

📚博客主页:爱敲代码的小杨.
✨专栏:《Java SE语法》 | 《数据结构与算法》 | 《C生万物》 |《MySQL探索之旅》 |《Web世界探险家》
❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更新的动力❤️
🙏小杨水平有限,欢迎各位大佬指点,相互学习进步!

文章目录
1. 数据库设计
1.1 数据库设计基本概念
- 数据库设计就是根据业务的具体需求,结合我们所学的 DBMS ,为了这个业务构造最优的数据存储模型。
- 建立数据库中的表结构以及表与表之间的关联关系的过程。
1.2 数据库设计的步骤
- 需求分析(数据是什么?数据具有哪些属性?数据和属性之间的特点是什么)
- 逻辑分析(通过 ER图对数据库进行逻辑建模)
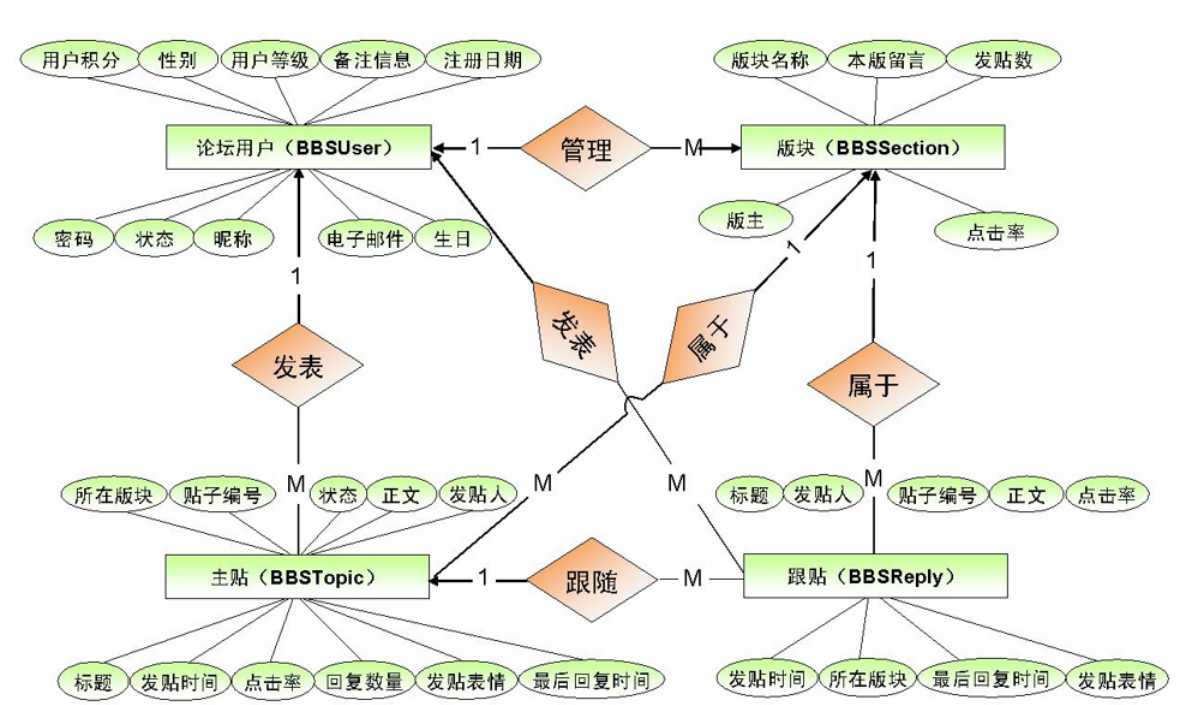
- 物理设计(根据数据库自身的特点把逻辑设计转换为物理设计)
- 维护设计(1. 对新的需求进行建表;2. 表优化)
1.3 表设计
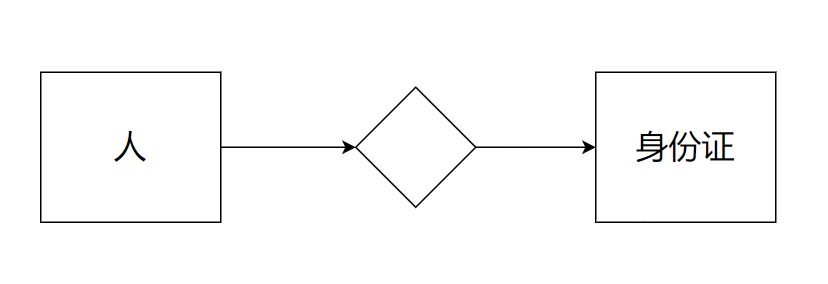
1.3.1 一对一
例如:人 和 身份证 的关系
一个人只能对应一个身份证号
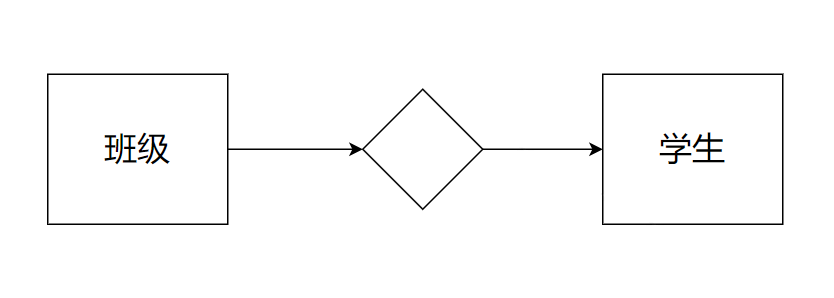
1.3.2 一对多
例如: 班级 和 学生 的关系
一个班级多个学生
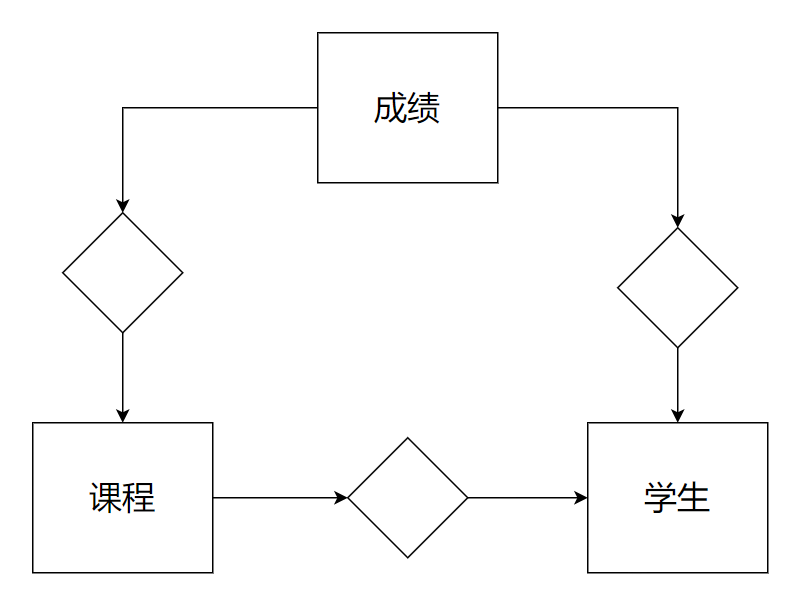
1.3.3 多对多
