
一). Hive的安装与配置
1. 前置说明
实验平台直达链接
任务描述
在已安装Hadoop的基础上安装配置好Hive并运行。
相关知识
完成本次任务,需要掌握:
1.Hive的基本安装;
2.Mysql的安装与设置;
3.Hive的配置。
注意:本次实训Hive的安装与配置建立在Hadoop已安装配置好的情况下。
2. 基本配置
2.1 解压缩
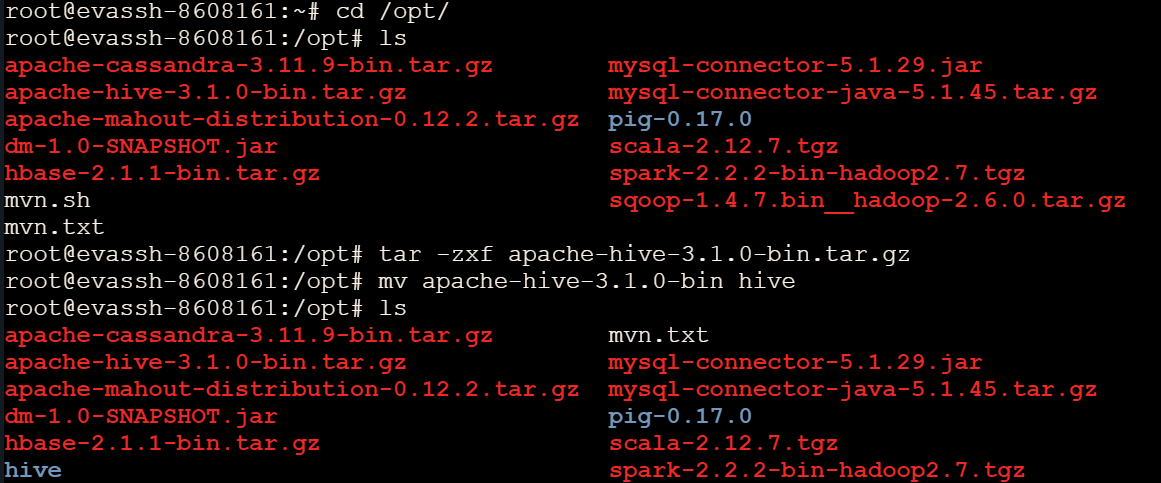
cd /opt
tar -zxf apache-hive-3.1.0-bin.tar.gz
mv apache-hive-3.1.0-bin hive
2.2 配环变
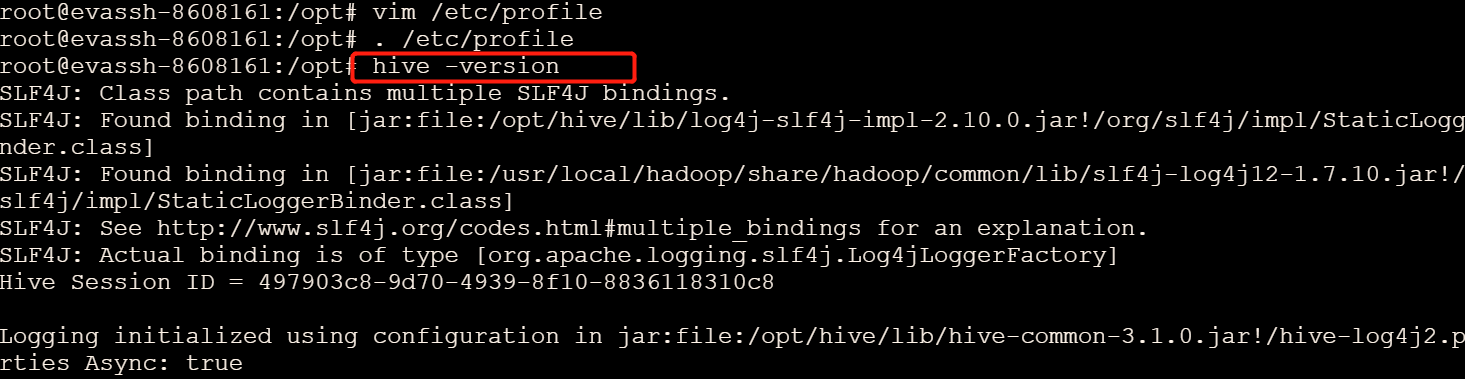
vim /etc/profile
export HIVE_HOME=/opt/hive
export PATH=$HIVE_HOME/bin:$PATH
解决包的冲突问题
rm /opt/hive/lib/log4j-slf4j-impl-2.10.0.jar
2.3 Mysql配置
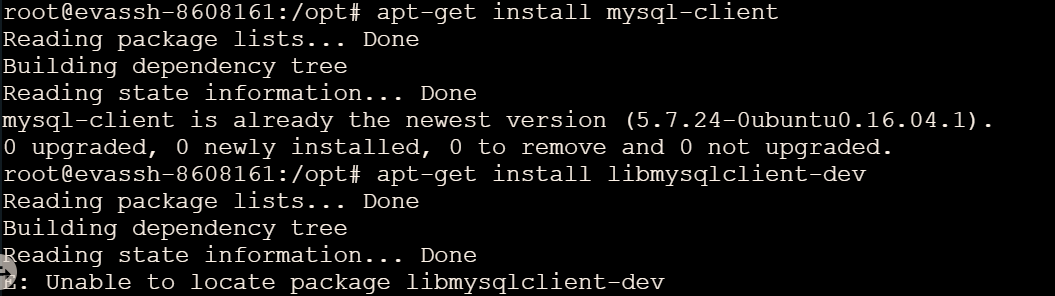
sudoapt-getinstall mysql-server #安装mysql服务apt-getinstall mysql-client #安装mysql客户端sudoapt-getinstall libmysqlclient-dev #安装相关依赖环境

