
快速安装
1、安装Paddle
conda install paddlepaddle-gpu==2.6.0 cudatoolkit=11.7 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
检验是否成功
import paddle
paddle.utils.run_check()
2、安装PaddleOCR
pip install “paddleocr>=2.0.1” --upgrade PyMuPDF==1.21.1
一、环境准备
1.1 创建虚拟环境
创建Anaconda虚拟环境,并指定python版本,PaddleOCR支持的python版本为 3.8 - 3.12。这里仅以3.11.2版本为例。
conda create -n paddle python=3.11.2
进入paddle虚拟环境
conda activate paddle
1.2 检查系统环境
python -c "import platform;print(platform.architecture()[0]);print(platform.machine())"
确认 Python 和 pip 是 64bit,并且处理器架构是 x86_64(或称作 x64、Intel 64、AMD64)架构。下面的第一行输出的是”64bit”,第二行输出的是”x86_64(或 x64、AMD64)”即可。
二、安装PaddleOCR
2.1 更改镜像源为清华镜像(可选)
2.1.1 取消现有镜像地址:
conda config --remove-key channels
2.1.2 设置清华镜像地址:
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/win-64/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/win-64/
conda config --add channels http://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
conda config --set ssl_verify yes
根据版本进行安装,如果电脑有英伟达显卡的话可以选择cuda版本的,否则可以安装CPU版本的,官网地址:飞桨PaddlePaddle-源于产业实践的开源深度学习平台
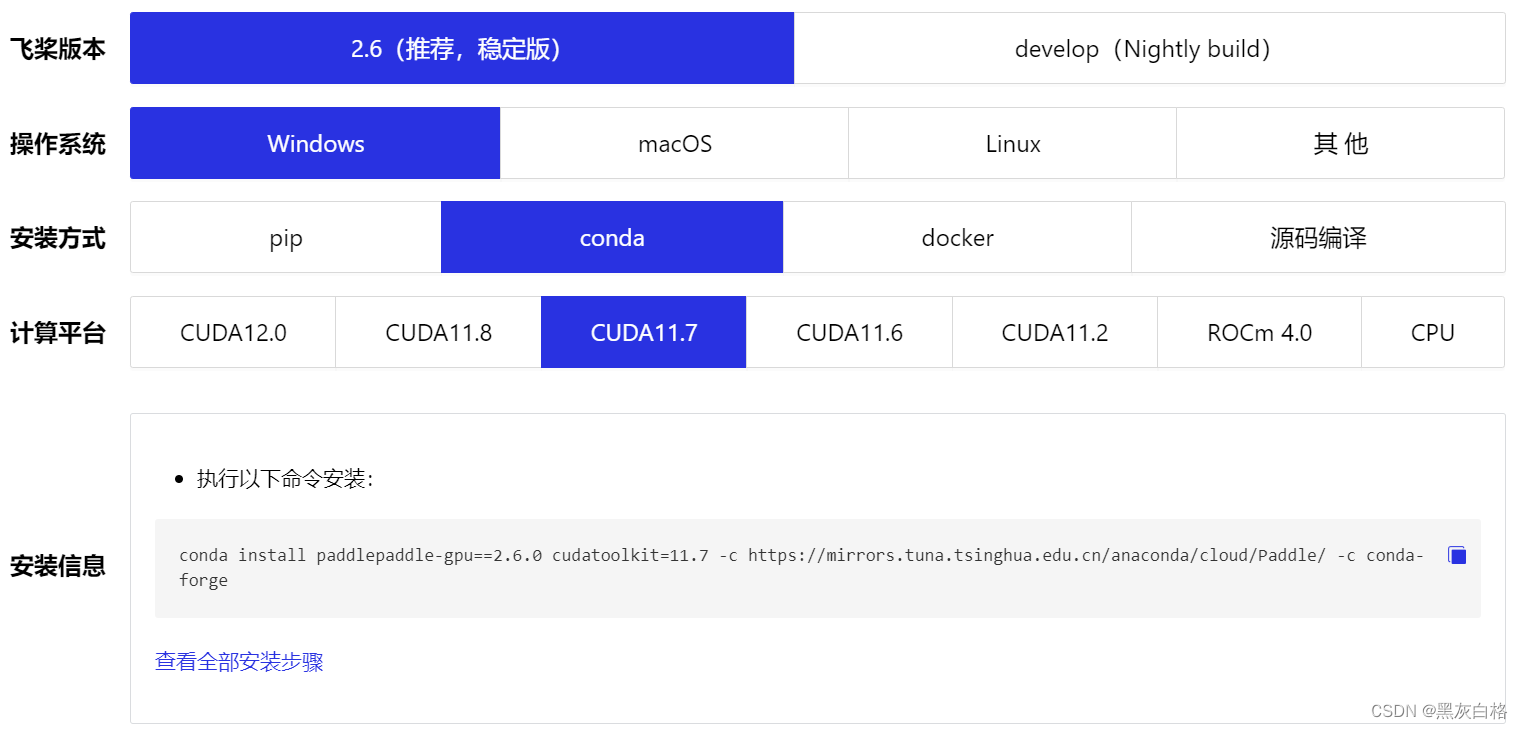
根据自己的版本进行选择安装。这里使用conda一直安装失败,采用pip命令安装。(不妨多等等)
conda install paddlepaddle-gpu==2.6.0 cudatoolkit=11.7 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
2.2 验证安装是否成功
输入python命令进入python编译器,依次输入以下命令:
2.2.1 导入paddle包
import paddle
2.2.2 运行paddle中的run_check()方法进行检查。
paddle.utils.run_check()
