
1.简介
mmsegmentation是目前比较全面和好用的用于分割模型的平台,原始的github链接
https://github.com/open-mmlab/mmsegmentation
2.GPU环境配置
我是按照自己的经历步骤配置环境的,目前把我配置环境的过程记录一下。
我的服务器信息:
Ubuntu 16.04.6 LTS (GNU/Linux 4.4.0-151-generic x86_64)
在服务器上已经安装了anaconda的,所以使用anaconda创建一个mmsegmentation训练的虚拟环境
【1】创建虚拟环境:
conda create -n mmlab python=3.8
目前我觉得3.7,3.8应该都可以的(其中mmlab是为该虚拟环境起的名字其他都OK的)
【2】激活虚拟环境:
conda activate mmlab
【3】安装所需要的包:
将原repo的代码我直接download到服务器上了,
cd
到
mmsegmentation-master
目录下面,直接执行
pip install -r requirements.txt
【4】安装额外的包:
需要根据自己的机器cuda的版本安装对应的pytorch和torchversion
cuda版本和torch版本的对应关系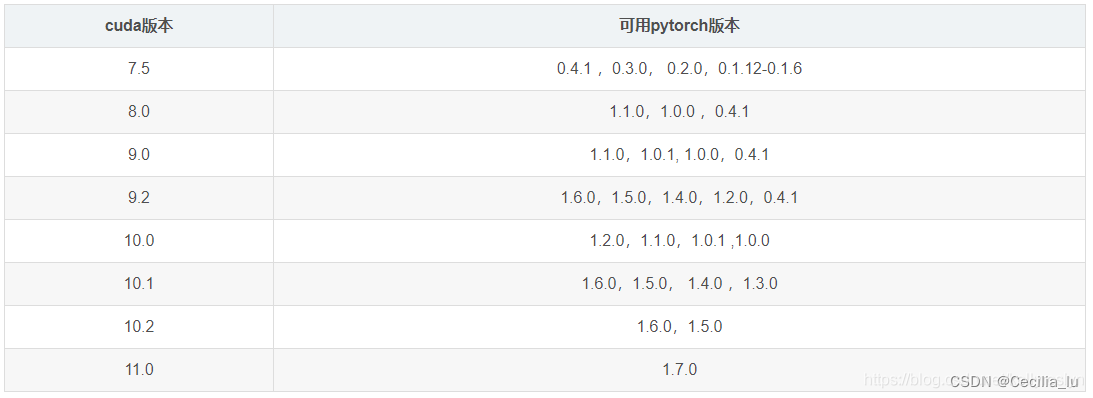
torch版本和torchversion版本的对应关系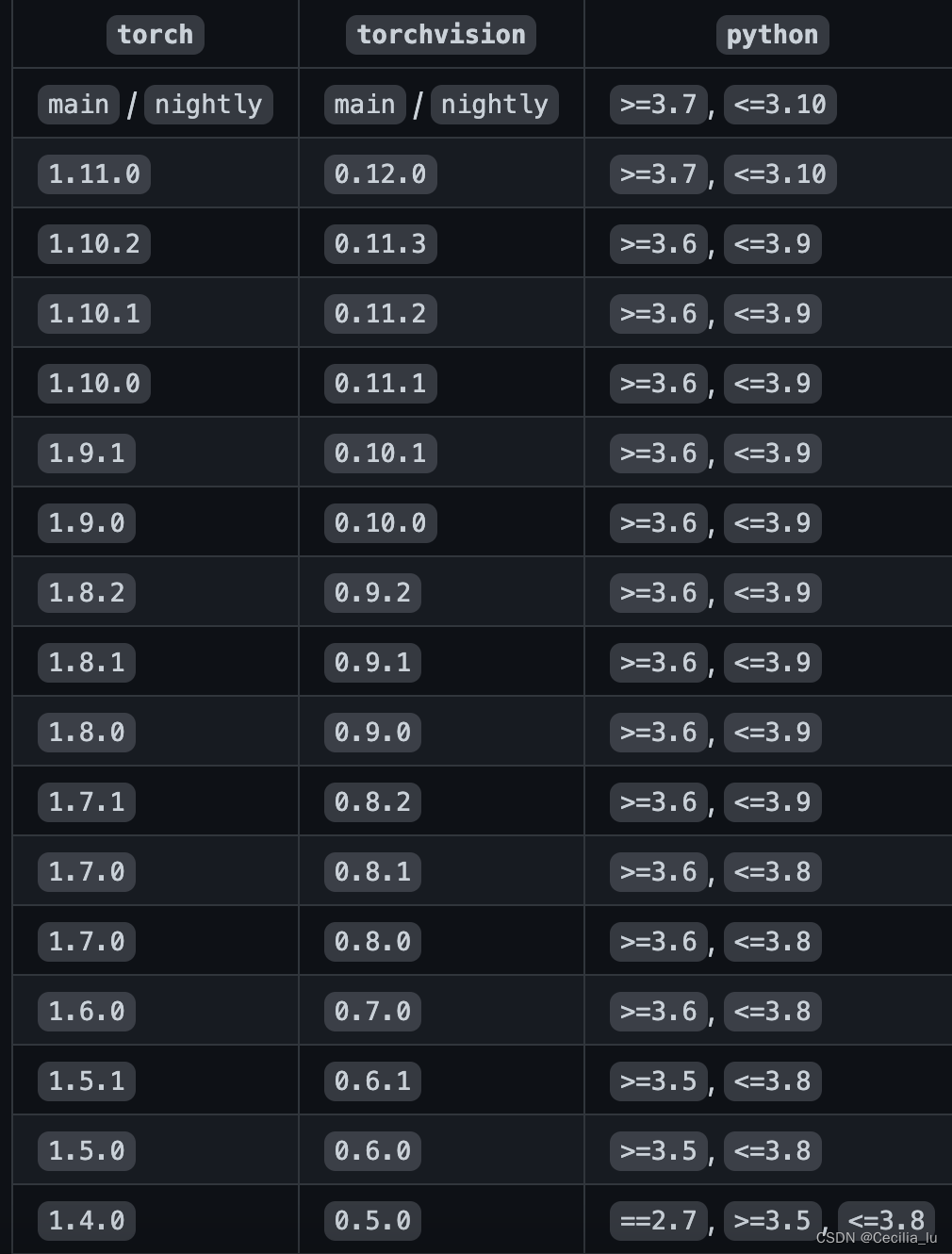
我的cuda版本是10.1版本的,所以我安装的版本如下图所示: 注意:还需要安装一下
注意:还需要安装一下
mmcv
,
mmcv
根据自己的
cuda
版本和
torch
版本进行选择,github上专门的repo下有说明,
mmcv
和
mmcv-full
只需要安装一个即可,
mmcv-full
是比较全面的我安装的是
mmcv-full
,详细的说明见mmcvrepo
根据repo中的这个表格选择安装的命令即可。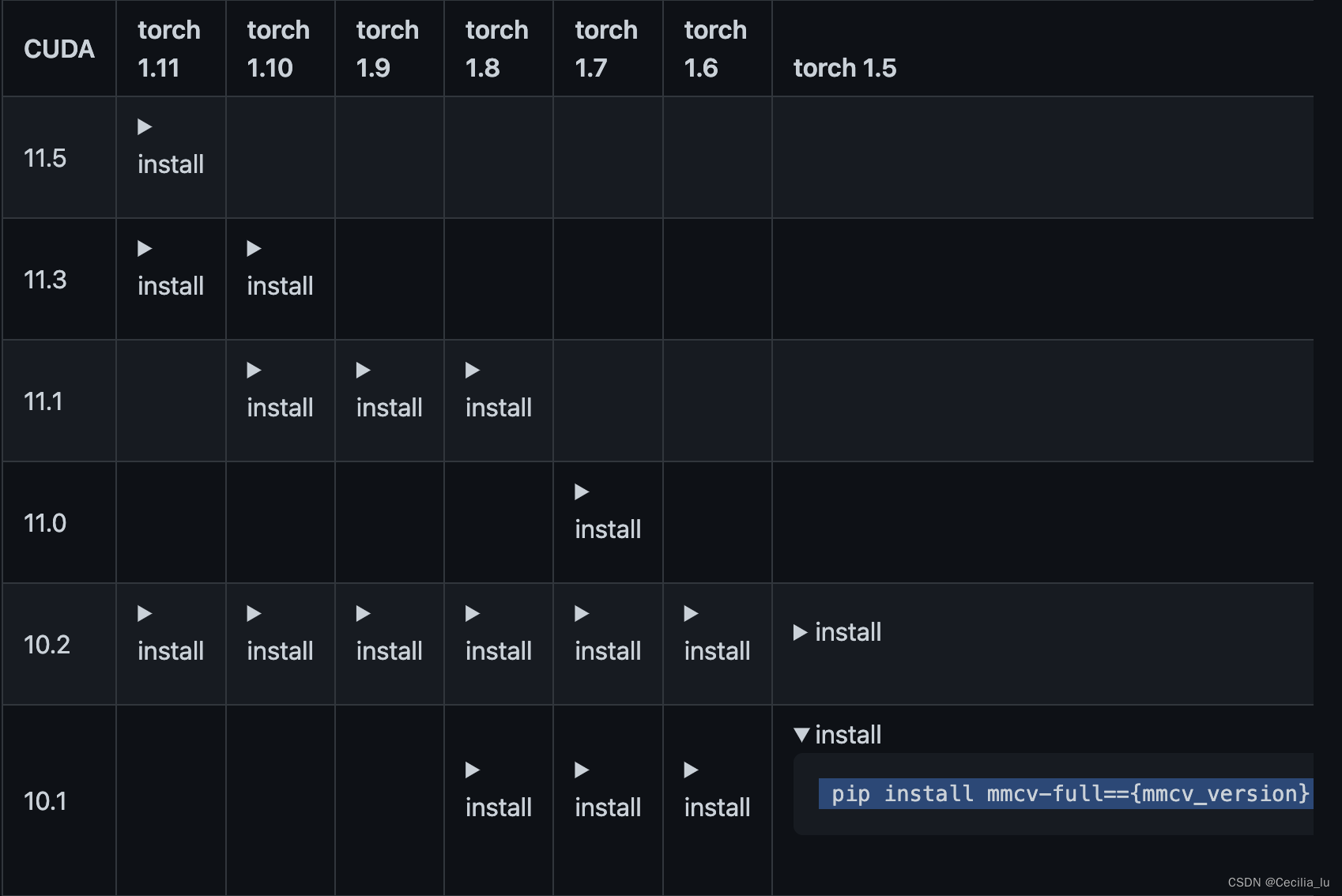
完成上述安装应该基本重要的都差不多了,如果跑的过程中提示没有某个模块的话再另行安装。
3.使用pascolvoc公开数据集跑mmsegmentation
【1】下载pascolvoc公开数据集
数据集下载镜像网站,这个是我找到的比较靠谱的镜像网站,我用的macbook_pro,下载了一个迅雷,用迅雷下载真的很快数据集有1.9G,迅雷下载可以有3M/s。
因为下载的是公开数据集,mmsegmentation是直接支持这种数据格式的,打开数据的话大概长这样,不用去做额外的操作,直接解压好后就是这样就OK了。
在
mmsegmentation-master
下面创建名字为
data
的文件夹,将上面下载的解压后的数据文件夹直接复制到
data
下面,这样数据就准备好了。
【2】配置自己训练的config
为了不打乱原repo的config, 建议直接创建一个自己要训练模型的config文件夹,我在
mmsegmentation-master
文件夹下创建了一个
my_model
的文件夹,这次主要是想实验deeplabv3+,所以在
my_model
下面又创建了一个名为
deeplabv3plus
