
1. Kafka是什么
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个按照分布式事务日志架构的大规模发布/订阅消息队列
流平台具有三个关键功能:
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 容错的持久方式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险·。
- 流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
Kafka 主要有两大应用场景:
- 消息队列 :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
- 数据处理: 构建实时的流数据处理程序来转换或处理数据流
和其他消息队列相比,Kafka的优势在哪里?
- 极致的性能 :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
- 生态系统兼容性无可匹敌 :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
2.为什么会有消息系统
想象一下,你正在一家繁忙的快递公司工作。每天,人们需要寄送各种包裹,而你们的任务是确保这些包裹能够准确、及时地送达。
现在,快递公司就好比是一个大型的系统,而你就是这个系统中的一个员工。在过去,你们可能是直接面对顾客,顾客来了,你就立刻处理他们的包裹,反馈给他们。这就好比直接的同步通信:顾客来了,你立即处理,然后给予反馈。
但是,随着业务的增长,人们寄送的包裹也越来越多,来来往往的顾客也变得越来越多。这时候,直接面对顾客的方式显然已经不够高效了。你们需要一种更有效率的方式来处理这些包裹,同时不至于让顾客等待太久。
于是,你们引入了一个新的系统:消息系统。这个消息系统就好比是一个中转站,顾客把包裹寄到这个中转站,然后你们可以按照自己的节奏来处理这些包裹,而不需要直接面对顾客。当你们处理完一个包裹,就把它发送给下一个节点(比如派送员),然后继续处理下一个包裹。这样,你们就可以更有效率地处理大量的包裹了。
这个消息系统有几个重要的特点:
- 解耦和异步通信:你们不再需要直接面对顾客,而是通过消息系统来收发包裹,这样就实现了解耦。而且,你们可以根据自己的节奏来处理这些包裹,这就是异步通信的特点。
- 消息持久化和可靠性:消息系统会确保每个包裹都被妥善处理,并且即使在处理过程中发生故障,也能够保证不会丢失。
- 扩展性:随着业务的增长,你们可以轻松地扩展消息系统,以应对更多的包裹和顾客。
总的来说,引入消息系统让你们的工作更加高效,让你们能够更好地处理大量的包裹,同时也提高了服务的可靠性和扩展性。
3. Kafka基本概念
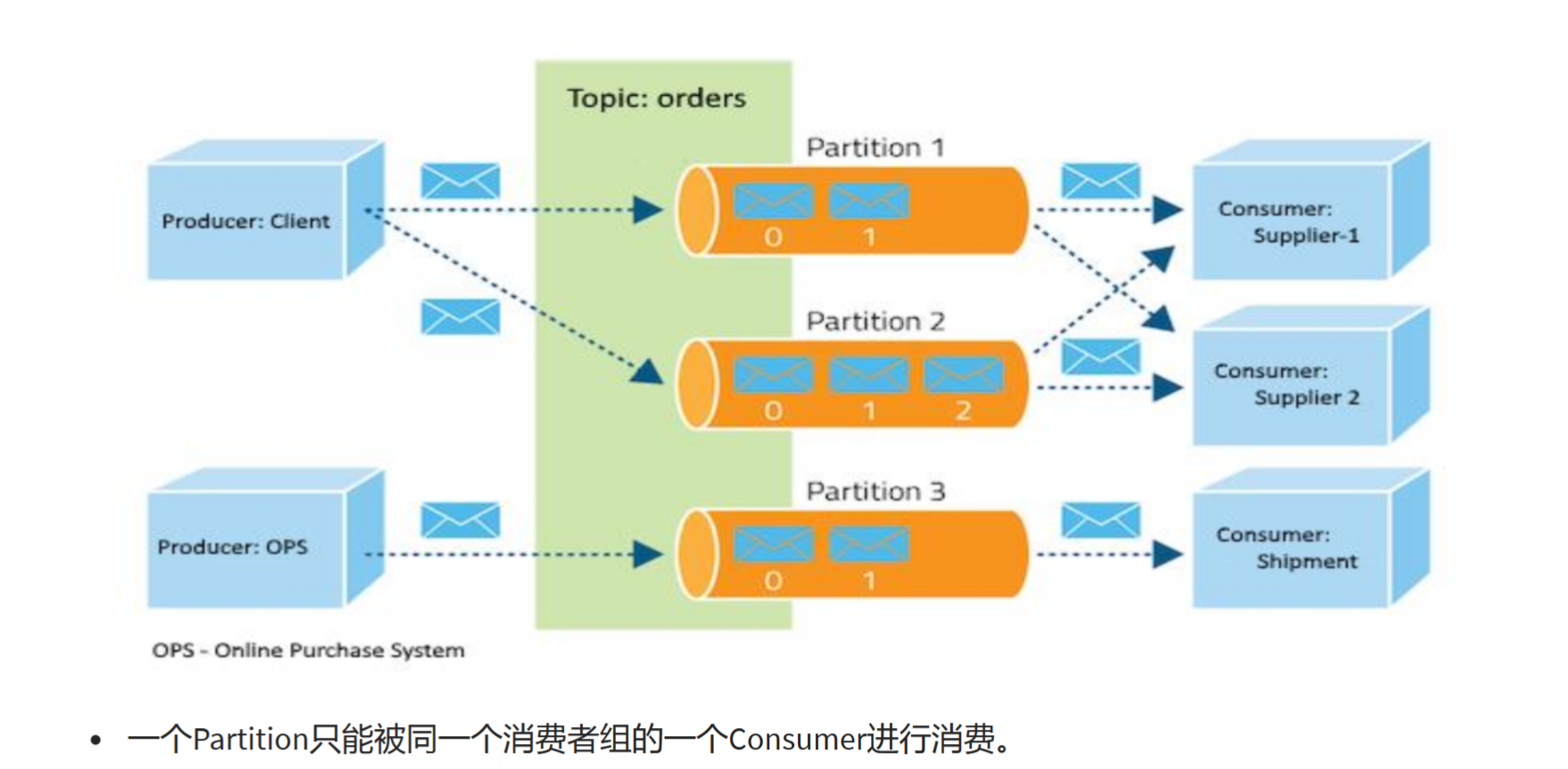
