
一、pyspark类库
类库:一堆别人写好的代码,可以直接导入使用,例如Pandas就是Python的类库。
框架:可以独立运行,并提供编程结构的一种软件产品,例如Spark就是一个独立的框架。
PySpark是Spark官方提供的一个Python类库,内置了完全的Spark API,可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行。
Pyspark类库和spark对比
功能PySparkSpark底层语言PythonScala(JVM)上层语言支持PythonPython\Java|Scala\R集群化\分布式运行不支持,仅支持单机支持定位Python库(客户端)标准框架(客户端和服务端)是否可以Daemon运行NoYes使用场景本地开发调试Python程序生产环境集群化运行
(1)下载PySpark库
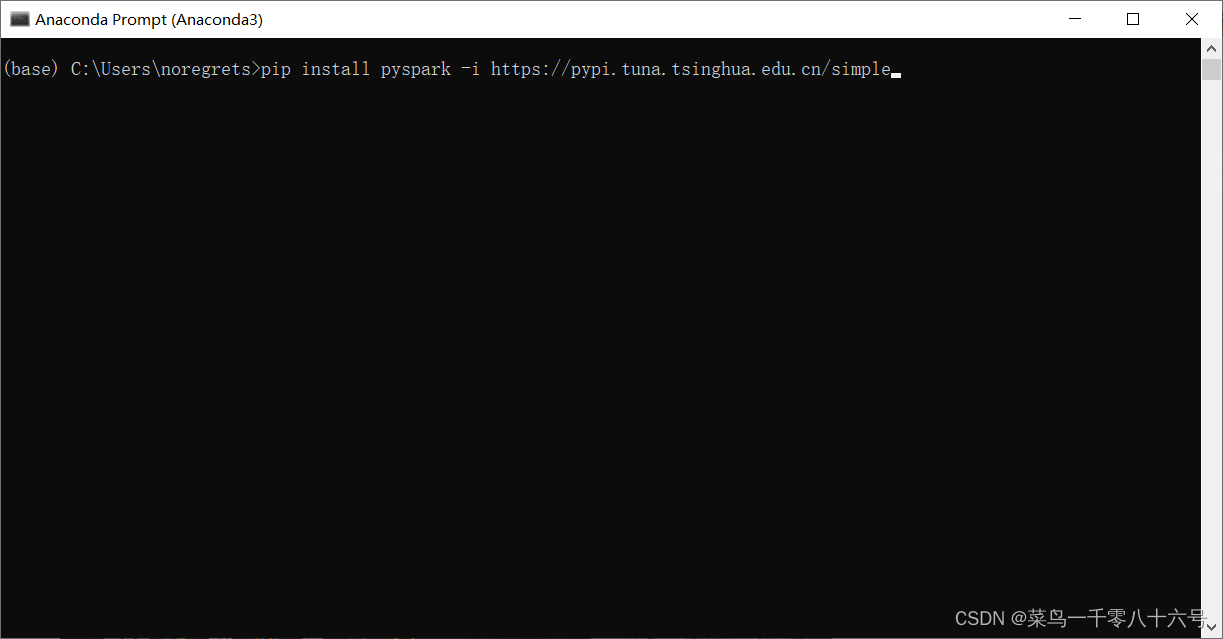
命令:pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
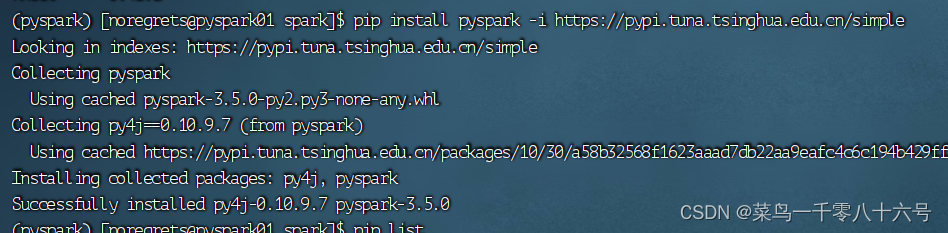
(2)验证Pyspark库
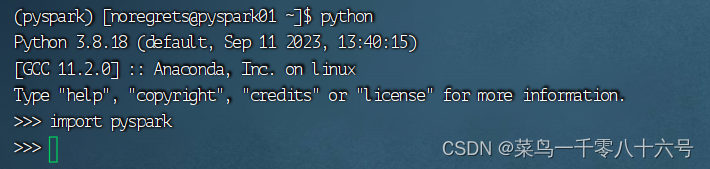
二、window安装anaconda
(1)下载安装包
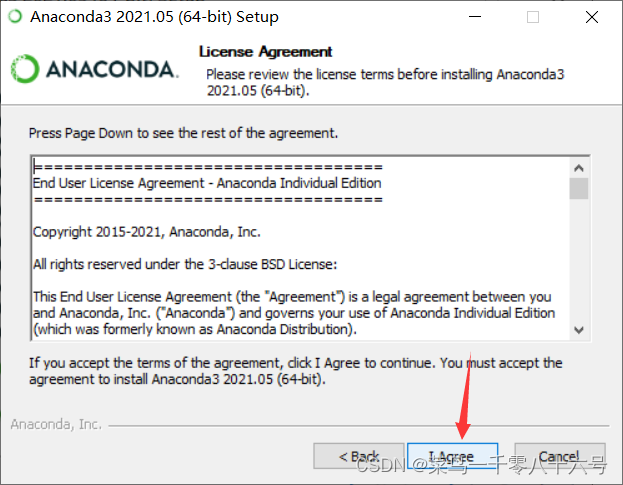
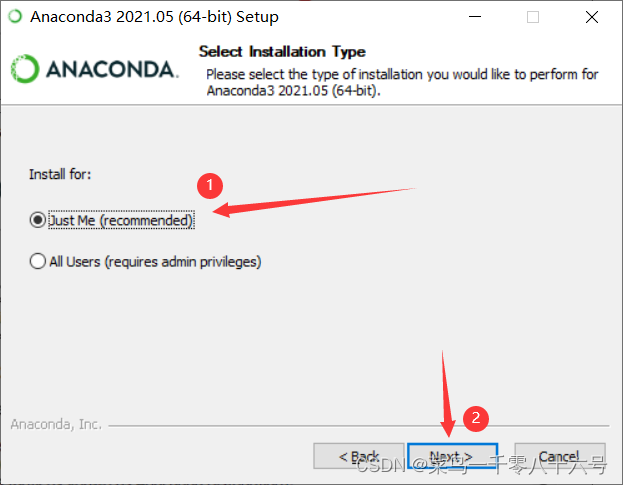