的文件夹,整体结构如下:
所有的实验训练的config文件全部放在
mmsegmentation-master/my_model/deeplabv3plus
下面,当然你的config放在其他地方也无所谓,训练的时候配置文件的路径选择好就可以了,我这是为了区分自己的和原来的才这样操作。
config文件总共包括5个主要的:
1.选择训练config
根据自己想训练的网络在
mmsegmentation-master/configs
目录下选择自己想要选取的网络模型及输入尺寸,迭代次数等选择一个config文件,例如:我想训练deeplabv3plus的pascol公开数据集所以我选择的是:
deeplabv3plus_r50-d8_512x512_20k_voc12aug.py
文件,将这个选择好的文件放在自己创建好的
mmsegmentation-master/my_model/deeplabv3plus
文件夹下。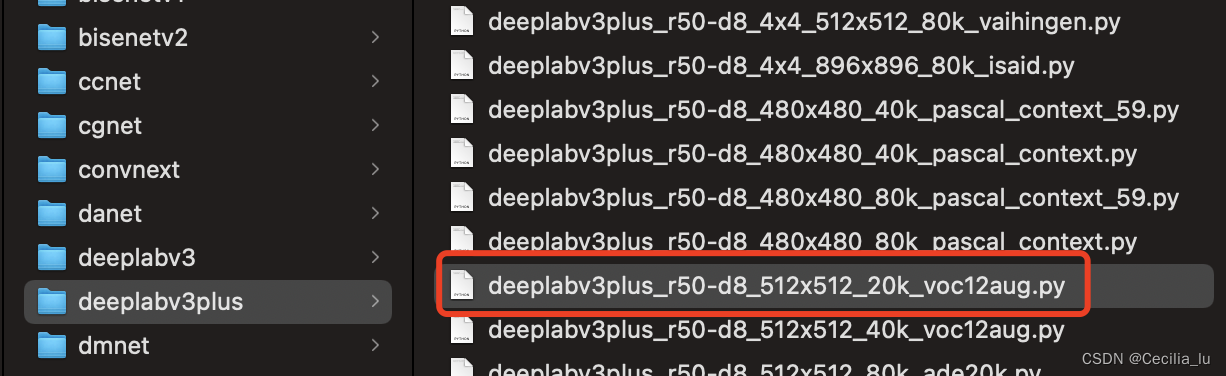
我们选择好的config里面的内容是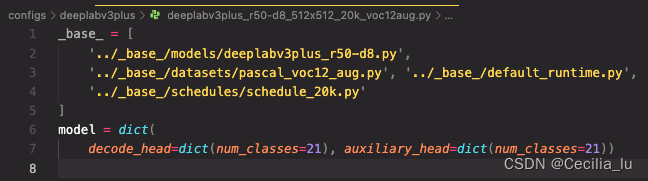
2.选择网络模型config
根据第一步选择好的config, 我们把模型config拿过来,复制
mmsegmentation-master/configs/_base_/models/deeplabv3plus_r50-d8.py
放在自己创建好的
mmsegmentation-master/my_model/deeplabv3plus
文件夹下.
3.选择数据config
此处注意⚠️:因为我们下载的是voc12数据集没有进行增强,所以数据config选择pascal_voc12.py
根据第一步选择好的config, 我们把数据config拿过来,复制
mmsegmentation-master/configs/_base_/datasets/pascal_voc12.py
放在自己创建好的
mmsegmentation-master/my_model/deeplabv3plus
文件夹下.
4.选择迭代进程config
根据第一步选择好的config, 我们把数据config拿过来,复制
mmsegmentation-master/configs/_base_/schedules/schedule_20k.py
放在自己创建好的
mmsegmentation-master/my_model/deeplabv3plus
文件夹下.
5.选择default_run_time
根据第一步选择好的config, 我们把数据config拿过来,复制
mmsegmentation-master/configs/_base_/default_runtime.py
放在自己创建好的
mmsegmentation-master/my_model/deeplabv3plus
文件夹下.
完成上述5步,config的选择基本完成最后我们的文件夹下应该是这样子。实际上你要用什么根据自己要训练的网络和迭代次数等去按照步骤选取就可以了。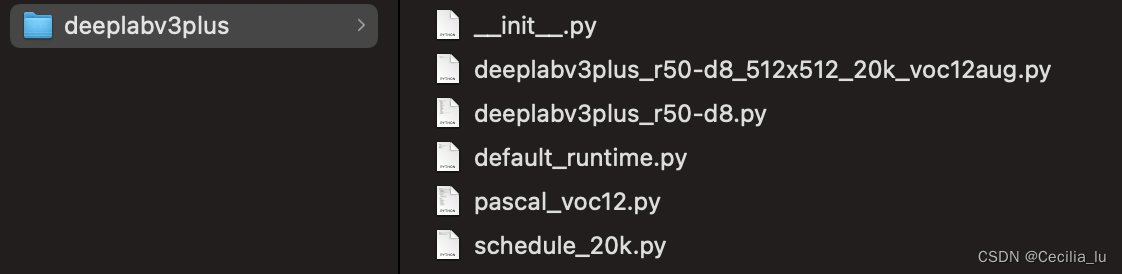
【3】按照需求修改自己训练的config
因为文件的位置变了,所以我们按照自己的需要可以去修改config了。
1.修改
