
Windows10 Pyspark+Hadoop 环境配置
一、Pyspark运行环境配置
- 安装 Pyspark包:
**pip install pyspark** - 配置PYSPARK_PYTHON环境变量。 💡 配置目的:如果没有配置PYSPARK_PYTHON,运行时会报错:Caused by: org.apache.spark.SparkException: Python worker failed to connect back. 注意这个Python环境是你安装了pyspark模块的Python环境 1. 第一种方法:打开控制台输入如下指令,即可在用户变量配置环境**
SETX PYSPARK_PYTHON "C:\python\python.exe"2. 第二种方法:如下图所示在用户变量添加PYSPARK_PYTHON** 环境变量
二、配置Java运行环境
- 下载JDK安装包;下载路径:jdk17-windows 下载链接;如下图所示我这里选择的是JDK1.7版本
 2. 安装完后配置JAVA_HOME环境变量 1. 第一种方法是通过控制台命令配置: 1. 配置JAVA_HOME环境:
2. 安装完后配置JAVA_HOME环境变量 1. 第一种方法是通过控制台命令配置: 1. 配置JAVA_HOME环境:**SETX JAVA_HOME "C:\Java\jdk-17"2. 配置 %JAVA_HOME%\bin环境:**setx PATH "$env:PATH;$env:JAVA_HOME/bin;"**2. 第二种方法手动去配置,如下图所示 1. 在用户变量区配置JAVA_HOME** 2. 在系统变量区配置**%JAVA_HOME%\bin**
2. 在系统变量区配置**%JAVA_HOME%\bin** 3. 配置完后打开控制输入
3. 配置完后打开控制输入 java -version检查一下是否配置成功,如下返回信息及配置OK。
三、配置Hadoop环境
- 下载Hadoop环境包与Windows 10 补丁包1. Hadoop环境包下载地址:hadoop-3.3.0.tar.gz 下载地址;如下图所示我这里下载的是3.3.0版本
 2. Hadoop 补丁包下载地址:https://github.com/kontext-tech/winutils,如下图所示选择3.3.0版本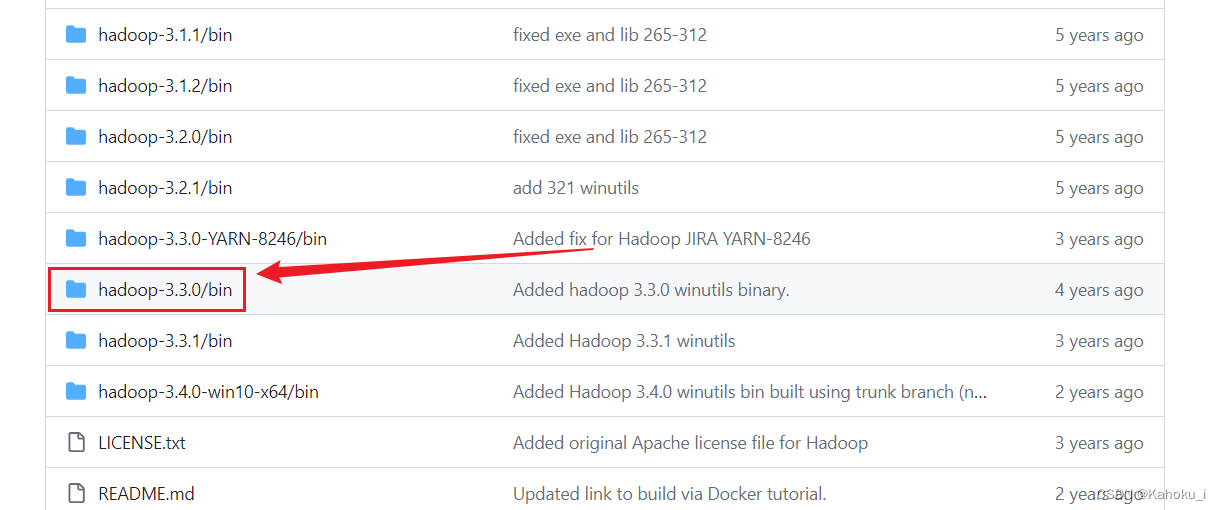
2. Hadoop 补丁包下载地址:https://github.com/kontext-tech/winutils,如下图所示选择3.3.0版本 - 解压下载的hadoop-3.3.0.tar.gz文件 💡 解压过程中可能会有如下报错,忽视即可;

