
基本的使用
showdatabases;createdatabase 数据库名;//创建数据库use 数据库名; //使用数据库
使用完use语句之后接下来的SQL操作都是针对当前数据库的了
showtables;//查看某个数据库的所有表格showtablesfrom 数据库名;
createtable 表名称{
字段名 数据类型,
字段名 数据类型
}
createtable student{
id int,
name varchar(20)//名字最长不超过20个字符
}
select*from 数据表名称;
select*from student;insertinto 表名称 values(值列表);insertinto student values(1,'张三');showcreatetable 表名称;//查看表的详细创建信息showcreatedatabase 数据库名称;droptable 表名称; //删除表dropdatabase 数据库名称;
基本的select语句
- DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。 主要的语句关键字包括 CREATE 、 DROP 、 ALTER 等。 DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。 主要的语句关键字包括 INSERT 、 DELETE 、 UPDATE 、 SELECT 等。 SELECT是SQL语言的基础,最为重要。 DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。 主要的语句关键字包括 GRANT 、 REVOKE 、 COMMIT 、 ROLLBACK 、 SAVEPOINT 等。
- MySQL 在 Windows 环境下是大小写不敏感的 MySQL 在 Linux 环境下是大小写敏感的 数据库名、表名、表的别名、变量名是严格区分大小写的 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的。 推荐采用统一的书写规范: 数据库名、表名、表别名、字段名、字段别名等都小写 SQL 关键字、函数名、绑定变量等都大写
- 单行注释:#注释文字(MySQL特有的方式) 单行注释:-- 注释文字(–后面必须包含一个空格。) 多行注释:/* 注释文字 */
- 必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使 用`(着重号)引起来
SELECT 标识选择哪些列
FROM 标识从哪个表中选择
SELECT1+1,3*2;SELECT1+1,3*2FROM DUAL;-- 伪表,和上面一行一样 select 字段 from 表名select id as"编号",`name`as"姓名"from t_stu;#起别名时,as都可以省略select id as 编号,`name`as 姓名 from t_stu;#如果字段别名中没有空格,那么可以省略""select id as 编 号,`name`as 姓 名 from t_stu;#错误,如果字段别名中有空格,那么不能省略""SELECT department_id, location_id