- 主题(Topics): - 主题是 Kafka 中的基本单位,用于对消息进行分类和组织。可以将主题想象成一个具有唯一名称的逻辑容器,用于存储相关联的消息。- 消息被发布到主题中,并且可以通过订阅主题来消费。- 例如,一个电商网站可以有一个名为 “orders” 的主题,用于存储用户订单的消息。
- 分区(Partitions): - 每个主题可以分成一个或多个分区,每个分区是一个有序的消息队列。- 分区允许 Kafka 横向扩展并提高并发性能,因为不同的分区可以在不同的服务器上进行处理。- 消息在分区中的顺序是保证的,但在不同分区之间的顺序不受保证。- 例如,“orders” 主题可以分成多个分区,每个分区存储不同用户的订单消息。
- 生产者(Producers): - 生产者是将消息发布到 Kafka 主题的客户端应用程序。- 生产者负责将消息发送到指定的主题,可以选择性地指定将消息发送到哪个分区。- 例如,电商网站的订单服务可以作为生产者,将用户提交的订单消息发送到 “orders” 主题。
- 消费者(Consumers): - 消费者是从 Kafka 主题中消费消息的客户端应用程序。- 消费者订阅一个或多个主题,并且从指定的分区中读取消息。- 消费者可以以不同的速率消费消息,并且可以以不同的消费者组来组织。- 例如,电商网站的库存服务可以作为消费者,从 “orders” 主题中读取订单消息并更新库存信息。
- 代理(Brokers): - 代理是 Kafka 集群中的服务器节点,负责存储和处理消息。- 每个代理都是一个独立的 Kafka 服务器,它们协同工作来构成一个完整的 Kafka 集群。- 代理负责管理主题的分区,处理生产者和消费者的请求,并维护消息的持久化存储。- 一个 Kafka 集群可以包含一个或多个代理。
- 消费者组(Consumer Groups): - 消费者可以组成消费者组来消费一个主题中的消息。- 每个消费者组可以有多个消费者,但一个分区只能由同一个消费者组中的一个消费者消费。- 消费者组可以实现消息的并行消费和负载均衡,从而提高消费性能和容错能力。- 例如,库存服务的多个实例可以组成一个消费者组,共同消费 “orders” 主题中的订单消息。
- 偏移量(Offset): - 偏移量是消息在分区中的唯一标识,用来表示消息在分区中的位置。- 消费者使用偏移量来记录自己读取到了分区中的哪个位置,从而实现消息的持久化和可靠性。- Kafka 提供了一种偏移量管理机制,消费者可以定期提交当前读取的偏移量,以确保消息不会被重复消费或丢失。- 例如,消费者可以记录下一个要读取的偏移量,以便在下次启动时从正确的位置继续消费消息。
4. Kafka架构和特点
Kafka 基于发布-订阅模型,使用持久化存储、分区和复制、消息推送和拉取等机制来实现高吞吐量、可靠性和可扩展性。
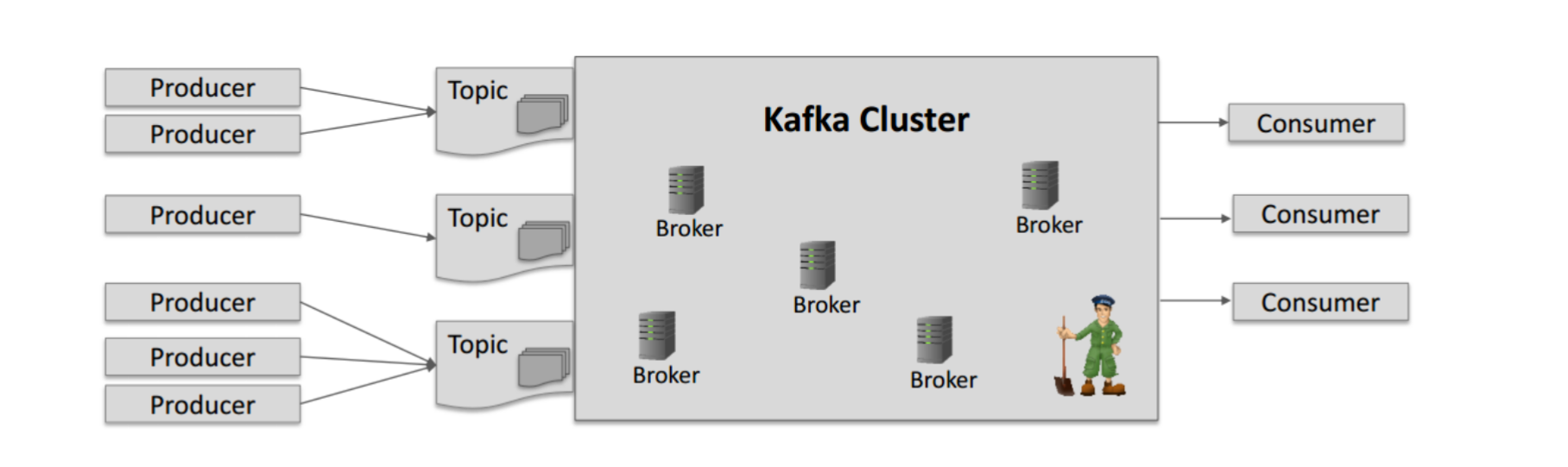
