
写在前面的话:
课程视频地址:
https://www.bilibili.com/video/BV1C34y1d74a完整的笔记可在我的公众号:manor的大数据之路 回复:"高级"获取~
Mysql高级01
MySQL高级课程简介
序号010203041基本硬件知识体系结构应用优化MySQL 常用工具2索引存储引擎查询缓存优化MySQL 日志3视图优化SQL步骤内存管理及优化MySQL 主从复制4存储过程和函数索引使用MySQL锁问题5触发器SQL优化常用SQL技巧
1.基本硬件知识(了解)
1.1计算机工作原理

1.中央处理器(英文Central Processing Unit,CPU)是一台计算机的运算核心和控制核心。CPU、内部存储器和输入/输出设备是电子计算机三大核心部件。其功能主要是解释计算机指令以及处理计算机软 件中的数据。
CPU核心组件:
1.算术逻辑单元(Arithmetic&logical Unit)是中 央处理器(CPU)的执行单元,是所有中央处理器的核
心组成部分,由"And Gate"(与门) 和"Or Gate"(或门)构成的算术逻辑单元,主要功能是进行二位元的算术运算,如加减乘(不包括整数除法)。
2.PC:负责储存内存地址,该地址指向下一条即将执行的指令,每解释执行完一条指令,pc寄存器的值 就会自动被更新为下一条指令的地址。
3.寄存器(Register)是CPU内部的元件,所以在寄存器之间的数据传送非常快。 用途:1.可将寄存器内的数据执行算术及逻辑运算。
2.存于寄存器内的地址可用来指向内存的某个位置,即寻址。
3.可以用来读写数据到电脑的周边设备。4.Cache:缓存
2.内存(Memory)是计算机的重要部件之一,也称内存储器和主 存储器,它用于暂时存放CPU中的运算数
据,与硬盘等外 部存储器交换的数据。它是外存与C PU进行沟通的桥梁,计算机中所有程序的运行都在
内存中进行,内存性能的强弱影响计算机整体发挥的水平。只要计算机开始运行,操作系统就会把需要 运算的数据从内存调到CPU中进行运算,当运算完成,CPU将结果传送出来。
1.2磁盘的一些概念
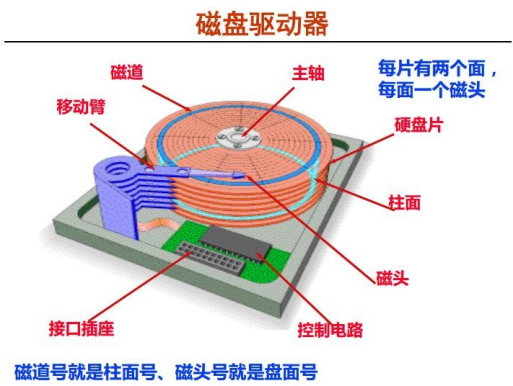
(1)盘片、片面 和 磁头
硬盘中一般会有多个盘片组成,每个盘片包含两个面,每个盘面都对应地有一个读/写磁头。受到硬盘整 体体积和生产成本的限制,盘片数量都受到限制,一般都在5片以内。盘片的编号自下向上从0开始,如 最下边的盘片有0面和1面,再上一个盘片就编号为2面和3面。
如下图:

(2)扇区 和 磁道
下图显示的是一个盘面,盘面中一圈圈灰色同心圆为一条条磁道,从圆心向外画直线,可以将磁道划分 为若干个弧段,每个磁道上一个弧段被称之为一个扇区(图践绿色部分)。扇区是磁盘的最小组成单 元,通常是512字节。(由于不断提高磁盘的大小,部分厂商设定每个扇区的大小是4096字节)
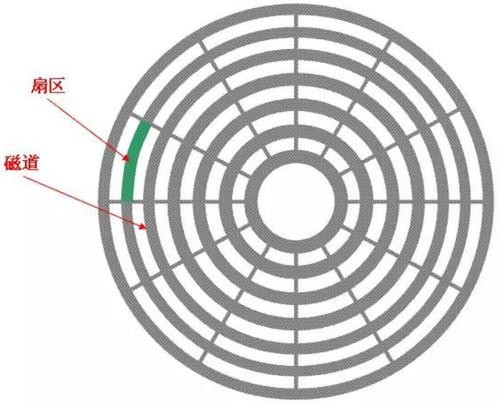
通过磁头和磁道的接触,然后我们进行数据的读写
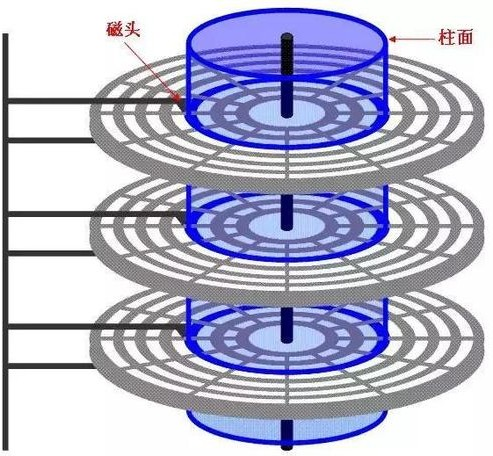
(3)磁头 和 柱面
硬盘通常由重叠的一组盘片构成,每个盘面都被划分为数目相等的磁道,并从外缘的“0”开始编号,具有 相同编号的磁道形成一个圆柱,称之为磁盘的柱面。磁盘的柱面数与一个盘面上的磁道数是相等的。由 于每个盘面都有自己的磁头,因此,盘面数等于总的磁头数。 如下图
3、磁盘容量计算
存储容量 = 磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数图3中磁盘是一个 3个圆盘6个磁头,7
个柱面(每个盘片7个磁道) 的磁盘,上图中每条磁道有12个扇区,所以此磁盘的容量为:存储容量 6
