
Kafka_深入探秘者(10):kafka 监控
一、kafka JMX
1、JMX :全称 Java Managent Extension
- 在实现 Kafka 监控系统的过程中,首先我们要知道监控的数据从哪来,Kafka 自身提供的监控指标(包括 broker 和主题的指标,集群层面的指标通过各个 broker 的指标累加来获取)都可以通过 JMX(Java Managent Extension) 来进行获取。
- 在使用 JMX 之前首先要确保 Kafka 开启了 JMX 的功能(默认是关闭的)。
- kafka 官网中 http://kafka.apache.org/082/documentation.html#monitoring 解释。
2、添加 JMX_PORT=9999 参数,启动 kafka, 确保 kafka 开启了 Jmx 监控
# 切换到 kafka-01 安装目录:
cd /usr/local/kafka/kafka-01/
# 添加 JMX_PORT=9999 参数,启动 kafka, 确保 kafka 开启了 Jmx 监控
JMXPORT-9999 bin/kafka-server-start.sh config/server.properties
# 切换到 kafka-02 安装目录:
cd /usr/local/kafka/kafka-02/
# 添加 JMX_PORT=9988 参数,启动 kafka, 确保 kafka 开启了 Jmx 监控
JMXPORT-9999 bin/kafka-server-start.sh config/server.properties
# 切换到 kafka-03 安装目录:
cd /usr/local/kafka/kafka-03/
# 添加 JMX_PORT=9977 参数,启动 kafka, 确保 kafka 开启了 Jmx 监控
JMXPORT-9999 bin/kafka-server-start.sh config/server.properties
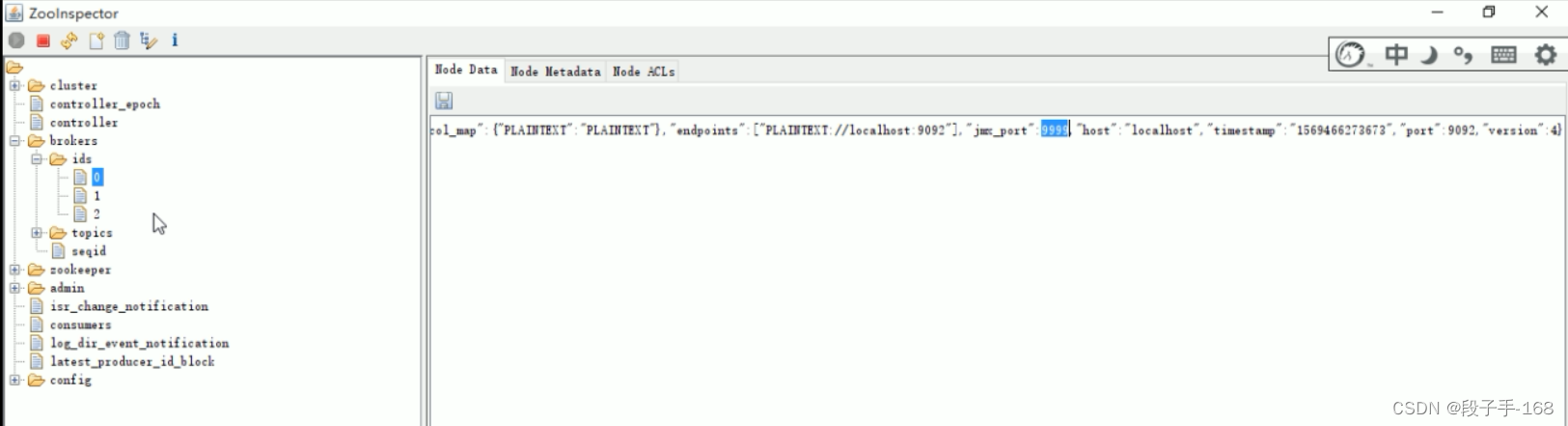
3、打开 ZooInspector 可视化工具,进行查看监控。
开启 JMX 之后会在 Zookeeper 的 /brokers/ids/ 节点中有对应的呈现 (jmx_port字段对应的值)。
二、kafka 编程获取指标
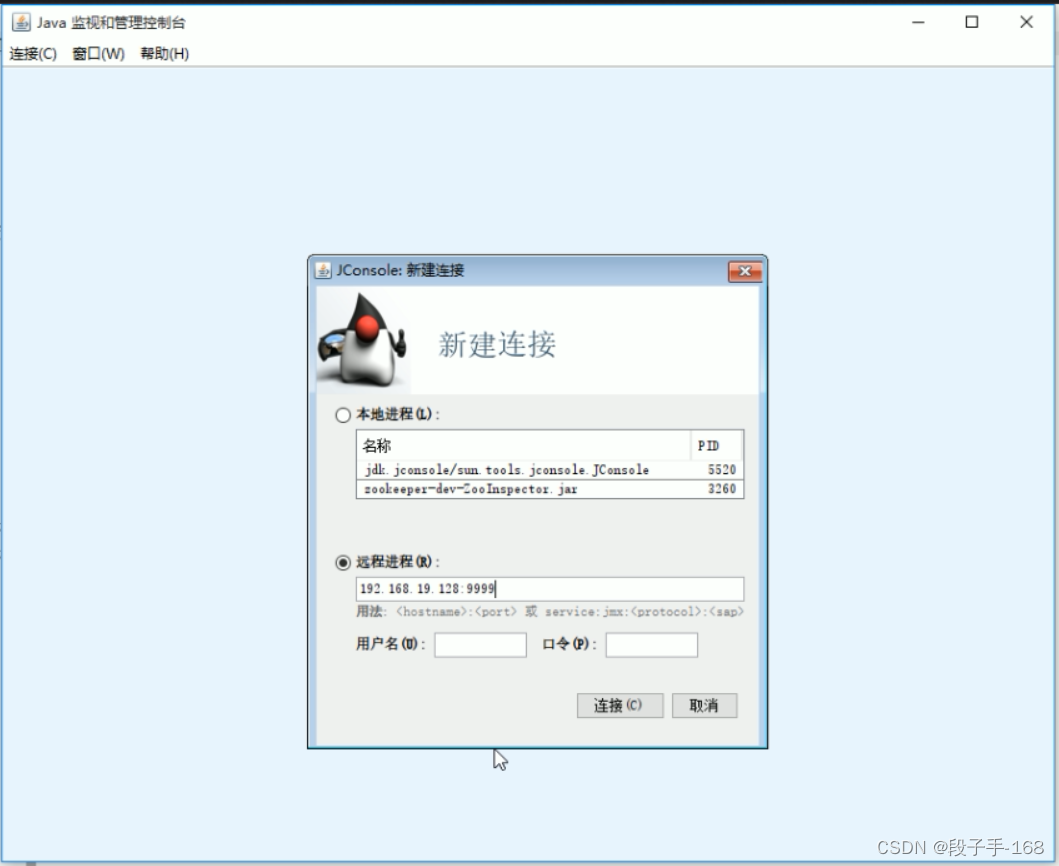
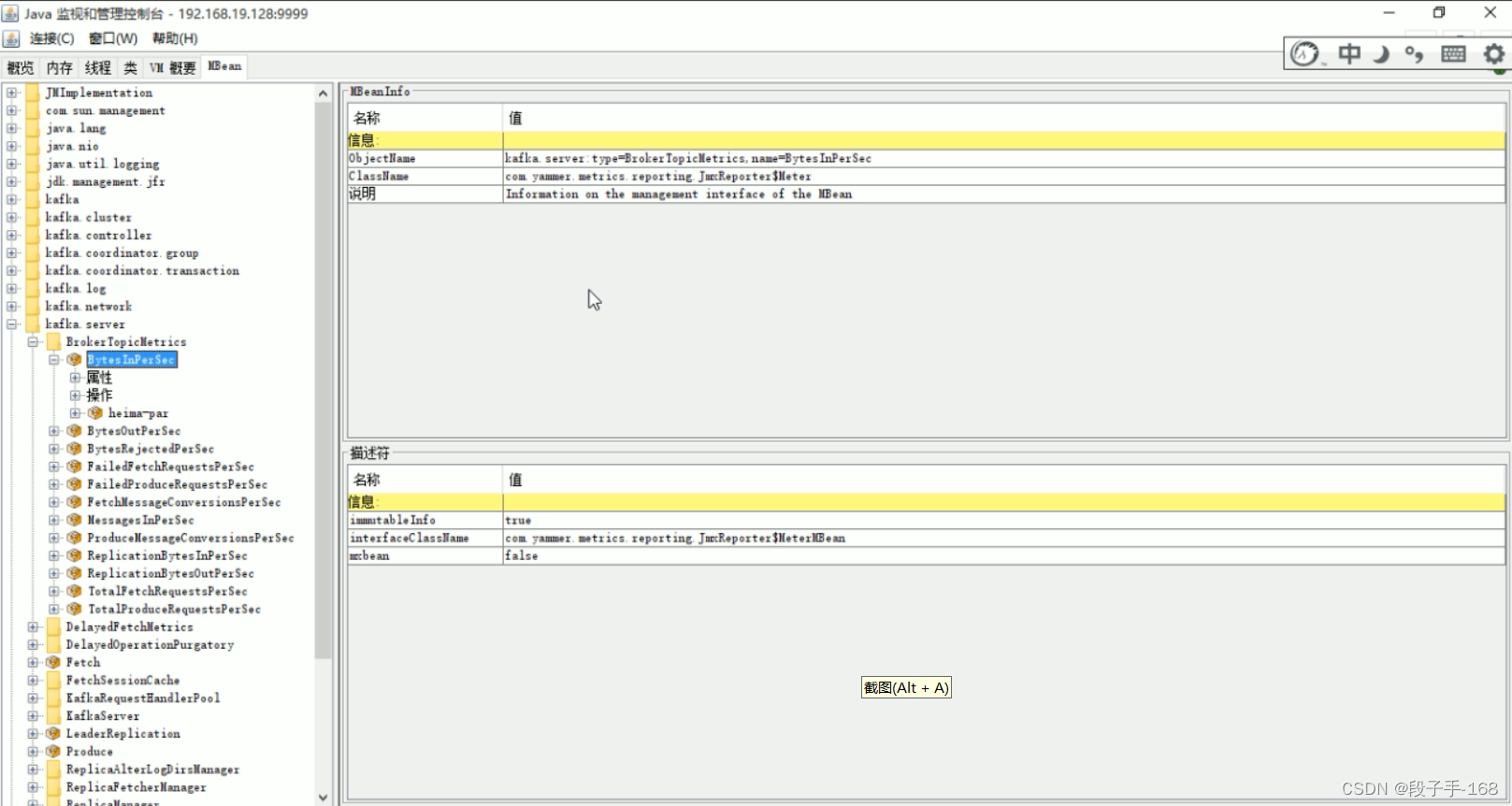
1、jConsole 工具的使用
在开启 JMX 之后最简单的监控指标的方式就是使用 JDK 套件下面的 JConsole 工具,可以通过 jconsole 连接 service:jmx:rmi:///jndi/rmi://localhost:9999/jmxrmi 或者 localhost:9999 来查看相应的数据值。

