
1. 大致原理
首页安装第三方库selenium库,
其次要下载好浏览器驱动文件,比如谷歌的 chromedriver.exe,配置上环境变量。
使用selenium的webdriver类去创建一个浏览器驱动对象赋值叫driver,一个浏览器驱动对象就可以
- 实现 对浏览器得操作
- 页面 元素的定位
- 和 元素的操作
(原理:代码--->发送http请求-----> 到了真正的浏览器驱动中的http server----->浏览器才执行步骤)
from selenium import webdriver
driver = webdriver.Chrome()
2. 浏览器
浏览器的操作
- 比如 get 访问网页、close关闭当前页、quit离开整个浏览器
- set_window_size设置窗口大小(最大化maximize_window(),最小化minimize_window)、
- 页面前进后退刷新等,**# .forward() .back() .refresh()**
- 浏览器标签页(窗口)的切换用到 swith_to.window(handle) - 再结合**.window_handles**获取 句柄列表 [ ]- 常见用法 1, 使用索引-1, 打开最新的标签页。 handles_list = driver.window_handles driver.switch_to.window(handles_list[-1]) # 切换到最后一个 handles- 常见用法 2, 遍历switch_to 到每个一个handle上, 使用title来判断是否break, 这样就到了想去的页面 代码用法
- 浏览器的滚动条也是能控制上下滚动:** driver.excute_script() **可以用户js语句实现任意页面上的操作, - 滚动条--"window.scrollTo(0,10000)" # 0表示向右移动 0- 比如一个日期控件的元素是有readonly属性,不能输入值,就可以写个js语句把它去掉。js="document.getElementById(id值').removeAttribute('readonly')" - 滚动到指定元素可见(方式2)- document.getElementById('password').type="text" # 修改元素属性
- **save_screenshot('./window.png') **保存【整屏截图】 (尺寸打开是多大就截多大) **element.screenshot('./ele.png') ** 元素截图 - 或 保存【整屏截图】 .get_screenshot_as_file("./all.png") (源码中,save_screentshot 就用的它)
(截全屏,和元素截图的另一种方式)
# 屏幕截图另一个格式
get_screenshot_as_png 这个是不带文件参数的,就需要用with open 来创建
with open('window1.png','wb') as f:
f.write(driver.get_screenshot_as_png())
# 元素截图另一种格式
另外元素截图还可以用这种,也是也是需要用with open打开
with open('code.png','wb') as f:
f.write(ele_code.screenshot_as_png) # 把图片变成字节流的数据
# 补充知识(OCR识别):
ele_bytes = ele_code.screenshot_as_png
import ddddocr # pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple/
ocr=ddddocr.DdddOcr(show_ad=False) # 参数表示去掉广告
text = ocr.classification(ele_bytes) # 提取文本信息
或者
with open('xxx.png' ,'rb') as f: # r表示读, b表示二进制 也是字节流的数据
data = f.read()
截图可以使用的地方:可以用来截取验证码,然后ocr识别图片上的文本
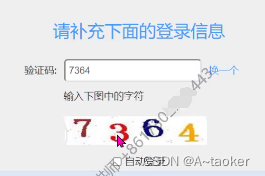
浏览器的获取
- driver.get_cookies() (需要手动登录一次),遍历得到的cookie列表,然后dirver.add_cookie(i), 就可以实现绕过登录
- driver.current_url 获取当前url
- driver.title 获取标题
- driver.get_window_size() 获取浏览器尺寸 --得到的是字典格式{'width': 945, 'height': 1020}
- driver.current_window_handle driver.window_handles 结合swith_to_window 来使用
3. 元素定位与操作
元素定位
- 我一般选择使用css定位,像 id,name,classname,tag_name这些底层都是通过css来定位的