FROM departments;//选择特定的列SELECT last_name AS name, commission_pct comm
FROM employees;//给这个字段名换一个别名,可以省略ASSELECT last_name "Name", salary*12"Annual Salary"FROM employees;SELECTDISTINCT department_id
FROM employees;// DISTINCT可以去除重复行1.DISTINCT 需要放到所有列名的前面,如果写成 SELECT salary,DISTINCT department_id
FROM employees 会报错。
2.DISTINCT 其实是对后面所有列名的组合进行去重,你能看到最后的结果是 74 条,因为这 74 个部
门id不同,都有 salary 这个属性值。如果你想要看都有哪些不同的部门(department_id),只需
要写 DISTINCT department_id 即可,后面不需要再加其他的列名了。
SELECT employee_id,salary,commission_pct,12* salary *(1+ commission_pct)"annual_sal"FROM employees;
所有运算符或列值遇到null值,运算的结果都为null
这里一定要注意,在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长
度是空。而且,在 MySQL 里面,空值是占用空间的。暂时不明白!!!
SELECT*FROM`ORDER`;
我们需要保证表中的字段、表名等没有和保留字、数据库系统或常用方法冲突。如果真的相同,请在
SQL语句中使用一对``(着重号)引起来。
SELECT 查询还可以对常数进行查询。对的,就是在 SELECT 查询结果中增加一列固定的常数列。这列的
取值是我们指定的,而不是从数据表中动态取出的。
即查询常数(在前面加点自己想要添加的列)
SELECT'帅'as corporation, last_name FROM employees;DESCRIBE 表名称;
DESC 表名称;
可以显示表中字段的详细信息
SELECT 字段1,字段2FROM 表名
WHERE 过滤条件
SELECT employee_id, last_name, job_id, department_id
FROM employees
WHERE department_id =90;
运算符
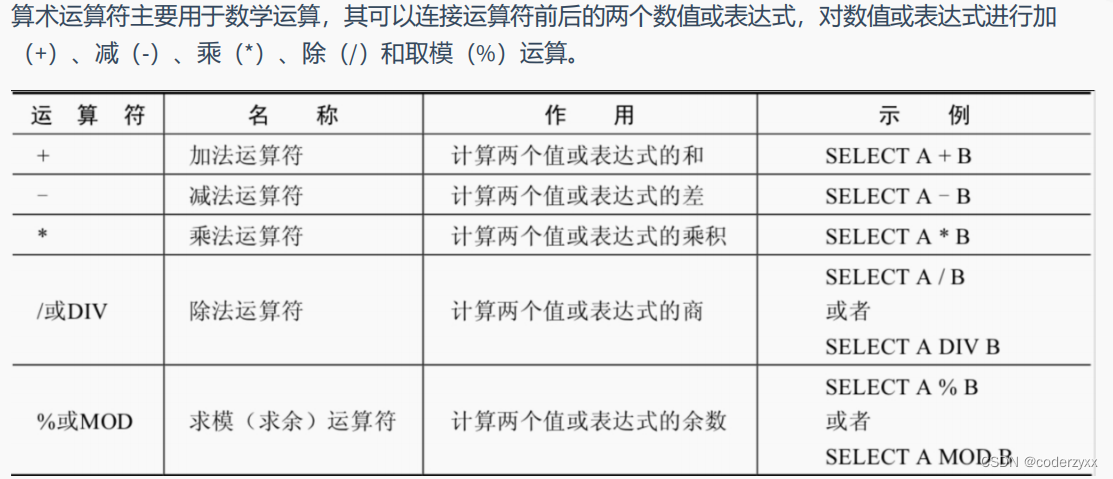