2、在 kafka_learn 工程模块中,创建 kafka 通过编程获取 kafka 监控指标 类 JmxConnection.java
/**
* kafka_learn\src\main\java\djh\it\kafka\learn\chapter10\JmxConnection.java
*
* 2024-6-27 创建 kafka 通过编程获取 kafka 监控指标 类 JmxConnection.java
*/packagedjh.it.kafka.learn.chapter10;importjavax.management.MBeanServerConnection;importjavax.management.MalformedObjectNameException;importjavax.management.ObjectName;importjavax.management.remote.JMXConnector;importjavax.management.remote.JMXConnectorFactory;importjavax.management.remote.JMXServiceURL;publicclassJmxConnection{privateString ipAndPort;privateString jmxURL;MBeanServerConnection conn =null;publicJmxConnection(String ipAndPort){this.ipAndPort = ipAndPort;}publicbooleaninit(){
jmxURL ="service:jmx:rmi:///jndi/rmi://"+ ipAndPort +"/jmxrmi";try{JMXServiceURL serviceURL =newJMXServiceURL(jmxURL);JMXConnector connector =JMXConnectorFactory.connect(serviceURL,null);
conn = connector.getMBeanServerConnection();if(conn ==null){returnfalse;}}catch(Exception e){
e.printStackTrace();}returntrue;}publicdoublegetMsgInPerSec(){String objectName ="kafka.server:type=BrokerTopicMetrics, name=MessagesInPerSec";try{ObjectName objectName1 =newObjectName(objectName);Object val = conn.getAttribute(objectName1,"OneMinuteRate");if(val !=null){return(double)(Double) val;}}catch(MalformedObjectNameException e){
