
全网付费课程欢迎咨询QQ:3388486286
一、 安装
官方安装Elasticsearch,和ES可视化工具kibana。安装下载过程略。
二、 启动Elasticsearch。
windows系统,直接进入到如图目录,然后启动elasticsearch.bat,这个就是ES服务。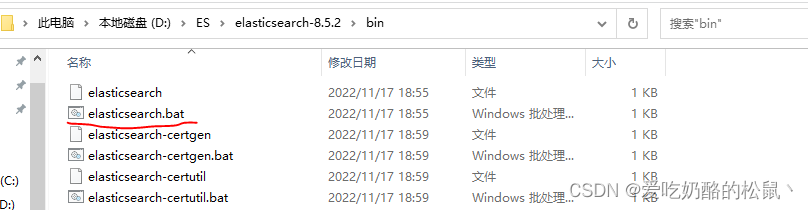
启动后,我们可以访问https://127.0.0.1:9200/来查看 ES是否 启动 成功。
浏览器启动后,提示输入账号密码。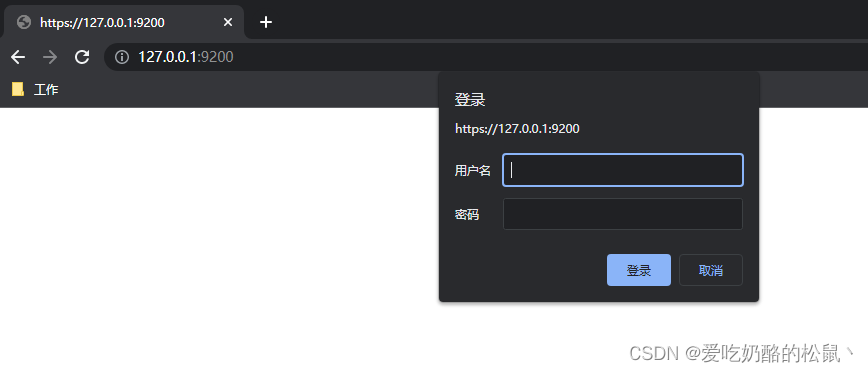
在安装的
elasticsearch-8.5.2\bin
目录下,启动
cmd
命令,输入以下指令获取账号密码。
elasticsearch-reset-password -u elastic
输入完后出现如图,[用户名]和密码。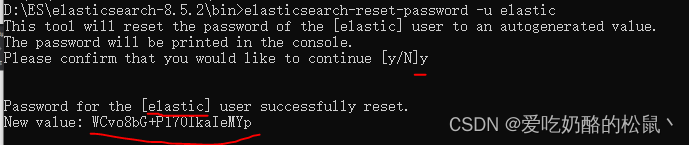
然后输入到浏览器中,就OK了。
出现该界面,表示ES启动成功。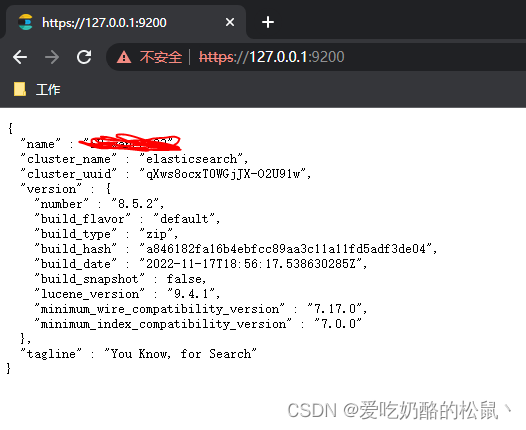
三、 启动kibana。
进入到如图目录。点击
kibana.bat
等待服务启动。
启动 完成后,访问如下地址:http://localhost:5601/
他会提示你配置token令牌。
进入如图目录
elasticsearch-8.5.2\bin
,执行一下命令获取令牌。
elasticsearch-create-enrollment-token.bat --scope kibana

然后进行配置即可。
配置完成后,会看到如图界面。
依次点击,就可以打开通信工具,按照ES的接口风格来和ES进行通信。
三、 Elasticsearch的基本使用。
ES是通过创建索引,去管理文档的。
1.创建文档。
ES中的文档就相当于面向对象中的对象,文档格式就是Json类型。
打开kibana找到Dev Tools,我们来使用
PUT
创建第一条数据。
//添加数据PUT/megacorp/_doc/1{"first_name":"JC","last_name":"W","age":25,"about":"I love to go swiming!","interests":["sports","music"]}

数据写完后,点击这个小三角形,即发生请求。
请求完,我们可以看到右边的返回结果。
{"_index":"megacorp","_id":"4","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":4,"_primary_term":1}
"successful": 1表示创建成功。
2.查询刚刚创建的文档。
//获取指定ID数据GET/megacorp/_doc/1//获取所有数据,默认返回10条GET/megacorp/_search
//尝试下搜索姓氏为 ``Smith`` 的雇员GET/megacorp/_search?q=last_name:Smith
以上都是轻量搜索,Query-string 搜索通过命令非常方便地进行临时性的即席搜索 ,但它有自身的局限性.。
Elasticsearch 提供一个丰富灵活的查询语言叫做 查询表达式 , 它支持构建更加复杂和健壮的查询。
3.使用查询表达式搜索
查询
last_name为w
的人。
//表达式查询GET/megacorp/_search
{"query":{"match":{"last_name":"w"}}}
返回结果:
{"took":890,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":1.2039728,"hits":[{"_index":"megacorp","_id":"1","_score":1.2039728,"_source":{"first_name":"JC","last_name":"W","age":25,"about":"I love to go swiming!","interests":["sports","music"]}}]}}
hits.value
代表查询了几条数据,
hits
数组是数据源。
查询 "last_name": "w"并且 年龄大于20
get /megacorp/_search
{"query":{"bool":{"must":[{"match":{"last_name":"w"}}],"filter":[{"range":{"age":{"gte":20}}}]}}}
这部分是一个
range
过滤器 , 它能找到年龄大于 20 的文档,其中 gt 表示_大于_。
4.全文搜索
搜索下所有喜欢攀岩(rock climbing)的员工:
//全文 搜索 GET/megacorp/_search
{"query":{"match":{"about":"rock climbing"}}}
返回结果:
{"took":0,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":2,"relation":"eq"},"max_score":1.9032972,"hits":[{"_index":"megacorp","_id":"5","_score":1.9032972,"_source":{"first_name":"John","last_name":"Smith 1","age":25,"about":"I love to go rock climbing","interests":["sports","music"]}},{"_index":"megacorp","_id":"6","_score":0.6682933,"_source":{"first_name":"Jane","last_name":"Smith 2","age":32,"about":"I like to collect rock albums","interests":["music"]}}]}}
Elasticsearch 默认按照相关性得分排序,即每个文档跟查询的匹配程度。第一个最高得分的结果很明显:John Smith 的 about 属性清楚地写着 “rock climbing” 。