例如:学生 和 课程 的关系
一个学生可以选择多个课程
一个课程可以被多个学生选择
案例:
- 创建学生表:学生 id ,姓名
createtable student( id intprimarykeyauto_increment, name varchar(20)); - 创建课程表:课程表,课程名
createtable course( courseId intprimarykeyauto_increment, courseName varchar(20)); - 创建关联表:学生和课程之间的关系,需要包含学生id 和课程id 作为外键。
createtable student_course( student_id int, course_id int,primarykey(student_id, course_id),foreignkey(student_id)references student(id),foreignkey(course_id)references course(courseId));
2. 聚合查询
2.1 聚合函数
常见的统计总数、计算平局值等操作,可以使用聚合函数来实现,常见的聚合函数有:
函数说明COUNT([DISTINCT] expr)返回查询的数据的数量SUM([DISTINCT] expr)返回查询到的数据的总和,忽略非数值AVG([DISTINCT] expr)返回查询到的数据的平均值,忽略非数值MAX([DISTINCT] expr)返回查询到的数据的最大值,忽略非数值MIN([DISTINCT] expr)返回查询到的数据的最小值,忽略非数值
案例:
- count:计数
-- 统计有多少位学生selectcount(*)from student;-- 统计学生表有多少个姓名,姓名为 NULL 不会计入结果selectcount(name)from student;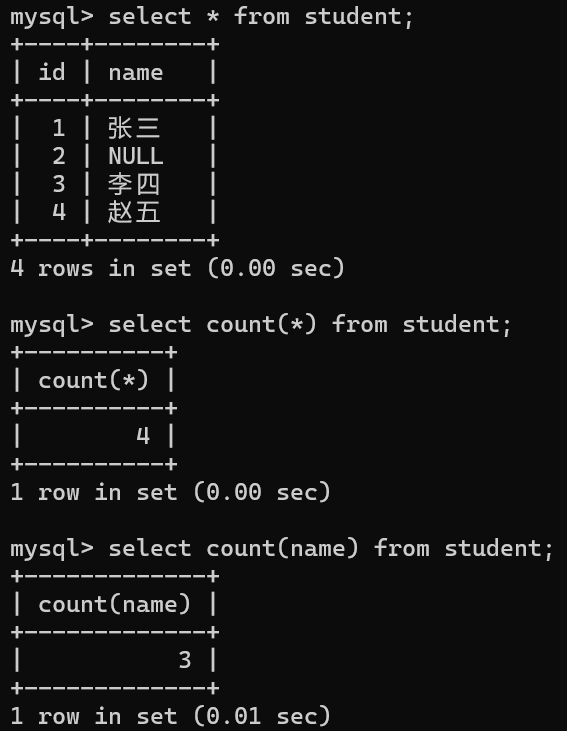
- sum:总和
-- 统计分数的总和selectsum(score)from score;-- 统计分数小于70的总分,如果没有返回nullselectsum(score)from score where score<70;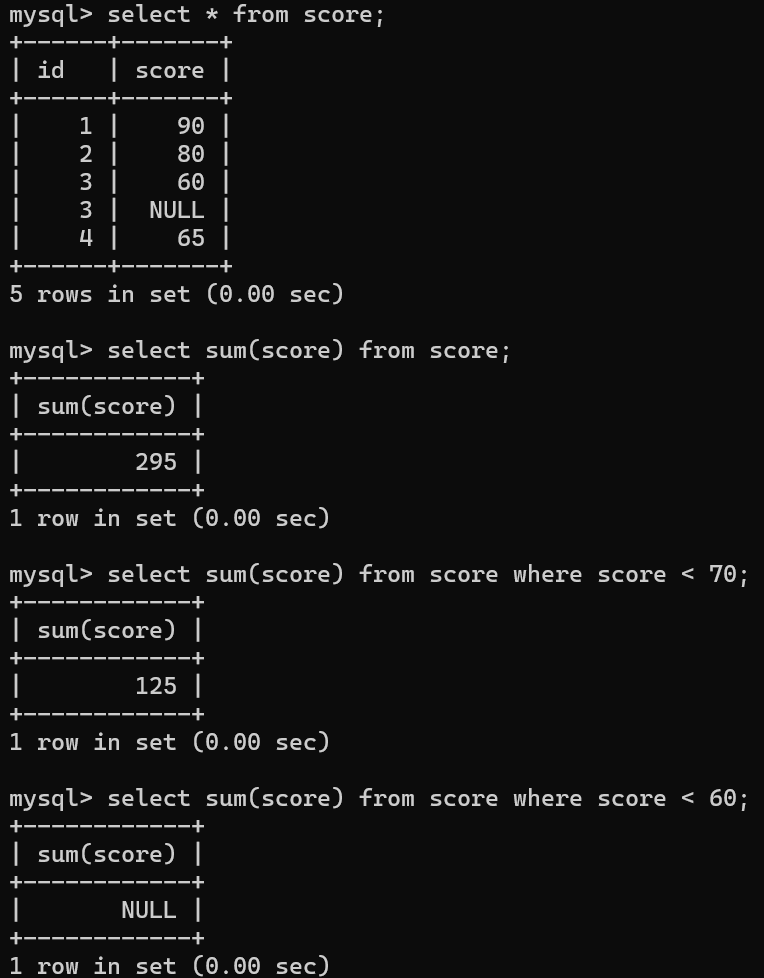
- avg:平均值
-- 查询分数的平均值selectavg(score)from score;-- 查询分数小于70的平均值,如果没有则返回 NULL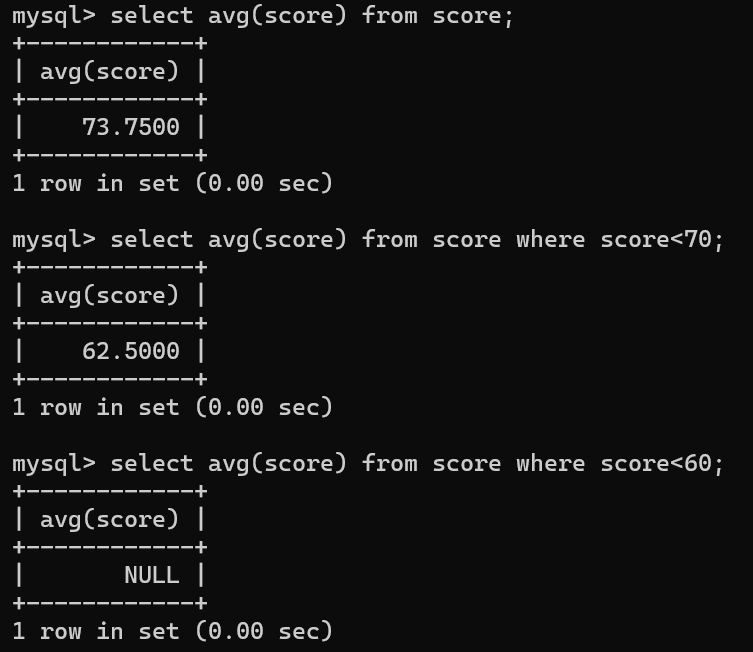
- MAX:最大值
-- 查询分数的最大值selectmax(score)from score;-- 查询60到90之间的最大值selectmax(score)from score where score>60and score<90;-- 查询大于90的最大值,如果没有则返回 NULLselectmax(score)from score where score>90;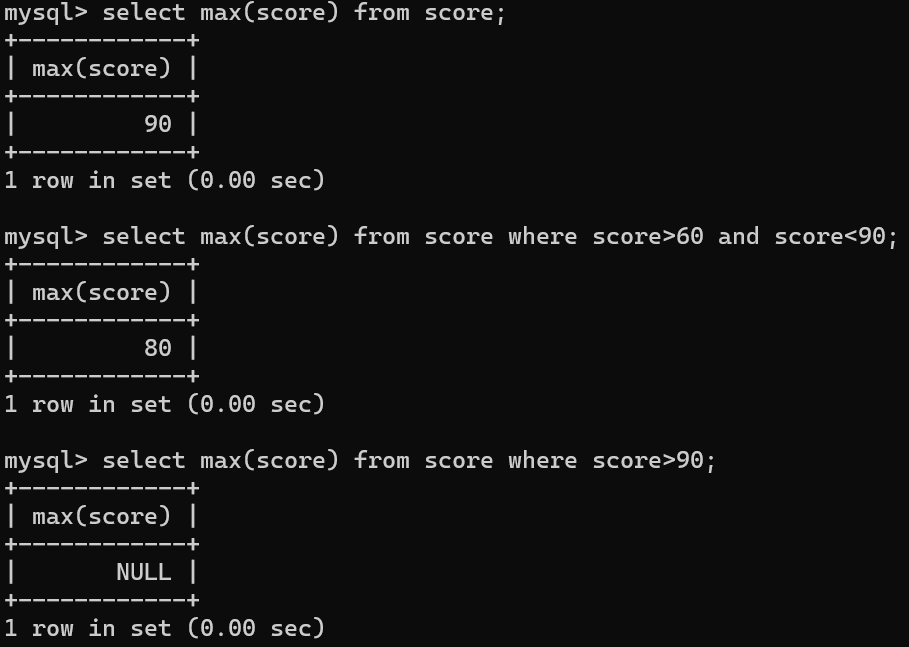