运行结果中显示PaddlePaddle is installed successfully! 则表示安装成功!
报错如下:
原因:CUDA、CUDNN均为安装!之前在pyTorch安装的时候看到的CUDA是显卡预装的驱动运行时。故还需要去官网安装。
简单验证电脑是否装了CUDA和CUDNN,若已安装则有
C:\Program Files\NVIDIA GPU Computing Toolkit
路径,而不是只有
C:\Program Files\NVIDIA Corporation
路径。
2.3 CUDA和CUDNN的安装(已安装的忽略)
2.3.1 CUDA安装
官网地址:CUDA Toolkit Archive | NVIDIA Developer
选择合适的版本,例如我选择的是11.7版本,因为Paddle中有该版本命令。此外,建议选择exe (network)版进行安装,比较小。
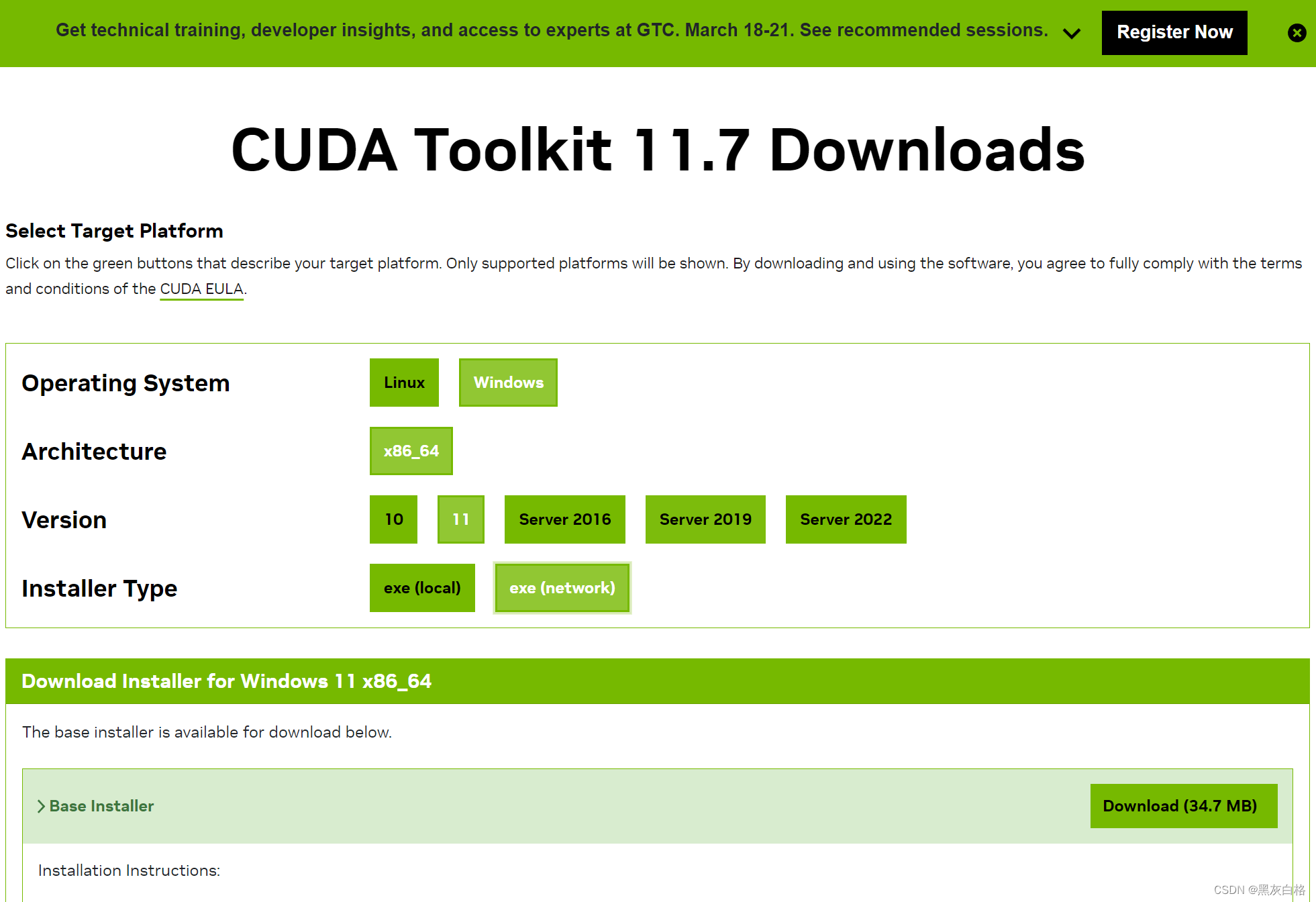
安装过程无脑下一步就会,默认路径即可。
2.3.2 CUDNN安装
CUDNN官网:cuDNN Archive | NVIDIA Developer
这里我选择的也是对应CUDA11.x版本的CUDNNv8.4.1
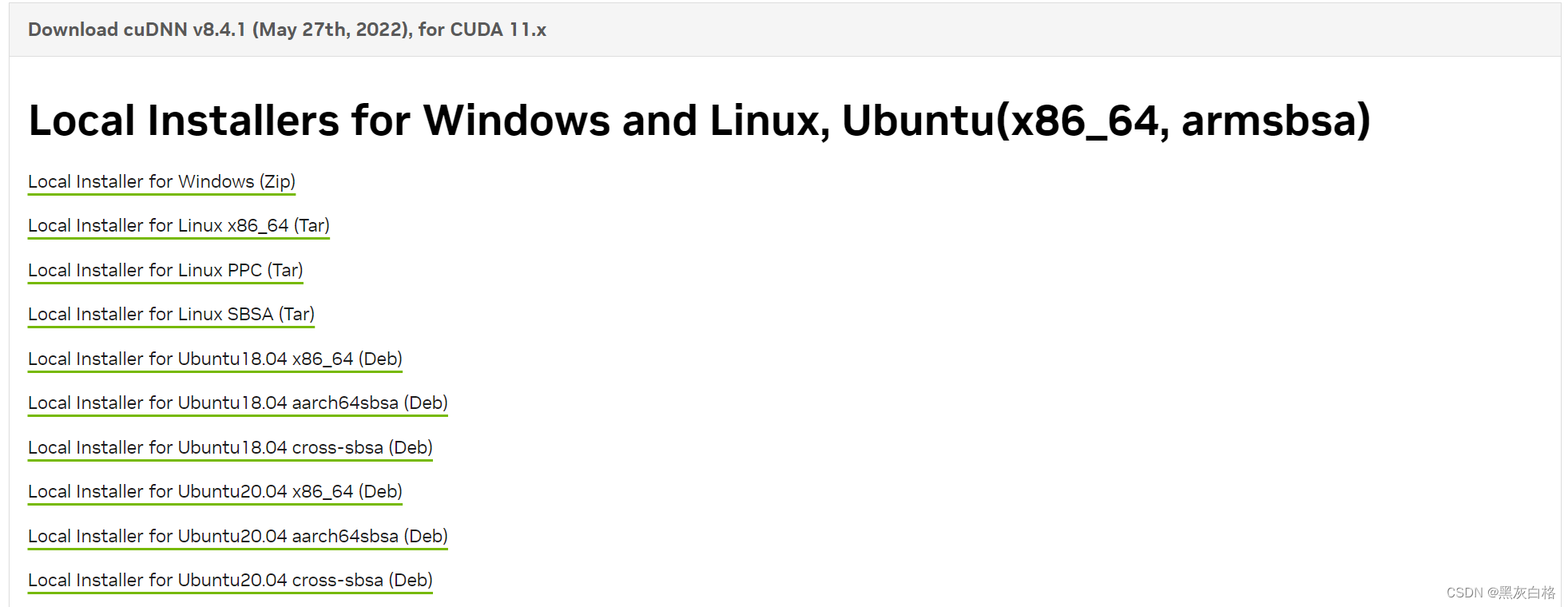
将下载好的压缩包解压,然后将里面所以的内容复制粘贴到刚才CUDA的安装路径中(C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7)

