
先看下大数据的发展历程
随着公司业务的增加,各种场景都要大量的业务数据产生,对于这些不断产生的数据如何进行有效的处理?
由此诞生了大数据处理工具:
- 数据存在关系型数据库,比如mysql,如何分析数据? 早期一般都是采用批量数据分析的方式 1.1 把数据丢到HDFS中,然后写mapReduce任务进行批数据分析(需要编写代码,麻烦) 1.2 将HDFS的数据映射到HIVE中,通过写HQL 来完成数据的分析,背后的逻辑还是转成mapReduce任务 (方便)
- 后来慢慢的对数据分析的实时性增加 storm 可以对数据进行实时分析
如果一个公司有批数据处理和流数据处理的要求时,需要掌握上面所有技术
- spark 早期支持批数据处理,后来支持流数据处理
一个优秀的计算框架需要支持批处理,流处理,支持SQL 处理
spark在流数据的处理上是微批处理,延迟比较大 (不是完全实时)
spark认为 流式处理是批处理的一个场景(微批)
- flink 计算框架 flink 任务 批处理是流式处理的一个场景 可以针对批处理和流式数据都可以支持sql
有边界
有开始,有结束
无边界
有开始,无结束
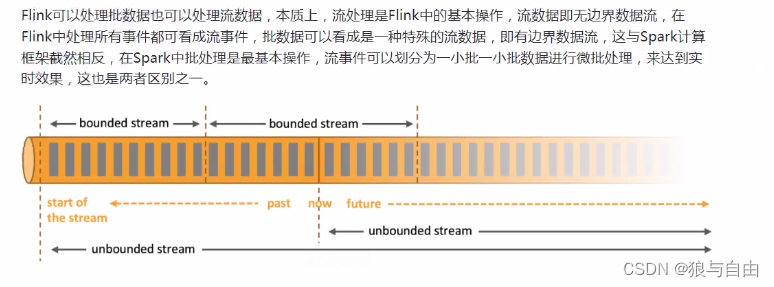
Fink是一个支持批数据,流数据,支持sql的计算框架
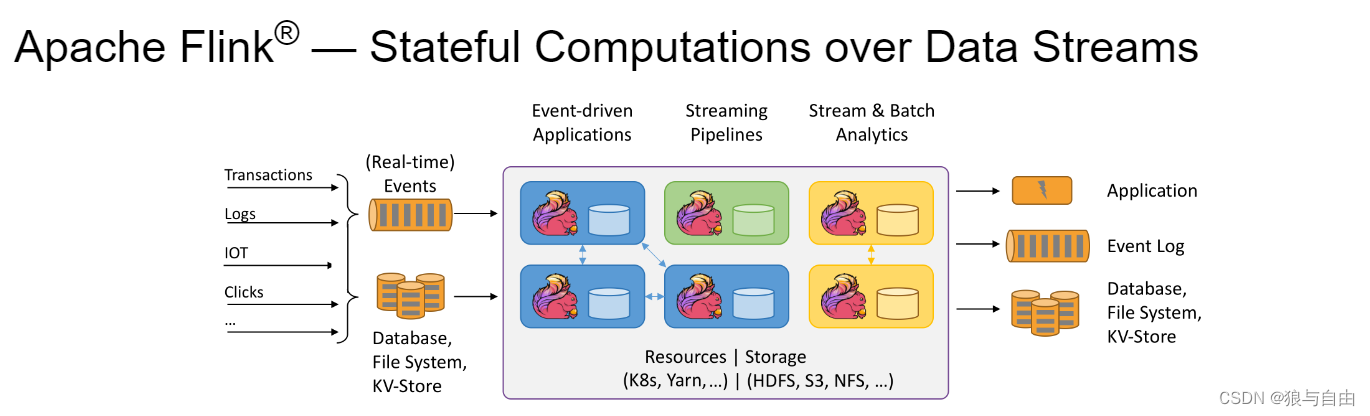
事件驱动型的应用
本文转载自: https://blog.csdn.net/u013929107/article/details/131736676
版权归原作者 狼与自由 所有, 如有侵权,请联系我们删除。
版权归原作者 狼与自由 所有, 如有侵权,请联系我们删除。