
文章目录
提示:实时flink sql 参考很多网上方法与自己实践方法汇总(版本:flink1.13+)
一、参数方面
- flink sql参数配置
//关闭详细算子链(默认为true),true后job性能会略微有提升。false则可以展示更详细的DAG图方便地位性能结点 ###有用的参数
pipeline.operator-chaining:'true'//指定时区 ###实用的参数
table.local-time-zone:Asia/Shanghai//对flink sql是否要敏感大小(建议false,不区分大小写。默认为true)
table.identifier-case-sensitive:'false'//开启 miniBatch
table.exec.mini-batch.enabled:'true'//批量输出的间隔时间
table.exec.mini-batch.allow-latency:5s
//防止 OOM 设置每个批次最多缓存数据的条数
table.exec.mini-batch.size:'500'//提交批次数据大小
batchSize: '127108864'
//刷数据间隔
flushIntervalMs:'60000'//几个flush线程
numFlushThreads:'5'// 写odps时压缩 :https://help.aliyun.com/zh/flink/developer-reference/maxcompute-connector
compressAlgorithm: snappy
//开启异步状态后端
state.backend.async:'true'//状态后端开启增量(默认就是true 增量)
state.backend.incremental:'true'//作业链与处理槽共享组(默认为false),开启后在针对某个操作算子增加并行度和cu等资源时,不与其他槽位共享资源,单独增加额外资源 ###有用的参数
