
前文回顾:Hive和数据仓库
📚为什么会有Spark
MapReduce计算模式的缺陷
- 最初设计用于高吞吐量批处理数据,不擅长低延迟。
- 需要将数据存储到HDFS,迭代计算中的数据共享效率太低。
- 系统设计没有充分利用内存,很难实现高性能。
- MapReduce不表达复杂的计算问题,如图形计算、迭代计算。
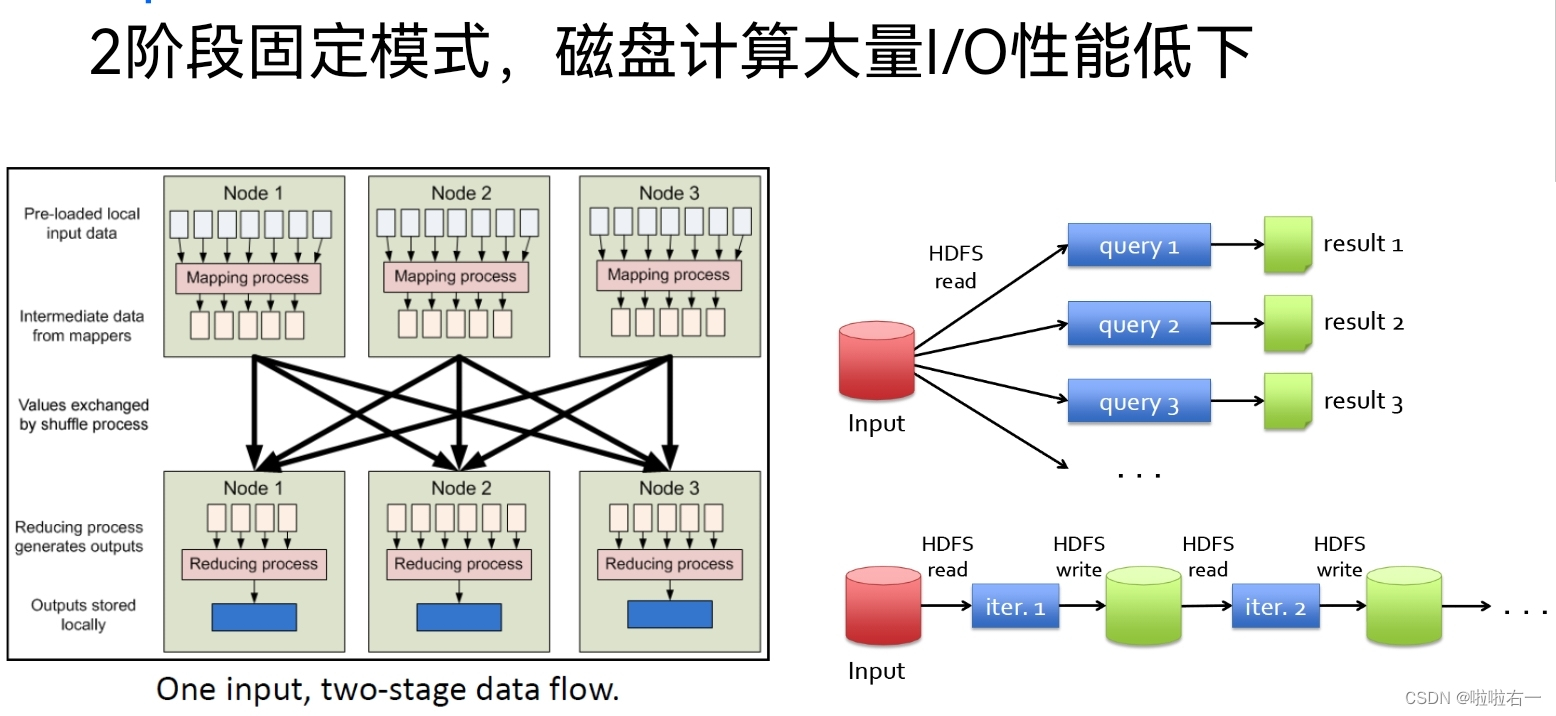
Spark基于内存计算思想提高计算性能
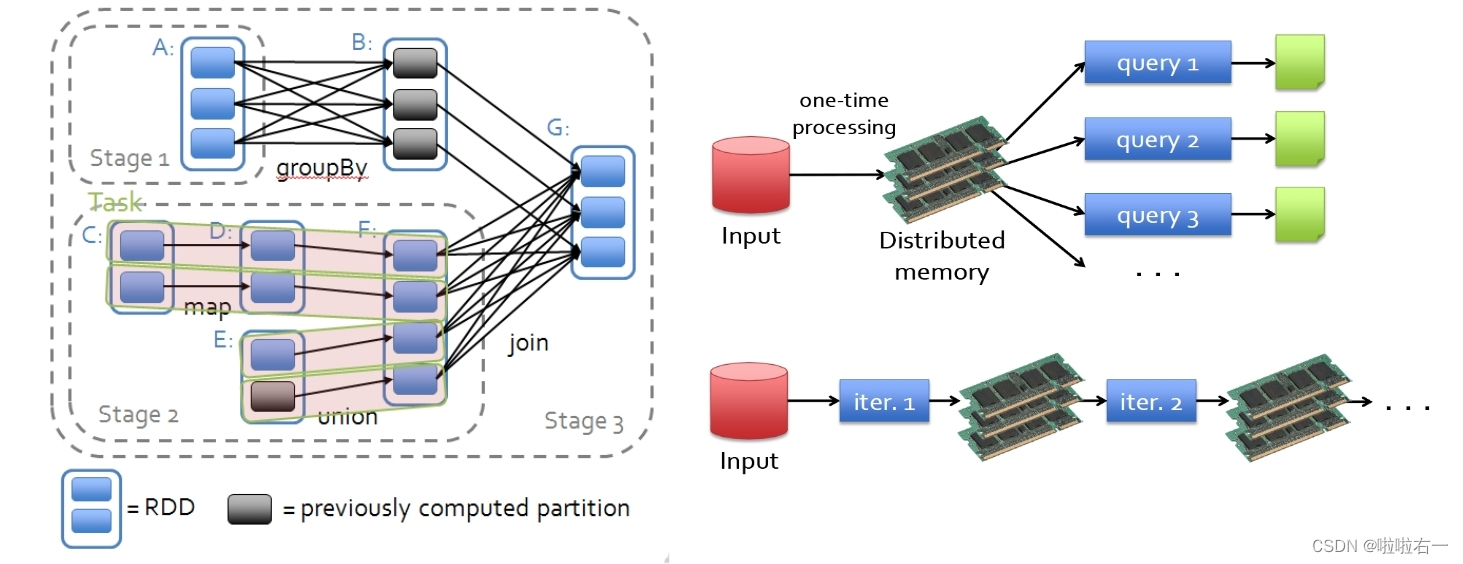
- Spark提出了一种基于内存的弹性分布式数据集(RDD),通过对RDD的一系列操作完成计算任务,可以大大提高性能。
- 同时一组RDD形成可执行的有向无环图DAG,构成灵活的计算流图。
- 覆盖多种计算模式。

