
使用Selenium和Python抓取快手网页大量评论.py资源-CSDN文库https://download.csdn.net/download/m0_74972192/89580850?spm=1001.2014.3001.5503
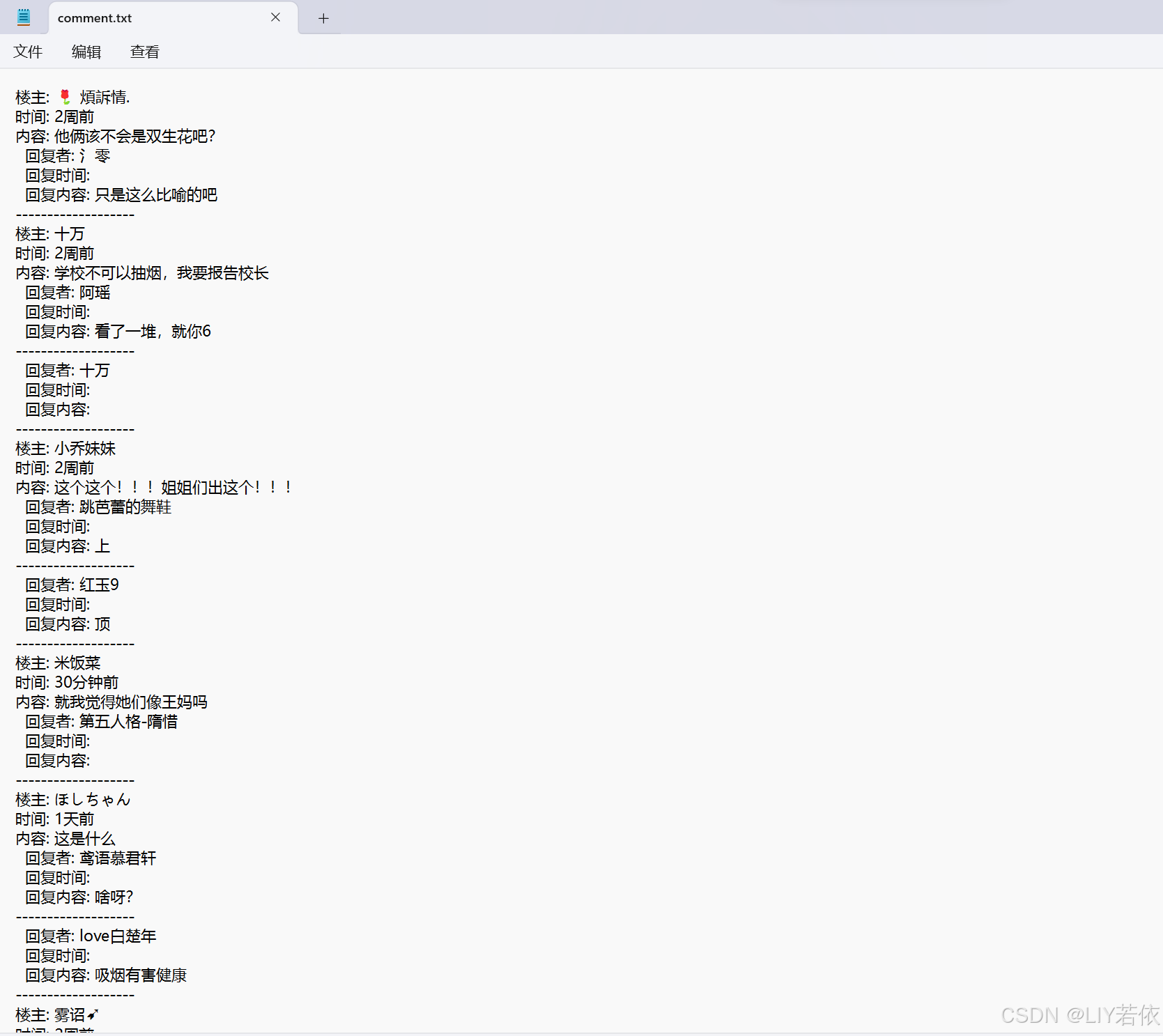
效果展示
通过运行批处理脚本,程序将自动打开目标网页,等待页面加载完成后,抓取所有评论项及其子评论,并将评论内容保存到一个文本文件中。最终效果是能够在文本文件中查看到所有抓取到的评论内容。这对于需要分析网页评论内容的用户来说,是一个非常实用的工具。

步骤解析
步骤一:设置WebDriver
首先,我们需要设置WebDriver来控制浏览器。这里使用了Chrome浏览器,并配置了调试地址。通过设置调试地址,我们可以在调试模式下运行浏览器,这样可以更方便地进行调试和测试。
步骤二:打开目标网页
使用WebDriver打开目标网页,并等待页面加载完成。我们使用了显式等待来确保页面中的评论项加载完成。显式等待是一种等待方式,它会在指定的时间内不断检查某个条件是否满足,如果条件满足则继续执行,否则等待直到超时。
步骤三:获取评论项
通过CSS选择器获取所有的评论项,并遍历每个评论项,提取评论的作者、时间和内容。CSS选择器是一种用于选择HTML元素的语法,通过CSS选择器我们可以方便地定位到页面中的特定元素。
步骤四:保存评论内容
将提取到的评论内容保存到一个文本文件中,以便后续查看和分析。我们使用Python的文件操作功能,将评论内容逐行写入到文本文件中。
步骤五:关闭浏览器
在完成所有操作后,关闭浏览器以释放资源。使用
driver.quit
方法可以关闭浏览器并结束WebDriver会话。
代码解析
- 设置WebDriver:- 导入所需的库,包括
webdriver、By、WebDriverWait、expected_conditions和Options。- 创建一个Options对象,用于配置Chrome浏览器的选项。- 使用webdriver.Chrome创建一个Chrome浏览器实例,并传入配置好的选项。- 设置调试地址为127.0.0.1:9222,这样可以在调试模式下运行浏览器。 - 打开目标网页:- 使用