deeplabv3plus_r50-d8_512x512_20k_voc12aug.py
修改后: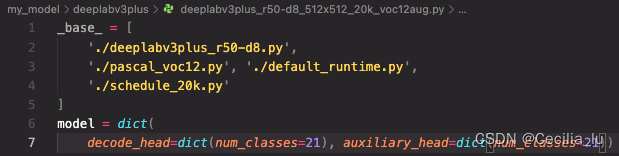
2.修改
pascal_voc12.py
后:
主要修改数据集的地址,我这里填写了绝对地址的,这样保证不会错
3.修改
schedule_20k.py
看自己的需求,原始的是下面我框起来的内容最大迭代次数,以及模型保存的间隔,评估的间隔,根据自己的需求改就OK了。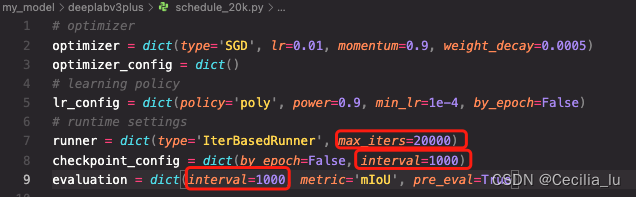
【4】开始训练
如果为了方便直接在
mmsegmentation-master/tools/train.py
里面改自己要传的内容
我直接改了下面这两个,当然你也可以进行外部穿参数
其中config是我们选择的第一个py文件的路径
work_dir是我们训练的模型及log的保存路径
修改完成后直接在终端cd 进
mmsegmentation-master
文件夹,
然后执行
python tools/train.py
即可进行模型训练了,如果你遇到终端跑报没有mmseg的modeule的问题可以在train.py中加上:
import sys
sys.path.append('xxx/xxx/mmsegmentation-master')#你的代码文件夹的绝对路径即可
【5】模型进行图片预测
完成训练后可以进行图片预测了,在我们训练所填的work_dir目录下应该会有若干.pth结尾的模型。
修改
mmsegmentation-master/demo/image_demo.py
(1)要预测的图片的路径
(2)训练时候的config文件的路径
(3)模型文件路径
修改完成后执行
python demo/image_demo.py
就可以看到图片了。如果是在服务器上保存图片需要你自己改改代码了。
注意⚠️:另外如果你是在cpu上进行图片预测的话,要把
deeplabv3plus_r50-d8.py
里面的
SyncBN
改成
BN
才可以。
4.制作自己的数据集跑mmsegmentation
【1】数据标注
语义分割的标注通常是使用labelme进行标注,labelme安装
conda create -n labelme python=3.6
conda activate labelme
pip install pyqt
pip install pillow
pip install labelme
直接终端
labelme
即可打开labelme进行数据标注
标注好的数据通常是一个图片带一个标注的json结果
我这里有之前其他平台的标注数据需要转化成labelme格式的方便检查标注,或者有其他用处,可以将其他格式的转化成labelme可以打开的标注数据
def gen_labelme_dict(self, sub_contour_dict, img_name, img_w, img_h, img_path):
labelme_dict ={'version':'4.2.10',
'flags':{},
'shapes':[],
'imagePath':img_name,
'imageData':'',
'imageHeight':img_h,
'imageWidth':img_w
}