table.exec.split-slot-sharing-group-per-vertex:'true'//Checkpoint间隔时间,单位为毫秒 默认180秒 ###如果作业量大,可以适当调大间隔时间。性能方便略有提升
execution.checkpointing.interval:180s
//State数据的生命周期,单位为毫秒。默认36小时
table.exec.state.ttl:129600000//Checkpoint生成超时时间(默认值10分钟),当Checkpoint生成时间超过10分钟,flink会把创建生成的Checkpoint杀掉,重新再创建生成Checkpoint。如果观察自己的job生成时间过长减少被杀死Checkpoint可以调大下面时间 ###有用的参数
execution.checkpointing.timeout :10min
- datastream代码配置
// 初始化 table environmentTableEnvironment tEnv =...// 获取 tableEnv 的配置对象Configuration configuration = tEnv.getConfig().getConfiguration();// 设置参数:// 开启 miniBatch
configuration.setString("table.exec.mini-batch.enabled","true");// 批量输出的间隔时间
configuration.setString("table.exec.mini-batch.allow-latency","5 s");// 防止 OOM 设置每个批次最多缓存数据的条数,可以设为 2 万条
configuration.setString("table.exec.mini-batch.size","20000");// 开启 LocalGlobal(job有聚合函数使用)
configuration.setString("table.optimizer.agg-phase-strategy","TWO_PHASE");// 开启 Split Distinct (job有聚合函数使用)
configuration.setString("table.optimizer.distinct-agg.split.enabled","true");// 第一层打散的 bucket 数目 (job有聚合函数使用)
configuration.setString("table.optimizer.distinct-agg.split.bucket-num","1024");// TopN 的缓存条数 (job有分组top使用)
configuration.setString("table.exec.topn.cache-size","200000");// 指定时区
configuration.setString("table.local-time-zone","Asia/Shanghai");
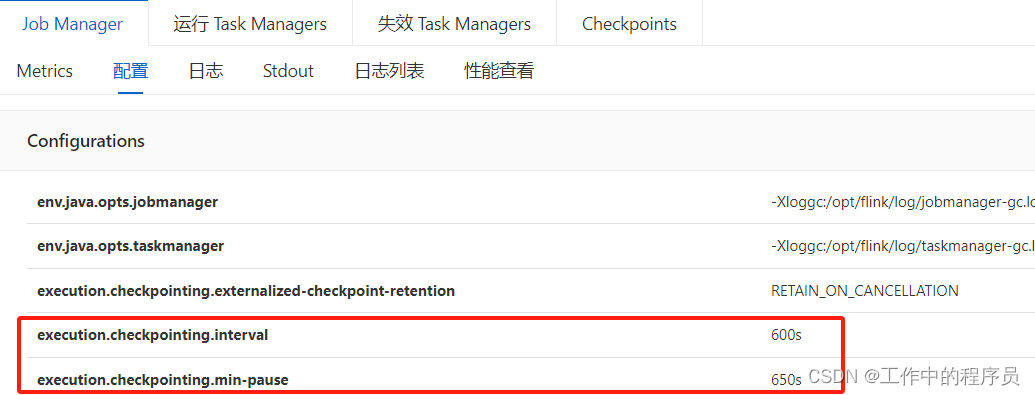
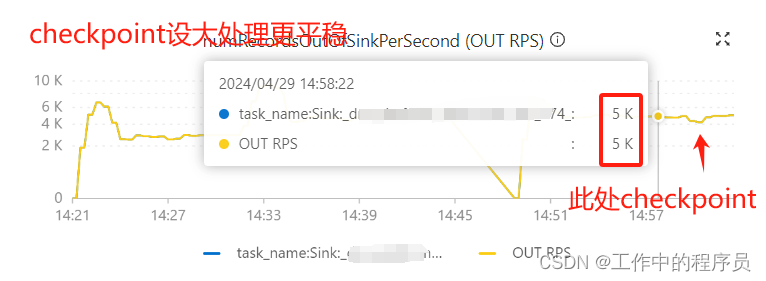
- flink sql 简单作业优化实验截图 1).调大checkpoint生成时间
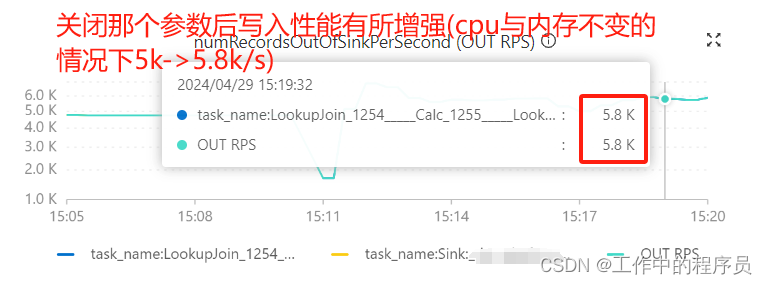
 2).去掉参数:pipeline.operator-chaining: ‘false’
2).去掉参数:pipeline.operator-chaining: ‘false’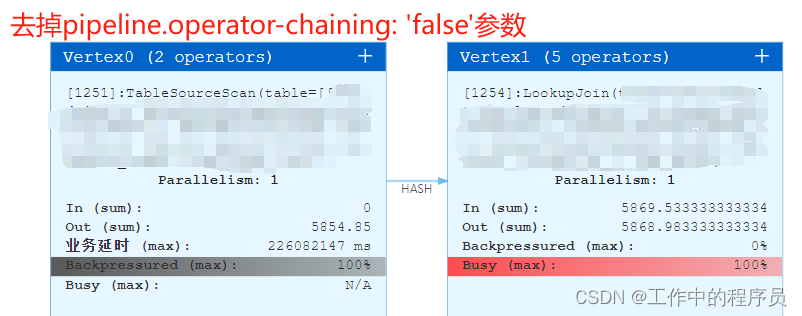