- MIN:最小值
-- 查询分数的最小值selectmin(score)from score;-- 查询分数在60到90之间的最小值selectmin(score)from score where score>60and score<90;-- 查询分数在60以下的最小值,如果没有则返回 NULLselectmin(score)from score where score<60;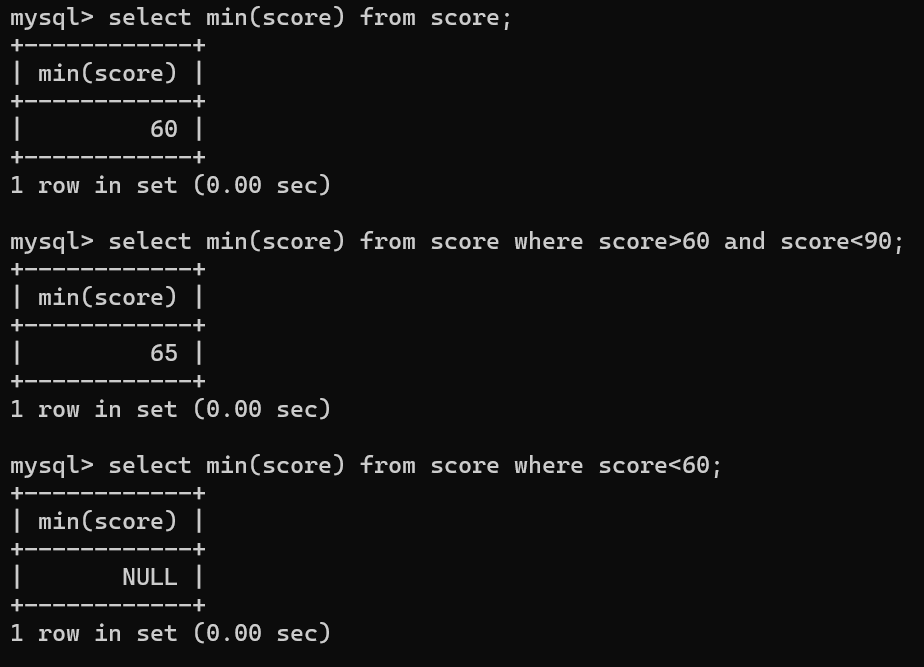
2.2 分组查询
select
中使用
group by
子句可以对指定列进行分组查询。需要满足:使用
group by
进行分组查
询时,
select
指定的字段必须是“分组依据字段”,其他字段若想出现在
select
中则必须包含在聚合函
数中。
select column1,sum(column2),..fromtablegroupby column1,column3;
案例:
测试表:职工表 id,name(姓名),role(职位),salary(工资)
createtable emp(id int, name varchar(20), role varchar(20), salary int);insertinto emp values(1,'张三','Java开发',10000);insertinto emp values(2,'李四','Java开发',9000);insertinto