shapes =[]for label, sub_cnt_list in sub_contour_dict.items():
forsub_cntin sub_cnt_list:
label_dict = defaultdict()
label_dict['label']= label_dict.get(label, label)
points = sub_cnt.reshape(-1, 2).tolist()
label_dict['points']= points
label_dict['group_id']= None
label_dict['shape_type']='polygon'
label_dict['flags']={}
with open(img_path, 'rb') as binary_file:
binary_file_data = binary_file.read()
base64_encoded_data = base64.b64encode(binary_file_data)
base64_message = base64_encoded_data.decode('utf-8')
labelme_dict['imageData']= base64_message
shapes.append(label_dict)
labelme_dict['shapes']= shapes
return labelme_dict
# 其中sub_contour_dict这张图片上标注的轮廓的集合大概类似于# {'类别1': [contour1, contour2,...], '类别2': [contour1, contour2,...]...,# contour1 的格式是np.array,shape是[-1,1,2]}
【2】自己的数据集mask制作
有了数据集文件夹下是若干图片和若干json文件,要进行训练的mask制作了
# -*- coding: utf-8 -*-import os
import json
import glob
import shutil
import tqdm
import cv2
import numpy as np
from PIL import Image
from sklearn.model_selection import train_test_split
np.random.seed(0)# 如果自己的数据集是中文或者英文像我这样用数字映射一下,特别提醒的是如果你没有背景类别也要在前面加上背景类别为0,自己的其他类别按照顺序往后映射
label_mapping ={'背景':0,
'客厅':1,
'餐厅':2,
'厨房':3,
'玄关':4,
'户内走道':5,
'卫生间干区':6}
def labelme2seg(json_files: list, output_path: str):
forjson_filein tqdm.tqdm(json_files, desc="transforming:"):
with open(json_file, encoding="utf-8") as f:
json_data = json.load(f)
img_path = json_file.replace('json', 'png')
img = cv2.imread(img_path)
img_h,img_w = img.shape[:2]