Kafka 架构
- Producer:生产者负责向 Kafka 集群的一个或多个主题发送消息。
- Broker: Broker 是 Kafka 集群中的服务器节点,每个 Broker 都存储了一个或多个主题的消息数据,并负责处理生产者和消费者的请求。
- Topic:主题是 Kafka 中消息的分类标签,消息被发布到一个或多个主题中。
- Partition:每个主题可以分成一个或多个分区,每个分区是一个有序的消息队列,消息被顺序写入并且每条消息都有一个唯一的偏移量。
- Consumer Group:消费者组是一组消费者的集合,每个消费者组消费一个主题中的消息。消费者组可以实现消息的并行消费和负载均衡。
Kafka 特点
- 发布-订阅模型:Kafka 使用发布-订阅模型,生产者将消息发布到一个或多个主题中,而消费者订阅一个或多个主题来消费消息。
- 持久化存储:Kafka 将消息持久化地存储在磁盘上,以保证消息的可靠性和持久性。消息被追加到主题的分区中,并且可以根据配置的保留策略来自动删除旧的消息。
- 分区和复制:每个主题可以分成一个或多个分区,并且每个分区可以有多个副本存储在不同的 Broker 上。分区和副本的存在提高了消息的可用性和容错性。
- 消息推送和拉取:Kafka 支持两种消息传递模式:生产者将消息推送到 Broker,而消费者从 Broker 拉取消息。这种模式允许消费者以自己的速率消费消息,并且可以有效地处理高吞吐量的消息流。
- 偏移量管理:消费者使用偏移量来记录自己读取到的位置,以便在下次启动时继续消费消息。Kafka 提供了一种偏移量管理机制,消费者可以定期提交当前读取的偏移量,以确保消息不会被重复消费或丢失。
- 水平扩展:Kafka 具有良好的水平扩展性,可以通过增加 Broker、增加主题分区、增加消费者组等方式来扩展集群的吞吐量和容量。
5. Kafka基本命令
#这条命令用于列出 Kafka 集群中的所有主题。
kafka-topics.sh --zookeeper hadoop5:2181 --list#这条命令用于在 Kafka 集群中创建一个名为 "demo1" 的主题,该主题有 1 个分区和 1 个副本
kafka-topics.sh --zookeeper hadoop5:2181 --create--topic demo1 --partitions1 --
replication-factor 1#这条命令用于删除名为 "demo1" 的主题。需要注意的是,删除主题需要在 Kafka 的配置文件#server.properties中开放delete.topic.enable=true才可以删除
kafka-topics.sh --zookeeper hadoop5:2181 --delete--topic demo1
#这条命令用于启动一个生产者,允许你手动输入消息并发送到名为 "demo2" 的主题中