- 一个整数类型的值对整数进行加法和减法操作,结果还是一个整数; 一个整数类型的值对浮点数进行加法和减法操作,结果是一个浮点数; 加法和减法的优先级相同,进行先加后减操作与进行先减后加操作的结果是一样的; 在Java中,+的左右两边如果有字符串,那么表示字符串的拼接。但是在MySQL中+只表示数值相加。如果遇到非数值类型,先尝试转成数值,如果转失败,就按0计算。(补充:MySQL中字符串拼接要使用字符串函数CONCAT()实现) 一个数乘以整数1和除以整数1后仍得原数; 一个数乘以浮点数1和除以浮点数1后变成浮点数,数值与原数相等; 一个数除以整数后,不管是否能除尽,结果都为一个浮点数; 一个数除以另一个数,除不尽时,结果为一个浮点数,并保留到小数点后4位; 乘法和除法的优先级相同,进行先乘后除操作与先除后乘操作,得出的结果相同。 在数学运算中,0不能用作除数,在MySQL中,一个数除以0为NULL。
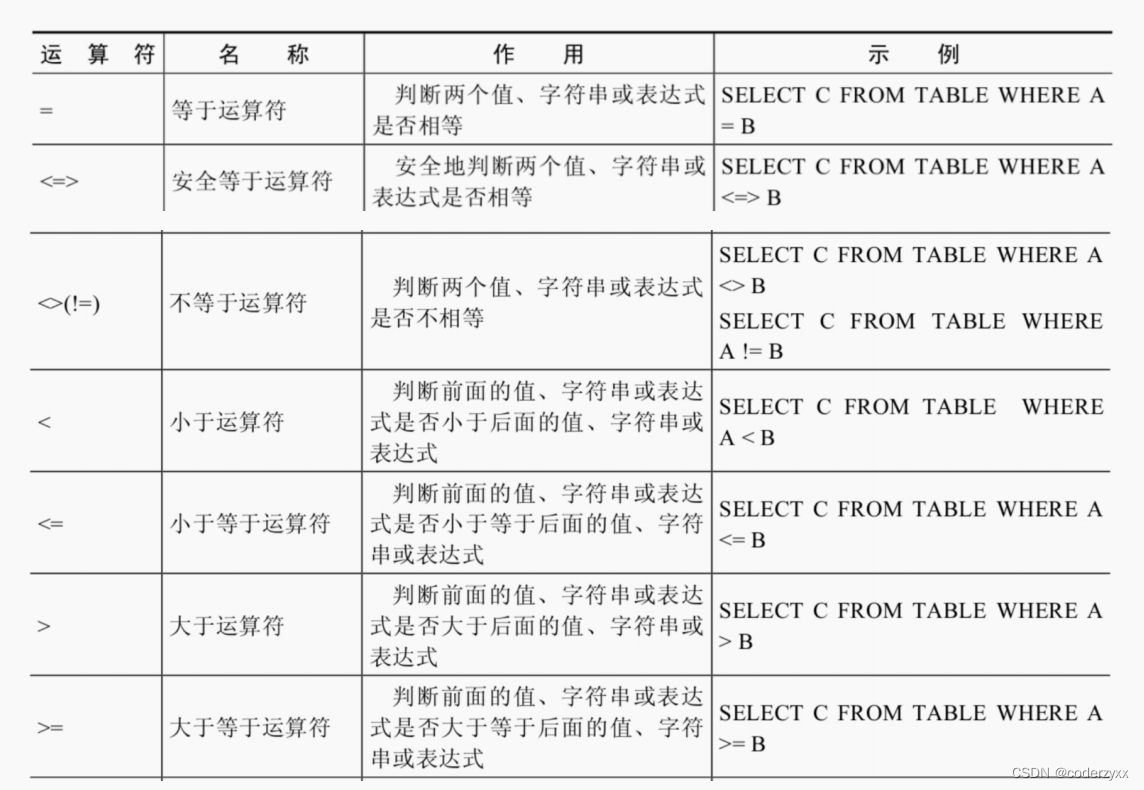 在使用等号运算符时,遵循如下规则: 如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的是每个字符串中字符的ANSI编码是否相等。 如果等号两边的值都是整数,则MySQL会按照整数来比较两个值的大小。 如果等号两边的值一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较。 如果等号两边的值、字符串或表达式中有一个为NULL,则比较结果为NULL。 安全等于运算符(<=>)与等于运算符(=)的作用是相似的, 唯一的区别 是‘<=>’可 以用来对NULL进行判断。在两个操作数均为NULL时,其返回值为1,而不为NULL;当一个操作数为NULL 时,其返回值为0,而不为NULL 不等于运算符(<>和!=)用于判断两边的数字、字符串或者表达式的值是否不相等, 如果不相等则返回1,相等则返回0。不等于运算符不能判断NULL值。如果两边的值有任意一个为NULL,或两边都为NULL,则结果为NULL。
在使用等号运算符时,遵循如下规则: 如果等号两边的值、字符串或表达式都为字符串,则MySQL会按照字符串进行比较,其比较的是每个字符串中字符的ANSI编码是否相等。 如果等号两边的值都是整数,则MySQL会按照整数来比较两个值的大小。 如果等号两边的值一个是整数,另一个是字符串,则MySQL会将字符串转化为数字进行比较。 如果等号两边的值、字符串或表达式中有一个为NULL,则比较结果为NULL。 安全等于运算符(<=>)与等于运算符(=)的作用是相似的, 唯一的区别 是‘<=>’可 以用来对NULL进行判断。在两个操作数均为NULL时,其返回值为1,而不为NULL;当一个操作数为NULL 时,其返回值为0,而不为NULL 不等于运算符(<>和!=)用于判断两边的数字、字符串或者表达式的值是否不相等, 如果不相等则返回1,相等则返回0。不等于运算符不能判断NULL值。如果两边的值有任意一个为NULL,或两边都为NULL,则结果为NULL。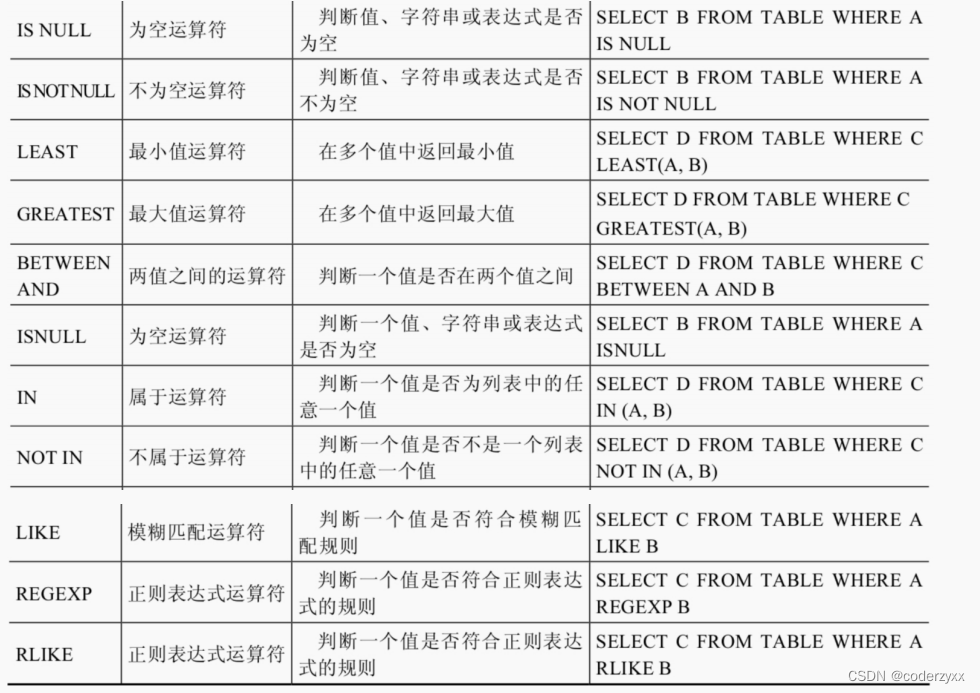