📚Spark的基本架构和组件
🐇主要体系结构和组件

🐇Spark集群的基本结构
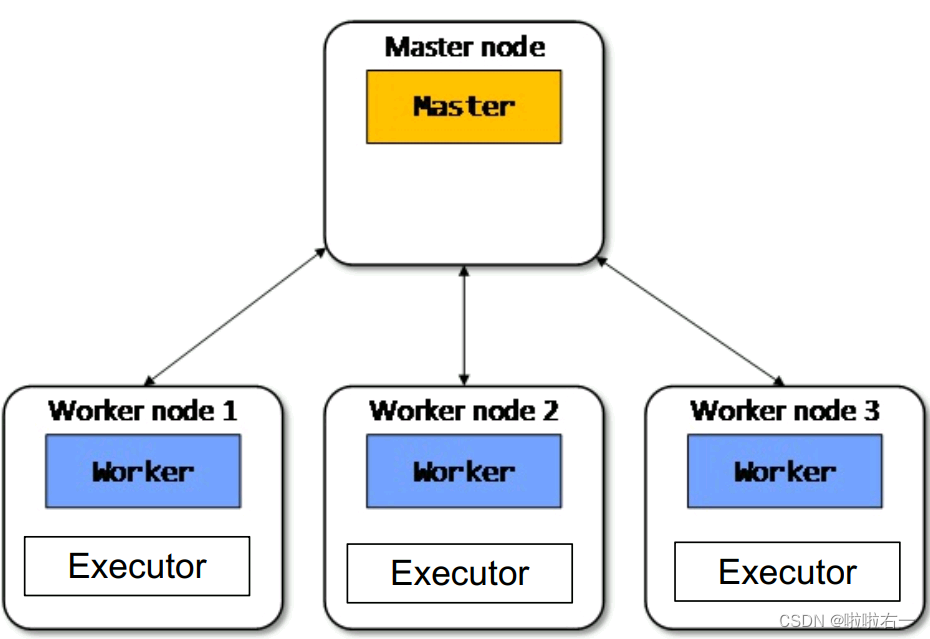
- Master node:集群部署时的概念,是整个集群的控制器,负责整个集群的正常运行,管理Worker node。
- Worker node:计算节点,接受主节点命令与进行状态汇报。
- Executors:每个Worker上有一个Executor,负责完成Task程序的部署。
- Spark集群部署后,需要从主从节点启动Master进程和Worker进程,对整个集群进行控制。
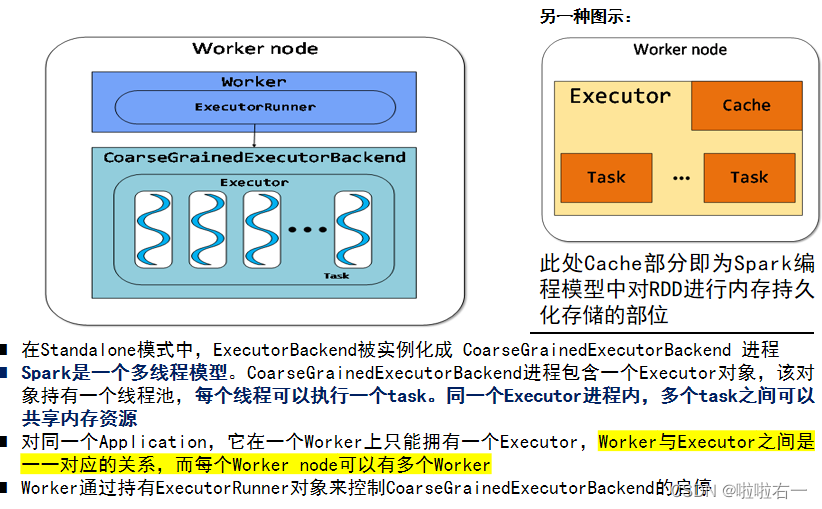
Worker node的结构:
🐇Spark系统的基本结构
Spark Driver的组成

🐇Spark应用程序的基本结构

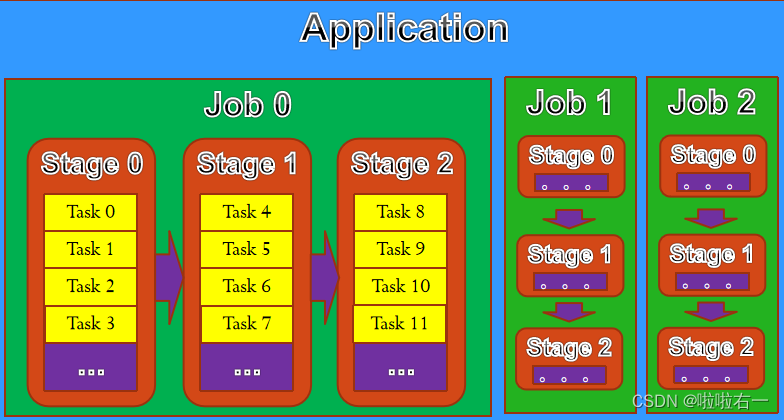
- Application:基于Spark的用户程序,包含一个Driver Program和多个executor(Worker中)
- Job:包含多个Task的并行计算,由Spark action催生。
- Stage:Job拆分成多组Task,每组任务被称为Stage,也可称为TaskSet。
- Task:基本程序执行单元,在一个executor上执行。
🐇Spark程序运行机制⭐️