img_data = np.zeros((img_h, img_w), dtype=np.uint8)
labels_data = json_data["shapes"]
# 将目标物区域像素填充为对应ID号
for label_data in labels_data:
# 下面这行,你的label不是数字的话,是汉字或者其它,自己记得稍微改一下,映射成数字,从0开始
goods_id = int(label_mapping[label_data["label"]])
location = np.asarray(label_data["points"], dtype=np.int32)
cv2.fillPoly(img_data, [location], color=(goods_id, goods_id, goods_id))
res_img_name = os.path.basename(json_file).replace(".json", ".png")
cv2.imwrite(os.path.join(output_path, res_img_name), img_data)# res_img = Image.fromarray(img_data, mode="P")# res_img.save(os.path.join(output_path, res_img_name))return
def gen_train_val_data(labelme_path, save_path):
img_dir_train = os.path.join(save_path, "img_dir", "train")
img_dir_val = os.path.join(save_path, "img_dir", "val")
img_dir_test = os.path.join(save_path, "img_dir", "test")
ann_dit_train = os.path.join(save_path, "ann_dir", "train")
ann_dir_val = os.path.join(save_path, "ann_dir", "val")
ann_dir_test = os.path.join(save_path, "ann_dir", "test")if not os.path.exists(img_dir_train):
os.makedirs(img_dir_train)if not os.path.exists(img_dir_val):
os.makedirs(img_dir_val)if not os.path.exists(img_dir_test):
os.makedirs(img_dir_test)if not os.path.exists(ann_dit_train):
os.makedirs(ann_dit_train)if not os.path.exists(ann_dir_val):
os.makedirs(ann_dir_val)if not os.path.exists(ann_dir_test):
os.makedirs(ann_dir_test)
json_list_path = glob.glob(labelme_path + "/*.json")