2.3.1 Mysql驱动
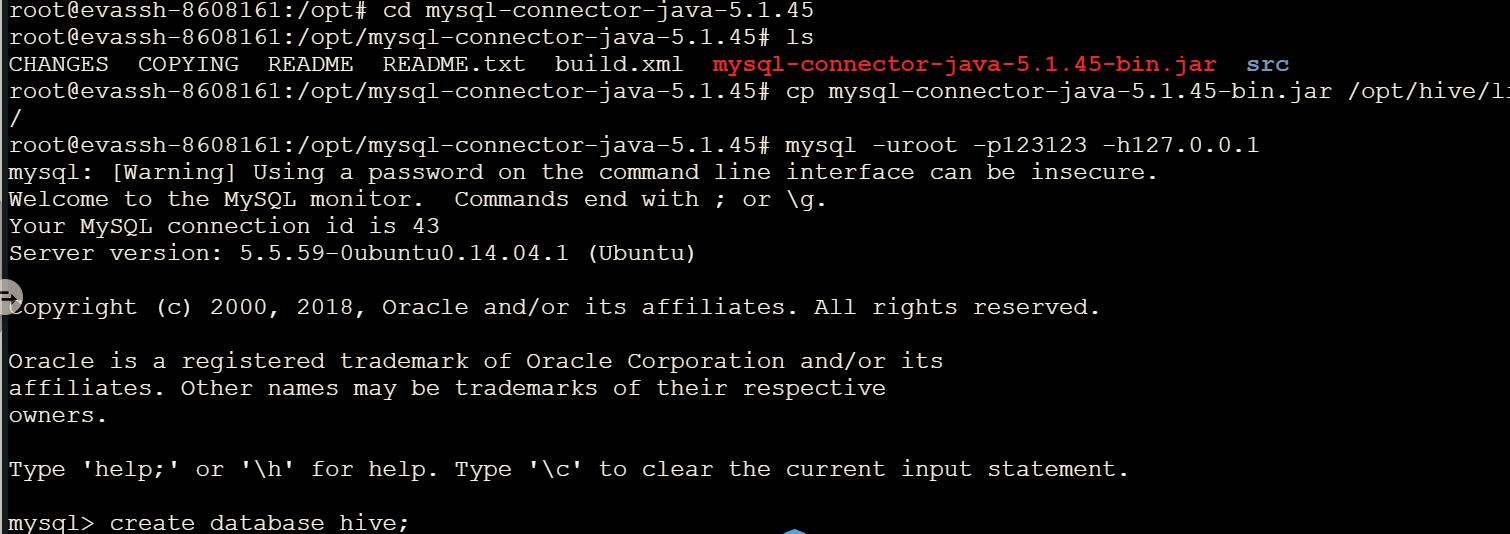
tar -zxvf mysql-connector-java-5.1.45.tar.gz
cd mysql-connector-java-5.1.45
cp mysql-connector-java-5.1.45-bin.jar /opt/hive/lib/
2.3.2 设置Mysql
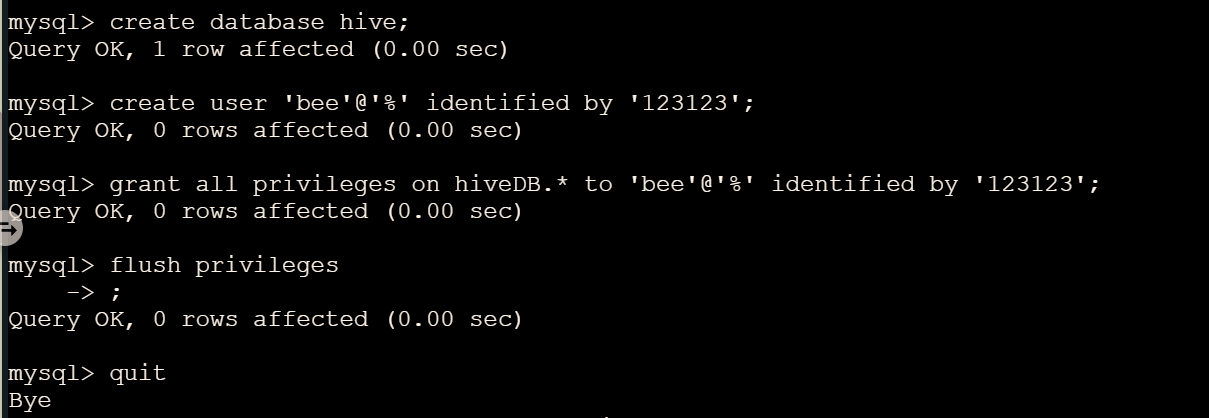
3. Hive 配置
3.1 文件配置
hive-site.xml
hive-site.xml
保存
Hive
运行时所需要的相关配置信息。
<configuration><property><name>hive.metastore.warehouse.dir</name><value>/opt/hive/warehouse</value></property><property><name>hive.exec.scratchdir</name><value>/opt/hive/tmp</value></property><property><name>hive.querylog.location</name><value>/opt/hive/logs</value></property><property><name>hive.server2.thrift.port</name><value