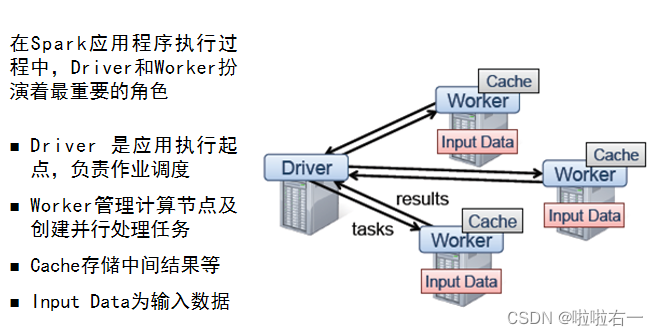
- Client 提交应用,Master节点启动Driver。
- Driver向Cluster Manager申请资源,并构建Application的运行环境,即启动SparkContext。
- SparkContext向ClusterManager申请Executor资源,启动CoarseGrainedExecutorBackend。
- Executor向SparkContext申请Task,SparkContext将代码发放给Executor。
- Standalone模式下,ClusterManager即为Master。YARN下,ClusterManager为资源管理器。
- Driver Program可以在Master上运行,此时Driver就在Master节点上。为了防止Driver和Executor间通信过慢,一般原则上要使它们分布在同一个局域网中。
📚Spark的程序执行过程

