
什么是无头浏览器——Headless Browser?
在如今的数字世界中,无头浏览器已经成为开发人员和测试人员不可或缺的工具。无头浏览器指的是一系列无界面的浏览器,这种浏览器能够以编程方式与网页进行交互,可以减少甚至替代手动处理任务。

无头浏览器的应用场景有哪些?
(1)数据提取
无头浏览器擅长网页内容抓取,能够在没有界面的环境下,导航网页、解析HTML和检索数据,从而有效地从网站中提取信息。
(2)自动化测试
无头浏览器在自动化测试领域可以扮演关键角色。它们可以在无人工干预的情况下在Web应用程序上执行测试脚本,实现对Web的功能和性能测试。这种方式加速了测试过程,保证了最终产品质量。
(3)性能指标优化
无头浏览器对于性能监控也很有价值。它们可以测量网页加载时间、执行速度等关键指标,从而深入了解网站的效率。这些基准测试有助于识别瓶颈,提高用户体验。
(4)创建网页快照
无头浏览器可以在任意时间以编程方式生成网页截图,用于帮助编制文档、调试和验证UI。
(5)模拟用户行为
实现用户交互自动化是无头浏览器最强大的功能之一。它们可以模拟点击、表单提交和其他Web操作。通过模仿真实的用户行为,对于测试复杂的工作流程以及确保流畅的用户体验至关重要。
下面重点推荐几个比较优秀的开源免费的无头浏览器,开发人员可以根据需要选型。
01
Puppeteer
https://github.com/puppeteer/puppeteer
GitHub Star: 88K
开发语言:Node/TypeScript/JavaScript
Puppeteer是一个开源的Node.js库,它通过DevTools协议实现了一些API来控制Chrome或Chromium。它可以实现浏览器任务的自动化,例如:Web抓取、自动测试和性能监控等。
Puppeteer支持无头模式,允许它在没有图形界面的情况下运行,并提供生成屏幕截图或者PDF,可以模拟用户交互和捕获性能指标等。它因其功能强大且易于与Web项目集成而被广泛使用。
安装:
npm i puppeteer
使用:
import puppeteer from 'puppeteer';(async () => { // Launch the browser and open a new blank page const browser = await puppeteer.launch(); const page = await browser.newPage(); // Navigate the page to a URL await page.goto('https://developer.chrome.com/'); // Set screen size await page.setViewport({width: 1080, height: 1024}); // Type into search box await page.type('.devsite-search-field', 'automate beyond recorder'); // Wait and click on first result const searchResultSelector = '.devsite-result-item-link'; await page.waitForSelector(searchResultSelector); await page.click(searchResultSelector); // Locate the full title with a unique string const textSelector = await page.waitForSelector( 'text/Customize and automate'); const fullTitle = await textSelector?.evaluate(el => el.textContent); // Print the full title console.log('The title of this blog post is "%s".', fullTitle); await browser.close();})();
02
Selenium WebDriver
https://github.com/SeleniumHQ/selenium
GitHub Star:30K
开发语言:支持Java、Python、Javascript、Ruby、.Net、C++、Rust...

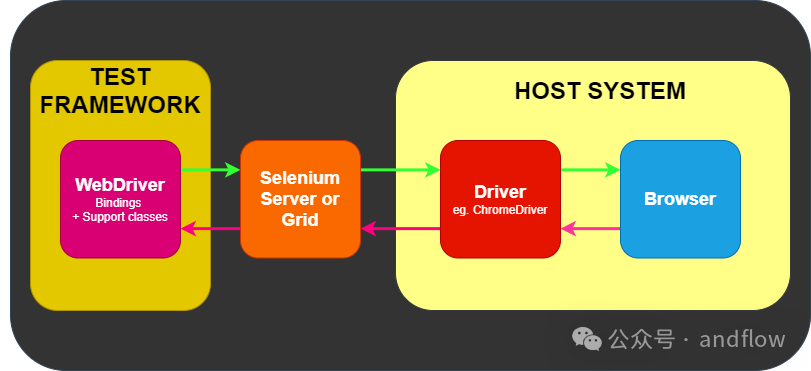
Selenium是一个封装了各种工具和库的浏览器自动化框架和生态系统。用于实现Web浏览器自动化。Selenium专门根据W3C WebDriver规范提供了一个能够与所有主要Web浏览器兼容,并且支持跨语言的编码接口。
03
Playwright
https://github.com/microsoft/playwright-python
GitHub Star:11.4K+
开发语言:Python
Playwright是一个用于实现Web浏览器自动化的Python库。支持端到端测试,提供强大的功能,支持多浏览器,包括:Chromium、Firefox和WebKit。
Playwright可以实现Web爬虫、自动化表单提交和UI测试等任务,提供了用户交互行为模拟和屏幕截图等工具。提供了强大的API,能够有效地支持各种Web应用程序测试需求。
安装python依赖:
pip install pytest-playwright playwright
Demo:
import refrom playwright.sync_api import Page, expectdef test_has_title(page: Page): page.goto("https://playwright.dev/") # Expect a title "to contain" a substring. expect(page).to_have_title(re.compile("Playwright"))def test_get_started_link(page: Page): page.goto("https://playwright.dev/") # Click the get started link. page.get_by_role("link", name="Get started").click() # Expects page to have a heading with the name of Installation. expect(page.get_by_role("heading", name="Installation")).to_be_visible()
04
Chromedp
https://github.com/chromedp/chromedp
GitHub Star:10.8K+
开发语言:Golang
Chromedp是一个可以快速驱动Chrome DevTools协议的浏览器的Golang库。无需外部依赖。
可以查看Golang 的各种应用案例:
https://github.com/chromedp/examples
05
Headless Chrome Crawler
https://github.com/yujiosaka/headless-chrome-crawler
GitHub Star:5.5K
开发语言:JavaScript