>10000</value></property><property><name>hive.server2.thrift.bind.host</name><value>localhost</value></property><property><name>hive.server2.enable.doAs</name><value>true</value></property><property><name>hive.session.id</name><value>false</value></property><property><name>hive.session.silent</name><value>false</value></property><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://localhost:3306/hiveDB?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>bee</value><!-- 这里是之前设置的数据库 --></property><property><name>javax.jdo.option.ConnectionPassword</name><!-- 这里是数据库密码 --><value>123123</value></property></configuration>
- hive-env.sh
由于
Hive
是一个基于
Hadoop
分布式文件系统的数据仓库架构,主要运行在
Hadoop
分布式环境下,因此,需要在文件
hive-env.sh
中指定
Hadoop
相关配置文件的路径,用于
Hive
访问
HDFS
(读取
fs.defaultFS
属性值)和
MapReduce
(读取
mapreduce.jobhistory.address
属性值)等
Hadoop
相关组件。
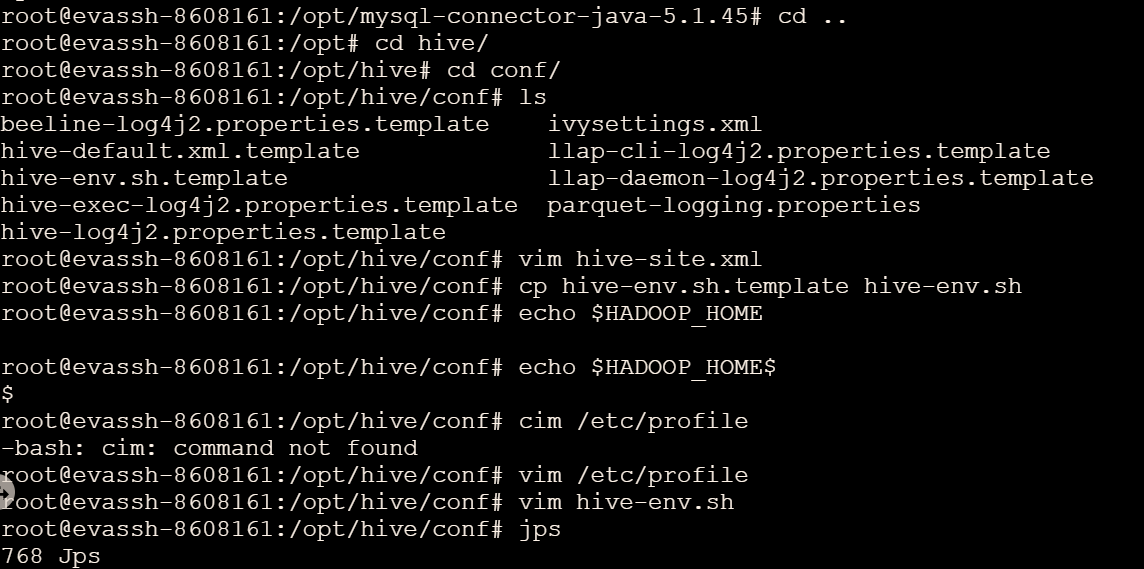
如果目录下没有该文件,我们就以hive-env.sh.template为模板复制一个
cp hive-env.sh.template hive-env.sh。
vim hive-env.sh打开文件,在文件末尾添加变量指向 Hadoop 的安装路径
HADOOP_HOME=/usr/local/hadoop #在本地环境安装,要根据自己hadoop的路径来确定
4. Hive 启动
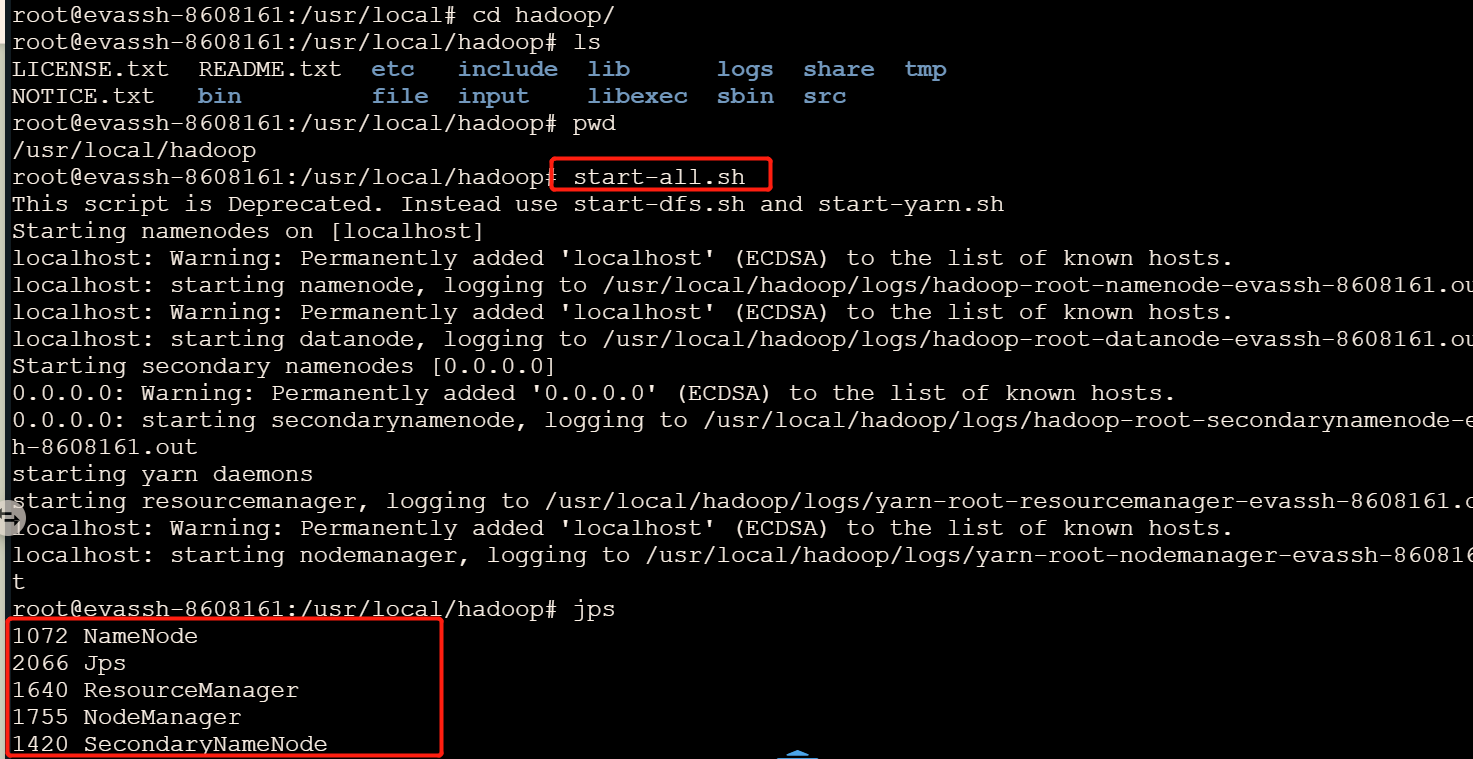
4.1 启动hadoop
4.2 元数据写入
第一次启动
Hive
前还需要执行初始化命令
schematool -dbType mysql -initSchema
二). Hive Shell基础命令
1. 前置说明
实验平台直达链接
任务描述
本关任务:按照编程要求,在
Hive
下创建表。
相关知识
Hive Shell
运行在
Hadoop