但为什么 Jane Smith 也作为结果返回了呢?原因是她的 about 属性里提到了 “rock” 。因为只有 “rock” 而没有 “climbing” ,所以她的相关性得分低于 John 的。
这是一个很好的案例,阐明了 Elasticsearch 如何 在 全文属性上搜索并返回相关性最强的结果。
5.短语搜索
查询,仅匹配同时包含 “rock” 和 “climbing” ,并且 二者以短语 “rock climbing” 的员工记录。
为此对
match
查询稍作调整,使用一个叫做
match_phrase
的查询:
GET/megacorp/_search
{"query":{"match_phrase":{"about":"rock climbing"}}}
返回结果:
{"took":0,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":2.4450343,"hits":[{"_index":"megacorp","_id":"5","_score":2.4450343,"_source":{"first_name":"John","last_name":"Smith 1","age":25,"about":"I love to go rock climbing","interests":["sports","music"]}}]}}
可以看到只返回了包含
rock climbing
的数据。
6.高亮搜索
//高亮搜索GET/megacorp/_search
{"query":{"match_phrase":{"about":"rock climbing"}},"highlight":{"fields":{"about":{}}}}
当执行该查询时,返回结果与之前一样,与此同时结果中还多了一个叫做 highlight 的部分。这个部分包含了 about 属性匹配的文本片段,并以 HTML 标签
<em></em>
封装:
{"took":593,"timed_out":false,"_shards":{"total":1,"successful":1,"skipped":0,"failed":0},"hits":{"total":{"value":1,"relation":"eq"},"max_score":2.4450343,"hits":[{"_index":"megacorp","_id":"5","_score":2.4450343,"_source":{"first_name":"John","last_name":"Smith 1","age":25,"about":"I love to go rock climbing","interests":["sports","music"]},"highlight":{"about":["I love to go <em>rock</em> <em>climbing</em>"]}}]}}
7.数据聚合分析
Elasticsearch 有一个功能叫聚合(
aggregations
),允许我们基于数据生成一些精细的分析结果。聚合与 SQL 中的
GROUP BY
类似但更强大。
Elasticsearch 5.x
版本以后,对排序和聚合等操作,用单独的数据结构
(fielddata)
缓存到内存里了,默认是不开启的,需要单独开启。
对对应字段执行聚合操作之前需要先开启
fielddata
//添加fielddataPUT megacorp/_mapping
{"properties":{"interests":{"type":"text","fielddata":true}}}
fielddata
开启后,我们再来使用聚合操作。
挖掘出员工中最受欢迎的兴趣爱好:
//聚合分析GET/megacorp/_search?pretty
{"aggs":{"all_interests":{"terms":{"field":"interests"}}}}
聚合结果:
"aggregations":{"all_interests":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"music","doc_count":4},{"key":"sports","doc_count":3},{"key":"forestry","doc_count":1},{"key":"games","doc_count":1},{"key":"play","doc_count":1},{"key":"sing","doc_count":1}]}}
可以看到,四位员工对音乐感兴趣,一位对林业感兴趣,三位对运动感兴趣…。这些聚合的结果数据并非预先统计,而是根据匹配当前查询的文档即时生成的。如果想知道叫 Smith 的员工中最受欢迎的兴趣爱好,可以直接构造一个组合查询:
//构造某个姓氏的兴趣爱好统计GET megacorp/_search
{"query":{"match":{"last_name":"Smith"}},"aggs":{"all_interests":{"terms":{"field":"interests","size":10}}}}
结果:
"aggregations":{"all_interests":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"music","doc_count":3},{"key":"sports","doc_count":2}]}}
聚合还支持分级汇总 。比如,查询特定兴趣爱好员工的平均年龄:
//查询特定爱好员工的平均年龄GET/megacorp/_search
{"aggs":{"all_interests":{"terms":{"field":"interests"},"aggs":{"avg_age":{"avg":{"field":"age"}}}}}}
结果:
"aggregations":{"all_interests":{"doc_count_error_upper_bound":0,"sum_other_doc_count":0,"buckets":[{"key":"music","doc_count":4,"avg_age":{"value":26.75}},{"key":"sports","doc_count":3,"avg_age":{"value":25}},{"key":"forestry","doc_count":1,"avg_age":{"value":35}},{"key":"games","doc_count":1,"avg_age":{"value":33}},{"key":"play","doc_count":1,"avg_age":{"value":33}},{"key":"sing","doc_count":1,"avg_age":{"value":33}}]}}
四、 Elasticsearch集群。
1.了解集群。
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同 cluster.name 配置的节点组成, 它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
当一个节点被选举成为 主 节点时, 它将负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。 任何节点都可以成为主节点。我们的示例集群就只有一个节点,所以它同时也成为了主节点。
作为用户,我们可以将请求发送到 集群中的任何节点 ,包括主节点。 每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。 无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。 Elasticsearch 对这一切的管理都是透明的。
2.集群健康。
Elasticsearch 的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是 集群健康 , 它在
status
字段中展示为
green
、
yellow
或者
red
。
//查看集群健康状态GET/_cluster/health
返回结果:
{"cluster_name":"elasticsearch","status":"yellow","timed_out":false,"number_of_nodes":1,"number_of_data_nodes":1,"active_primary_shards":12,"active_shards":12,"relocating_shards":0,"initializing_shards":0,"unassigned_shards":1,"delayed_unassigned_shards":0,"number_of_pending_tasks":0,"number_of_in_flight_fetch":0,"task_max_waiting_in_queue_millis":0,"active_shards_percent_as_number":92.3076923076923}
status
字段是我们最关心的。
status
字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green
所有的主分片和副本分片都正常运行。
yellow
所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red
有主分片没能正常运行
3.添加索引。
我们往 Elasticsearch 添加数据时需要用到 索引 —— 保存相关数据的地方。 索引实际上是指向一个或者多个物理 分片 的 逻辑命名空间 。
我们只需知道一个分片是一个 Lucene 的实例,以及它本身就是一个完整的搜索引擎。 我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
一个分片可以是 主 分片或者 副本 分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。
一个副本分片只是一个主分片的拷贝。副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,但是副本分片数可以随时修改。
让我们在包含一个空节点的集群内创建名为
blogs
的索引。 索引在默认情况下会被分配5个主分片。
//设置节点中分片数量 。表示设置了5个主分片,每个分配有一个备份。PUT/blogs
{"settings":{"number_of_shards":5,"number_of_replicas":1}}
简而言之,数据都存放在
shard
中,每个
node
可以自己设置
shard
数量,
shard
分为
primary shard
和
replicas shard
replicas shard是primary shard的备份,并且同一个
primary shard
的
replicas shard
不能放在同一个节点中,例如:P_A ,R_A不能在一个节点。但是P_A,R_B可以在同一个节点。如果相同数据和备份都在一个节点,那该节点如果宕机了,所有数据就会丢失。
4.水平扩容
主分片的数目在索引创建时就已经确定了下来。实际上,这个数目定义了这个索引能够 存储 的最大数据量。(实际大小取决于你的数据、硬件和使用场景。) 但是,读操作——搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量。
在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把副本数从默认的 1 增加到 2 :
PUT/blogs/_settings
{"number_of_replicas":2}
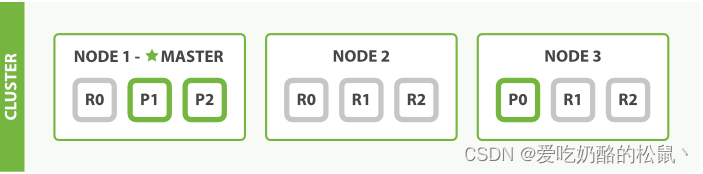
blogs 索引现在拥有9个分片:3个主分片和6个副本分片。 这意味着我们可以将集群扩容到9个节点,每个节点上一个分片。相比原来3个节点时,集群搜索性能可以提升 3 倍。
5.Autogenerating IDs
如果你的数据没有自然的 ID, Elasticsearch 可以帮我们自动生成 ID 。 请求的结构调整为: 不再使用 PUT 谓词, 而是使用 POST 谓词
POST/website/_doc
