
集群规划(辛苦我的小本本了,拖8台centos):
flink采用on yarn模式,机器资源有限,ck只装了单节点
域名IP安装的软件运行的进程zcx1192.168.220.128
hadoop
flink
kafka
NameNode
DFSZKFailoverController(zkfc)
JobManager
TaskManager
zcx2192.168.220.129
hadoop
flink
NameNode
DFSZKFailoverController(zkfc)
JobManager
TaskManager
zcx3192.168.220.130
hadoop
flink
ResourceManager
TaskManager
zcx4192.168.220.131
hadoop
zookeeper
kafka
DataNode
NodeManager
JournalNode
QuorumPeerMain
zcx5192.168.220.132
hadoop
zookeeper
kafka
DataNode
NodeManager
JournalNode
QuorumPeerMain
zcx6192.168.220.133
hadoop
zookeeper
kafka
DataNode
NodeManager
JournalNode
QuorumPeerMain
zcx7192.168.220.134hadoopResourceManagerck3192.168.220.142clickhoueclickhouse-server
flink主要代码
public class Kafka_To_Flink_To_Clickhouse {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
Properties properties=new Properties();
properties.setProperty("bootstrap.servers","zcx4:9092");
FlinkKafkaConsumer<String> stringFlinkKafkaConsumer = new FlinkKafkaConsumer<String>("zcx1",new SimpleStringSchema(),properties);
stringFlinkKafkaConsumer.setStartFromEarliest();
DataStreamSource<String> topic = env.addSource(stringFlinkKafkaConsumer);
SingleOutputStreamOperator<String> map = topic.map(new MapFunction<String, String>() {
@Override
public String map(String s) throws Exception {
return s;
}
});
tenv.registerDataStream("zcx1",map,"name");
Table result = tenv.sqlQuery("select name from zcx1");
DataStream<Zcx1> rowDataStream = tenv.toDataStream(result,Zcx1.class);
rowDataStream.print();
rowDataStream.addSink(new MyClickhouseUtil());
env.execute();
}
}
public class MyClickhouseUtil extends RichSinkFunction<Zcx1> {
Connection connection;
PreparedStatement preparedStatement;
@Override
public void invoke(Zcx1 value, Context context) throws Exception {
preparedStatement.setString(1,value.name);
// preparedStatement.setInt(2,value.num);
preparedStatement.execute();
}
@Override
public void open(Configuration parameters) throws Exception {
Class.forName("ru.yandex.clickhouse.ClickHouseDriver");
connection = DriverManager.getConnection("jdbc:clickhouse://192.168.220.142:8123/default","default","GsAdBi/O");
preparedStatement = connection.prepareStatement("insert into zcx1 values(?)");
}
@Override
public void close() throws Exception {
if(null!=connection){
connection.close();
}
if(null!=preparedStatement){
preparedStatement.close();
}
}
}
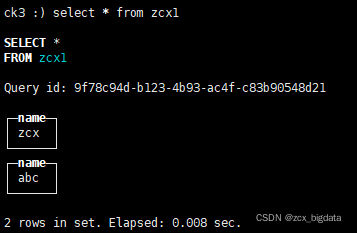
测试
kafka producer生产数据

实时写入clickhouse
本文转载自: https://blog.csdn.net/u011611051/article/details/122753723
版权归原作者 zcx_bigdata 所有, 如有侵权,请联系我们删除。
版权归原作者 zcx_bigdata 所有, 如有侵权,请联系我们删除。