#找不是null的另一种方法SELECT last_name,salary,commission_pct
FROM employees
WHERENOT commission_pct <=>NULL;SELECT employee_id,commission_pct FROM employees WHERE commission_pct ISNULL;SELECT employee_id,commission_pct FROM employees WHERE commission_pct <=>NULL;SELECT employee_id,commission_pct FROM employees WHERE ISNULL(commission_pct);SELECT employee_id,commission_pct FROM employees WHERE commission_pct =NULL;//这个不行,因为where中=会返回NULL
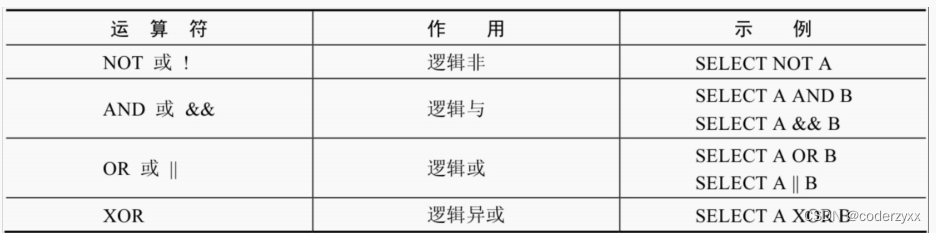
- 逻辑或(OR或||)运算符是当给定的值都不为NULL,并且任何一个值为非0值时,则返 回1,否则返回0;当一个值为NULL,并且另一个值为非0值时,返回1,否则返回NULL;当两个值都为NULL时,返回NULL。 逻辑异或(XOR)运算符是当给定的值中任意一个值为NULL时,则返回NULL;如果 两个非NULL的值都是0或者都不等于0时,则返回0;如果一个值为0,另一个值不为0时,则返回1。
排序与分页
- DESC降序,ASC为升序
#WHERE需要声明在from后,order by 之前,他先从from where中拿数据,然后select,最后order bySELECT employee_id ,salary,department_id
FROM employees
WHERE department_id IN(50,60,70)ORDERBY department_id DESC;SELECT last_name, department_id, salary
FROM employees
ORDERBY department_id, salary DESC;
这种department_id就是默认情况下的ASC
列的别名可以在orderby 中用
SELECT employee_id , last_name , salary *12 annual_sal
FROM employees
ORDERBY annual_sal;
列的别名不可以在where中用
SELECT employee_id , last_name , salary *12 annual_sal
FROM employees
WHERE annual_sal >81600;LIMIT[位置偏移量,] 行数
第一个“位置偏移量”参数指示MySQL从哪一行开始显示,是一个可选参数,如果不指定“位置偏移