{"title":"My second blog entry","text":"still trying this out ...","date":"2022-01-01"}
post
后会自动生成一个
GUID
{"_index":"website","_id":"03HF8IQBM50g06X4YHbb","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}
6.文档的取回
取出刚刚创建的文档
get /website/_doc/03HF8IQBM50g06X4YHbb
返回 文档的一部分
//请求某个文档中的某个字段GET/website/_doc/03HF8IQBM50g06X4YHbb?_source=title,text
7.检查文档是否存在
如果只想检查一个文档是否存在–根本不想关心内容—那么用 HEAD 方法来代替 GET 方法。 HEAD 请求没有返回体,只返回一个 HTTP 请求报头:
//检查 文档 是否 存在 HEAD/website/_doc/123
8.更新整个文档
在 Elasticsearch 中文档是 不可改变 的,不能修改它们。相反,如果想要更新现有的文档,需要 重建索引 或者进行替换。
//修改文档数据PUT/website/_doc/123{"title":"My second blog entry","text":"still trying this out ...","date":"2022-01-11"}
9.创建新文档
方式1
POST/website/_doc/{"title":"My second blog entry","text":"still trying this out ...","date":"2022-01-01"}
然而,如果已经有自己的 _id ,那么我们必须告诉 Elasticsearch ,只有在相同的 _index 、 _type 和 _id 不存在时才接受我们的索引请求。这里有两种方式,他们做的实际是相同的事情。使用哪种,取决于哪种使用起来更方便。
第一种方法使用
op_type
查询-字符串参数:
//ID不存在时候才创建PUT/website/_doc/1234?op_type=create
{"title":"My second blog entry","text":"still trying this out ...","date":"2022-01-11"}
返回结果
{"error":{"type":"version_conflict_engine_exception","reason":"[1234]: version conflict, document already exists (current version [2])","index_uuid":"Dhq2F9QCR3G1DSWLM7niVA","shard":"0","index":"website"},"status":409}
返回409表示该ID已经存在。无法创建。
第二种方法是在 URL 末端使用 /
_create
:
PUT/website/_create/1{"title":"My second blog entry","text":"still trying this out ...","date":"2022-01-11"}
10. 删除文档
删除文档的语法和我们所知道的规则相同,只是使用
DELETE
方法:
//删除指定ID文档DELETE/website/_doc/1
如果找到该文档,Elasticsearch 将要返回一个 200 ok 的 HTTP 响应码,和一个类似以下结构的响应体。注意,字段 _version 值已经增加:
{"found":true,"_index":"website","_type":"blog","_id":"123","_version":2}
如果文档没有找到,我们将得到 404 Not Found 的响应码和类似这样的响应体:
{"found":false,"_index":"website","_type":"blog","_id":"123","_version":4}
即使文档不存在(
Found
是
false
),
_version
值仍然会增加。这是 Elasticsearch 内部记录本的一部分,用来确保这些改变在跨多节点时以正确的顺序执行。
11.乐观并发控制
Elasticsearch 是分布式的。当文档创建、更新或删除时, 新版本的文档必须复制到集群中的其他节点。Elasticsearch 也是异步和并发的,这意味着这些复制请求被并行发送,并且到达目的地时也许 顺序是乱的 。 Elasticsearch 需要一种方法确保文档的旧版本不会覆盖新的版本。
当我们之前讨论 index , GET 和 delete 请求时,我们指出每个文档都有一个 _version (版本)号,当文档被修改时版本号递增。 Elasticsearch 使用这个 _version 号来确保变更以正确顺序得到执行。如果旧版本的文档在新版本之后到达,它可以被简单的忽略。
我们可以利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失。我们通过指定想要修改文档的 version 号来达到这个目的。 如果该版本不是当前版本号,我们的请求将会失败。
老版本是通过
_version
进行控制,新版现在改为
_seq_no
和
_primary_term
进行控制,其中_primary_term相当于老版本中的_version。
假如此时 是并发操作,2个机器同时请求了 以下连接,如果第一个请求成功了,_version就加1,后者再发相同的请求就会失败。
//version=1的才修改PUT/website/_doc/3?if_seq_no=15&if_primary_term=1{"title":"My first blog entry","text":"Just trying this out11111"}
返回结果:
{"_index":"website","_id":"3","_version":2,"_seq_no":16,"_primary_term":1,"found":true,"_source":{"title":"My first blog entry","text":"Just trying this out"}}