🐇Spark运行框架主节点
- Application:由用户编写的Spark应用程序,其中包括driver program和executor。
- Driver Program:执行用户代码的main()函数,并创建SparkContext。
- Cluster manager:集群当中的资源调度服务选取。例:standalone manager, Mesos, YARN
- Job:由某个RDD的Action算子生成或者提交的一个或者多个一系列的调度阶段,称之为一个或者多个Job,类似于MapReduce中Job的概念
- SparkContext:SparkContext由用户程序启动,是Spark运行的核心模块,它对一个Spark程序进行了必要的初始化过程,其中包括了: - 创建SparkConf类的实例:这个类中包含了用户自定义的参数信息和Spark配置文件中的一些信息等等 (用户名、程序名、Spark版本等) - 创建SparkEnv类的实例:这个类中包含了Spark执行时所需要的许多环境对象,例如底层任务通讯的Akka actor System、block manager、serializer等- 创建调度类的实例:Spark中的调度分为TaskScheduler和DAGScheduler两种,而它们的创建都在SparkContext的初始化过程中
🐇Spark运行框架的从节点
- Executor:executor负责在子节点上执行Spark任务,每个application都有自身的Executor。
- Stage:每一个Job被分成一系列的任务的集合,这些集合被称之为Stage,用于Spark阶段的调度。例:在MapReduce作业中,Spark将划分为Map的Stage和Reduce的Stage进行调度
- Task:被分发到一个Executor上的最小处理单元。
🐇Spark程序执行过程⭐️
- 用户编写的Spark程序提交到相应的Spark运行框架中。
- Spark创建SparkContext作为本次程序的运行环境。
- SparkContext连接相应的集群配置(Mesos/YARN),来确定程序的资源配置使用情况。
- 连接集群资源成功后,Spark获取当前集群上存在Executor的节点,即当前集群中Spark部署的子节点中处于活动并且可用状态的节点(Spark准备运行你的程序并且确定数据存储)。
- Spark分发程序代码到各个节点。
- 最终,SparkContext发送tasks到各个运行节点来执行。
Spark的技术特点
- RDD:Spark提出的弹性分布式数据集,是Spark最核心的分布式数据抽象,Spark的很多特性都和RDD密不可分。
- Transformation&Action:Spark通过RDD的两种不同类型的运算实现了惰性计算,即在RDD的Transformation运算时,Spark并没有进行作业的提交;而在RDD的Action操作时才会触发SparkContext提交作业。
- Lineage:为了保证RDD中数据的鲁棒性,Spark系统通过世系关系(lineage)来记录一个RDD是如何通过其他一个或者多个父类RDD转变过来的,当这个RDD的数据丢失时,Spark可以通过它父类的RDD重新计算。
- Spark调度:Spark采用了事件驱动的Scala库类Akka来完成任务的启动,通过复用线程池的方式来取代MapReduce进程或者线程启动和切换的开销。
- API:Spark使用scala语言进行开发,并且默认Scala作为其编程语言。因此,编写Spark程序比MapReduce程序要简洁得多。同时,Spark系统也支持Java、Python语言进行开发。
- Spark生态:Spark SQL、Spark Streaming、GraphX等等为Spark的应用提供了丰富的场景和模型,适合应用于不同的计算模式和计算任务
- Spark部署:Spark拥有Standalone、Mesos、YARN等多种部署方式,可以部署在多种底层平台上。
综上所述,Spark是一种基于内存的迭代式分布式计算框架,适合于完成多种计算模式的大数据处理任务。
📚Spark编程模型
Spark为了解决以往分布式计算框架存在的一些问题(重复计算、资源共享、系统组合),提出了一个分布式数据集的抽象数据模型:RDD(Resilient Distributed Datasets)弹性分布式数据集。