 3).加攒批参数
3).加攒批参数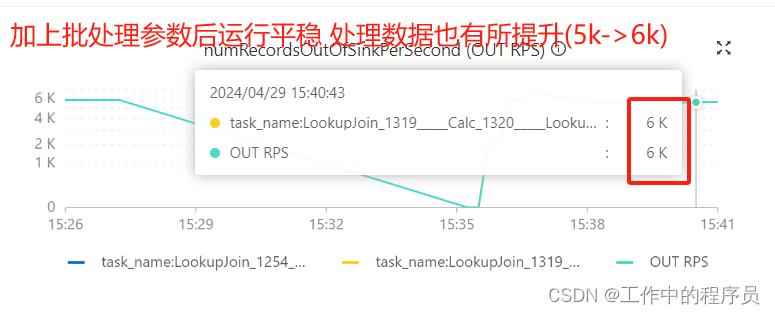
 4).由于full GC导致job性能过差(排查)
4).由于full GC导致job性能过差(排查) 查看gc日志:
查看gc日志: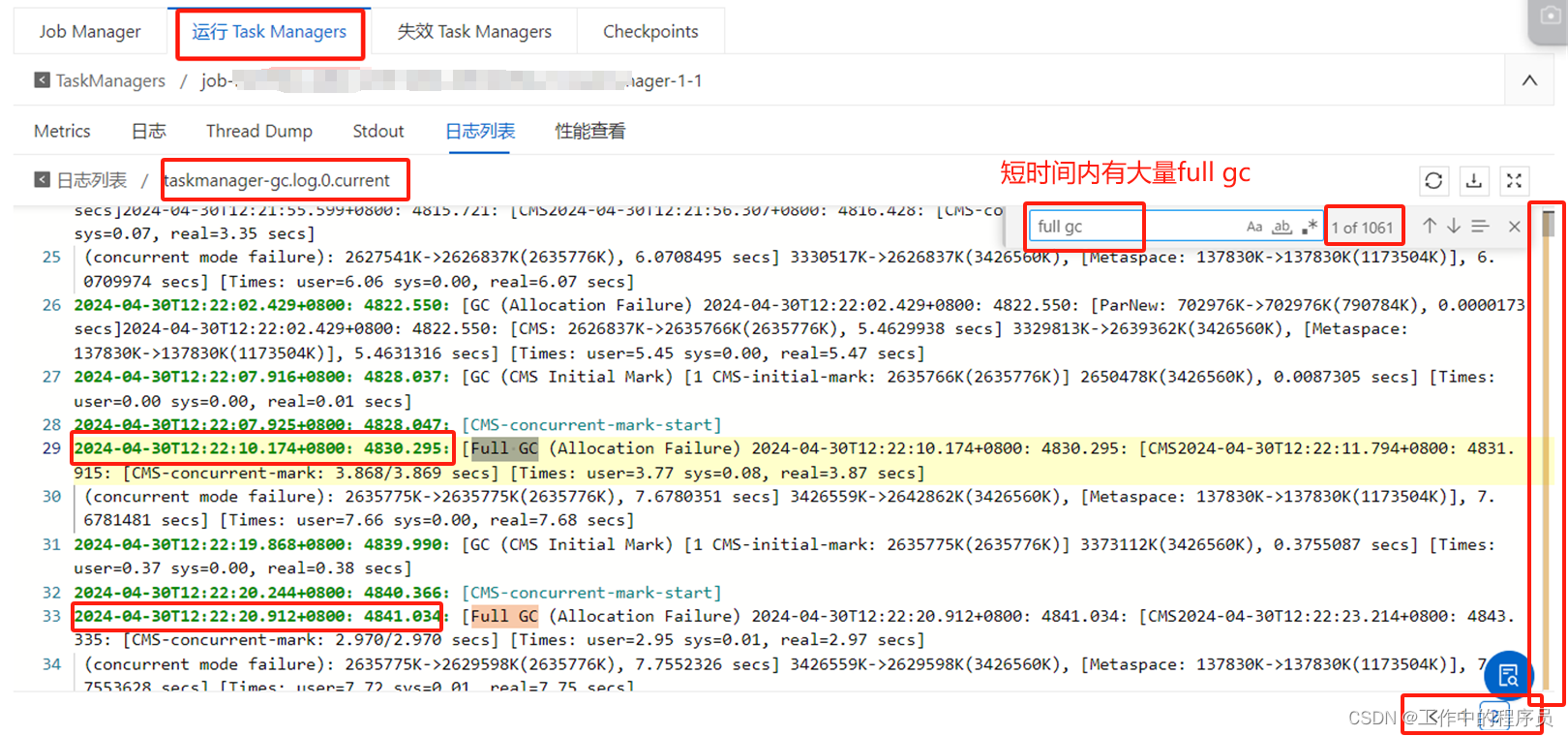
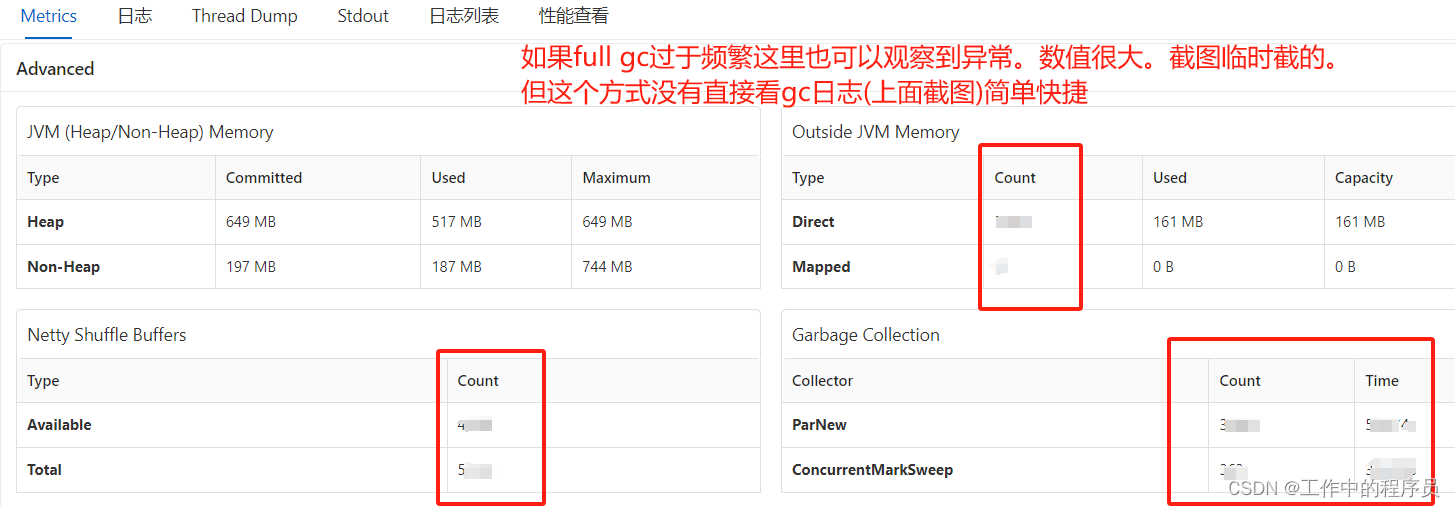 解决方案:对taskmanager增加内存(jobmanager略,因为它很少会出现频繁full gc)。
解决方案:对taskmanager增加内存(jobmanager略,因为它很少会出现频繁full gc)。
5).全量Checkpoint与增量Checkpoint的大小一致,是否正常?
如果您在使用Flink的情况下,观察到全量Checkpoint与增量Checkpoint的大小一致:
- 检查增量快照是否正常配置并生效。
- 是否为特定情况。在特定情况下,这种现象是正常的,例如: a.在数据注入前(18:29之前),作业没有处理任何数据,此时Checkpoint只包含了初始化的源(Source)状态信息。由于没有其他状态数据,此时的Checkpoint实际上是一个全量Checkpoint。 b.在18:29时注入了100万条数据。假设数据在接下来的Checkpoint间隔时间(3分钟)内被完全处理,并且期间没有其他数据注入,此时发生的第一个增量Checkpoint将会包含这100万条数据产生的所有状态信息。 在这种情况下,全量Checkpoint和增量Checkpoint的大小一致是符合预期的。因为第一个增量Checkpoint需要包含全量数据状态,以确保能够从该点恢复整个状态,导致它实际上也是一个全量Checkpoint。