kafka-console-producer.sh --broker-list hadoop5:9092 --topic demo2
#这条命令用于启动一个消费者,用于消费名为 "demo2" 的主题中的消息,并从最早的消息开始消费。
kafka-console-consumer.sh --bootstrap-server hadoop5:9092 --from-beginning --topic
demo2
#这条命令用于显示名为 "demo1" 的主题的详细信息,包括分区、副本分配情况等。
kafka-topics.sh --zookeeper hadoop5:2181 --describe--topic demo1
#这条命令用于修改名为 "demo1" 的主题的分区数,这里将分区数增加到了 3 个。需要注意的是,Kafka 中分区数只能增加,不能减少
kafka-topics.sh --zookeeper hadoop5:2181 --alter--topic demo1 --partitions3#这条命令用于重置指定应用程序的偏移量,以便从指定的输入主题重新开始消费消息
kafka-streams-application-reset.sh --zookeeper hadoop5:2181 --bootstrap-servers
hadoop5:9092 --application-id consumer_user1 --input-topics demo3
6. Kafka的索引机制
1.消息存储和检索:
- Kafka 的消息存储和检索是基于分区和偏移量来实现的。当生产者向 Kafka 发送消息时,消息会被追加到相应主题的分区中,并且每个消息都会被分配一个递增的偏移量。
- 当消费者从 Kafka 中消费消息时,它会指定要消费的主题和分区,以及开始消费的偏移量。Kafka 会根据指定的分区和偏移量来检索消息,并将消息传输给消费者。
- Kafka 的存储设计是基于顺序读写的,因此它可以高效地进行消息的存储和检索
- Kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。
- Topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中 存储的就是producer生产的数据。Producer生产的数据会被不断追加到该log文件末端,且每条数据 都有自己的offset。消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢 复时,从上次的位置继续消费。---
- Kafka 中的索引文件(.index)以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消 息在索引文件中都有对应的索引项,也就是说 Offset 是不连续的,是一个区间范围。