量”,将会从表中的第一条记录开始(第一条记录的位置偏移量是0,第二条记录的位置偏移量是
1,以此类推);第二个参数“行数”指示返回的记录条数。
--前10条记录:SELECT*FROM 表名 LIMIT0,10;
或者
SELECT*FROM 表名 LIMIT10;LIMIT 子句必须放在整个SELECT语句的最后!
MySQL 8.0中可以使用“LIMIT3OFFSET4”,意思是获取从第5条记录开始后面的3条记录,和“LIMIT4,3;”返回的结果相同。
使用 LIMIT 的好处:
约束返回结果的数量可以 减少数据表的网络传输量 ,也可以 提升查询效率 。如果我们知道返回结果只有
1 条,就可以使用 LIMIT1 ,告诉 SELECT 语句只需要返回一条记录即可。这样的好处就是 SELECT 不需要扫描完整的表,只需要检索到一条符合条件的记录即可返回。
多表查询
#案例:查询员工的姓名及其部门名称SELECT last_name, department_name
FROM employees, departments
WHERE employees.department_id = departments.department_id;
表的别名:使用别名可以简化查询。
列名前使用表名前缀可以提高查询效率。
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e , departments d
WHERE e.department_id = d.department_id;
需要注意的是,如果我们使用了表的别名,在查询字段中、过滤条件中就只能使用别名进行代替,
不能使用原有的表名,否则就会报错。
SELECT e.last_name, e.salary, j.grade_level
FROM employees e, job_grades j
WHERE e.salary BETWEEN j.lowest_sal AND j.highest_sal;#如果有n个表查询,至少要n-1个连接条件SELECT emp.employee_id,dep.department_name,dep.department_id,l.city,l.location_id
FROM employees emp,departments dep,locations l
WHERE emp.department_id = dep.department_id
AND dep.location_id = l.location_id;
当table1和table2本质上是同一张表,只是用取别名的方式虚拟成两张表以代表不同的意义。然后两
个表再进行内连接,外连接等查询。
SELECT CONCAT(worker.last_name ,' works for ', manager.last_name)FROM employees worker, employees manager
WHERE worker.manager_id = manager.employee_id ;