可以看到 此时
"_version"
:值为2。后面值为1的版本请求将会失败。
12.文档的部分更新
update
请求最简单的一种形式是接收文档的一部分作为
doc
的参数, 它只是与现有的文档进行合并。对象被合并到一起,覆盖现有的字段,增加新的字段。 例如,我们增加字段
tags
和
views
到我们的博客文章,如下所示:
//添加 字段POST/website/_update/2/{"doc":{"tags":["testing"],"views":0}}
结果:
{"_index":"website","_id":"2","_version":2,"_seq_no":17,"_primary_term":1,"found":true,"_source":{"title":"My first blog entry","text":"Just trying this out...","views":0,"tags":["testing"]}}
这样就把新字段和老字段进行了合并。
另外ES还支持用
Groovy
脚本编程。
POST/website/_update/2/{"script":"ctx._source.views+=1"}
这样
views
的值就可以加1,具体用法可自行百度。
13.取回多个文档
mget
API 要求有一个 docs 数组作为参数,每个元素包含需要检索文档的元数据, 包括 _index 、 _id 。如果你想检索一个或者多个特定的字段,那么你可以通过 _source 参数来指定这些字段的名字:
//取回多个文档GET/_mget
{"docs":[{"_index":"website","_id":2},{"_index":"megacorp","_id":2,"_source":"age"}]}
结果:
{"docs":[{"_index":"website","_id":"2","_version":4,"_seq_no":19,"_primary_term":1,"found":true,"_source":{"title":"My first blog entry","text":"Just trying this out...","views":2,"tags":["testing"]}},{"_index":"megacorp","_id":"2","_version":1,"_seq_no":1,"_primary_term":1,"found":true,"_source":{"age":33}}]}
事实上,如果所有文档的 _index都是相同的,你可以只传一个 ids 数组,而不是整个 docs 数组:
//请求多id数据GET/megacorp/_mget
{"ids":["2","1"]}
14.批量增删改。
与
mget
可以使我们一次取回多个文档同样的方式,
bulk
API 允许在单个步骤中进行多次
create
、
index
、
update
或
delete
请求。 如果你需要索引一个数据流比如日志事件,它可以排队和索引数百或数千批次。
bulk
与其他的请求体格式稍有不同,如下所示:
POST/_bulk?pretty
{"delete":{"_index":"website","_id":"2"}}{"create":{"_index":"website","_id":"2"}}{"title":"My first blog post"}{"index":{"_index":"website"}}{"title":"My second blog post"}{"update":{"_index":"website","_id":"123"}}{"doc":{"title":"My updated blog post"}}
这种格式类似一个有效的单行 JSON 文档 流 ,它通过换行符(\n)连接到一起。注意两个要点:
每行一定要以换行符
(\n)
结尾, 包括最后一行 。这些换行符被用作一个标记,可以有效分隔行。
这些行不能包含未转义的换行符,因为他们将会对解析造成干扰。这意味着这个 JSON 不 能使用 pretty 参数打印。
这个 Elasticsearch 响应包含 items 数组,这个数组的内容是以请求的顺序列出来的每个请求的结果。
{"took":93,"errors":false,"items":[{"delete":{"_index":"website","_id":"2","_version":3,"result":"deleted","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":35,"_primary_term":2,"status":200}},{"create":{"_index":"website","_id":"2","_version":4,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":36,"_primary_term":2,"status":201}},{"index":{"_index":"website","_id":"L2ppV4UBxaYKjqkGJim4","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":37,"_primary_term":2,"status":201}},{"update":{"_index":"website","_id":"123","_version":4,"result":"noop","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":34,"_primary_term":2,"status":200}}]}
每个子请求都是独立执行,因此某个子请求的失败不会对其他子请求的成功与否造成影响。 如果其中任何子请求失败,最顶层的
error
标志被设置为
true
,并且在相应的请求报告出错误明细。
这也意味着
bulk
请求不是原子的: 不能用它来实现事务控制。每个请求是单独处理的,因此一个请求的成功或失败不会影响其他的请求。
15.路由一个文档到一个分片中
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?