emp values(3,'王五','Web开发',8000);insertinto emp values(4,'赵六','Web开发',9000);insertinto emp values(5,'王麻子','运维',8500);insertinto emp values(6,'玛晕','老板',100000);
- 查询每个岗位的最高工资、最低工资和平均工资
select role,max(salary),min(salary),avg(salary)from emp groupby role;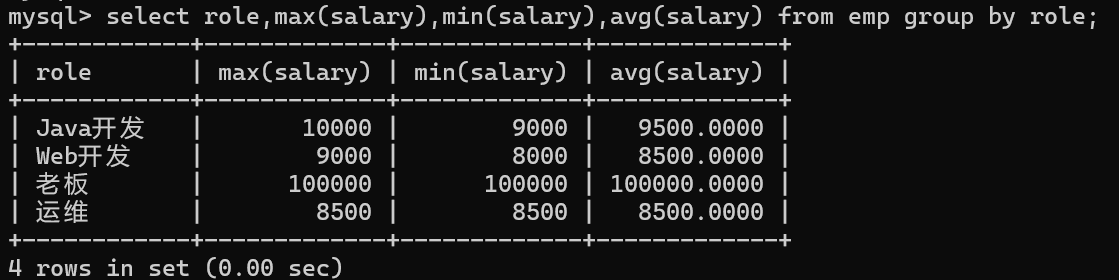
2.3 条件过滤
group by
子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用
where
语句,而需要用
having
。
- 查询平均工资低于9000的职位和它的平均工资
select role,max(salary),min(salary),avg(salary)from emp groupby role havingavg(salary)<9000;

本文转载自: https://blog.csdn.net/QQ3447387928/article/details/137460590
版权归原作者 爱敲代码的小杨. 所有, 如有侵权,请联系我们删除。
版权归原作者 爱敲代码的小杨. 所有, 如有侵权,请联系我们删除。