内连接: 合并具有同一列的两个以上的表的行, 结果集中不包含一个表与另一个表不匹配的行
外连接: 两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的
行 ,这种连接称为左(或右) 外连接。没有匹配的行时, 结果表中相应的列为空(NULL)。
如果是左外连接,则连接条件中左边的表也称为 主表 ,右边的表称为 从表 。
如果是右外连接,则连接条件中右边的表也称为 主表 ,左边的表称为 从表 。
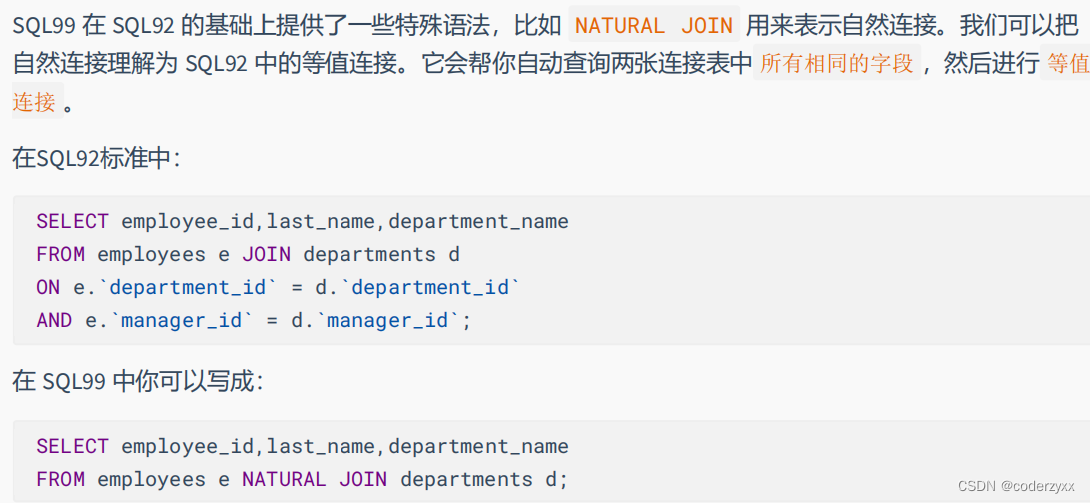
SQL99 采用的这种嵌套结构非常清爽、层次性更强、可读性更强,即使再多的表进行连接也都清晰
可见。如果你采用 SQL92,可读性就会大打折扣。
语法说明:
可以使用 ON 子句指定额外的连接条件。
这个连接条件是与其它条件分开的。
ON 子句使语句具有更高的易读性。
关键字 JOIN、INNERJOIN、CROSSJOIN 的含义是一样的,都表示内连接
SELECT e.employee_id, e.last_name, e.department_id,
d.department_id, d.location_id
FROM employees e JOIN departments d
ON(e.department_id = d.department_id);SELECT employee_id, city, department_name
FROM employees e
JOIN departments d
ON d.department_id = e.department_id
JOIN locations l
ON d.location_id = l.location_id;SELECT e.last_name, e.department_id, d.department_name
FROM employees e
LEFTOUTERJOIN departments d
ON(e.department_id = d.department_id);
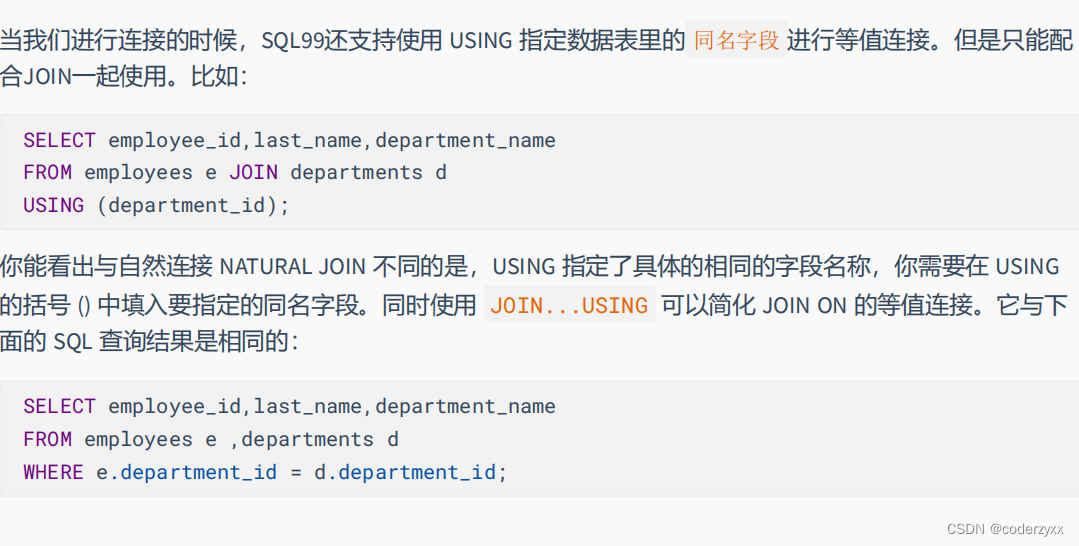
需要注意的是,MySQL不支持FULLJOIN,但是可以用 LEFTJOINUNIONRIGHTjoin代替。
合并查询结果 利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并
时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SELECT语句之间使用UNION或UNIONALL关键字分隔。
UNION 操作符返回两个查询的结果集的并集,去除重复记录。
UNIONALL操作符返回两个查询的结果集的并集。对于两个结果集的重复部分,不去重。
注意:执行UNIONALL语句时所需要的资源比UNION语句少。如果明确知道合并数据后的结果数据
不存在重复数据,或者不需要去除重复的数据,则尽量使用UNIONALL语句,以提高数据查询的效