e.printStackTrace();}return0.0;}publicstaticvoidmain(String[] args){//你的虚拟机IP地址JmxConnection jmxConnection =newJmxConnection("172.18.30.110:9999");
jmxConnection.init();System.out.println(jmxConnection.getMsgInPerSec());}}
3、启动 JmxConnection.java 类,进行测试。
三、kafka 监控指标了解
1、kafka 当中关键监控指标: broker 监控指标
1.1 活跃控制器
该指标表示 broker 是否就是当前的集群控制器,其值可以是0或!。如果是1,表示 broker 就是当前的控制器任何时候,都应该只有一个 broker 是控制器,而且这个 broker 必须一直是集群控制器。如果出现了两个控制器,说明有一个本该退出的控制器线程被阻 塞了,这会导致管理任务无陆正常执行,比如移动分区。为了解决这个问题,需要将这两 个 broker 重启,而且不能通过正常的方式重启,因为此时它们无陆被正常关闭。
# 值区间:0或1
kafka.controller:type=KafkaController,name=ActiveControllerCount
1.2 请求处理器空闲率
Kafka 使用了两个线程地来处理客户端的请求:网络处理器线程池和请求处理器线程池。 网络处理器线程地负责通过网络读入和写出数据。这里没有太多的工作要做,也就是说,不用太过担心这些线程会出现问题。请求处理器线程地负责处理来自客户端的请求,包括从磁盘读取消息和往磁盘写入消息。因此,broker 负载的增长对这个线程池有很大的影响。
kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent
1.3 主题流入字节
主题流入字节速率使用 bis 来表示,在对 broker 接收的生产者客户端悄息流量进行度量时,这个度量指标很有用。该指标可以用于确定何时该对集群进行扩展或开展其他与规模增长 相关的工作。它也可以用于评估一个 broker 是否比集群里的其他 broker 接收了更多的流 量,如果出现了这种情况,就需要对分区进行再均衡。
kafka.server:type-BrokerTopicMetrics,name-BytesInPerSec
- RateUni.t这是速率的时间段,在这里是“秒\这两个属性表明,速率是通过 bis 来表示的,不管它的值是基于多长的时间段算出的平均 值。速率还有其他 4个不同粒度的属性。
- OneMi.nuteRate 前1分钟的平均值。
- Fi.ve问i.nuteRate 前5分钟的平均值。
- Fi.fteenMi.nuteRate 前 15 分钟的平均值。
- MeanRate 从 broker启动到目前为止的平均值。
1.4 主题流出字节