索引文件记录的索引项是这样的
索引项1: 偏移量范围 [0, 99] - 物理位置 0
索引项2: 偏移量范围 [100, 199] - 物理位置 1000
索引项3: 偏移量范围 [200, 299] - 物理位置 2000
现在,假设我们要找到偏移量为 150 的消息。由于索引文件中没有直接记录偏移量为 150 的索引项,因此我们可以使用稀疏索引的方式来定位消息的位置。我们首先找到索引文件中最接近偏移量为 150 的索引项,即索引项2,该索引项记录了偏移量范围为 [100, 199] 的消息在日志文件中的起始物理位置为 1000。然后,我们在日志文件中从物理位置 1000 开始向后查找,直到找到偏移量为 150 的消息。
这就是稀疏索引的工作原理:它不需要记录每个消息的偏移量,而是通过记录消息偏移量范围和起始物理位置的方式,快速地定位到消息在日志文件中的位置。这样,即使索引文件中的索引项是不连续的,我们仍然可以快速地定位到消息的位置。
这种稀疏索引的设计有以下几个优点:
- 减小索引文件的大小:由于不是每个消息都有对应的索引项,索引文件的大小会相对较小,节省了磁盘空间。
- 加速定位速度:即使索引文件中的索引项是稀疏的,但仍然可以通过插值或二分查找等方式快速地定位到消息在日志文件中的物理位置,从而实现高效的消息读取操作。
- 减少索引维护开销:因为索引项是按照一定的间隔记录的,而不是每个消息都记录一个索引项,这样可以减少对索引文件的更新和维护的开销,提高了系统的性能和可扩展性。
7. Kafka日志文件存储机制
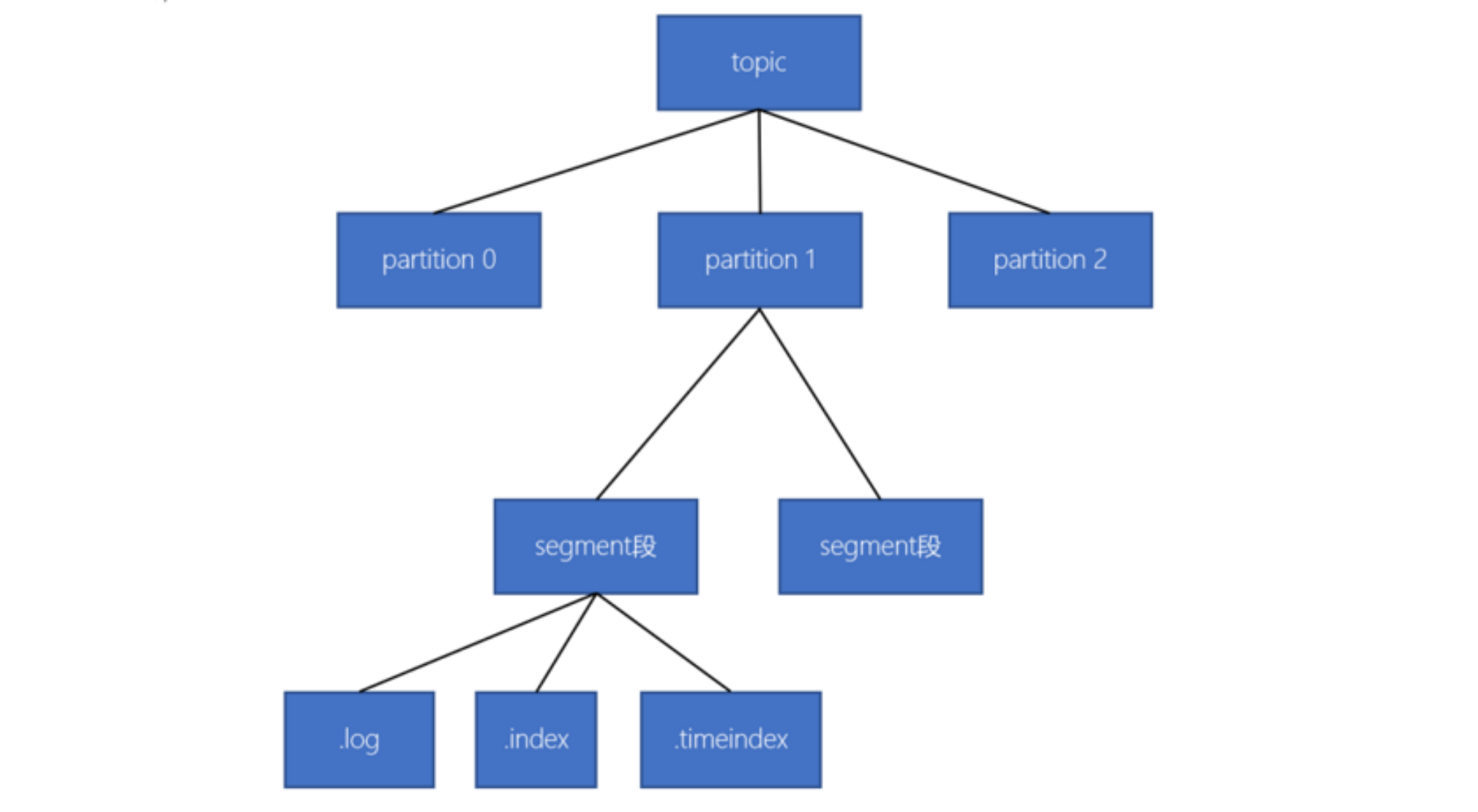
- 一个topic由多个分区组成
- 一个分区(partition)由多个 segment(段)组成
- 一个 segment(段)由多个文件组成(log、index、timeindex)
Kafka 使用日志文件(Log Segments)来持久化存储消息。
Kafka 的日志文件存储机制是基于日志分段的,每个日志分段都是一个固定大小的文件(默认1G),通过滚动和压缩来管理和清理日志文件,以确保消息的持久化存储和高效检索。
日志分段(Log Segments):
- Kafka 的消息被追加到日志文件末尾中,每个主题分区对应一个或多个日志分段。
- 日志分段是固定大小的文件,一旦创建后,它们不会被修改,只能追加新的消息。
日志段滚动(Log Segment Rolling):
- 当一个日志分段达到了预先配置的大小限制(通过
log.segment.bytes参数配置),Kafka 就会创建一个新的日志分段来替代原来的分段。 - 这个过程称为日志段滚动,它确保了日志文件的大小是可控的,并且每个日志分段都是一个独立的文件,便于管理和复制。
日志段压缩(Log Compaction):