率。
SELECT*FROM employees WHERE email LIKE'%a%'UNIONSELECT*FROM employees WHERE department_id>90;
- 我们要控制连接表的数量 。多表连接就相当于嵌套 for 循环一样,非常消耗资源,会让 SQL 查询性能下降得很严重,因此不要连接不必要的表。在许多 DBMS 中,也都会有最大连接表的限制。 【强制】超过三个表禁止 join。需要 join 的字段,数据类型保持绝对一致;多表关联查询时, 保证被关联的字段需要有索引。说明:即使双表 join 也要注意表索引、SQL 性能。来源:阿里巴巴《Java开发手册》
单行函数
- 数值函数
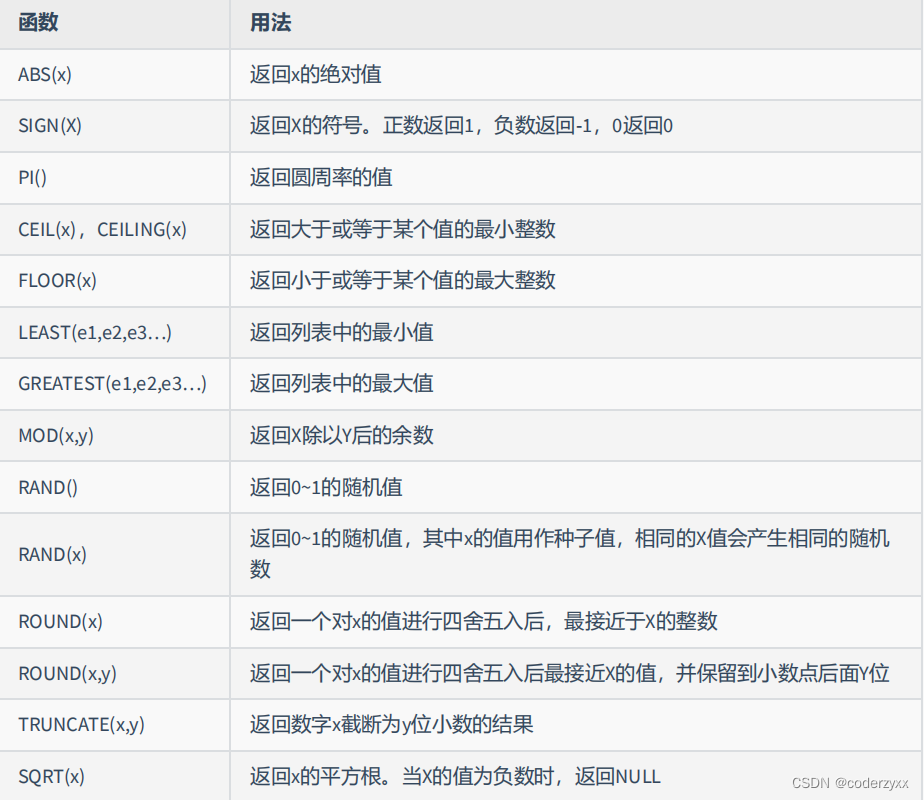

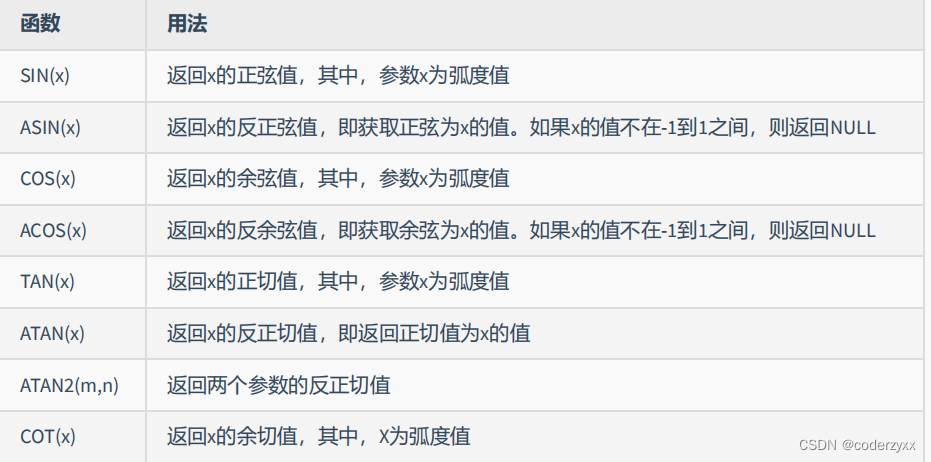
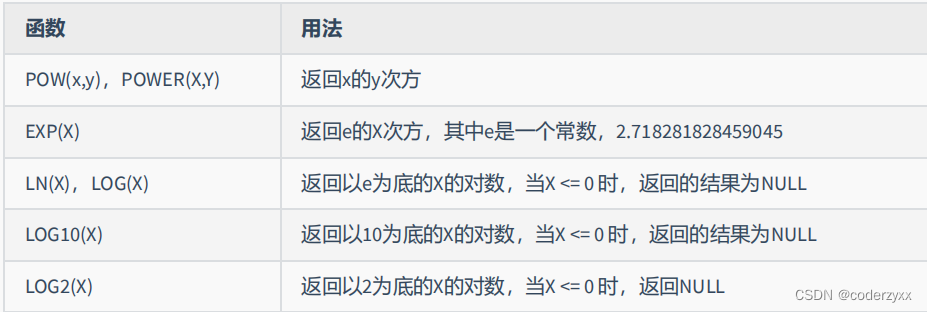
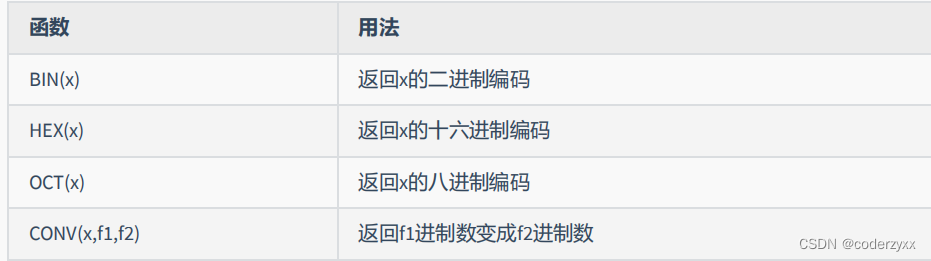
SELECT BIN(10),HEX(10),OCT(10),CONV(10,2,8)FROM DUAL;
- 字符串函数
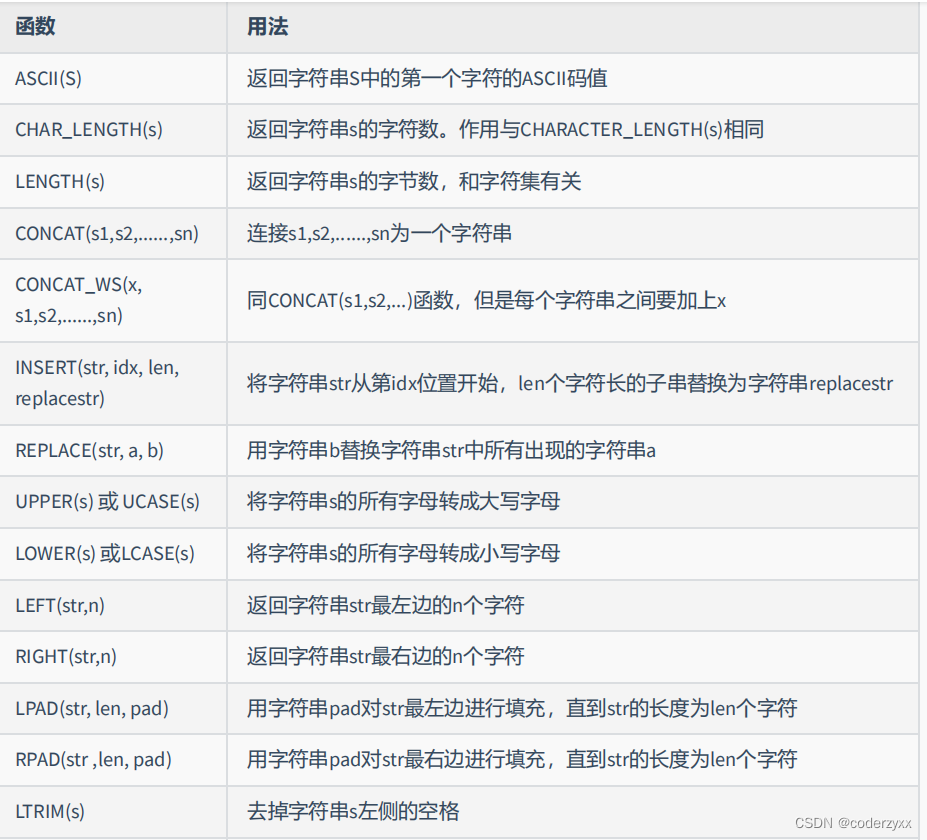
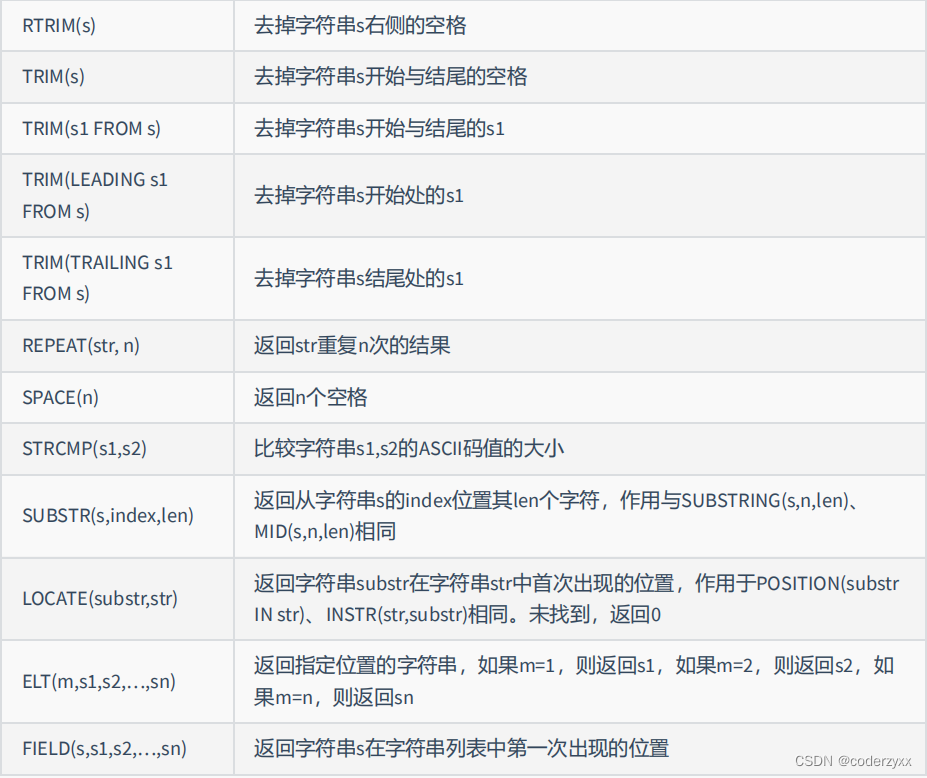
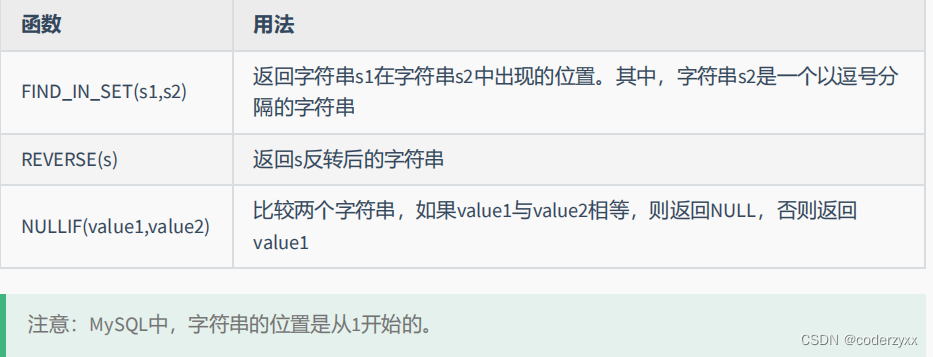
SELECT CONCAT(emp.last_name,' worked for ',mgr.last_name)"details"FROM employees emp JOIN employees mgr
WHERE emp.`manager_id`= mgr.employee_id;
- 日期相关的函数
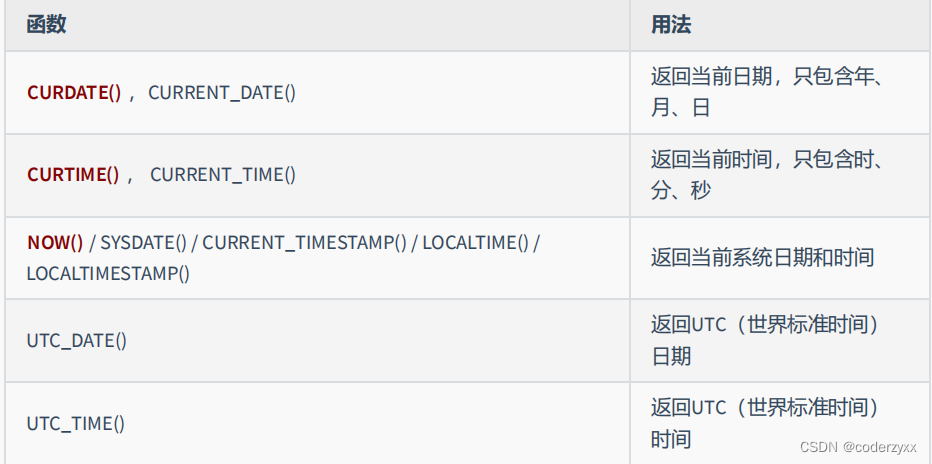
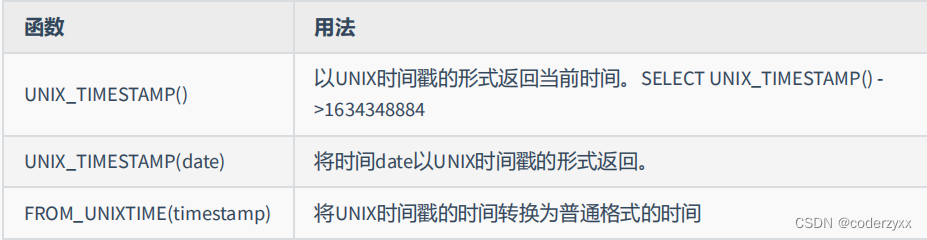
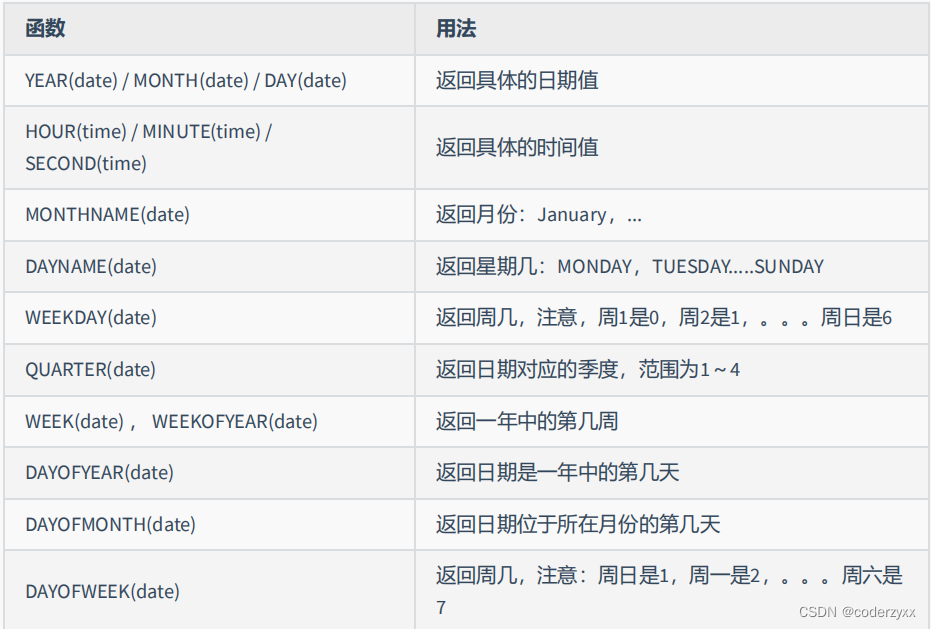
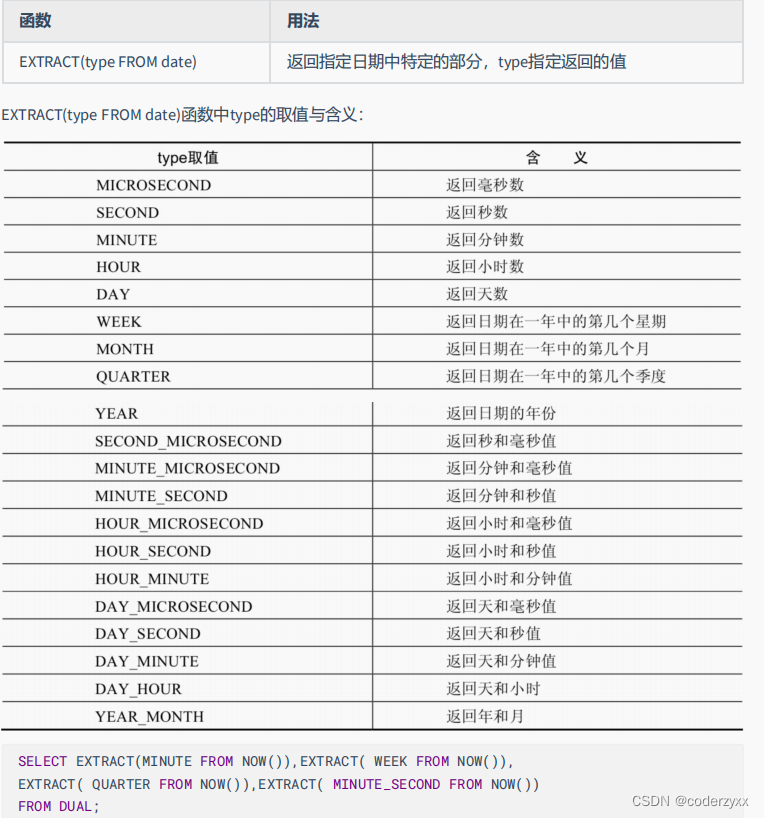
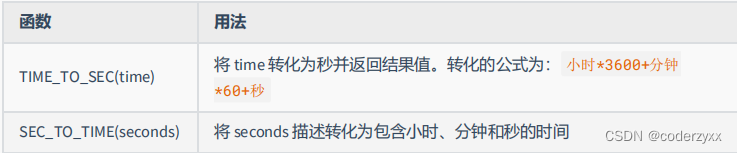
- 还有挺多,看看课件吧
- 流程控制函数
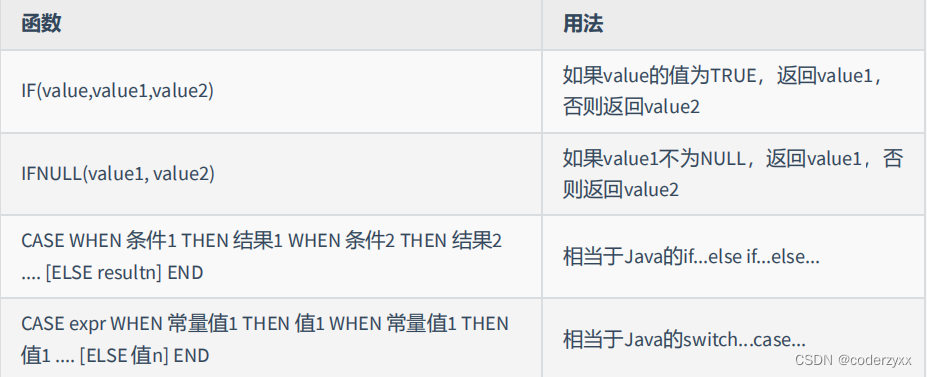
SELECT employee_id,salary,CASEWHEN salary>=15000THEN'高薪'WHEN salary>=10000THEN'潜力股'WHEN salary>=8000THEN'屌丝'ELSE'草根'END"描述"FROM employees;SELECT oid,`status`,CASE`status`WHEN1THEN'未付款'WHEN2THEN'已付款'WHEN3THEN'已发货'WHEN4THEN'确认收货'ELSE'无效订单'ENDFROM t_order;