主题流出字节速率与流入字节速率类似,是另一个与规模增长有关的度量指标。流出字节速 率显示的是悄费者从broker读取消,息的速率。流出速率与流入速率的伸缩方式是不一样的,这要归功于 Kafka 对多消费者客户端的支持。
kafka.server:type=BrokerTopicMetrics,name=BytesOutPersec
1.5 主题流入的消息
之前介绍的字节速率以字节的方式来表示 broker 的流量, 而消息速率则以每秒生成消息个 数的方式来表示流量,而且不考虑消息的大小。这也是一个很有用的生产者流量增长规模 度量指标。它也可以与字节速率一起用于
1.6分区数量
broker 的分区数量一般不会经常发生改变,它是指分配给 broker 的分区总数。它包括 broker 的每一个分区副本,不管是首领还是跟随者
kafka.server:type.ReplicaManager,name PartitionCount
1.7 首领数量
该度量指标表示 broker 拥有的首领分区数量。与 broker 的其他度量一样,该度量指标也应 该在整个集群的 broker 上保持均等。我们需要对该指析|进行周期性地检查,井适时地发出 告警,即使在副本的数量和大小看起来都很完美的时候,它仍然能够显示出集群的不均衡 问题。因为 broker 有可能出于各种原因释放掉一个分区的首领身份,比如 Zookeeper 会话 过期,而在会话恢复之后,这个分区并不会自动拿回首领身份(除非启用了自动首领再均 衡功能)。在这些情况下,该度量指标会显示较少的首领分区数,或者直接显示为零。这 个时候需要运行一个默认的副本选举,重新均衡集群的首领。
kafka.server:type=ReplicaManager,name-LeaderCount
2、kafka 主题分区监控指标
broker 的度量指标描述了 broker 的一般行为,除此之外,还有很多主题实例和分区实例的度盘指标。
2.1 主题实例的度量指标
主题实例的度量指标与之前描述的 broker 度量指标非常相似。事实上,它们之间唯一的区 别在于这里指定了主题名称,也就是说,这些度量指标属于某个指定的主题。主题实例的 度量指标数量取决于集群主题的数量,而且用户极有可能不会监控这些度量指标或设置告 警。它们一般提供给客户端使用,客户端依此评估它们对 Kafka 的使用情况,并进行问题 调试。
2.2 分区实例的度量指标
分区实例的度量指标不如主题实例的度量指标那样有用。另外,它们的数量会更加庞大,因为几百个主题就可能包含数千个分区。不过不管怎样,在某些情况下,它们还是有一定用处的。 Partition size 度量指标表示分区当前在磁盘上保留的数据量。
如果把它们组合在一起,就可以表示单个主题保留的数据量,作为客户端配额的依据。同一 个主题的两个不同分区之间的数据量如果存在差异,说明消,息并没有按照生产消息的键 进行均句分布。 LOgsegment count 指标表示保存在磁盘上的日志片段的文件数量,可以与 Partition size 指标结合起来,用于跟踪资糠的使用情况。
3、生产者监控指标
