
(一)概述
前段时间公司规划了一个新的项目,我成了这个项目的负责人。在做技术选型时,有一个需求阻碍了前进的步伐。大概有十亿条数据,数据总量在六百G左右,这些海量的数据需要每天根据一定的逻辑计算得到几千万的值。当数据量达到这种程度时,Java应用已经无法支撑了,于是在技术选型时选中了大数据计算框架–Spark。
(二)什么是Spark
Spark是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。主要用来做大数据的分析计算。Spark是一个分布式数据快速分析框架,提供了比MapReduce更丰富的模型,可以在内存中对数据集进行多次迭代,以支持复杂的数据挖掘算法和图形计算算法。针对数亿级别的计算需求,Spark可以将所有数据读入到内存中,按配置的不同在内部生成几十或者几百个算子同时计算,速度十分快。
Spark的主要模块分为以下几个:
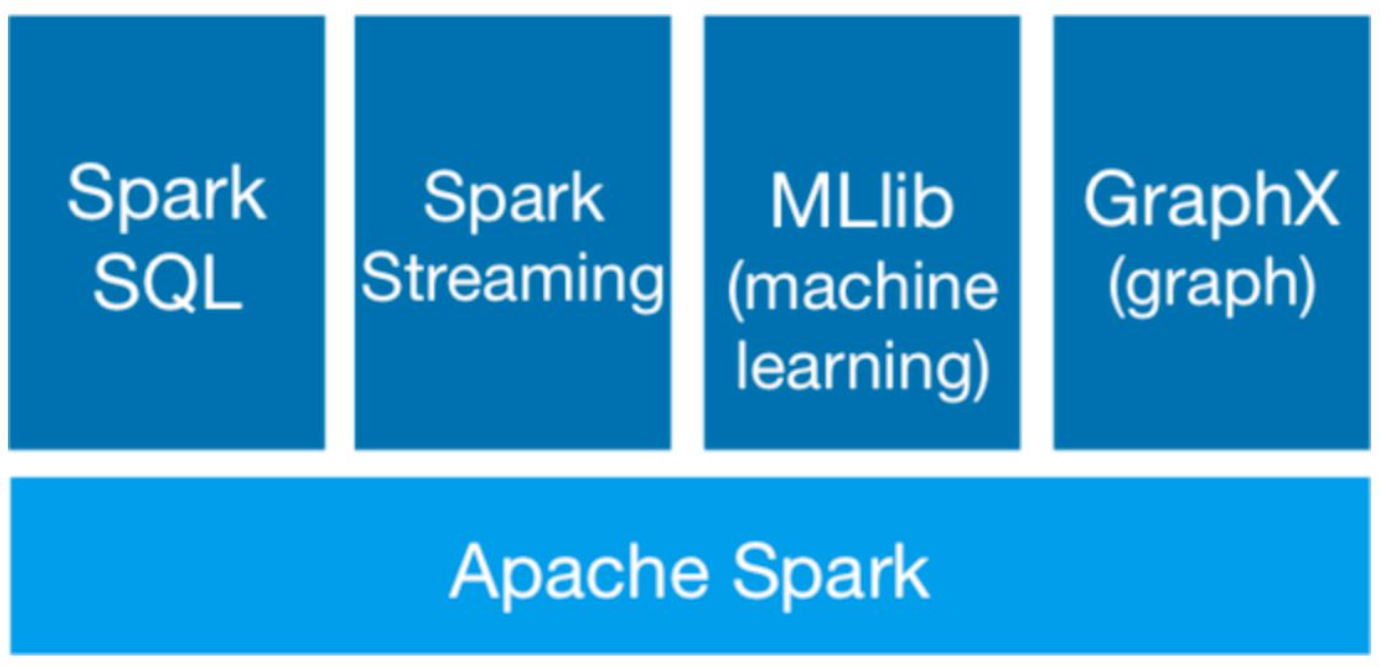
Spark Core: 提供了Spark最基础与最核心的功能,Spark的其他模块都是在Spark Core上进行扩展。
Spark SQL:用来操作结构化数据的组件,通过SparkCore,用户可以使用SQL来查询数据。
Spark Streaming:Spark平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流API。
Spark MLlib:一个机器学习算法库。
Spark GraphX:Spark面向图计算提供的框架和算法库。
(三)Spark 应用构建
Spark的源码是用scala语言写的,同时也支持Java版本。更推荐使用scala语言去写spark代码,但是对程序员而言有一定的成本,因此在项目比较急的情况下使用Java写也是没问题的。
Spark的生产环境中使用需要搭建一套Spark运行环境,目前我所在公司搭建的Spark集群内存达到了1T,完全可以把所有的数据放进内存中计算。同时Spark也支持本地直接调用,通过引入maven依赖即可。
首先介绍在Idea中如何搭建Spark环境,本文所使用的scala版本是2.12,运行项目前首先确保安装了scala环境。
首先创建一个Maven项目,项目结构如下:
安装Idea中的scala插件:
在Project Structure中将scala引入
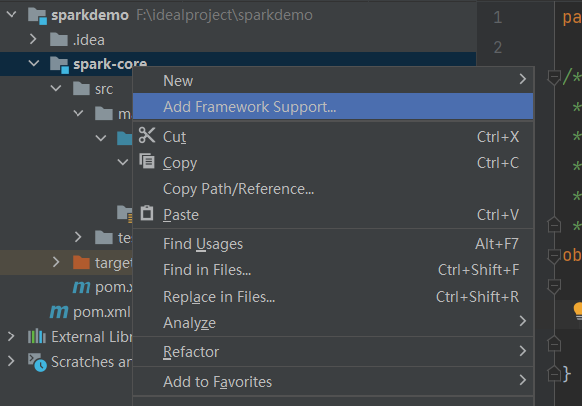
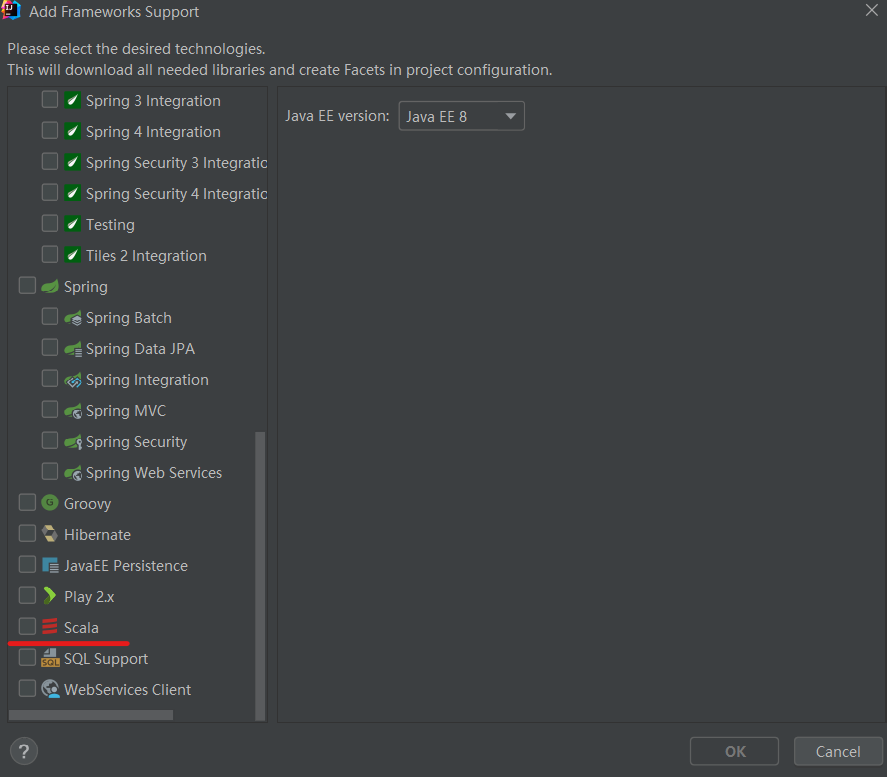
选择Add Framework Suppor,将里面的scala勾选
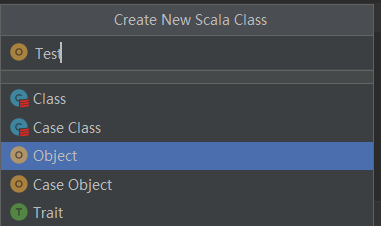
创建一个Object类型的Scala文件
编写测试代码:
object Test {def main(args: Array[String]):Unit={
println("hello world")}}
如果成功输出,说明环境一切正常。
(四) wordCount案例
WordCount是大数据界的HelloWorld,一个最经典的MapReduce案例,这个案例是用来统计每个单词出现的次数,下面进入正题。
首先在Idea中引入Spark相关的依赖,我用的Scala是2.12版本,需要和依赖对齐:
<dependencies><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0</version></dependency></dependencies>