- 这里推荐使用7zip工具解压,工具下载链接:https://www.7-zip.org/;如下图所示点击下载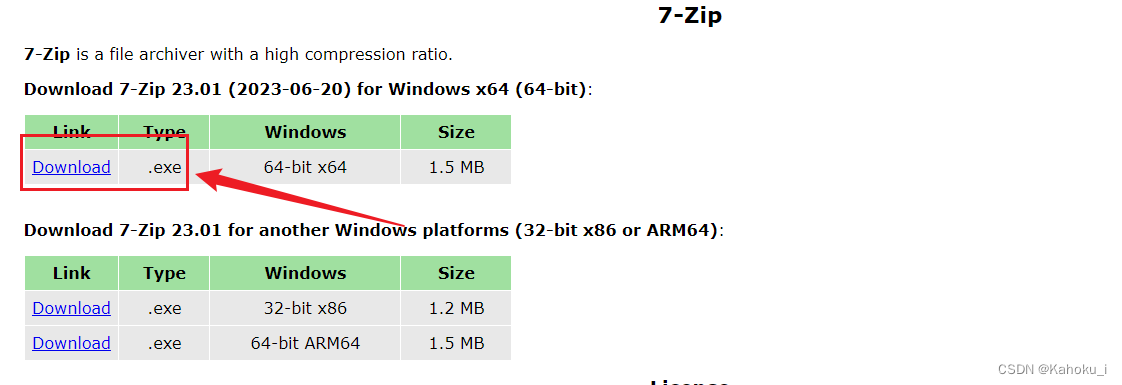
- 7zip的解压方法如下1. 先提取文件为:
 2. 再解压tar文件
2. 再解压tar文件 3. 解压完后目录如下图所示
3. 解压完后目录如下图所示
- 配置HADOOP_HOME环境变量1. 第一种方法是通过控制台命令配置: 1. 配置HADOOP_HOME环境:
**SETX HADOOP_HOME "C:\hadoop-3.3.0"2. 配置 %HADOOP_HOME%\bin环境:**setx PATH "$env:PATH;$env:HADOOP_HOME/bin"**2. 第二种方法是手动配置环境 1. 先配置HADOOP_HOME** 2. 再配置 %HADOOP_HOME%\bin
2. 再配置 %HADOOP_HOME%\bin
- 替换 hadoop-3.3.0中bin文件1. 解压从github上下载的hadoop-3.3.0\bin文件
 2. 将hadoop-3.3.0\bin文件 与hadoop-3.3.0中替换
2. 将hadoop-3.3.0\bin文件 与hadoop-3.3.0中替换
- 找到 hadoop-3.3.0\etc\hadoop目录下的 hadoop-env.cmd,打开并修改里面的JAVA_HOME的路径,替换为你当前的配置的JAVA_HOME路径;如下图所示

- 打开控制台输入
**hadoop -version,**检查环境是否配置成功配置成功如下图所示
四、运行pyspark脚步,检验是环境是否正常
- 调试脚步如下
"""演示RDD的map成员方法的使用"""# -*- coding: utf-8 -*-from pyspark import SparkConf, SparkContext# 创建SparkConf对象,设置本地模式和应用名称conf = SparkConf().setMaster("local[*]").setAppName("sperkconf_test")# 根据配置创建 SparkContext对象sc = SparkContext(conf=conf)# sc.addPyFile(r"C:\Users\EDY\anaconda3\envs\other\python.exe")# 准备一个包含整数的RDDrdd = sc.parallelize([1,2,3,4,5])# 使用lambda表达式定义匿名函数,该函数接受一个参数x并返回x*10的结果# 然后通过map方法将此函数应用到RDD的所有元素上rdd_transformed = rdd.map(lambda x: x *10)# 再次使用lambda表达式定义一个匿名函数,将上一步得到的结果加5# 这样就实现了对RDD中每个元素先乘以10再加5的操作rdd2 = rdd_transformed.map(lambda x: x +5)# 使用collect方法将处理后的RDD结果收集到Driver端并打印print(rdd2.collect())# 在 Windows 中运行 Spark 会出现删除 Spark 临时问题。您可以如下设置将其隐藏。sc.stop() - 运行结果如下图所示
 💡 运行结果如下图报错信息,Spark 运行结束后没有权限删除此路径:C:\Users\EDY\AppData\Local\Temp下文件夹,不影响运行结果忽视即可
💡 运行结果如下图报错信息,Spark 运行结束后没有权限删除此路径:C:\Users\EDY\AppData\Local\Temp下文件夹,不影响运行结果忽视即可

本文转载自: https://blog.csdn.net/qq_39950572/article/details/136260712
版权归原作者 Kahoku_i 所有, 如有侵权,请联系我们删除。
版权归原作者 Kahoku_i 所有, 如有侵权,请联系我们删除。