train_path, test_val_path = train_test_split(json_list_path, test_size=0.2)
test_path, val_path = train_test_split(test_val_path, test_size=0.2)# 制作mask:
labelme2seg(train_path, ann_dit_train)
labelme2seg(val_path, ann_dir_val)
labelme2seg(test_path, ann_dir_test)# 图复制进对应位置forfilein tqdm.tqdm(train_path, desc="copy train_img"):
shutil.copy(file.replace(".json", ".png"), img_dir_train)forfilein tqdm.tqdm(val_path, desc="copy val_img"):
shutil.copy(file.replace(".json", ".png"), img_dir_val)forfilein tqdm.tqdm(test_path, desc="copy test_img"):
shutil.copy(file.replace(".json", ".png"), img_dir_test)if __name__ =='__main__':
labelme_path = r"/Users/cecilia/Desktop/new_data"
save_path = r"/Users/cecilia/Desktop/my_dataset"
gen_train_val_data(labelme_path, save_path)
执行完上述代码后会在自己save_path下生成对应的标注mask文件和训练的图片文件,可以根据自己的训练比例验证集比例进行修改划分比例。
将生成的数据文件夹命名为my_dataset包含如下内容,放在
mmsegmatation-master
下即可:
【3】配置mydataset
配置适合自己数据集的dataset文件
在mmseg/datasets新建一个文件
my_dataset.py
仿造其它的数据集写下如下内容:
from .builder import DATASETS
from .custom import CustomDataset
@DATASETS.register_module()
class MyDataset(CustomDataset):
# 写你实际的类别名就好了,跟生成mask是映射的数字顺序一致即可,有背景不需要改没有背景记得与生成mask时一样一定要在第一个加上background
CLASSES =('背景', '客厅', '餐厅', '厨房', '玄关', '户内走道', '卫生间干区')# 这个数量与上面个数对应就好了,只是最后的预测每个类别对应的mask颜色
PALETTE =[[0, 0 , 0], [215, 0 , 255], [255, 0, 0], [0, 255, 0], [0, 0, 255],
[0, 215, 255], [215, 255, 0]]
def __init__(self, **kwargs):
super(MyDataset, self).__init__(