- 而且css定位比较方便,可以用 - 标签选择器,和 #id值 .class值- 属性选择器,(可以属性等于某个值,属性以某个值开头,或包含某个值)- 路径选择器,(比如空格表示,后代, > 表示找儿子)- 伪类选择器 (比如:ntrh-child(n))
- 如果要根据某个元素的文本值来定位,或者要根据一个标签多个属性值组合判断,我就会用到xpath定位, - //[text(),"文本"] //[contains(text(),"文本")] (这种方式也能代替link_text)- //*[@id="id1",@class="class1"]
- 其他: find_element 是找一个元素, find_elements, 是把能找到的装到列表里面,找不到也不会报错,是返回空列表
driver.find_element(By.CSS_SELECTOR,'#multiSelect')
8种定位方式,面试前背背就行。。
页面F12, 可以ctrl F进行搜索
下图也是不用专门背

Xpath定位(这两种要用的):
//*[text(),"文本"] //*[contains(text(),"文本")]
//input[@id='kw' and @class]
元素操作
按钮、输入框 (单选框) 代码举例
- 常用的点击click、输入文字send_keys(补充:追加写入)、清空文字**clear、submit,get_attribute() **获取属性,.tag_name .text 坐标尺寸 .location .size, .rect更准的坐标尺寸 等
多选框 代码举例
需要用** is_selected() **是否选中 判断多选框是否选中(bool),然后click (is_displayed() 是否可见 有hidden属性的 is_enabled() 是否可用 有disabled属性的)
例: se = ele.is_selected() if se: print("已经被选中")
特殊一点的1: select元素 下拉框的选择 代码举例
方式1(只适用于select标签):
先实例化一个选择对象, select = Select (ele) # 参数为元素对象- select_by_index- select_by_value- select_by_visible_text- deselect_all() 反选
方式2(div的下拉选择,或者select都行)- 直接用send_keys("某个值") --- 定位到選項标签- 或者直接click --- 定位到其中的一项
特殊一点的2: alert警告框的处理
警告框出来后,首先要driver.switch_to点alert
- 点accept() , 确认
- 点dismiss(), 取消
- 点send_keys(), 输入
- 或者 点text 不要()
键盘操作元素
记住是通过send_keys,完成的就行了,然后传入键盘的值, 用的少,也没难度,用时查
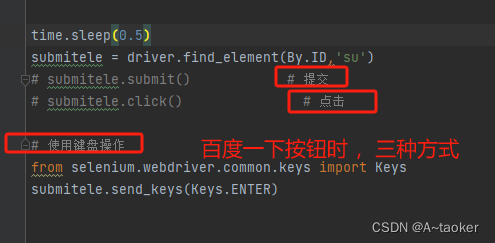
如:对【提交按钮】元素进行,回车键
对【输入框】元素进行,ctrl A, ctrl C V 等, (Keys.键数字) 表示多次操作 如回退 Keys.BACKSPACE2 等
如下图,是百度提交
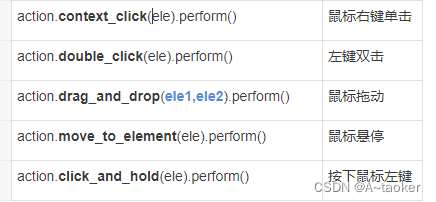
鼠标操作 代码笔记
从selenium引入ActionChains类,然后action = ActionChains(driver)实例化一个action对象
from selenium.webdriver import ActionChains
练习地址:https://sahitest.com/demo/
ActionChains(driver).动作1.动作2.perform() 它是一个链式调用
拖动滑块也能实现 drag_and_drop_by_offset(ele,向右的x,向下的y))
ui自动化需掌握的知识点还有:
嵌套网页
遇到有 iframe的元素嵌套网页,需要先先使用到 switch_to点frame(iframe元素de定位) ,切换到对应frame,才能进行元素操作,
另外它还有返回上层页面,和默认地方的操作(百度下)
- driver.switch_to.frame(ele), # 参数除了是元素定位ele,还可以是 id name, 或者通过索引号
- driver.switch_to.parent_frame() 返回上一层
- driver.switch_to.default_content() 调回最外层
文件上传 代码演示
http://42.192.62.186:8088/index.html#/home 账号密码: sq3 123 万能验证码:999999
普通的input框,直接用send_keys,传图片路径
非input框,用python第三方库,pypiwin32 或者 pyautogui 结合pyperclip
ui自动化其他必备知识点
隐式等待 和显示等待 代码演示
