签表示忽略大小写var a='helloHELLO'.replace(reg,'f')
console.log(a)//输出结果为:heffoHEffO (大写和小写的l都被替换了)
m:multiple lines 多行搜索
var reg=newRegExp('od')var str='so good\n so good'var result=str.replace(reg,'hi')
console.log(result)//结果为:
so gohi
so good
//只给第一行匹配了
var reg=newRegExp('od','gm')//加上m标签表示多行匹配var str='so good\n so good'var result=str.replace(reg,'hi')
console.log(result)//结果为:
so gohi
so gohi
其他标志符
s:允许 . 匹配换行符。
u:使用unicode码的模式进行匹配。
y:执行“粘性(sticky)”搜索,匹配从目标字符串的当前位置开始。
量词符
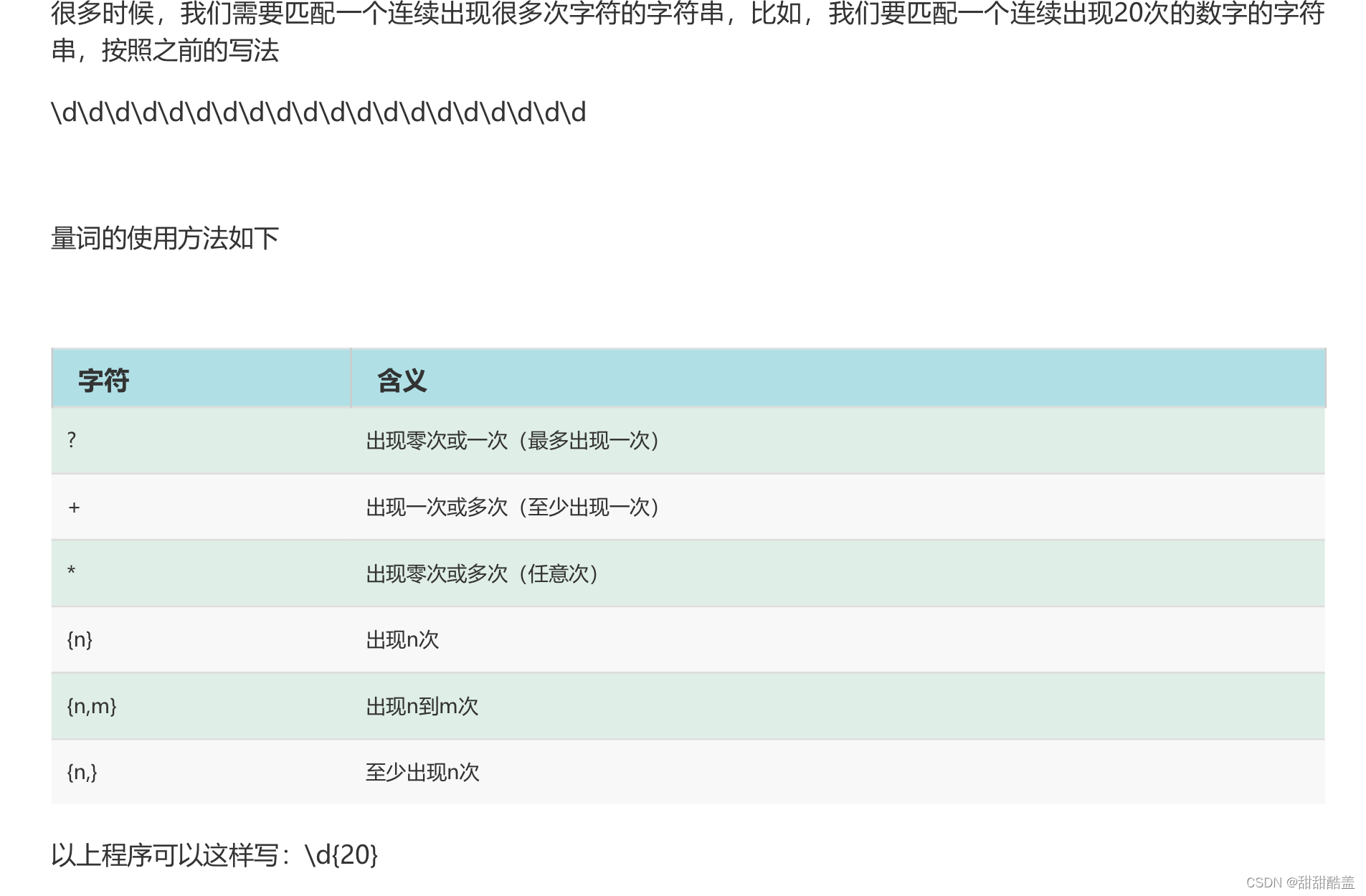
贪婪模式
之前说了正则表达式的量词,但量词会带来一个到底匹配哪个的问题
例如:
var str="12345678"var reg=/\d{3,6}/g
str.replace(reg,'X')//X78
可以看到结果是将123456 六个数字替换成了X,所以我们可以得到,正常模式下,正则表达式会尽可能多的匹配。正常情况下,正则表达式采用贪婪模式,即,尽可能多的匹配。
非贪婪模式
一但成功匹配不再继续尝试,这就是非贪婪模式。
只需要在量词后加上?即可
var str="12345678"var reg=/\d{3,6}?/g
str.replace(reg,'X')//X45678
分组
在使用正则表达式的时候会想要匹配一串字符串连续出现多次的情况,使用()可以达到分组的功能
例如:
(hello){3}
使用符号 | (或)实现选择的功能
例如:
var str='12341235'let reg=/123(4|5)/g//1234 1235二选一
反向引用
将一种格式的时间字符串:yyyy-MM-DD转为MM/DD/yyyy类型格式字符串。
由于年月日是不固定的,没法直接转换为固定数值。这时我们可以使用反向引用解决这个问题。
利用$n,n代表着分组的序号,序号是从1开始的。
例如:
let text='2022-02-23'let reg=/(\d{4})-(\d{2})-(\d{2})/let res=text.replace(reg,'$3/$2/$1')//将yyyy-MM-DD转换为MM/DD/yyyy
console.log(res)
版权归原作者 甜甜酷盖 所有, 如有侵权,请联系我们删除。