这项目提供了一个由无头Chrome驱动的分布式爬虫功能。
项目主要特征包括:
- 支持分布式爬行
- 可配置并发、延迟和重试
- 同时支持深度优先搜索和广度优先搜索算法
- 支持Redis缓存
- 支持CSV和JSON导出结果
- 达到最大请求时暂停,并随时恢复
- 自动插入jQuery进行抓取
- 保存截图作为抓取证据
- 模拟设备和用户代理
- 根据优先级队列提高爬行效率
- 服从 robots.txt
06
Splash
https://github.com/scrapinghub/splash
GitHub Star:4.1K
开发语言:Python
Splash是一个支持JavaScript渲染的HTTP API服务。是一个轻量级的浏览器,具有HTTP API,在Python 3中使用Twisted和QT5实现。
得益于它的快速、轻量级和无状态等特性,使其易于使用和推广。
07
Splinter
https://github.com/cobrateam/splinter
GitHub Star:2.7K
开发语言:Python
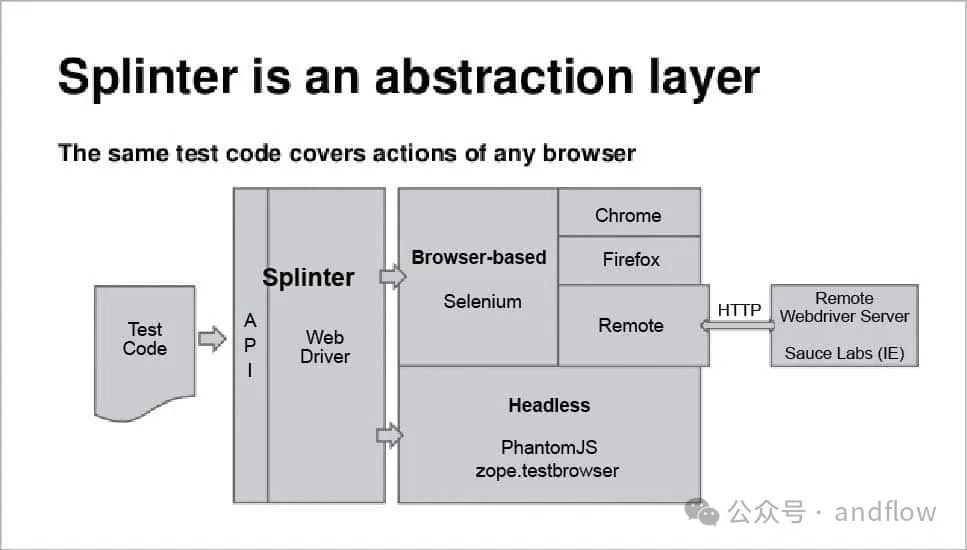
Splinter是一个基于Python的Web应用程序测试工具,可用于Web应用程序自动化,提供了简单且一致的API。
它可以自动执行浏览器操作,例如:导航到URL、填写表格以及与页面元素交互。Splinter支持各种Web驱动程序,包括Selenium WebDriver、Google Chrome和Firefox等。
它提供了非常友好的API来控制浏览器,简化了自动化测试过程的开发,使其成为Web应用程序的开发人员和测试人员的宝贵工具。
主要特点包括:
- 易于学习:API的设计是直观和快速拿起。
- 更快的编码:快速且可靠地与浏览器自动交互,而无需与工具发生冲突。
- 强大:专为真实的世界用例而设计,可防止常见的自动化怪癖。
- 灵活:对较低级别工具的访问从不隐藏。
- 强大:支持多个自动化驱动程序(Selenium,Django,Flask,ZopeTestBrowser)。
08
Serverless-chrome
https://github.com/adieuadieu/serverless-chrome
Github Star:2.9K
开发语言:JavaScript
这是一个无服务器Chrome 。这个项目的目的主要是为在无服务器函数调用期间使用Headless Chrome提供框架。Serverless-chrome负责构建和捆绑Chrome二进制文件,并确保在执行无服务器函数时Chrome正在运行。此外,该项目还提供了一些常见模式的服务,例如:对页面进行屏幕截图、打印到PDF、页面抓取等。
09
Ferrum
https://github.com/rubycdp/ferrum
GitHub Star:1.7K
开发语言:Ruby

Ferrum是一个用于实现Chrome自动化的Ruby库。它提供了一种控制浏览器的方法,而不需要像Selenium这样的驱动程序。Ferrum可以处理诸如浏览网页、与元素交互以及捕获屏幕截图等任务。
它对于Web抓取、自动化测试和模拟用户交互非常有用。Ferrum支持在无头和非无头模式下运行,使其能够满足各种自动化需求。
10
Surf
https://github.com/headzoo/surf
GitHub Star:1.5K
Surf是一个Golang库,Surf不仅仅是一个Web内容提取的Go解决方案,还实现了一个可以用于编程控制的虚拟Web浏览器。
Surf被设计成像Web浏览器一样,功能包括:cookie管理、历史记录、书签、用户代理、表单提交、通过jQuery样式的CSS选择器选择和遍历DOM、抓取图像、样式表等。
安装:
go get gopkg.in/headzoo/surf.v1
Demo:
package main
import ( "gopkg.in/headzoo/surf.v1" "fmt")func main() { bow := surf.NewBrowser() err := bow.Open("http://golang.org") if err != nil { panic(err) } // Outputs: "The Go Programming Language" fmt.Println(bow.Title())}
转自:10个优秀的开源无头浏览器——自动化测试、爬虫、RPA利器
版权归原作者 Hacker_Future 所有, 如有侵权,请联系我们删除。