增量Checkpoint通常是从第二个Checkpoint开始体现出来的,在数据稳定输入且没有大规模的状态变更时,后续的增量Checkpoint应该显示出大小上的差异,表明系统正常地只对状态的增量部分进行快照。如果仍然一致,则需要进一步审查系统状态和行为,确认是否存在问题。
二、资源方面
当上面添加配置性能还是不行是,可以增加资源。
- 添加cu 一般对taskmanager添加cup,默认给1的整数倍,例如1,2,3等。jobmanager 基本不咋干活(业务数据处理),不用添加资源,之前给很少cup即可
- 添加内存 一般默认每个taskmanager给4G内存,后面再对它增加资源。jobmanager不用增加内存
- 槽位(slot) 每个 TaskManager Slot 数给1个( TaskManager 只能同时执行一个 Subtask),性能比较好(一般简单的job没有大量的回撤流的情况下)。 A.如果开3个并行度,每个taskmanager1个槽位:1个槽位 乘 3个并行度 乘 每个taskmanager分配的资源+job manager资源=job的总使用资源 B.如果开3个并行度,每个taskmanager3个槽位:1个槽位 乘 每个taskmanager分配的资源+job manager资源=job的总使用资源
- 并行度 在 TaskManager Slot 数给1个情况下(此方案性能比较好),增加并行度可以提升处理性能。但taskmanager资源(内存和cpu)也会成倍增加
*上面只是建议给taskmanager 1cup,4Gb内存起,原因现在很多平台大多是云虚拟资源,这样分配性能较好,同时也是养成良好习惯。
三、总结