集群环境上,是
Hive
提供的命令行接口(
CLI
),在
Hive
提示符输入
HiveQL
命令,
Hive Shell
把
HQL
查询转换为一系列
MapReduce
作业对任务进行并行处理,然后返回处理结果。
为了完成本实验的任务,需要掌握:
Hive Shell
常用命令 。
Hive Shell 常用命令
注意:
Hive
命令必须以分号
;
结束。
2. 具体操作
2.1 交互式运行
在Hive的安装与配置基础上
- 启动 Hive Shell:
hive - 查询数据库:
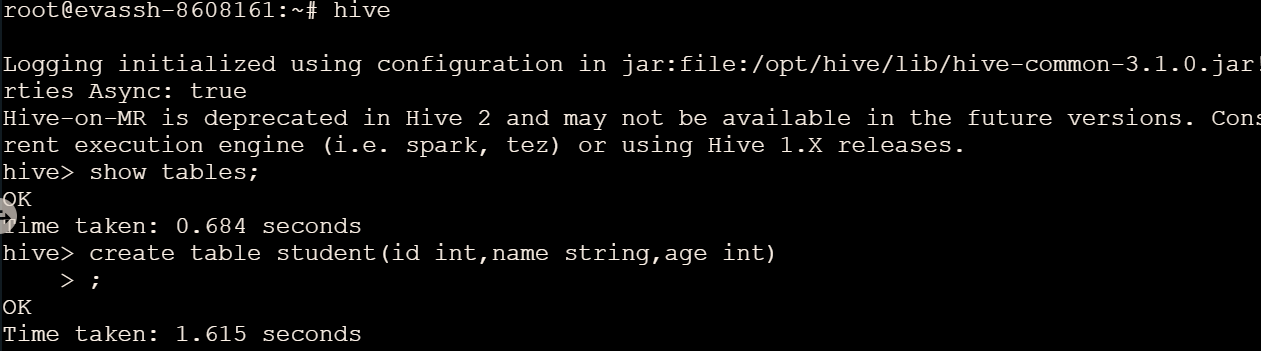
show databases; - 查询表:
show tables;
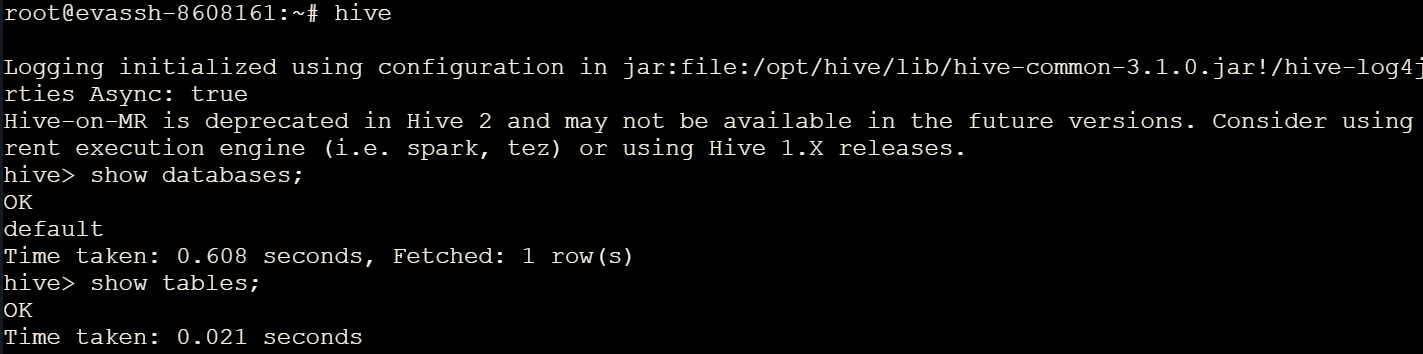
因为该数据库下没有创建表,所以输出结果为
0行。
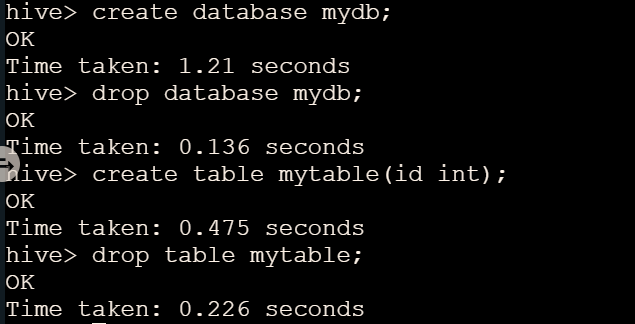
- 创建数据库
mydb:create database mydb; - 删除数据库
mydb:drop database mydb; - 创建表
mytable,有id字段,数据类型为int:create table mytable(id int); - 删除表
mytable:drop table mytable;; - 退出 Hive Shell:
exit;。
2.2 非交互式运行
可以在不启动
Hive Shell
,直接在
Linux
的命令行操作
Hive
hive -e 'show databases;';hive -S -e 'show databases;'

在
Hive
的交互式模式和非交互式模式下,执行
HiveQL
操作都会输出执行过程信息,如执行查询操作所用时间,通过指定
-S
选项可以禁止输出此类信息。
3. 测试任务
请根据左侧知识点的描述,在右侧命令行中使用 Hive 进行创表 ,具体任务如下:
在
Hive Shell
下创建一个表
student
,表结构如下:
col_namedata_typeidintnamestringageint
hive>createtable student(id int,name string,age int);
在
Hive Shell
下创建一个表
student
,表结构如下:
col_namedata_typeidintnamestringageint
hive>createtable student(id int,name string,age int);
申明:以上所有流程基于头歌实验平台提供的环境,如需实操点击直达链接跳转即可开启实验,文章仅作记录
本文转载自: https://blog.csdn.net/kangqiao0422/article/details/122575500
版权归原作者 会撸代码的懒羊羊 所有, 如有侵权,请联系我们删除。
版权归原作者 会撸代码的懒羊羊 所有, 如有侵权,请联系我们删除。