新版本 Kafka 生产者客户端的度量指标经过调整变得更加简洁,只用了少量的 MBean。相 反,之前版本的客户端(不再受支持的版本)使用了大量的 MBean,而且度量指标包含了 大量的细节(提供了大量的百分位和各种移动平均数)。这些度量指标提供了很大的覆盖 面,但这样会让跟踪异常情况变得更加困难。生产者度盐指标的 MBean 名字里都包含了生产者的客户端ID。在下面的示例里,客户端 ID 使用 CLIENTID 表示,brokerID 使用 BROKERID 表示,主题的名字使用 TOPICNAME 表示,
kafka.server:type=BrokerTopicMetrics,name=ProduceMessageConversionsPerSec
kafka.server:type=BrokerTopicMetrics,name=TotalProduceRequestsPerSec
4、消费者监控指标
与新版本的生产者客户端类似,新版本的消费者客户端将大量的度量指标属性塞进了少数 的几个 MBean 里
kafka. consumer:type=consumer-metrics,client-id=CLIENTID
kafka. consumer:type=consumer-metrics,client-id-CLIENTIDkafka, consumer:type=consumer-fetch-manager-metrics,client-id-CLIENTID
5、集群消息监控系统: Kafka Eagle
在开发工作当中,消费 Kafka 集群中的消息时,数据的变动是我们所关心的,当业务并不复杂的前提下,我们可以使用 Kafka 提供的命令工具,配合 Zookeeper 客户端工具,可以很方便的完成我们的工作。随着业务的复杂化,Group 和 Topic 的增加,此时我们使用 Kafka 提供的命令工具,已预感到力不从心,这时候 Kafka 的监控系统此刻便尤为显得重要,我们需要观察消费应用的详情。监控系统业界有很多杰出的开源监控系统。我们在早期,有使用 KafkaMonitor 和 Kafka Manager 等,不过随着业务的快速发展,以及互联网公司特有的一些需求,现有的开源的监控系统在性能、扩展性、和 DEVS 的使用效率方面,已经无法满足了。因此,我们在过去的时间里,从互联网公司的一些需求出发,从各位 DEVS 的使用经验和反馈出发,结合业界的一些开源的 Kafka 消息监控,用监控的一些思考出发,设计开发了现在 Kafka 集群消息监控系统: Kafka Eagle。
四、kafka 小结:
第1章 初识 kafka
第2章 kafka 生产者
第3章 kafka 消费者
第4章 kafka 主题 topic
第5章 kafka 分区
第6章 kafka 物理存储
第7章 kafka 稳定性
第8章 kafka 高级应用
第9章 kafka 集群管理
第10章 kafka 监控
**
上一节关联链接请点击
**
Kafka_深入探秘者(9):kafka 集群管理
版权归原作者 段子手-168 所有, 如有侵权,请联系我们删除。