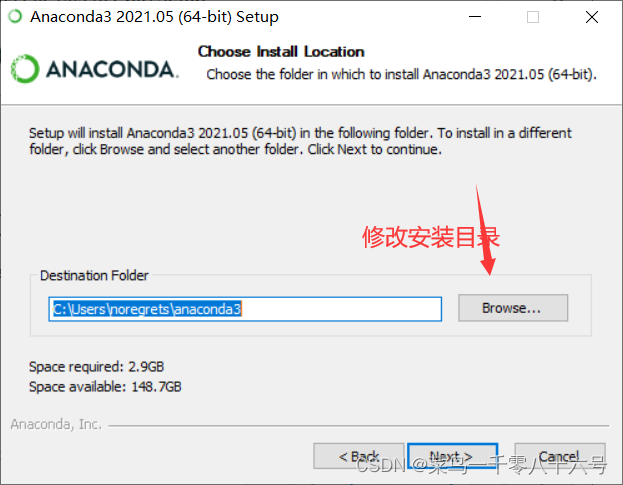
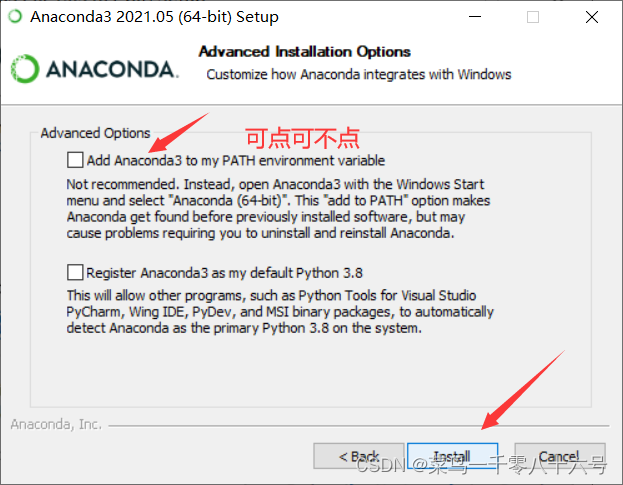
(2)安装anaconda
(3)下载软件包
命令:pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple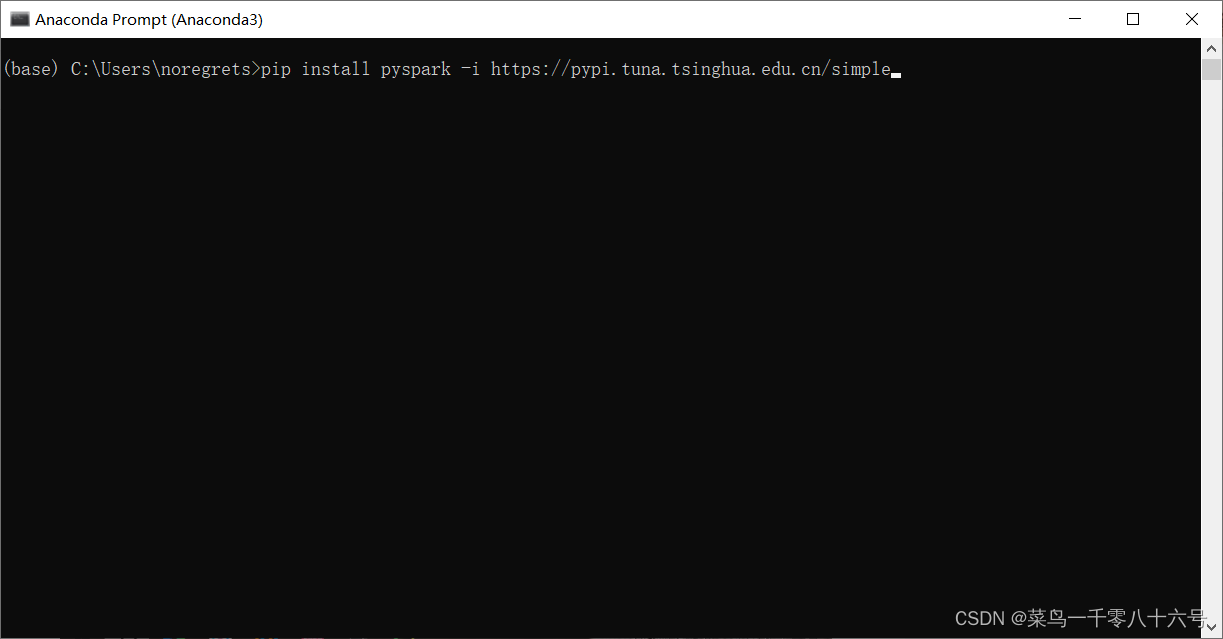
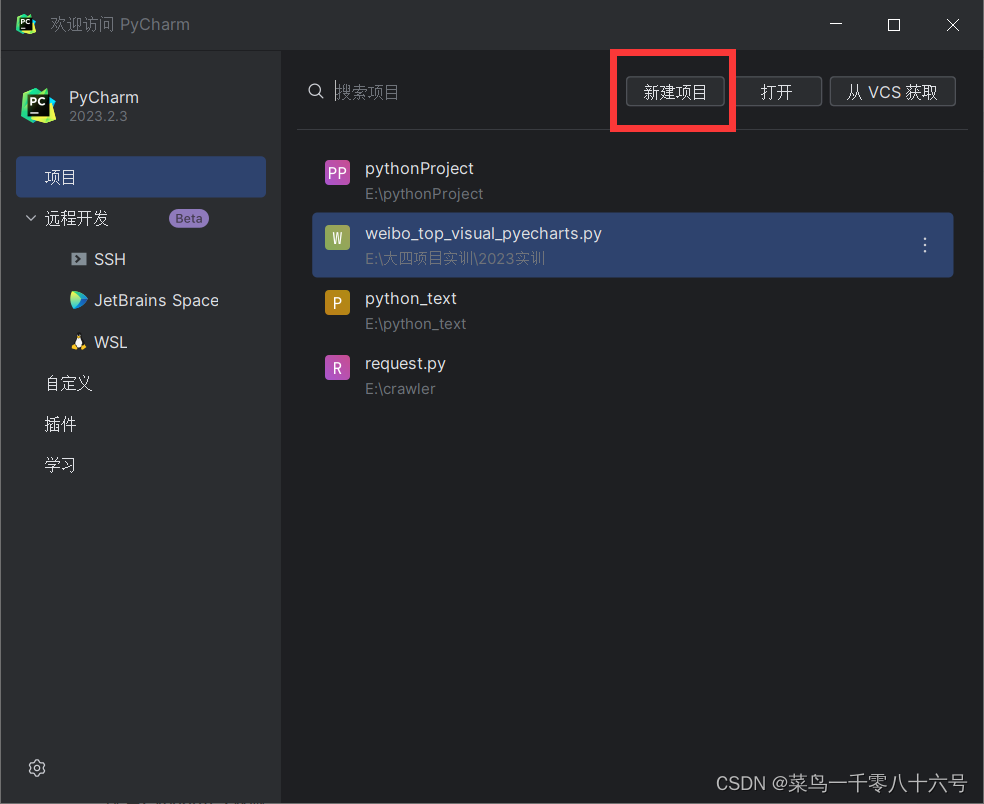
三、配置Pycharm专业版
(1)新建项目
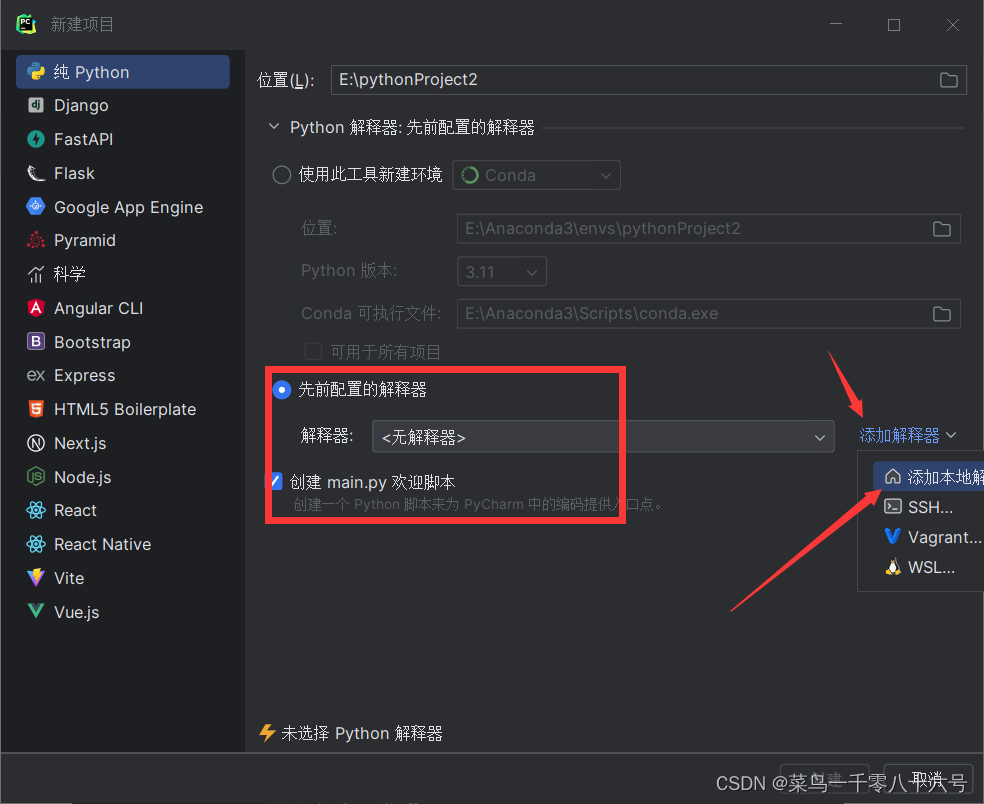
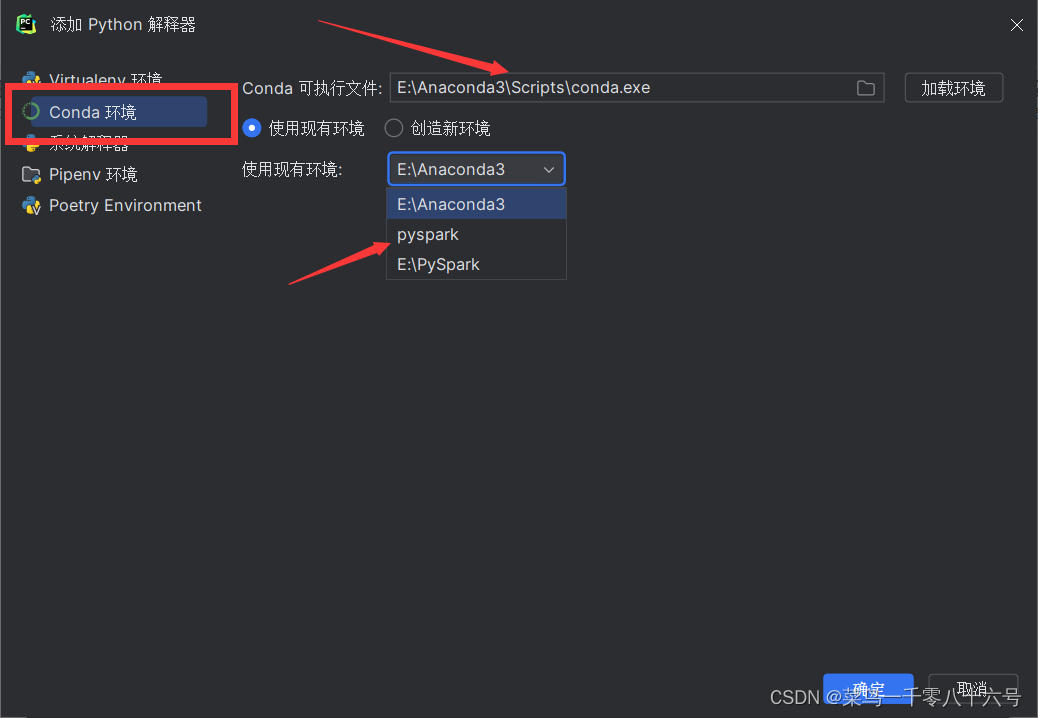
