
1:个人使用背景:filebeat采集日志写入es的时候,日志内容在message字段中,因为其中添加了tid字段,要提取出projectname,date,tid等这些字段,采用管道对数据进行预处理,格式化数据,重新构建了索引,最后查询,排序,条件查询什么的都直接操作字段就可以了。
ps:原理什么的就不说了,目标就是能直接操作下来,实际点。
第一步:首先要创建管道pipeline.json文件
1)touch一个pipeline.json文件,具体路径最好是跟日志文件一起(自己决定吧)
2)vim编辑pipeline.json文件格式如下
{
"description" : "test-pipeline",
"processors" : [
{
"grok" :{
"field" : "message",
"patterns" :["%{USERNAME:projectName} %{LOGLEVEL:level} %{TIMESTAMP_ISO8601:date} %{USERNAME:TID}:%{USERNAME:tranceid}%{GREEDYDATA:info}"
]
}
}
]
}
①test-pipeline是管道名称②field是你需要处理的字段③patterns是你写的grok语句(跟logstash是一样的)具体语法请参考grok语法定义
例子
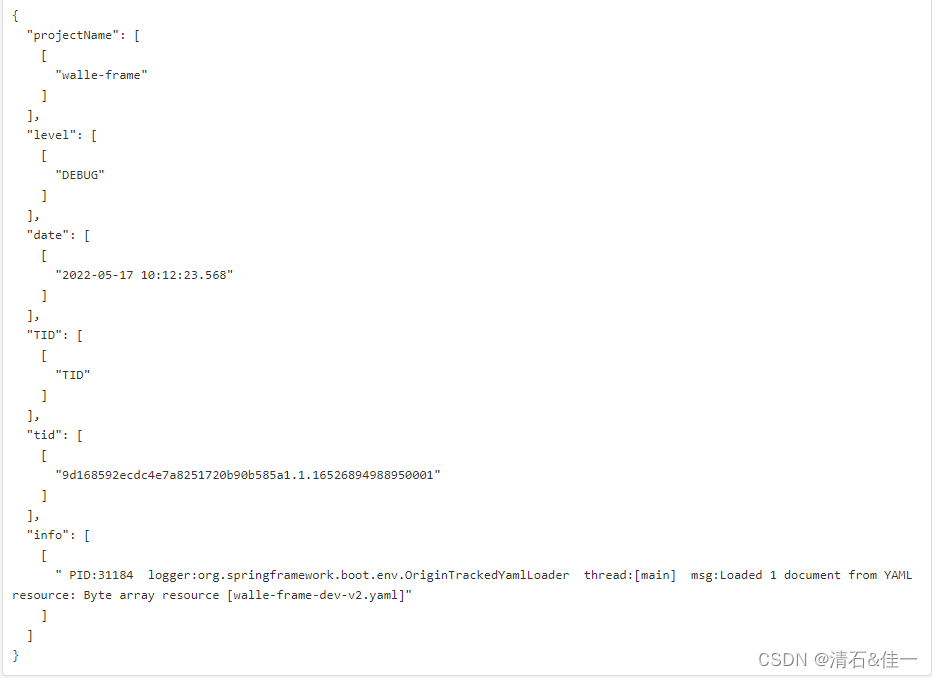
我的日志信息
walle-frame DEBUG 2022-05-17 10:12:23.568
TID:9d168592ecdc4e7a8251720b90b585a1.1.16526894988950001 PID:31184 logger:org.springframework.boot.env.OriginTrackedYamlLoader
thread:[main] msg:Loaded 1 document from YAML resource: Byte array resource [walle-frame-dev-v2.yaml]