- 简单来说,RDD是MapReduce模型的一种简单的扩展和延伸。
- RDD是一种分布式的内存抽象,允许在大型集群上执行基于内存的计算(In-Memory Computing),同时还保持了MapReduce等数据流模型的容错特性。
- RDD只读、可分区,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。
🐇Spark的基本编程方法与示例⭐️
Spark编程接口
- Spark用Scala语言实现了RDD的API
- Scala是一种基于JVM的静态类型、函数式、面向对象的语言。Scala具有简洁(特别适合交互式使用)、有效(因为是静态类型)等优点
- Spark支持三种语言的API:Scala、Python、Java
//在一个存储于HDFS的Log文件中,计算出现ERROR的行数
//定义一个main函数
def main(args: Array[String])
{
//定义一个sparkConf,提供Spark运行的各种参数,如程序名称、用户名称等
val conf = new SparkConf().setAppName("Spark Pi")
//创建Spark的运行环境,并将Spark运行的参数传入Spark的运行环境中
val sc = new SparkContext(conf)
//调用Spark的读文件函数,从HDFS中读取Log文件,输出一个RDD类型的实例:fileRDD。
//具体类型:RDD[String]
val fileRDD=sc.textFile(“hdfs:///root/Log”)
//调用RDD的filter函数,过滤fileRDD中的每一行,如果该行中含有ERROR,保留;
//否则,删除。生成另一个RDD类型的实例:filterRDD。
//具体类型:RDD[String]
//line=>line.contains(“ERROR”)表示对每一个line应用contains()函数
val filterRDD=fileRDD.filter(line=>line.contains(“ERROR”))
//统计filterRDD中总共有多少行,result为Int类型
val result = filterRDD.count()
//关闭Spark
sc.stop()
}
🥕RDD的创建
从形式上看,RDD是一个分区的只读记录的集合。因此,RDD只能通过两种方式创建:
- 通过从存储器中读取,例如上述代码:val file=sc.textFile(“hdfs:///root/Log”),从HDFS中读取。例如:val rdd = sc.parallelize(1 to 100, 2) ,生成一个1到100的数组,并行化成RDD。
- 其他RDD的数据上的确定性操作来创建(即Transformation)。例如:val filterRDD = file.filter(line=>line.contains(“ERROR”)) //通过file的filter操作生成一个新的filterRDD。
🥕RDD的操作
RDD支持两种类型的操作:
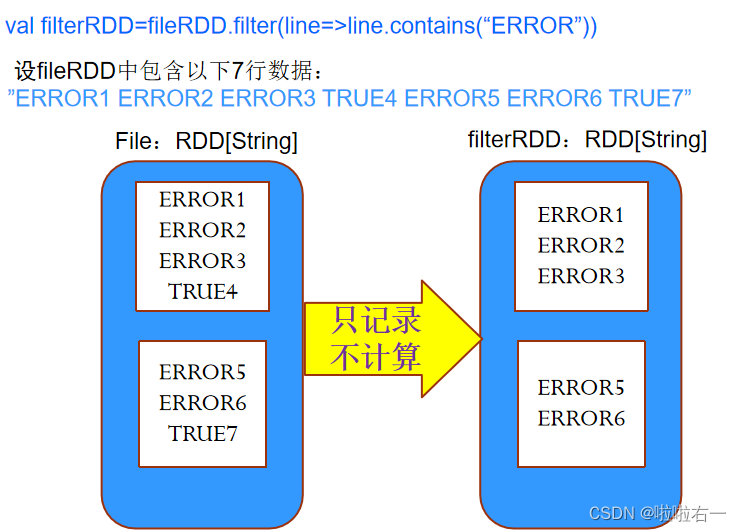
- 转换(transformation):这是一种惰性操作,即使用这种方法时,只是定义了一个新的RDD,而并不马上计算新的RDD内部的值。 - 例:val filterRDD=fileRDD.filter(line=>line.contains(“ERROR”))。上述这个操作对于Spark来说仅仅记录从file这个RDD通过filter操作变换到filterRDD这个RDD的变换,并不计算filterRDD的结果。
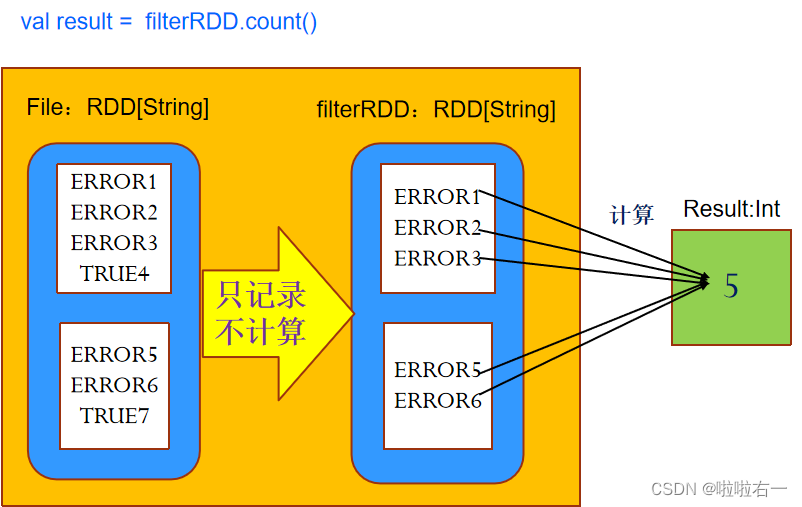
- 动作(action):立即计算这个RDD的值,并返回结果给程序,或者将结果写入到外存储中。 - 例:val result = filterRDD.count(),上述操作计算最终的result结果是多少,包括前边transformation时的变换。
Spark 支持的一些常用 transformation操作
Spark支持的一些常用action操作
图片来源:帅成一匹马