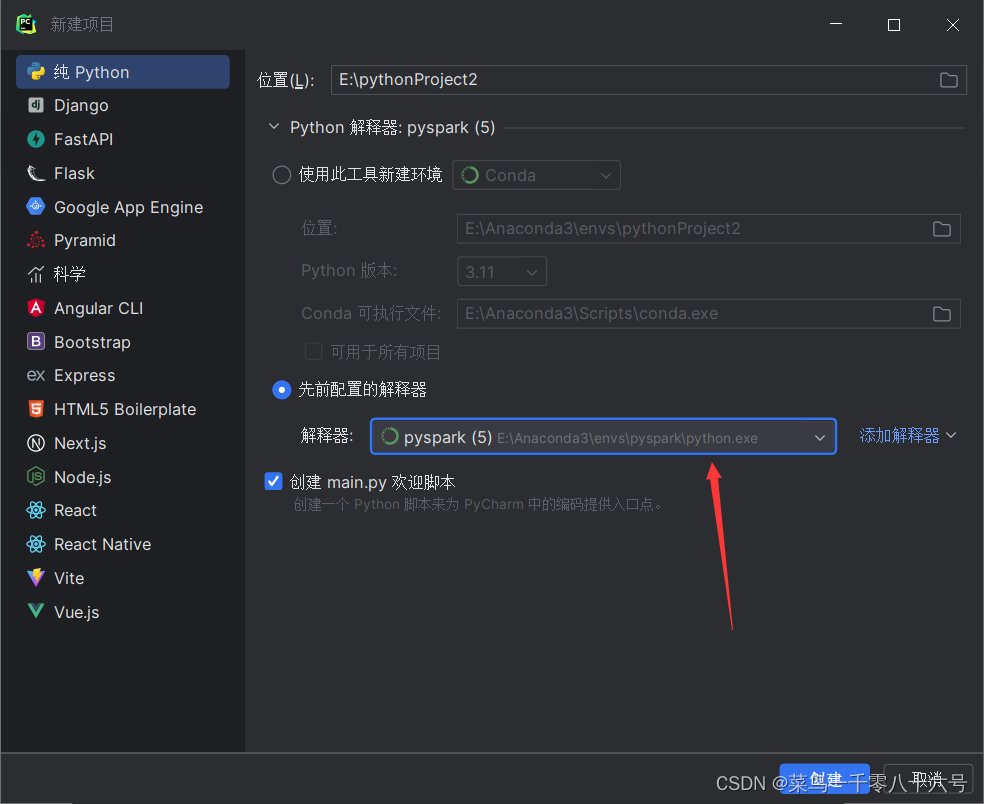
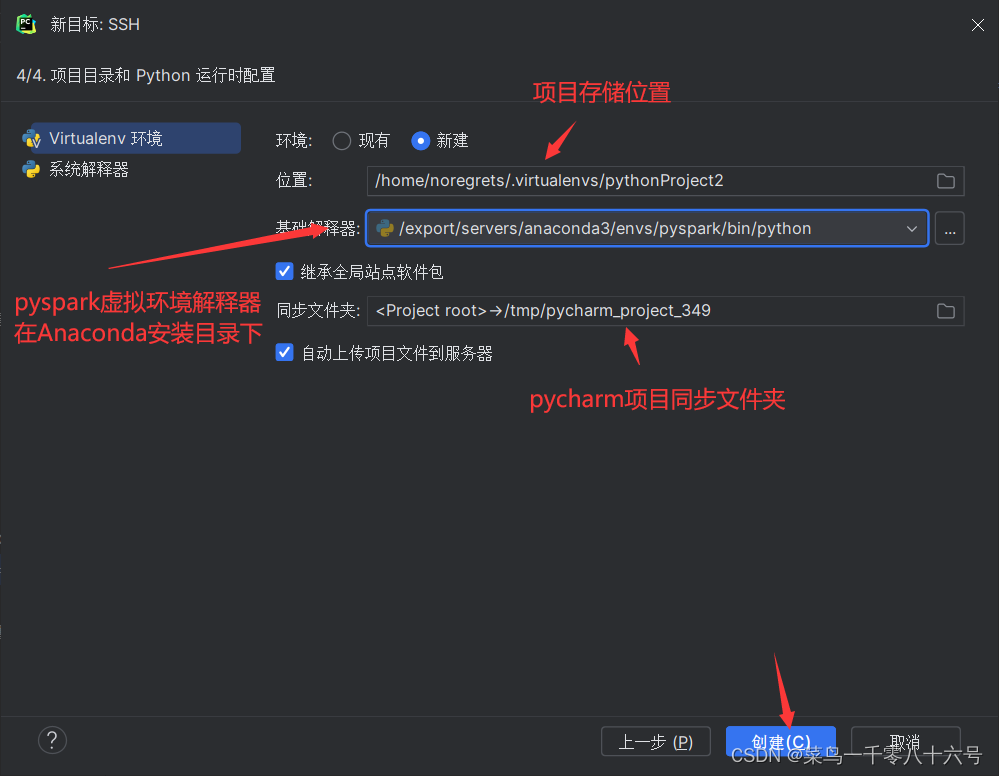
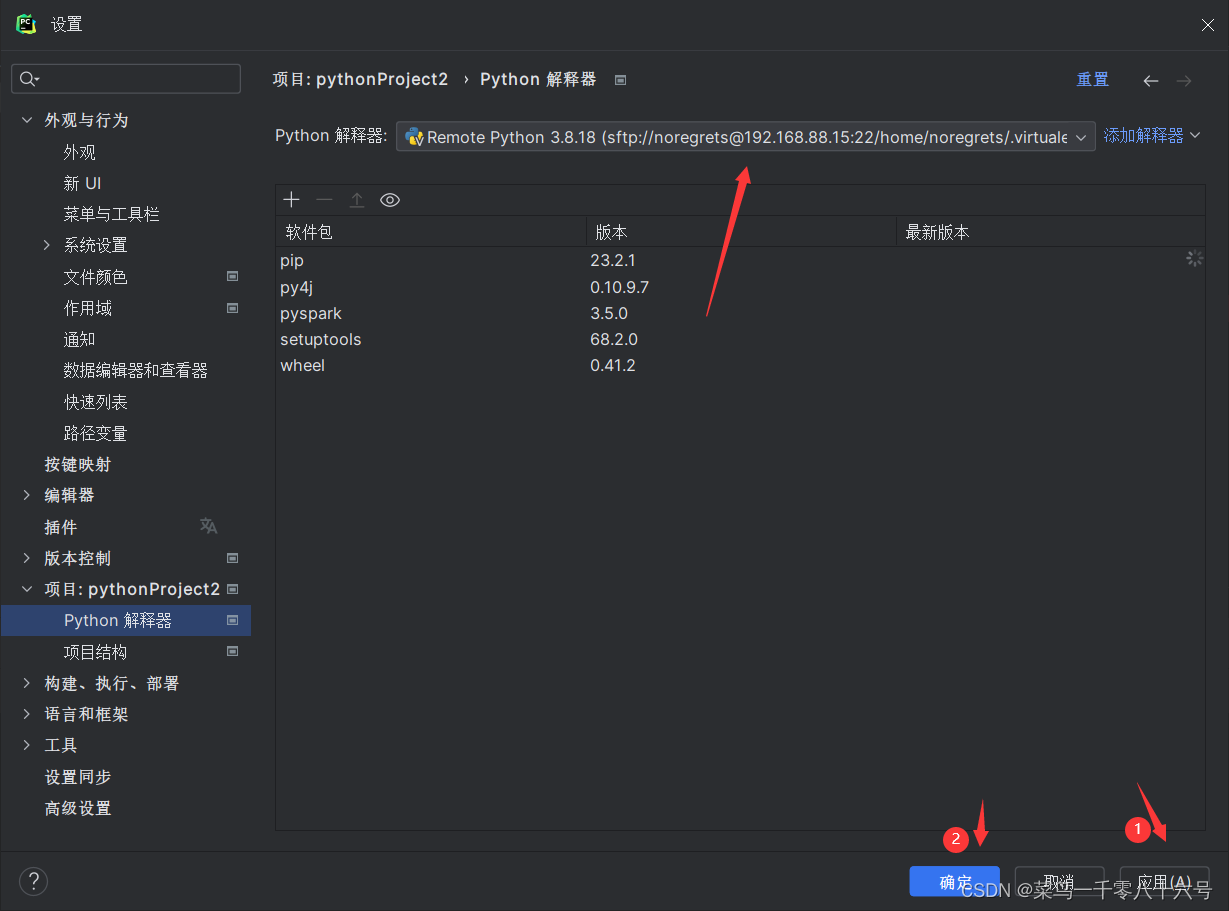
(2)配置SSH远程连接
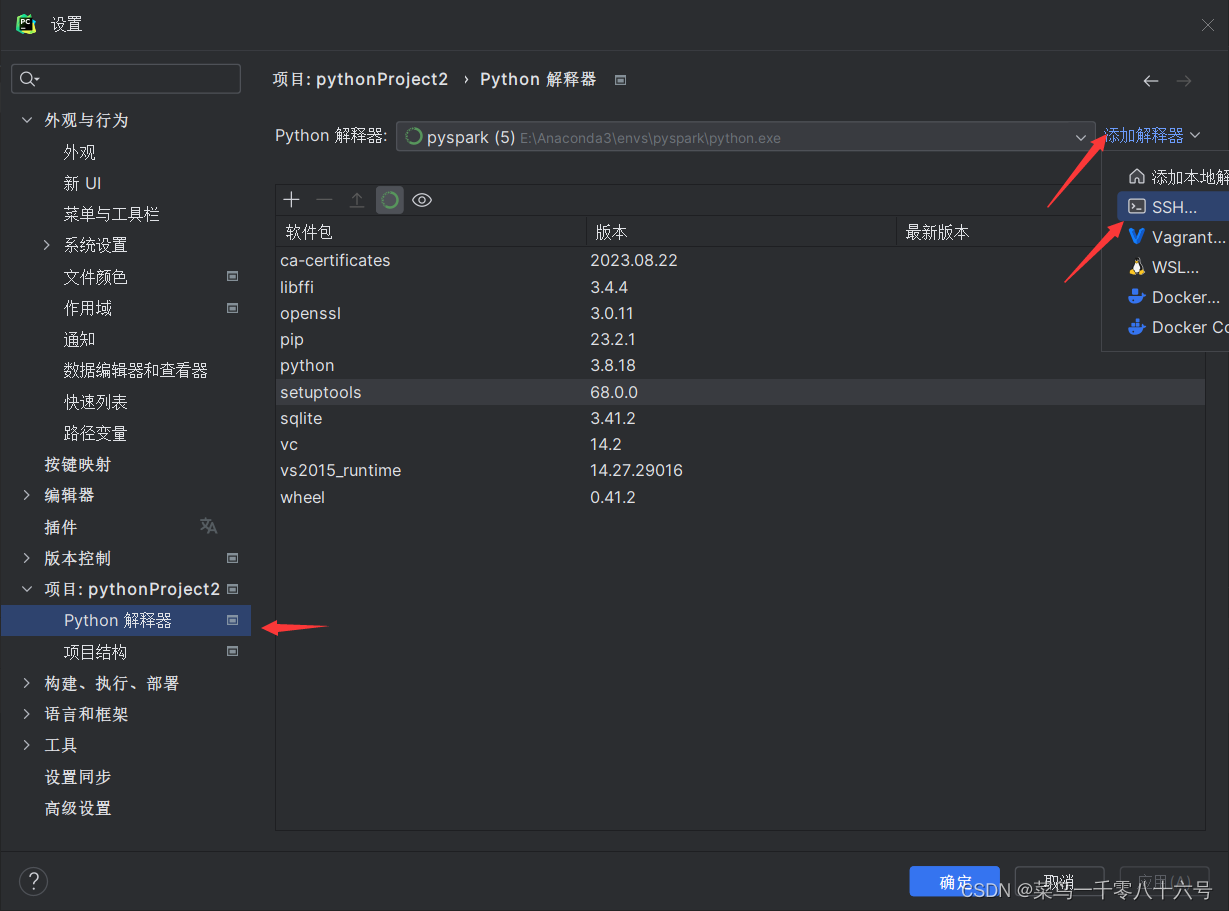
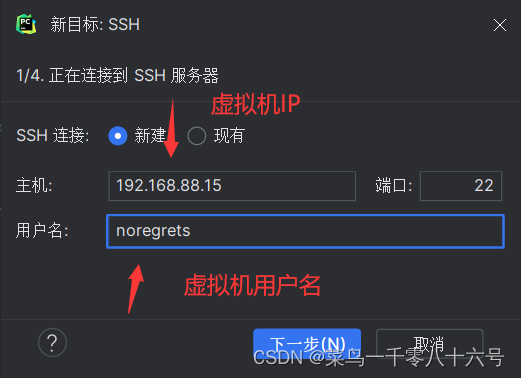
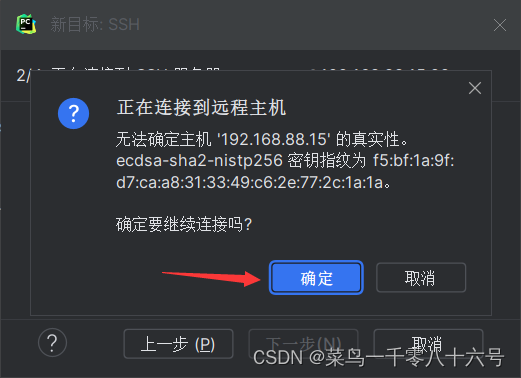
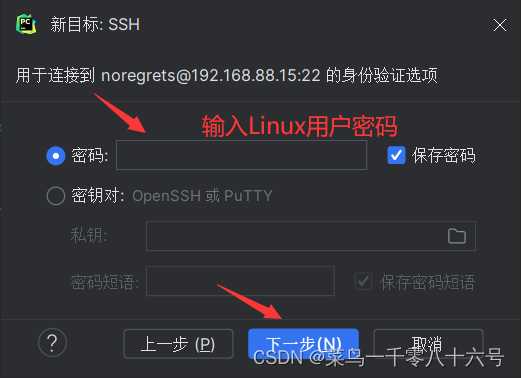
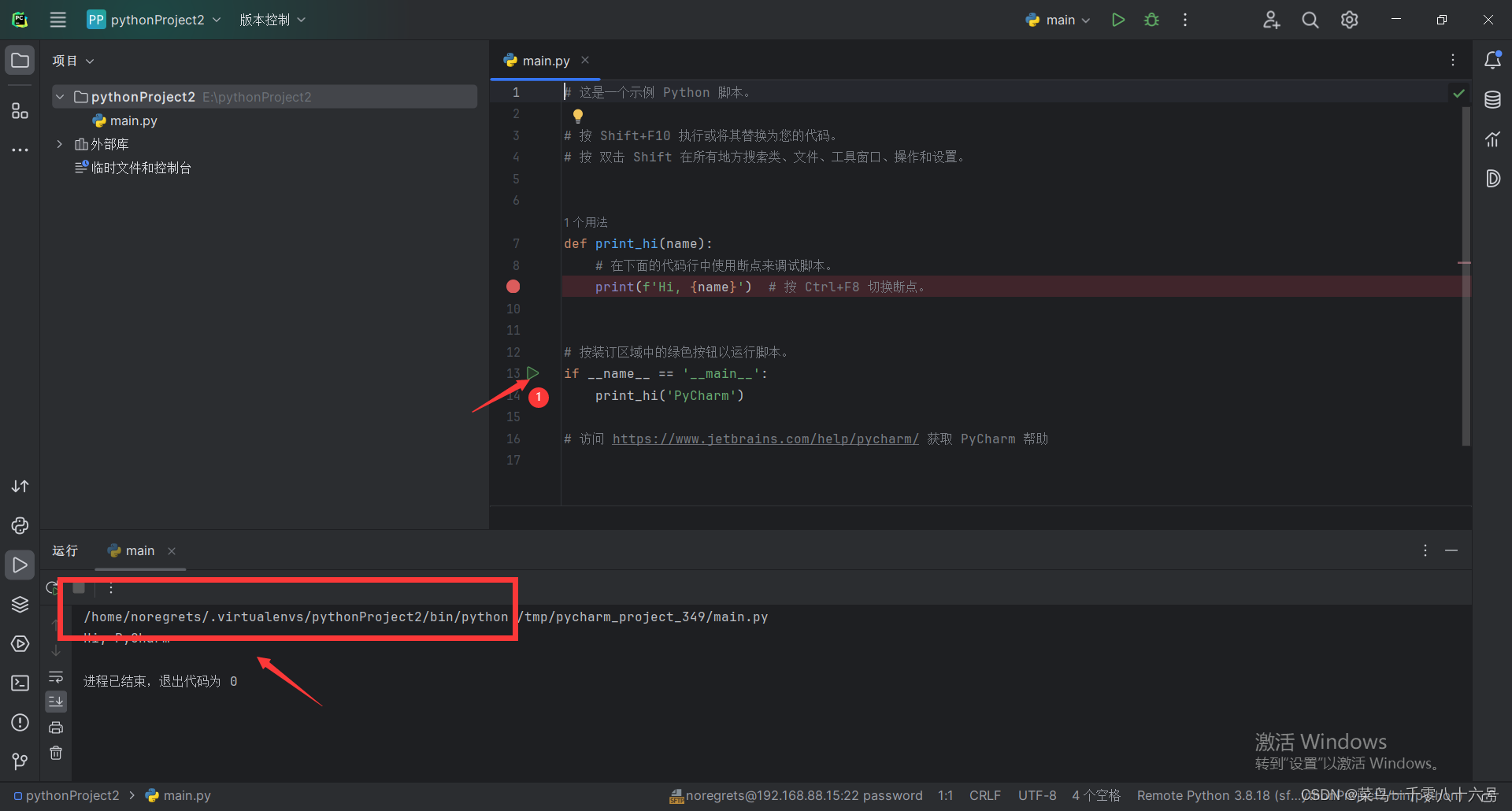
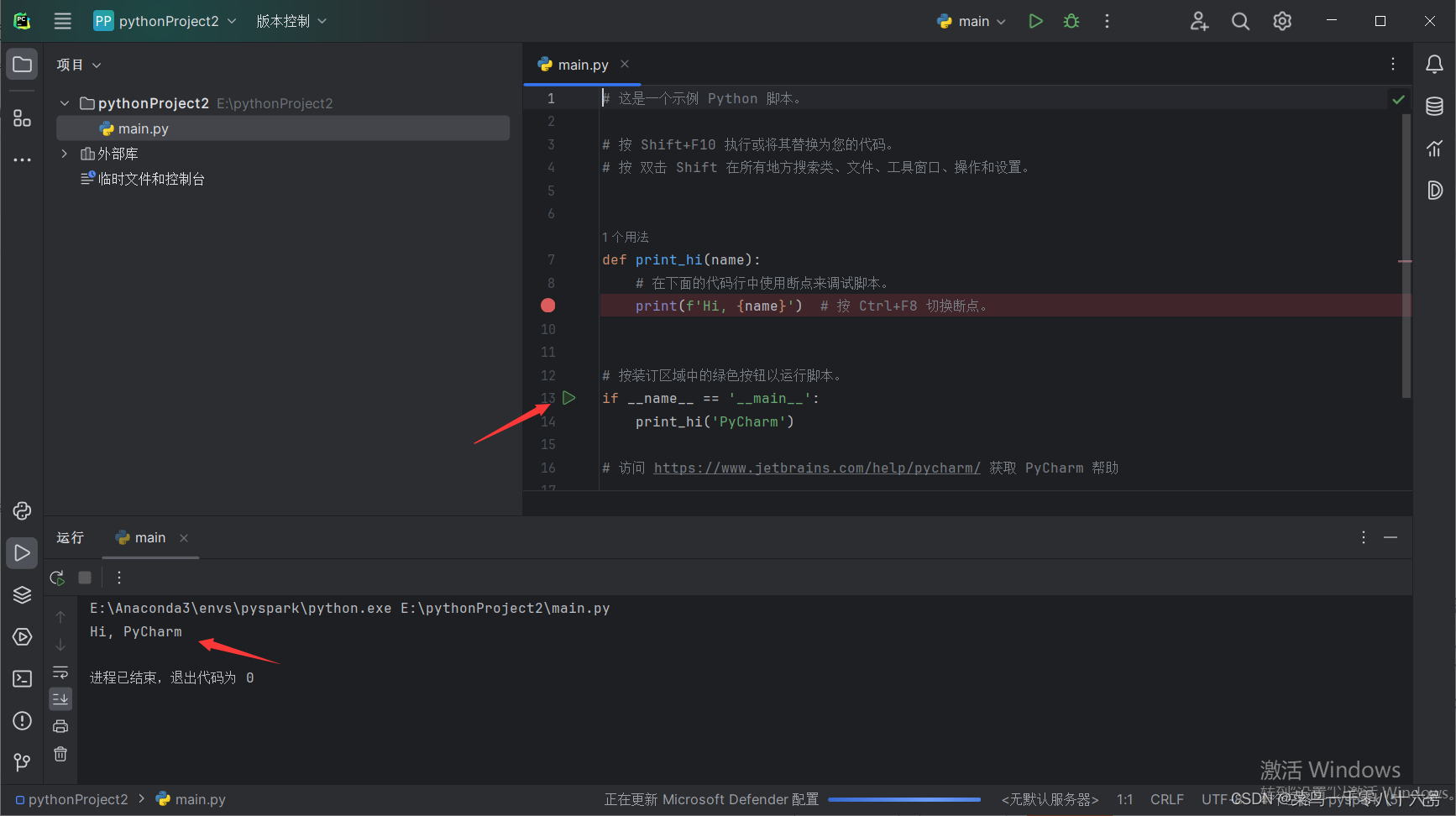