- Kafka 提供了日志段压缩机制,用于删除重复的消息和清理过期的消息,以减小磁盘空间的使用。
- 日志段压缩通过 Kafka 的 Log Cleaner 来实现,它定期检查日志文件中的消息,并删除重复的消息或者标记过期的消息。
- 这个过程可以有效地减小日志文件的大小,节省磁盘空间。
索引文件(Index Files):
- 为了加速消息的检索,Kafka 还使用了索引文件(Index Files)来记录消息在日志文件中的位置。
- 索引文件以固定的间隔记录日志文件中的偏移量和物理位置的映射关系,以便消费者可以快速地定位消息。
日志段压缩策略(Log Compaction Policy):
- Kafka 提供了灵活的日志段压缩策略,可以根据应用程序的需求来配置不同的压缩策略。
- 压缩策略可以根据消息的键来删除重复的消息,也可以根据消息的时间戳来删除过期的消息,或者根据自定义的标记来删除消息
8. Kafka读写删
Kafka 的读取、写入和删除操作背后的原理涉及到 Kafka 的整体架构和核心概念。
- 写入(Producing):- 生产者(Producer)将消息发送到 Kafka 集群中的主题(Topic)。- 生产者将消息发送到指定的主题时,消息首先被追加到主题的分区(Partition)中的日志文件(Log Segment)中。(producer负责选择将哪个消息分配给topic中的哪个分区)- 每个分区中的消息都会被分配一个唯一的偏移量(Offset),用于标识消息在分区中的位置。- 生产者可以选择将消息发送到特定的分区,或者让 Kafka 使用分区器(Partitioner)根据消息的键来决定消息应该发送到哪个分区。> 1.指明Partition的情况下,直接将指明的值作为partiton值> 2.没有指明partition值但有key的情况下,将Key的hash值与topic的partition数量进行取余得到> partition值> 3.既没有 partition 值又没有 key 值的情况下,第一次调用时随机生成一个整数(后面每次调用在> 这个整数上自增),将这个值与 topic 可用的 partition 总数取余得到 partition 值,也就是常说> 的 Round-Robin算法
- 读取(Consuming):- 消费者(Consumer)从 Kafka 集群中的主题订阅消息,并消费这些消息。- 消费者通过指定主题和分区来订阅消息,然后从指定的分区中读取消息。- 每个消费者会记录自己读取到的偏移量,以便在下次启动时从上次的位置继续读取消息。
- 删除主题(Deleting Topics):- 删除主题是一项管理操作,需要在 Kafka 集群中执行。- 当执行删除主题操作时,Kafka 首先会停止接受该主题的新消息,并将主题标记为删除状态。- 然后,Kafka 会逐步清理和删除该主题的所有日志分段和索引文件,释放磁盘空间。- 需要注意的是,删除主题是一个慎重的操作,因为一旦删除了主题,所有与该主题相关的消息都将丢失。