🐇RDD的容错实现
在RDD中,存在两种容错的方式:
- **Lineage(世系系统、依赖系统)**:RDD提供一种基于粗粒度变换的接口,这使得RDD可以通过记录RDD之间的变换,而不需要存储实际的数据,就可以完成数据的恢复,使得Spark具有高效的容错性。
- **CheckPoint(检查点)**:对于很长的lineage的RDD来说,通过lineage来恢复耗时较长。因此,在对包含宽依赖的长世系的RDD设置检查点操作非常有必要。
🐇RDD之间的依赖关系
在Spark中存在两种类型的依赖:
- 窄依赖:父RDD中的一个Partition最多被子RDD中的一个Partition所依赖。
- 宽依赖:父RDD中的一个Partition被子RDD中的多个Partition所依赖。


🐇RDD持久化
Spark提供了三种对持久化RDD的存储策略:
- 未序列化的Java对象,存于内存中:性能表现最优,可以直接访问在JAVA虚拟机内存里的RDD对象。
- 序列化的数据,存于内存中: - 取消JVM中的RDD对象,将对象的状态信息转换为可存储形式,减小RDD的存储开销,但使用时需要反序列化恢复。- 在内存空间有限的情况下,这种方式可以让用户更有效的使用内存,但是这么做的代价是降低了性能。
- 磁盘存储:适用于RDD太大难以在内存中存储的情形,但每次重新计算该RDD都会带来巨大的额外开销。
完整的存储级别介绍:

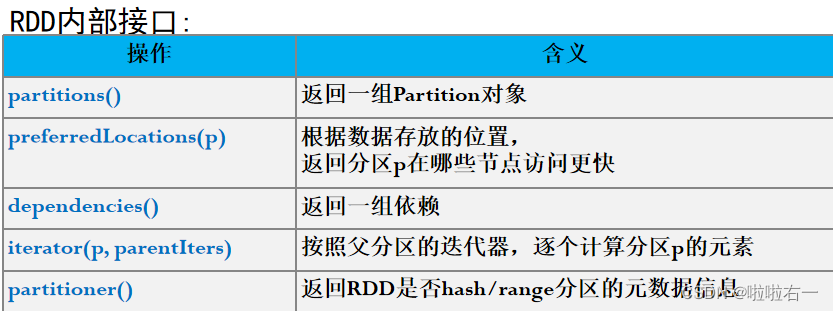
🐇RDD内部设计
每个RDD都包含:
- 一组RDD分区(partition),即数据集的原子组成部分。
- 对父RDD的一组依赖,这些依赖描述了RDD的Lineage。
- 一个函数,即在父RDD上执行何种计算。
- 元数据,描述分区模式和数据存放的位置。
📚Spark和集群管理工具的结合
不同计算引擎各有所长,真实应用中往往需要同时使用不同的计算框架。不同框架和应用会争抢资源,互相影响,使得管理难度和成本增加。
统一资源管理平台和集装箱思想
- 统一的资源管理平台(YARN、Mesos、Docker)将资源独立管理。通过资源管理可在同一个集群平台上部署不同的计算框架和应用,从而实现多租户资源共享。
- 集装箱思想:将应用和依赖“装箱”,一次配置,随处部署。
- 资源管理:所有接入的框架要先向它申请资源,申请成功之后,再由平台自身的调度器决定资源交由哪个任务使用。
- 资源共享:通过资源管理可在同一集群平台上部署不同的计算框架和应用,实现多租户资源共享
- 资源隔离:不同的框架中的不同任务往往需要的资源(内存,CPU,网络IO等)不同,它们运行在同一个集群中,会相互干扰。所以需要实现资源隔离以免任务之间由资源争用导致效率下降
- 提高资源利用效率:当将各种框架部署到同一个大的集群中,进行统一管理和调度后,由于各种作业交错且作业提交频率大幅度升高,则为资源利用率的提升增加了机会
- 扩展和容错:统一资源管理平台不能影响到上层框架的可扩展性和容错,同时自身也应具备良好的可扩展性和容错性。
YARN:YARN是Hadoop2.0时代的编程架构,被称为新一代MapReduce。其核心思想是将原MapReduce框架中的 JobTracker 和 TaskTracker 重新设计,变成了:ResourceManager(中心的服务)、ApplicationMaster(负责一个 Job 生命周期内的所有工作)、NodeManager(负责 Container 状态的维护)。

Mesos:Mesos是Apache旗下著名的分布式资源管理框架,被称为分布式系统的内核。Mesos包含两个组件,Master和Slave。

Docker:搬运工,搬运的是集装箱(Container),集装箱里面装的是任意类型的App。Docker把App装在Container内,通过Linux Container技术的包装将App变成一种标准化的、可移植的、自管理的组件。