driver.get方法打开目标网页,这里使用的是https://www.kuaishou.com/new-reco。- 使用WebDriverWait等待页面加载完成,直到页面中的评论项(通过CSS选择器.comment-item定位)出现。- 使用time.sleep(10)等待10秒,以确保页面完全加载。 - 获取评论项:- 使用
driver.find_elements方法通过CSS选择器获取所有的评论项。- 遍历每个评论项,提取评论的作者、时间和内容。作者通过CSS选择器.author-name定位,时间通过CSS选择器.comment-item-time定位,内容通过CSS选择器.comment-item-content定位。- 将提取到的评论内容打印到控制台,并写入到一个名为comment.txt的文本文件中。 - 保存评论内容:- 打开一个名为
comment.txt的文本文件,以写入模式('w')打开,并设置编码为utf-8。- 将提取到的评论内容逐行写入到文本文件中,包括作者、时间和内容。- 对于每个评论项,还会获取其所有的子评论项,并提取子评论的作者、时间和内容。子评论的作者通过CSS选择器.reply-name定位,时间通过CSS选择器.comment-sub-item-time定位,内容通过CSS选择器.comment-item-content定位。- 将子评论内容也写入到文本文件中,并在每个评论项之间添加分隔线。 - 关闭浏览器:- 使用
driver.quit方法关闭浏览器并结束WebDriver会话,以释放资源。
结论
通过以上步骤,我们成功地使用Selenium和Python创建了一个简单的网页评论抓取工具。这个工具可以自动打开目标网页,抓取所有评论项及其子评论,并将评论内容保存到一个文本文件中。虽然这个工具非常基础,但它展示了Selenium在网页自动化任务中的强大功能。希望这篇文章对你有所帮助!
版权归原作者 LIY若依 所有, 如有侵权,请联系我们删除。