**kwargs
)
然后在
mmseg/datasets/__init__.py
中把自己的数据集添加进去(主要是添加以下两行):
from .my_dataset import MyDataset
# 在 __all__中添加自己的类名
__all__ =['......', 'LoveDADataset', 'MyDataset'# 最后添加这个]
【4】配置自己训练config
按照上述讲的
3.使用pascolvoc公开数据集跑mmsegmentation
下面的【2】配置自己训练的config配置自己的config就可以了,注意这里我们使用了自己的数据集格式,所以要在
mmsegmentation-master/my_model/deeplabv3plus
下创建一个my_datasets.py用这个代替pascal_voc12.py
里面的内容为:
# dataset settings
dataset_type ='MyDataset'
data_root ='/Users/cecilia/Desktop/mmsegmentation-master/my_dataset'#填你生成的mask数据集的那个路径
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
crop_size =(512, 512)
train_pipeline =[
dict(type='LoadImageFromFile'),
dict(type='LoadAnnotations'),
dict(type='Resize', img_scale=(1024, 1400), ratio_range=(0.5, 2.0)), # img_scale根据自己的图片大小填写
dict(type='RandomCrop', crop_size=crop_size, cat_max_ratio=0.75),
dict(type='RandomFlip', prob=0.5),
dict(type='PhotoMetricDistortion'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size=crop_size, pad_val=0, seg_pad_val=255),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_semantic_seg']),
]
test_pipeline =[
dict(type='LoadImageFromFile'),
dict(type='MultiScaleFlipAug',
img_scale=(1024, 1400),
# img_ratios=[0.5, 0.75, 1.0, 1.25, 1.5, 1.75],flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])]
data = dict(samples_per_gpu=2,
workers_per_gpu=1,
train=dict(type='RepeatDataset',
times=40000,
dataset=dict(type=dataset_type,
data_root=data_root,