我的gorck
%{USERNAME:projectName} %{LOGLEVEL:level} %{TIMESTAMP_ISO8601:date} %{USERNAME:TID}:%{USERNAME:tid}%{GREEDYDATA:info}
测试工具地址:grok调试地址
ps:注意空格,注意符号,从前往后一个个提取,我建议就是把比较好提取的日志信息放到前面来,这样前面匹配完了,直接用GREEDYDATA取最后所有的信息放到一个字段中,调试比较难受,参考语法,注意空格和符号,慢慢整吧少年。
效果图:
第二步:将管道导入es中,指定管道名称
1)pipeline.json文件好了,然后在json文件目录下执行下面的语句创建es管道(IP地址自己更换一下)
curl -H 'Content-Type: application/json' -XPUT 'http://localhost:9200/_ingest/pipeline/test-pipeline' [email protected]
2)这样es管道搞好了,然后在filebeat写入的时候指定管道名称就可以了
output.elasticsearch:
hosts: ["localhost:9200"]
pipeline: "test-pipeline"
ps:如果不创建管道,先在filebeat的yml文件中指定管道的话,filebeat就起不来了
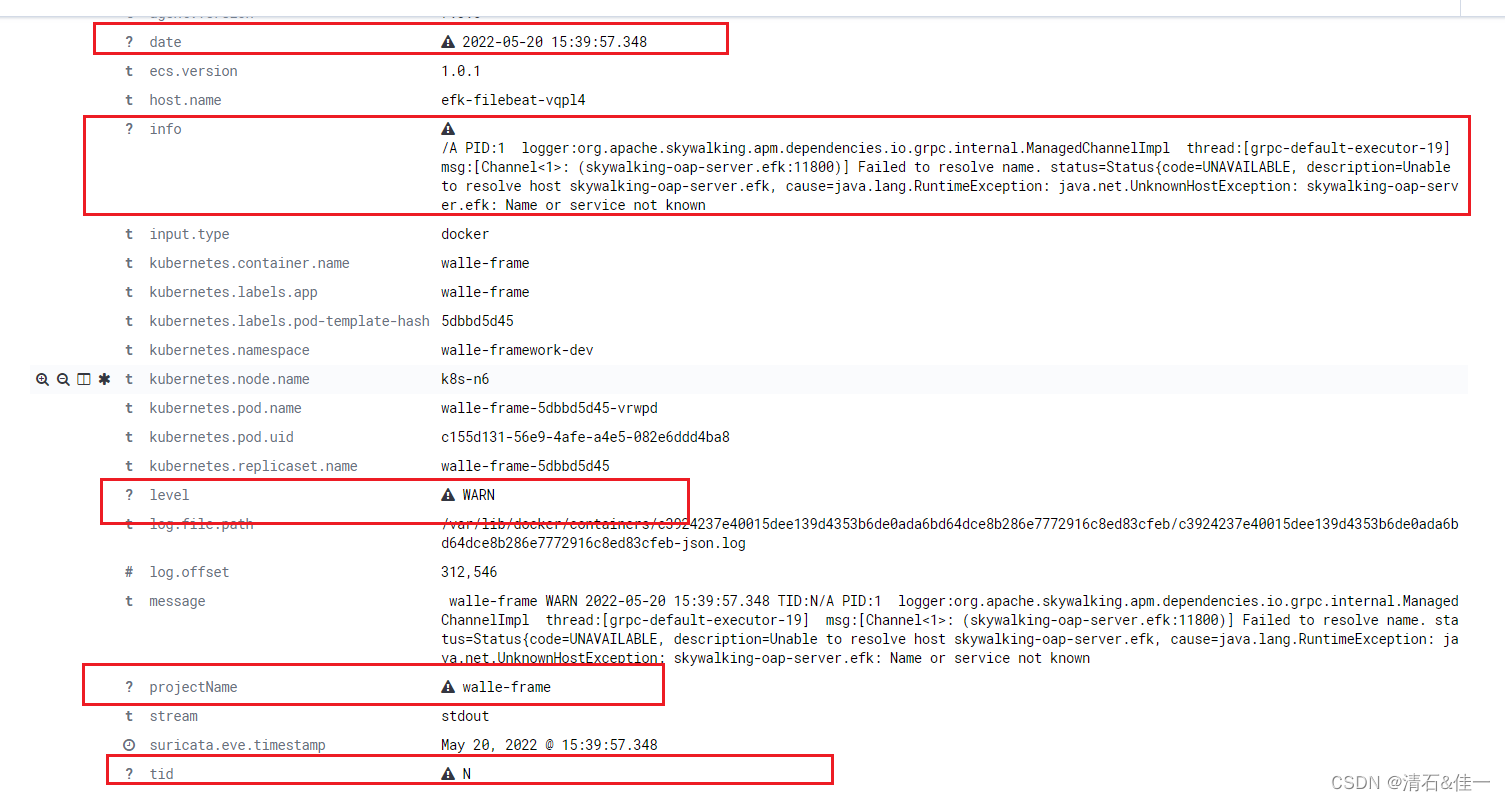
这样就可以了,完事了,自己重启一下filebeat,kibana查看一下es数据,验证一下
这个是我的效果,接口取数据,也都ok
好了,到这吧。
本文转载自: https://blog.csdn.net/zbh1957282580/article/details/124959648
版权归原作者 清石&佳一 所有, 如有侵权,请联系我们删除。
版权归原作者 清石&佳一 所有, 如有侵权,请联系我们删除。