四、程序测试
# coding:utf-8
from pyspark import SparkConf,SparkContext
if __name__ == "__main__":
conf = SparkConf().setMaster("local[*]").setAppName("wordcount")
#通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
#需求:wordcount单从技术,通过读取HDFS上的words.txt文件,对内部的单词统计出现的数量
#读取文件
file_rdd = sc .textFile("hdfs://pyspark01:8020/input/words.txt")
#将单词进行分割,得到一个存储全部单纯的集合对象
words_rdd = file_rdd.flatMap(lambda line: line.split(" "))
#将单词转换为元组对象:key是单词,value是数字
words_with_one_rdd = words_rdd.map(lambda x: (x,1))
#将元组的value按照key来分组,对所有的value执行聚合操作(相加)
result_rdd = words_with_one_rdd.reduceByKey(lambda a,b: a + b )
#通过collect方法手机RDD的数据打印输出结果
print(result_rdd.collect())
五、python on spark原理
PySpark宗旨是在不破坏Spark已有的运行时架构,在Spark架构外层包装一层Python API,借助Py4j实现Python和Java的交互,进而实现通过Python编写Spark应用程序,其运行时架构如下图所示。 宗旨是在不破坏已有的运行时架构,在火花架构外层包装一层PythonAPI,借助Py4j实现Python和Java的交互,进而实现通过Python编写应用程序,其运行时架构如下图所示。
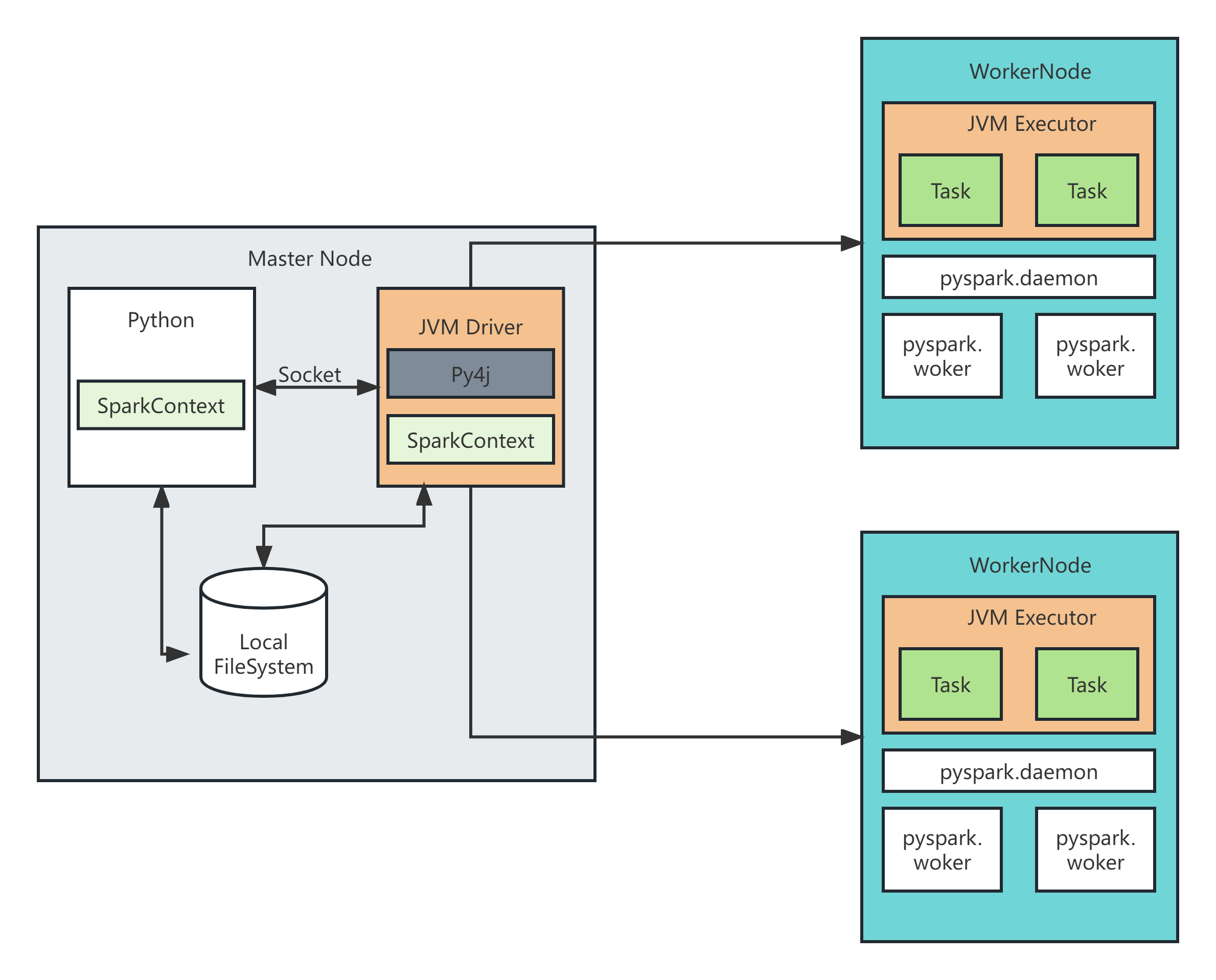
python on spark流程:Python -> JVM代码 -> RPC ->调度JVM Executor ->PySpark中转 ->
Python Executor进程
详细流程:
①在Driver端,python的Driver代码通过Py4j模块翻译成JVM代码,变成JVM Driver运行。
②在Executor端,python启动pyspark守护进程,做一个中转站。
③Driver的操作命令发送给JVM Executor,JVM Executor通过pyspark守护进程将指令发送给pyspark守护进程。
④PySpark守护进程将指令调度到运行的Python进程上。
ps:Executor端本质是Python进程在工作,指令是又JVM Executor发送(RPC)而来
本文转载自: https://blog.csdn.net/2202_75347029/article/details/133868914
版权归原作者 吗喽也是命 所有, 如有侵权,请联系我们删除。
版权归原作者 吗喽也是命 所有, 如有侵权,请联系我们删除。