Spark 编程示例——实验三:PageRank算法实现
📚Spark环境中其它功能组件简介

🐇Spark SQL
Spark SQL 是一个用来处理结构化数据的分布式SQL查询引擎,具有以下几个特点:
- 与Spark程序无缝对接。使用集成的API,Spark SQL允许使用RDD模型来查询结构化数据,这使得在复杂程序里运行SQL查询变得容易。
- 统一数据访问接口。Spark SQL提供统一的接口来访问各种结构化数据,包括Hive、Parquet和Json文件。
- 与Hive高度兼容。对已经存在的Hive数据、Hive查询语句和UDFs等,Spark SQL都可以完美兼容,方便了应用迁移。
- 使用标准链接。Spark SQL可以使用工业标准JDBC和ODBC进行链接,减小了开发人员的学习成本。
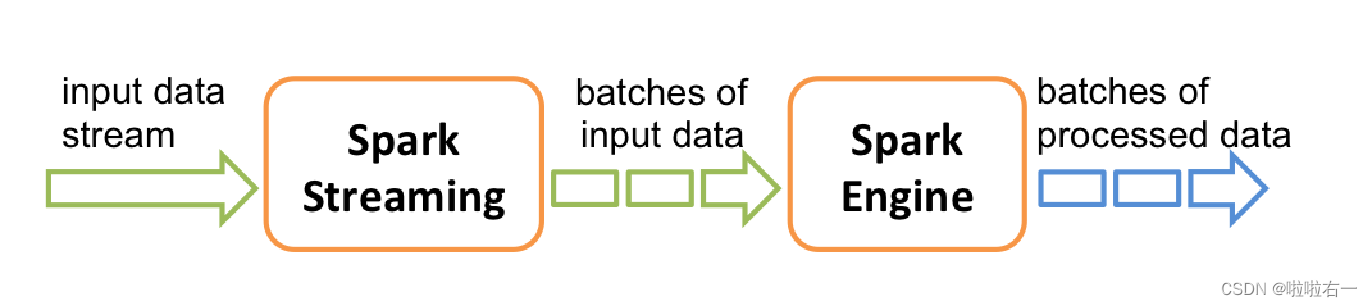
🐇Spark Streaming
- Spark Streaming 的工作机制是对数据流进行分片,使用Spark计算引擎处理分片数据,并返回相应分片的计算结果。
- Spark Streaming 提供的基本流式数据抽象叫discretized stream,或称DStream。DStream由一系列连续的RDD表示(每个数据流分片被表示为一个RDD),对DStream的操作被转换成对相应RDD序列的操作。
🐇GraphX
- GraphX是Spark系统中对图进行表示和并行处理的组件,它把图抽象为:给每个顶点和边附着了属性的有向多重图。
- GraphX提供了一系列基本图操作(比如subgraph、joinVertices、aggregateMessages等)和优化了的Pregel API变种,并且各种图算法还在不断丰富中。

- GraphX使用高效的点分割存储模式。


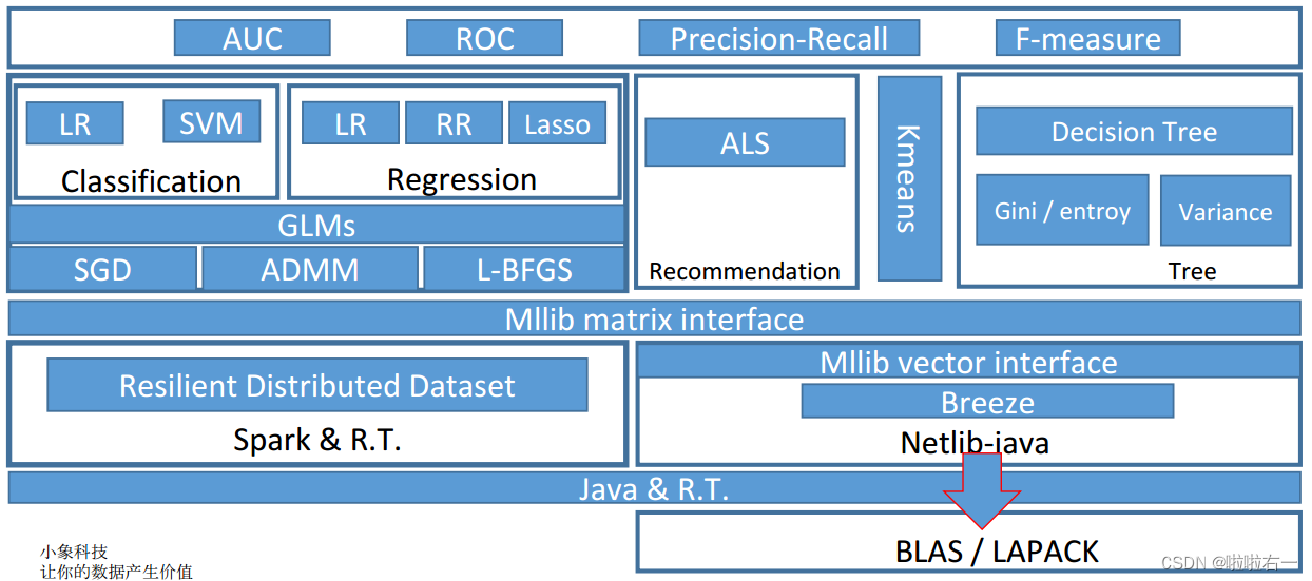
🐇MLlib
- MLlib是Spark的分布式机器学习算法库,包含了很多常用机器学习算法和工具类
版权归原作者 啦啦右一 所有, 如有侵权,请联系我们删除。