不是所有job资源越堆越多好。有时作业的复杂或数据的特殊情况(外部系统性能除外,例如写数据库),增加资源只会让job性能越来越差或报错(亲身经历job性能差,特别痛苦,一直加资源性能还是差或运行报错)。需要不断找根源问题,多使用不同方法测试才能找到适合job的处理性能。
- 如果优化很多次后job性能还是很差(资源给的很多性能还是不理想)(略增加一些资源) 可以将一个job拆分两个job(将占用比较多的业务数据(50%更好)在新的job单独处理)
- 性能优化一直无法提升,要么看业务要么看job的性能瓶颈业务(业务牺牲)
- 要么flink只做业务写表,离线负责处理业务写其他表(时效牺牲)
- 调优举例(真实案例,折腾了很久): 背景:(flink 双流join) 默认资源配置(taskmanager 1cpu,4Bb内存,1个槽位,1个并行度) 数据有堆积,且越堆越多,写入性能弱(每秒十几条写入),CP(checkpoint有时失败,但很大,生成很慢),业务处理简单,单日数量在1700万条数据。
- 后面开始对此job加资源,加并行度,加各种优化配置,增加CP生成时间等等。 开启job运行后生成CP一直失败(生成CP更大,之前200多兆,改后生成700-800兆还没有生成,生成变慢,生成时间变成)
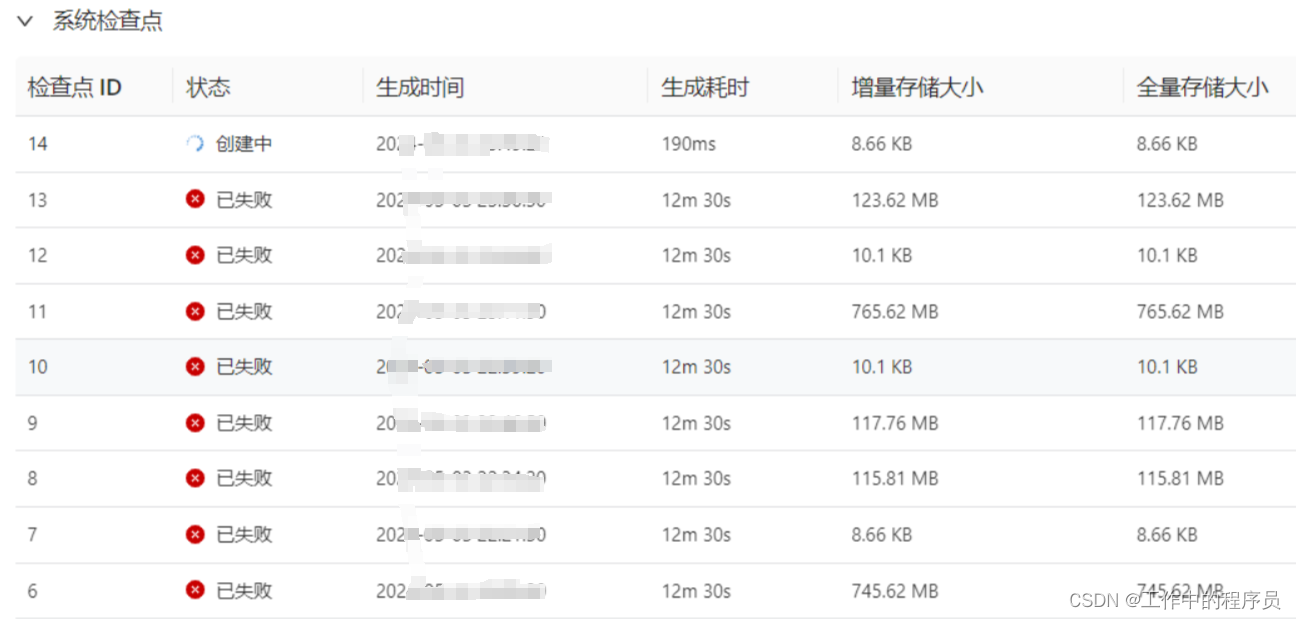 即使加大CP生产时间和CP校验时间,CP依旧是失败。 CP一直失败导致处理性能极差(CP在生成时整个job几乎都在停止),如下截图
即使加大CP生产时间和CP校验时间,CP依旧是失败。 CP一直失败导致处理性能极差(CP在生成时整个job几乎都在停止),如下截图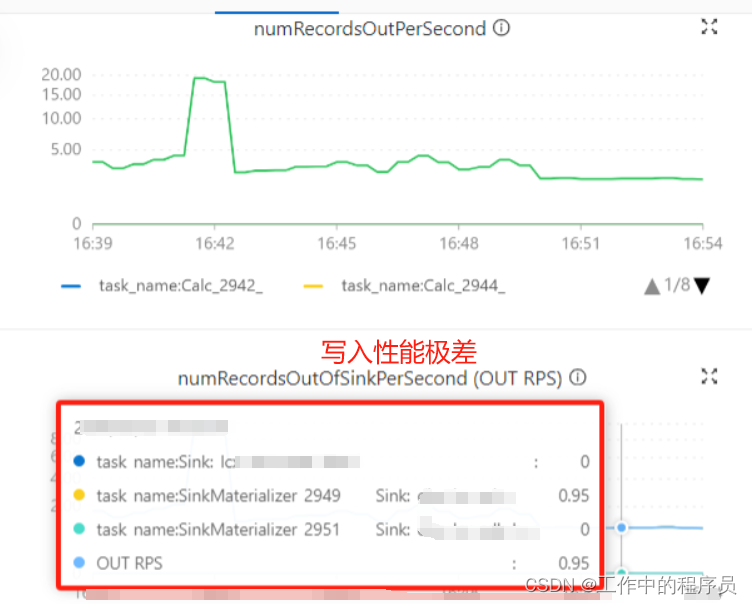 后面是各种调优尝试都不能,发现问题是flink在双流join时,有大量的回撤流.如果撤回数据较多的话 , 就会造成这个节点的state大 从而导致SinkMaterializer节点压力大(自己结合UI监控图观察得到)。