隐式等待
driver.implicitly_wait(30) 可以设置一个最大等待时间,等页面加载完,才会去执行后面的找元素。 不然加载没出来,就找元素,会报错。
比如在渲染页面时,如果不等待直接去找,会找不到。
显示等待
找一种元素时,可以不停的找,直到它可见,就找到。
它的逻辑有点像下面这种(轮询去找,最后超过时间就不等了)
导入一个等待条件 (直接出现,或者直接可见),和一个webDriverWait类。
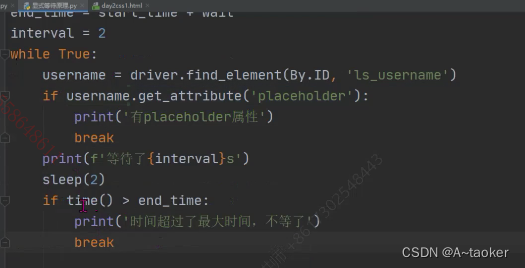
小补充:
- 元素ele点location_once_scrolled_into_view等 滚动到可见----1. 如例子:https://www.runoob.com/ 页面下放的元素
- ele.value_of_css_property('color') 获取CSS属性值
- 元素上找元素 (第4课,2节)
- 冻屏操作(针对那种不好定位元素)---自己百度, 如:百度输入框,输入了 学习两个字,弹窗上面的元素不好捕获

- setTimeout(()=>{debugger;},5000) 表示5秒后debugger. 就可以先在consloe里输入,回车,然后去页面上操作,让页面挺住就可以操作
滚动到可见代码 和 获取css属性值的例子
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.runoob.com/')
sleep(2)
#打开了人看不到,但是网页这个树加载好了,这个元素可能就可以操作
# driver.find_element_by_xpath("//h4[contains(text(),'【网站主机教程】')]").click()
ele_host = driver.find_element(By.XPATH,"//h4[contains(text(),'【网站主机教程】')]")
ele_host.location_once_scrolled_into_view # 报黄,但是不影响, 滚动条会自动下去
print(ele_host.value_of_css_property('color')) #rgba(100, 133, 76, 1)
元素上找元素
http://42.192.62.186:8088/index.html#/demo/13
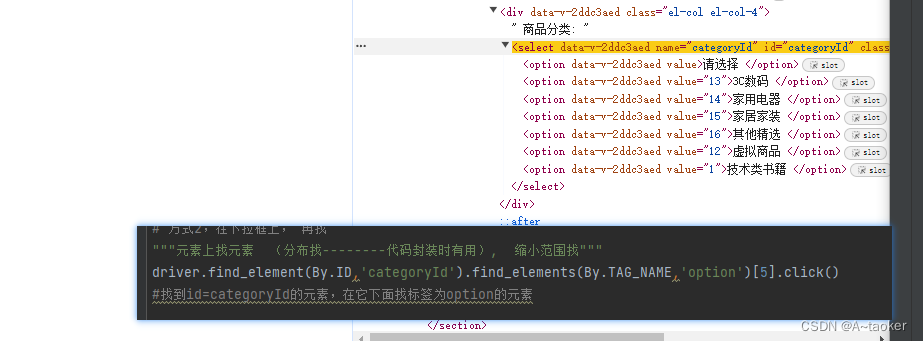
'''
知识点:webelement的find_element_xxxx方法
'''
from selenium import webdriver
import time
driver = webdriver.Chrome()
from selenium.webdriver.common.by import By
driver.implicitly_wait(5)
driver.get("http://42.192.62.186:8088/index.html#/")
driver.maximize_window()
# 账号密码
driver.find_element(By.CSS_SELECTOR, '#username').send_keys('sq3')
driver.find_element(By.CSS_SELECTOR, '#password').send_keys('123')
driver.find_element(By.CSS_SELECTOR, '#code').send_keys('999999')
driver.find_element(By.CSS_SELECTOR, "#submitButton").click()
time.sleep(1)
driver.refresh()
time.sleep(1)
driver.find_element(By.XPATH, "//span[contains(text(),'按钮')]").click()
driver.find_element(By.XPATH, "//li[contains(text(),'下拉框')]").click()
# 方式1 ,点击选项
driver.find_element(By.XPATH, "//*[contains(text(),'3C数码')]").click()
time.sleep(3)
# 方式1 ,CSS定位
driver.find_element(By.CSS_SELECTOR, "#categoryId > option:nth-child(3)").click()
time.sleep(3)
# 方式2,在下拉框上, 再找
"""元素上找元素 (分布找--------代码封装时有用), 缩小范围找"""
driver.find_element(By.ID, 'categoryId').find_elements(By.TAG_NAME, 'option')[5].click()
#找到id=categoryId的元素,在它下面找标签为option的元素
版权归原作者 A~taoker 所有, 如有侵权,请联系我们删除。