在sparkdemo根目录下创建一个文件夹data,在里面放两个文件分别是1.txt和2.txt,分别写上
Hello world
Hello scala
编写WordCount程序,先介绍Java的使用,Spark中具体的代码含义会在后续博客中更新,整个程序做的事情就是统计两个文件中每个单词出现的次数,是最经典的MapReduce案例:
publicclassJavaWordCount{publicstaticvoidmain(String[] args){
SparkConf conf =newSparkConf().setAppName("wordCount").setMaster("local");
JavaSparkContext sc =newJavaSparkContext(conf);//读取文件转成RDD
JavaRDD<String> lines = sc.textFile("data/*");//将每一行的单词根据空格拆分
JavaRDD<String> words = lines.flatMap((FlatMapFunction<String, String>) s -> Arrays.asList(s.split(" ")).iterator());//将Hello转化为(Hello,1)这种格式
JavaPairRDD<String, Integer> wordToOne = words.mapToPair((PairFunction<String, String, Integer>) s ->newTuple2<String,Integer>(s,1));//根据key进行统计
JavaPairRDD<String, Integer> wordToCount = wordToOne.reduceByKey((x, y)-> x + y);//输出结果
wordToCount.foreach((VoidFunction<Tuple2<String, Integer>>) stringIntegerTuple2 -> System.out.println(stringIntegerTuple2._1+stringIntegerTuple2._2));
sc.close();}}
使用scala实现的版本如下:
object WordCount {def main(args: Array[String]):Unit={val sparkConf =new SparkConf().setMaster("local").setAppName("WordCount");val sparkContext =new SparkContext(sparkConf);val lines: RDD[String]= sparkContext.textFile(path ="data/*");val words: RDD[String]= lines.flatMap(_.split(" "))val wordToOne: RDD[(String,Int)]= words.map(word =>(word,1))val wordToCount = wordToOne.reduceByKey((x, y)=> x + y).foreach(println)
sparkContext.stop();}}
运行结果如下:

(五)总结
本文只要结合具体的需求引出Spark,并快速介绍了Spark能做的一些事情,希望对你有所启发。我是鱼仔,我们下期再见。
版权归原作者 Java鱼仔 所有, 如有侵权,请联系我们删除。