然后清空conda环境重新安装
conda clean -all
使用conda安装时依然存在问题:

故直接采用pip命令进行安装
python -m pip install paddlepaddle-gpu==2.6.0.post117 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html
再次进行测试PaddleOCR环境,安装成功!!

补充:查看电脑中CUDA、CUDNN的版本号
CUDA版本号,cmd输入
nvcc --version
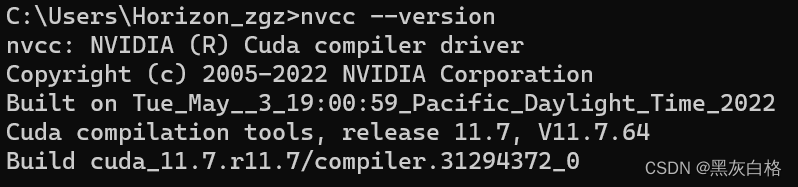
CUDNN的版本号需要进入目录:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.7\include下的cudnn_version.h中查看。记事本编辑打开划到最后可以查看到CUDNN版本为8.4.1

3 安装PaddleOCR whl包
pip install paddleocr>=2.0.1 # 推荐使用2.0.1+版本
安装过程中可能出现错误,如下:

安装paddleocr 的时候 指定PyMuPDF版本
pip install “paddleocr>=2.0.1” --upgrade PyMuPDF==1.21.1
到此,PaddleOCR的环境已经配置完成。
三、在PyCharm中使用PaddleOCR
从PaddleOCR官网中下载需要的代码,链接如下:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/doc/doc_ch/models_list.md

本文以英文检测模型为例。
下载并解压后

创建一个test.py文件进行测试
from paddleocr import PaddleOCR
if __name__ == '__main__':
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, det_model_dir=r"./inference/ch_ppocr_server_v1.1_det_infer",
rec_model_dir=r"./inference/ch_ppocr_server_v1.1_rec_infer",
cls_model_dir=r"./inference/ch_ppocr_mobile_v1.1_cls_infer") # 使用CPU预加载,不用GPU
text_list = ocr.ocr("images/11.jpg", cls=True) # 打开图片文件
# print(text)
# 打印所有文本信息
tiny_dict = {}
i = 0
for t in text_list:
tiny_dict.update({'key'+str(i): t[-1][0]})
i += 1
print(tiny_dict)
运行结果如下:

由于NumPy版本导致的问题,只需将对应的np.int等改为int即可。

最终结果:
版权归原作者 黑灰白格 所有, 如有侵权,请联系我们删除。