后面是各种调优尝试都不能,发现问题是flink在双流join时,有大量的回撤流.如果撤回数据较多的话 , 就会造成这个节点的state大 从而导致SinkMaterializer节点压力大(自己结合UI监控图观察得到)。 - 后面经过很多次调优将并行度改为3,每个 TaskManager Slot 数 给3个,其他不变,性能有提升,CP生成也变快了
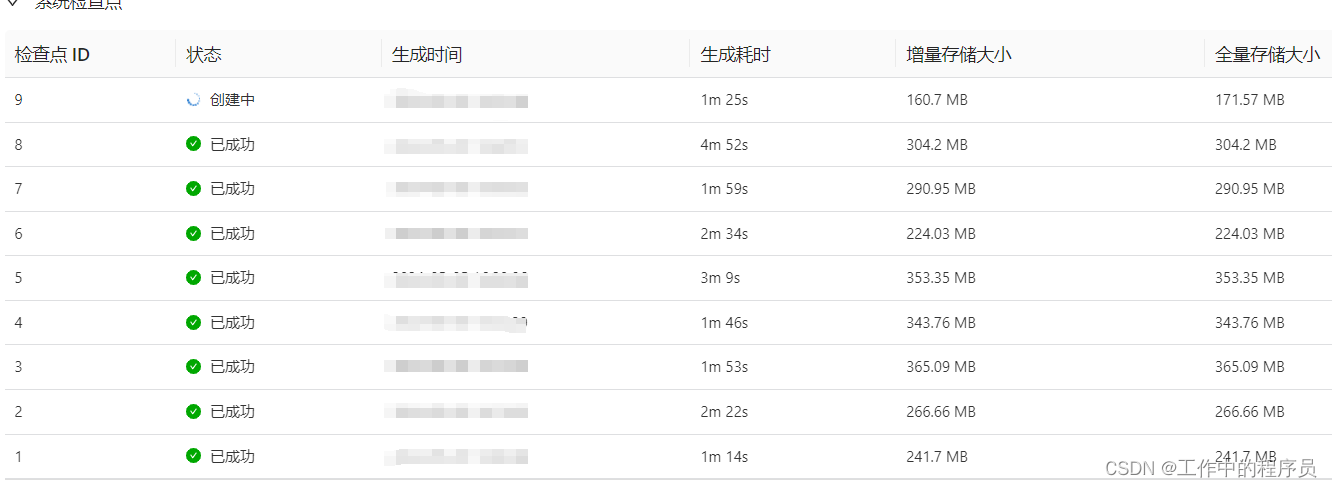
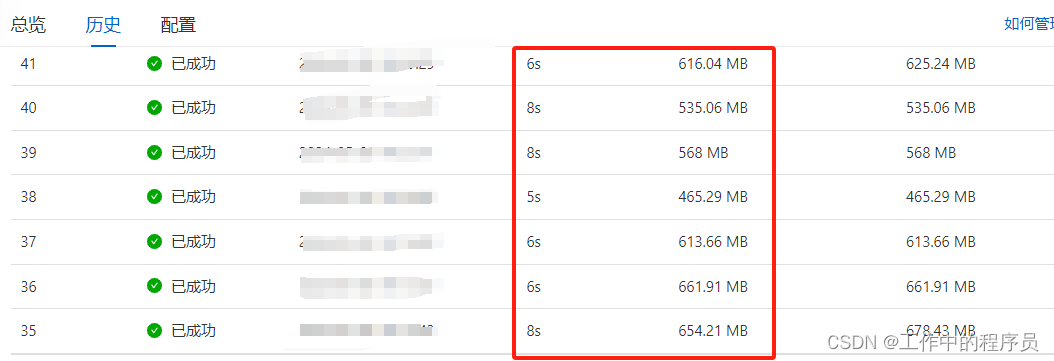
- 又做调整将taskmanager 给3cup,内存给15Gb,开5个并行度,每个 TaskManager Slot 数 给5个。 目的:将5个并行度放到一个槽位,资源也没有使用多少。 测试后发现CP比上面3个并发的增量存储要大(意料之中),CP生成特别快,已将数据堆压十几个小时的数据全部追上。
*上面案例思想:
A.减少CP生成时间。flink才能快速处理数据(提交完已处理的偏移量数据,快速进行下一轮的新数据)。
B.在有回撤流,需要状态(自己观察在一个并发时CP较大几百兆,一般join情况出现的比较多)将多个并发尽量放到一个slot,减少数据传输和交换(一个槽位共享状态)。其他简单的job没有或很少回撤流的情况下可以只建一个槽位。
C.增加并行度会导致CP增大。原因之前一个线程一个CP,现在是多个线程有自己的状态(可能会有重复数据状态),多个状态合在一起CP就大了。
参考:文档1
本文转载自: https://blog.csdn.net/qq_27627985/article/details/138467198
版权归原作者 工作中的程序员 所有, 如有侵权,请联系我们删除。
版权归原作者 工作中的程序员 所有, 如有侵权,请联系我们删除。