- 加密函数
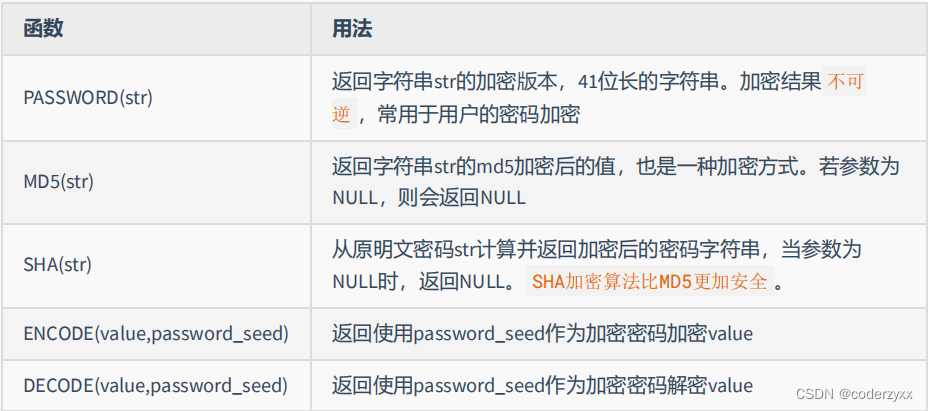
- mysql信息函数
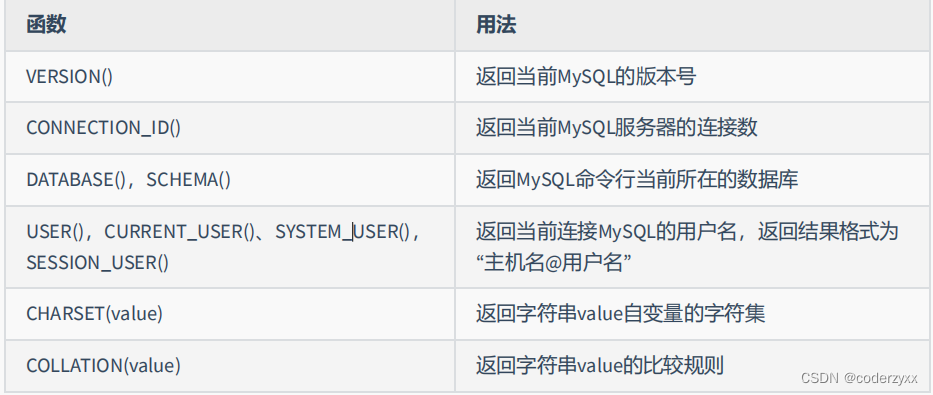
- 其他函数
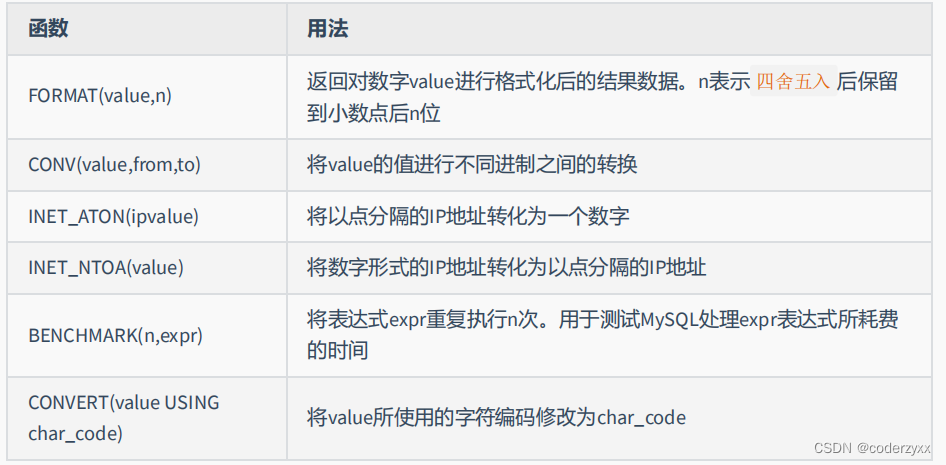
聚合函数
可以对数值型数据使用AVG 和 SUM 函数。
可以对任意数据类型的数据使用 MIN 和 MAX 函数。
COUNT(*)返回表中记录总数,适用于任意数据类型。
COUNT(expr) 返回expr不为空的记录总数。
SELECTAVG(salary),MAX(salary),MIN(salary),SUM(salary)FROM employees
WHERE job_id LIKE'%REP%';SELECTCOUNT(*)FROM employees
WHERE department_id =50;SELECTCOUNT(commission_pct)FROM employees
WHERE department_id =50;

SELECTcolumn, group_function(column)FROMtable[WHERE condition][GROUPBY group_by_expression][ORDERBYcolumn];SELECT department_id,AVG(salary)FROM employees
GROUPBY department_id ;SELECT department_id dept_id, job_id,SUM(salary)FROM employees
GROUPBY department_id, job_id ;

- 过滤分组:HAVING子句
- 行已经被分组。
- 使用了聚合函数。
- 满足HAVING 子句中条件的分组将被显示。
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。


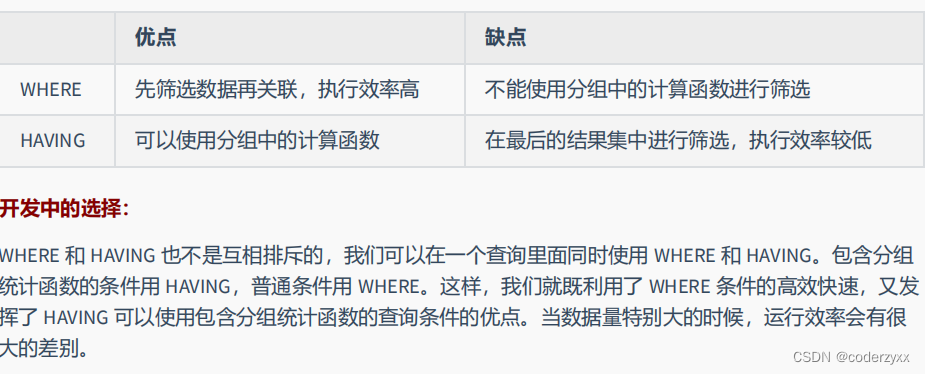

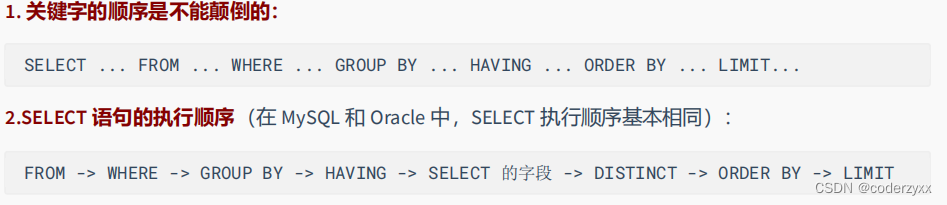 在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个 虚拟表 ,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个 虚拟表 ,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
标签:
mysql
本文转载自: https://blog.csdn.net/j15941558855/article/details/128001824
版权归原作者 coderzyxx 所有, 如有侵权,请联系我们删除。
版权归原作者 coderzyxx 所有, 如有侵权,请联系我们删除。