首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard =hash(routing)% number_of_primary_shards
routing
是一个可变值,默认是文档的
_id
,也可以设置成一个自定义的值。
routing
通过
hash
函数生成一个数字,然后这个数字再除以
number_of_primary_shards
(主分片的数量)后得到 余数 。这个分布在
0
到
number_of_primary_shards-1
之间的余数,就是我们所寻求的文档所在分片的位置。
这就解释了为什么我们要在创建索引的时候就确定好主分片的数量 并且永远不会改变这个数量:因为如果数量变化了,那么所有之前路由的值都会无效,文档也再也找不到了。
16.空搜索
搜索API的最基础的形式是没有指定任何查询的空搜索,它简单地返回集群中所有索引下的所有文档:
GET /_search
17.多索引,多类型
我们可以通过在URL中指定特殊的索引和类型达到这种效果,如下所示:
/_search
在所有的索引中搜索所有的类型
/gb/_search
在 gb 索引中搜索所有的类型
/gb,us/_search
在 gb 和 us 索引中搜索所有的文档
/g*,u*/_search
在任何以 g 或者 u 开头的索引中搜索所有的类型
/gb/user/_search
//在 gb 索引中搜索 user 类型 5.0版本后不支持/gb,us/user,tweet/_search
在 gb 和 us 索引中搜索 user 和 tweet 类型 // 5.0版本后不支持/_all/user,tweet/_search // 5.0版本后不支持
在所有的索引中搜索 user 和 tweet 类型
18.分页
size
显示应该返回的结果数量,默认是 10
from
显示应该跳过的初始结果数量,默认是 0
如果每页展示 5 条结果,可以用下面方式请求得到 1 到 3 页的结果:
GET /_search?size=5
GET /_search?size=5&from=10
GET /_search?size=10&from=15
19.轻量 搜索
查询在所有类型中 Sponsor 字段包含 李四 单词的所有文档:
GET/_all/_search?q=Sponsor:李四
_all 字段
这个简单搜索返回包含 mary 的所有文档:
GET /_search?q=mary
之前的例子中,我们在 tweet 和 name 字段中搜索内容。然而,这个查询的结果在三个地方提到了 mary :
有一个用户叫做 Mary
6条微博发自 Mary
一条微博直接 @mary
Elasticsearch 是如何在三个不同的字段中查找到结果的呢?
当索引一个文档的时候,Elasticsearch 取出所有字段的值拼接成一个大的字符串,作为 _all 字段进行索引。例如,当索引这个文档时:
{"tweet":"However did I manage before Elasticsearch?","date":"2014-09-14","name":"Mary Jones","user_id":1}
这就好似增加了一个名叫 _all 的额外字段:
"However did I manage before Elasticsearch? 2014-09-14 Mary Jones 1"
除非设置特定字段,否则查询字符串就使用
_all
字段进行搜索。
在刚开始开发一个应用时,
_all
字段是一个很实用的特性。之后,你会发现如果搜索时用指定字段来代替
_all
字段,将会更好控制搜索结果。当
_all
字段不再有用的时候,可以将它置为失效,正如在 元数据:
_all
字段 中所解释的。
精确值 VS 全文
Elasticsearch 中的数据可以概括的
参考:ES文档。
版权归原作者 爱吃奶酪的松鼠丶 所有, 如有侵权,请联系我们删除。