- 7 * 12 * 512 = 258048 每个磁道的扇区数一样是说的老的硬盘,外圈的密度小,内圈的密度大,每圈可存储的数据量是一样 的。新的硬盘数据的密度都一致,这样磁道的周长越长,扇区就越多,存储的数据量就越大。 4、磁盘读取响应时间 1.寻道时间:磁头从开始移动到数据所在磁道所需要的时间,寻道时间越短,I/O操作越快,目前磁 盘的平均寻道时间一般在3-15ms,一般都在10ms左右。 2.旋转延迟:盘片旋转将请求数据所在扇区移至读写磁头下方所需要的时间,旋转延迟取决于磁盘转 速。普通硬盘一般都是7200rpm,慢的5400rpm。 3.数据传输时间:完成传输所请求的数据所需要的时间。 小结一下:从上面的指标来看、其实最重要的、或者说、我们最关心的应该只有两个:寻道时间;旋转 延迟 读写一次磁盘信息所需的时间可分解为:寻道时间、延迟时间、传输时间。为提高磁盘传输效率,软件 应着重考虑减少寻道时间和延迟时间。(类似于CPU缓存行,把随机读改成顺序读写) 5、块/簇 磁盘块/簇(虚拟出来的)。 块是操作系统中最小的逻辑存储单位。操作系统与磁盘打交道的最小单位是磁盘块。每个块可以包括2、4、8、16、32、64…2的n次方个扇区。 为什么存在磁盘块?
读取方便:由于扇区的数量比较小,数目众多在寻址时比较困难,所以操作系统就将相邻的扇区组合在 一起,形成一个块,再对块进行整体的操作。分离对底层的依赖:操作系统忽略对底层物理存储结构的 设计。通过虚拟出来磁盘块的概念,在系统中认为块是最小的单位。(就是类似于班级,小组等)
6、page
操作系统经常与内存和硬盘这两种存储设备进行通信,类似于“块”的概念,都需要一种虚拟的基本单
位。所以,与内存操作,是虚拟一个页的概念来作为最小单位。与硬盘打交道,就是以块为最小单位。
7、扇区、块/簇、page的关系
1.扇区: 硬盘的最小读写单元
2.块/簇: 是操作系统针对硬盘读写的最小单元
3.page: 是内存与操作系统之间操作的最小单元。
扇区 <= 块/簇 <= page
8、计算机读取数据流程
当需要从磁盘读取数据时,系统会将数据地址传给磁盘,即确定要读的数据在哪个磁道,哪个扇区。为 了读取这个扇区的数据,需要将磁头放到这个扇区上方,为了实现这一点,磁头需要移动对准相应磁 道,这个过程叫做 寻道 ,所耗费时间叫做 寻道时间 ,然后磁盘旋转将目标扇区旋转到磁头下,这个过程耗费的时间叫做旋转时间。
1.3局部性原理,磁盘预读,CPU缓存行,磁盘IO
1、 由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的十万分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格 按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长 度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。程序运行期间所需要的数据通常比较集中。 由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序 来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存 和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此 时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然 后异常返回,程序继续运行。
下图是计算机硬件延迟的对比图,供大家参考:

2、磁盘IO的问题
mysql的数据一般以文件形式存储在磁盘上,检索需要磁盘I/O操作。与主存不同,磁盘I/O存在机械运 动耗费,因此磁盘I/O的时间消耗是巨大的。
2.索引
2.1索引概述
MySQL官方对索引的定义为:索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据 之外,数据库系统还维护者满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数 据, 这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。如下面的示意图所示 :