- 删除消息(Deleting Messages):- Kafka 并不直接支持删除消息,因为一旦消息被追加到日志文件中,就不会被修改或删除。- 如果需要删除消息,可以通过更新消息来实现,例如,可以发送一个带有标记的特殊消息来表示该消息已经被删除。- 另一种方法是使用消息保留策略(Retention Policy),通过设置较短的消息保留时间来自动删除旧的消息。
9. Kafka数据可靠性保证
Kafka 提供了多种机制来保证数据的可靠性,确保消息不会丢失或被篡改。
副本机制
- Kafka 使用分区的副本机制来确保数据的可靠性。每个分区可以配置多个副本,其中一个副本被选举为主要副本(Leader Replica),其他副本称为追随者副本(Follower Replica)。
- 生产者将消息发送到分区的主要副本,主要副本负责将消息追加到日志文件中。一旦消息被追加到主要副本的日志文件中,Kafka 将异步地将消息复制到其他追随者副本中。
- 如果主要副本发生故障,Kafka 将从追随者副本中选举新的主要副本,确保分区的可用性和数据的完整性。(好处)
ISR(In-Sync Replica)机制
- Kafka 使用 ISR 机制来确保消息的可靠性。ISR 是指与主要副本保持同步的副本集合,只有在 ISR 中的副本才能被选举为主要副本。
- 当追随者副本与主要副本保持同步时,它们被认为是 ISR 中的一部分。如果追随者副本与主要副本失去同步,它将被移出 ISR,直到与主要副本重新保持同步。
消息复制机制
- Kafka 使用消息复制机制来确保消息的可靠性。一旦消息被追加到主要副本的日志文件中,Kafka 将异步地将消息复制到 ISR 中的其他副本中。
- 生产者可以配置消息的可靠性要求(acks 参数),以指定需要等待多少个 ISR 中的副本完成消息复制后才返回确认。
持久化机制
- Kafka 使用持久化机制将消息写入到磁盘中,确保消息在发生故障时不会丢失。
- 消息在被追加到日志文件之前会先写入到操作系统的页缓存中,然后异步地将消息刷写到磁盘中
ack机制
acks=0:
- 当
acks设置为0时,生产者发送消息后不会等待任何确认消息,即异步发送模式。 - 生产者将消息发送给服务器后即返回,不会等待服务器的确认消息。
- 这种模式下,生产者无法确保消息已被成功写入到服务器,可能存在数据丢失的风险。
acks=1:
- 当
acks设置为1时,生产者发送消息后会等待分区的主副本写入成功的确认消息。 - 生产者发送消息后会等待分区的主副本(Leader Replica)确认消息已被成功写入到日志文件中,然后返回确认。
- 这种模式下,生产者可以确保消息至少被写入到分区的主副本中,但可能存在数据丢失的风险,因为消息还未被复制到其他副本。
acks=all 或 acks=-1:
- 当