img_dir='img_dir/train',
ann_dir='ann_dir/train',
pipeline=train_pipeline)),
val=dict(type=dataset_type,
data_root=data_root,
img_dir='img_dir/val',
ann_dir='ann_dir/val',
pipeline=test_pipeline),
test=dict(type=dataset_type,
data_root=data_root,
img_dir='img_dir/test',
ann_dir='ann_dir/test',
pipeline=test_pipeline))
上述注释的地方修改成自己的就OK了,其他一般不需要修改
这个修改了以后注意这个训练的config里面的pascol_voc.py要改成my_datasets.py,另外类别数要改成我们自己的类别数量了,记住是自己的实际类别+背景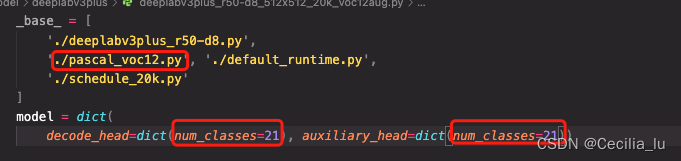
其他的几个文件,就根据自己的迭代数量和模型保存数量进行修改即可,模型选的不一样按照上面介绍的步骤选择自己的config就可以了。
【5】模型训练
在tools/train.py中设置好自己的config路径及work_dir路径或者外部传参
# 内部改好的话执行
python tools/train.py
# 外部传参数执行
python tools/train.py xxx/xxx/deeplabv3plus_r50-d8_512x512_20k_voc12aug.py
有一点需要注意的是,如果你的图片是jpg格式,mask是png格式,应该没问题,要是不是这两种格式的话,需要在mmseg/datasets/custom.py中修改你的图片的格式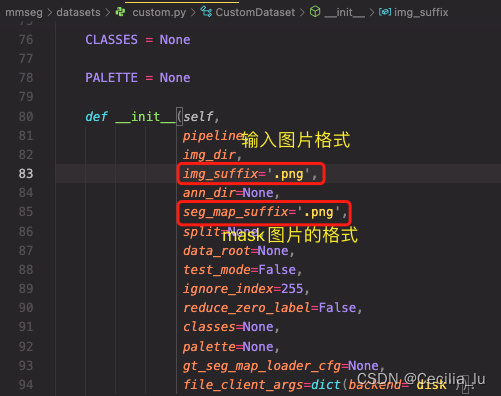
训练起来大概是这个输出: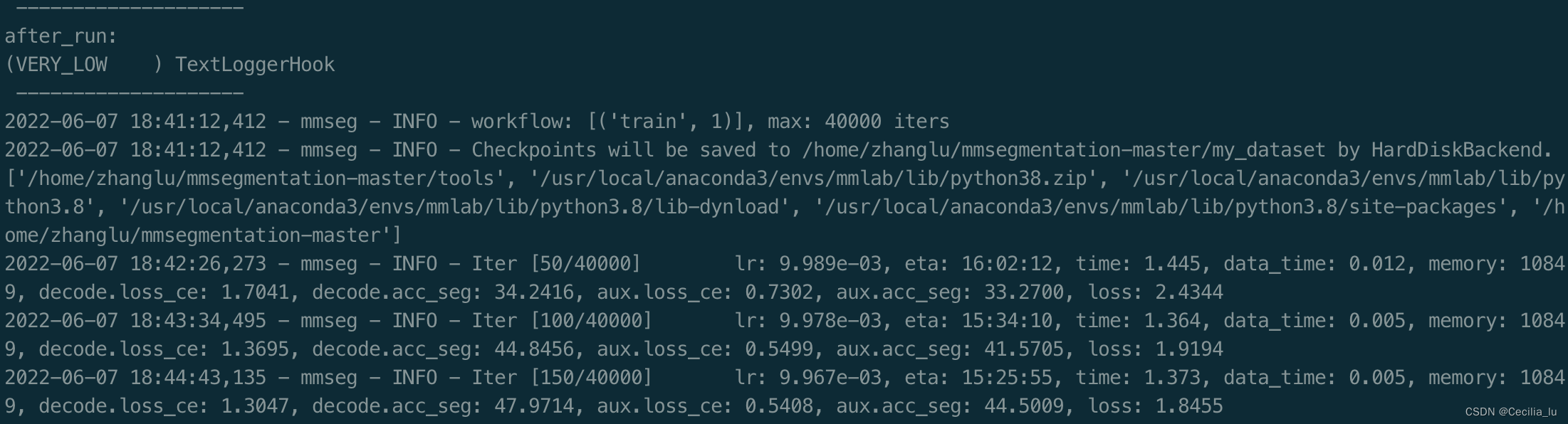
【6】模型预测
如果要进行图片的预测展示demo的效果的话需要修改
mmseg/core/evaluation/class_names.py
在这里面加
def mydata_classes():
return['背景','客厅', '餐厅', '厨房', '玄关', '户内走道', '卫生间干区']
def mydata_palette():
return[[0, 0 , 0],[215, 0 , 255], [255, 0, 0], [0, 255, 0], [0, 0, 255],
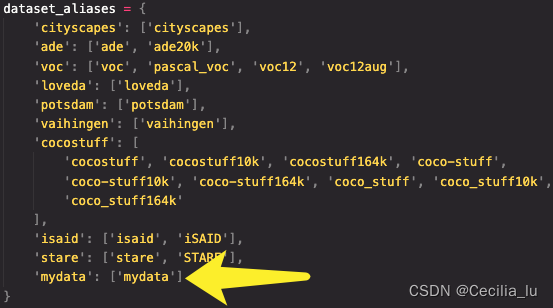
[0, 215, 255], [215, 255, 0]]#另外dataset_aliases = {}该字典中加上'mydata':['mydata']
修改demo/image_demo.py里面的图片路径,模型路径还有数据格式就OK,或者是你直接外部传参数。运行image_demo.py就可以图片展示了。
以上是mmsegmentation训练的一些内容,有问题的话还可在交流,应该是比较全面了,希望你能自己跑起来!!!
版权归原作者 Cecilia_lu 所有, 如有侵权,请联系我们删除。