左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘 上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点 分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应 数据。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。 索引是数据库中用来提高性能的最常用的工具。
2.2索引优势劣势
优势
1)类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
2)通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。劣势
1)实际上索引也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要 占用空间的。
2)虽然索引大大提高了查询效率,同时却也降低更新表的速度,如对表进行INSERT、UPDATE、
DELETE。因为更新表时,MySQL 不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
2.3索引结构
索引是在MySQL的存储引擎层中实现的,而不是在服务器层实现的。所以每种存储引擎的索引都不一定 完全相同,也不是所有的存储引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引:
BTREE 索引 : 最常见的索引类型,大部分索引都支持 B 树索引。
HASH 索引:只有Memory引擎支持 , 使用场景简单 。
R-tree 索引(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少,不做特别介绍。
Full-text (全文索引) :全文索引也是MyISAM的一个特殊索引类型,主要用于全文索引,
InnoDB从Mysql5.6版本开始支持全文索引。MySAM、InnoDB、Memory三种存储引擎对各种索引类型的支持
索引InnoDB引擎MyISAM引擎Memory引擎BTREE索引支持支持支持HASH 索引不支持不支持支持R-tree 索引不支持支持不支持Full-text5.6版本之后支持支持不支持
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的 索引。其中聚集索引、复合索引、前缀索引、唯一索引默认都是使用 B+tree 索引,统称为索引。
2.3.1索引数据结构的选型
从第一块内容中我们明白了磁盘是怎么存储文件的,而我们的mysql的数据文件又是存储在磁盘上的, 所以我们有必要去研究一下,mysql是怎么保障数据在磁盘上存储,效率还能比较高的原因。首先,在 数据库文件存储在磁盘时,为了提升查询效率,一定会选用合适的数据结构进行文件的存储。
接下来咱们探讨一下:
1、数组和链表
肯定不能选,这种最基本的数据结构,各自的劣势太明显。数据库对查询要求是最很高的所以链表这种 查询必须全表遍历的基本数据结构是不能用的。数组这种结构在添加数据时成本太大,插入数据时太过 于频繁。
2、HASH
类似与咱们的hashmap,这样行吗? 速度快,但是只要是hash就会产生无序的问题,所以不常用但也有。
3、树
看来看去也就是树这种结构比较合理了。二叉查找树可以吗?在查找一个数据时,二叉树是读取根节 点,小则从左找,大则从右找,每次读取一个数据。没有办法合理的利用局部性原理与磁盘预读,IO次 数太多太多,其次就是树的层次还是偏高,所以不适合。那每次读多个数据,每一个节点存多个数据的 结构就只有B-树和B+树了;
接下来就讨论这两种数据结构的选型。
4、B-树
B-树,这里的 B 表示 balance( 平衡的意思),B-树是一种多路自平衡的搜索树
它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。下图是 B-树的简化图.