acks设置为all或-1时,生产者发送消息后会等待所有副本写入成功的确认消息。 - 生产者发送消息后会等待分区的所有副本(包括主副本和追随者副本)确认消息已被成功写入到日志文件中,然后返回确认。
- 这种模式下,生产者可以确保消息被写入到分区的所有副本中,是最安全的确认模式,但会增加延迟
补充
关于 follower 和 leader 故障处理的细节和注意事项
- follower 故障: - 当 follower 发生故障时,它会被临时踢出 ISR(In-Sync Replica)集合。- follower 恢复后,它会读取本地磁盘记录的上次的 HW(High Watermark),即已经成功写入磁盘的最大偏移量。- 然后,follower 将自己的日志文件中高于 HW 的部分截取掉,并从 HW 开始向 leader 进行同步。- follower 必须追上 leader,即 follower 的 LEO(Log End Offset)大于等于该分区的 HW,才能重新加入 ISR。
- leader 故障: - 当 leader 发生故障时,Kafka 会从 ISR 中选出一个新的 leader。- 新的 leader 需要确保与旧 leader 之间的数据一致性,因此其余的 follower 会将各自的日志文件中高于 HW 的部分截取掉,并从新的 leader 同步数据。- 由于 Kafka 使用副本机制和 ISR 机制来保证数据的可靠性和一致性,因此在 leader 故障后,即使选举出新的 leader,也无法保证数据的完整性。这只能保证副本之间的数据一致性,不能保证数据不丢失或者不重复。
- 数据一致性与数据可靠性: - 在 Kafka 中,数据一致性和数据可靠性是两个不同的概念。- 数据一致性指的是分区中的所有副本数据是相同的,即各个副本之间的数据是一致的。- 数据可靠性指的是数据不会丢失或者不会被篡改,即数据在被写入到日志文件后是持久化的。 r 会将各自的日志文件中高于 HW 的部分截取掉,并从新的 leader 同步数据。- 由于 Kafka 使用副本机制和 ISR 机制来保证数据的可靠性和一致性,因此在 leader 故障后,即使选举出新的 leader,也无法保证数据的完整性。这只能保证副本之间的数据一致性,不能保证数据不丢失或者不重复。
- 数据一致性与数据可靠性: - 在 Kafka 中,数据一致性和数据可靠性是两个不同的概念。- 数据一致性指的是分区中的所有副本数据是相同的,即各个副本之间的数据是一致的。- 数据可靠性指的是数据不会丢失或者不会被篡改,即数据在被写入到日志文件后是持久化的。- Kafka 使用副本机制和 ISR 机制来保证数据的一致性,同时使用持久化机制来保证数据的可靠性。但即使数据是一致的,也不能完全保证不丢失或者不重复,因此需要在生产者和消费者端使用适当的配置来确保数据的可靠性和一致性。
版权归原作者 xQil 所有, 如有侵权,请联系我们删除。