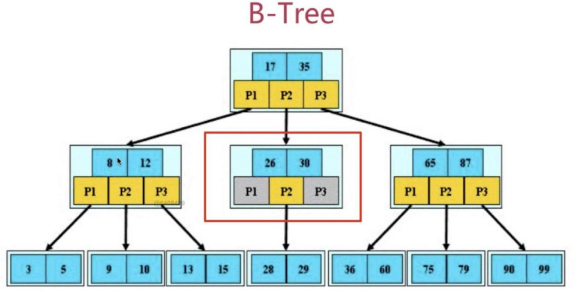
B-树有如下特点:
1.所有键值分布在整颗树中;
2.任何一个关键字出现且只出现在一个结点中;
3.搜索有可能在非叶子结点结束;
4.在关键字全集内做一次查找,性能逼近二分查找
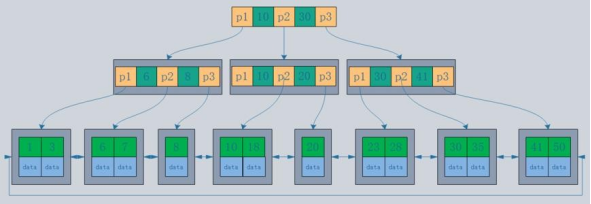
5、B+ 树
mysql默认是主键,如果没有主键则使用唯一索引,唯一索引也没有则使用rowid,行号。所以一定要建 立主键。
B+树是B-树的变体,也是一种多路搜索树, 它与 B- 树的不同之处在于:
1.所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data)
2.为所有叶子结点增加了一个链指针
简化 B+树 如下图
6、为什么使用B-/B+ Tree
红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。
MySQL 是基于磁盘的数据库系统,索引往往以索引文件的形式存储的磁盘上,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
MySQL(默认使用InnoDB引擎),将记录按照页的方式进行管理,每页大小默认为16K(这个值可以修 改).linux 默认页大小为4K
7、为什么使用 B+树
1.B+树更适合外部存储,由于内节点无 data 域,一个结点可以存储更多的内结点,每个节点能索引的范围更大更精确,也意味着 B+树单次磁盘IO的信息量大于B-树,I/O效率更高。
2.Mysql是一种关系型数据库,区间访问是常见的一种情况,B+树叶节点增加的链指针,加强了区间访 问性,可使用在范围区间查询等,而B-树每个节点 key 和 data 在一起,则无法区间查找。
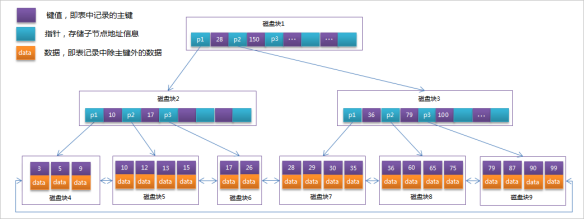
2.3.2MySQL中的B+Tree
MySql索引数据结构对经典的B+Tree进行了优化。在原B+Tree的基础上,增加一个指向相邻叶子节点的 链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
MySQL中的 B+Tree 索引结构示意图:
2.4索引分类
1)单值索引 :即一个索引只包含单个列,一个表可以有多个单列索引
2)唯一索引 :索引列的值必须唯一,但允许有空值
3)复合索引 :即一个索引包含多个列
2.5索引语法
索引在创建表的时候,可以同时创建, 也可以随时增加新的索引。准备环境:
create database demo_01 default charset=utf8mb4;
use demo_01;
CREATE TABLE `city` (
`city_id` int(11) NOT NULL AUTO_INCREMENT,
`city_name` varchar(50) NOT NULL,
`country_id` int(11) NOT NULL, PRIMARY KEY (`city_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `country` (
`country_id` int(11) NOT NULL AUTO_INCREMENT,
`country_name` varchar(100) NOT NULL, PRIMARY KEY (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `city` (`city_id`, `city_name`, `country_id`) values(1,'西安',1);
insert into `city` (`city_id`, `city_name`, `country_id`) values(2,'NewYork',2); insert into `city` (`city_id`, `city_name`, `country_id`) values(3,'北京',1); insert into `city` (`city_id`, `city_name`, `country_id`) values(4,'上海',1);
insert into `country` (`country_id`, `country_name`) values(1,'China'); insert into `country` (`country_id`, `country_name`) values(2,'America'); insert into `country` (`country_id`, `country_name`) values(3,'Japan'); insert into `country` (`country_id`, `country_name`) values(4,'UK');
2.5.1创建索引
语法 :
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX index_name
[USING index_type]
ON tbl_name(index_col_name,...)
index_col_name : column_name[(length)][ASC | DESC]
示例 : 为city表中的city_name字段创建索引 ;

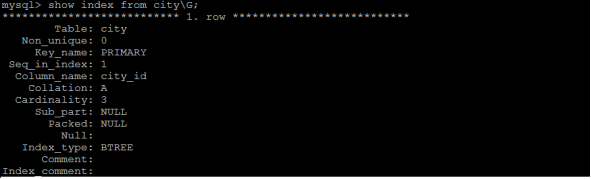
2.5.2查看索引
语法:
show index from table_name;
示例:查看city表中的索引信息;
版权归原作者 Maynor大数据 所有, 如有侵权,请联系我们删除。