
一、动静态库链接的几种情况
- 如果我们同时提供动态库和静态库,gcc默认使用的是动态库。如果我们非要使用静态库,要加-static选项。
- 如果我们只提供静态库,那可执行程序没办法,只能对该库进行静态链接,但程序不一定整体式静态链接的。
- 如果我们只提供了动态库而我们要进行静态链接会发生链接错误,程序此时默认只能进行动态链接。
二、理解动态库加载
**我们的动态库默认就是一个磁盘级别的文件****。当我们的程序开始运行时,当程序运行到需要用到库中的实现方法时,库的代码和数据就会被加载到物理内存当中。库的实现方法一定是要跟程序运行起来所形成的进程产生关联的,动态库加载后,会被映射到该进程的地址空间中,准确来说,是先在页表中填写好对应虚拟地址和物理地址之间的映射关系,才被映射到进程地址空间中的共享区中。**
**如果此时另一个进程也要加载该动态库,只需要填写它的页表的映射关系即可,不需要再从磁盘中加载一份动态库代码和数据,如果所需库不在内存中才需要加载。这样就保证了一个动态库最多只在内存中存在一份,大大节省了内存开销。这里的本质就是说其实****所有系统进程中公共的代码和数据,只需要存在一份**。

三、可执行程序的理解
3.1、可执行程序中区域的划分
** 可执行程序本身是有自己的格式信息的。我们的可执行程序在被加载到内存中之前,程序当中本身就有地址,可执行程序的每一行都是被编址的。我们的可执行程序在没有加载之前,也已经基本被按照类别(比如权限,访问属性等),已经将可执行程序划分成了各个区域。**
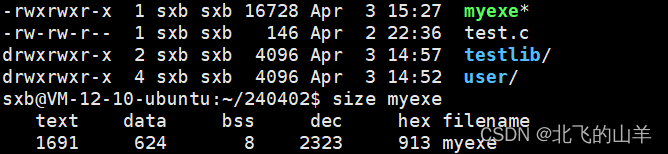
text (或 code):
- 这部分包含了程序的机器代码,即CPU执行的指令。
- 通常,text (或 code)的大小表示了程序中的指令数量。
data:
- 这部分包含了程序中已经初始化的全局变量和静态变量的值。
- data段的大小表示了程序中已初始化数据的大小。
bss:
- 这部分用于存储未初始化的全局变量和静态变量。
- 与 data不同,bss段在程序加载到内存时并不包含实际的数据值,而是只预留了足够的空间。这些变量的初始值通常是0。
dec (decimal):
- 这通常表示某个段或整个程序大小的十进制表示。
- 当你看到dec 值时,它可能是text、data、bss或整个程序大小的十进制表示。
hex (hexadecimal):
- 这表示某个段或整个程序大小的十六进制表示。
- 与 dec类似,hex值可能是 text、data、bss或整个程序大小的十六进制表示。
** 可执行程序中除了上述说到的信息外,****可执行程序的头部信息(表头)包含了关于程序执行所必需的一系列元数据和结构信息****, 头部信息中就保存了main函数的起始地址,所以我们的可执行程序本身就知道要从哪里开始执行。**
3.2、可执行程序的编址
**首先在这里需要跟大家明确一个概念,我们进程地址空间中的很多地址数据,都是从可执行程序中来的。将我们可执行程序中的每一行都以绝对编址的方式进行编址,每一行就对应一个地址,这就相当于我们进程地址空间中的虚拟地址。也就是说,虚拟地址需要我们的操作系统、编译器和计算机体系结构共同配合才能形成。当我们的静态库被我们的可执行程序加载时,静态库的代码就要被写到我们可执行程序text部分,静态库代码在text部分的绝对编址是确定的,当然静态库数据的编址也是确定的。**
3.3、理解动态库动态链接和加载
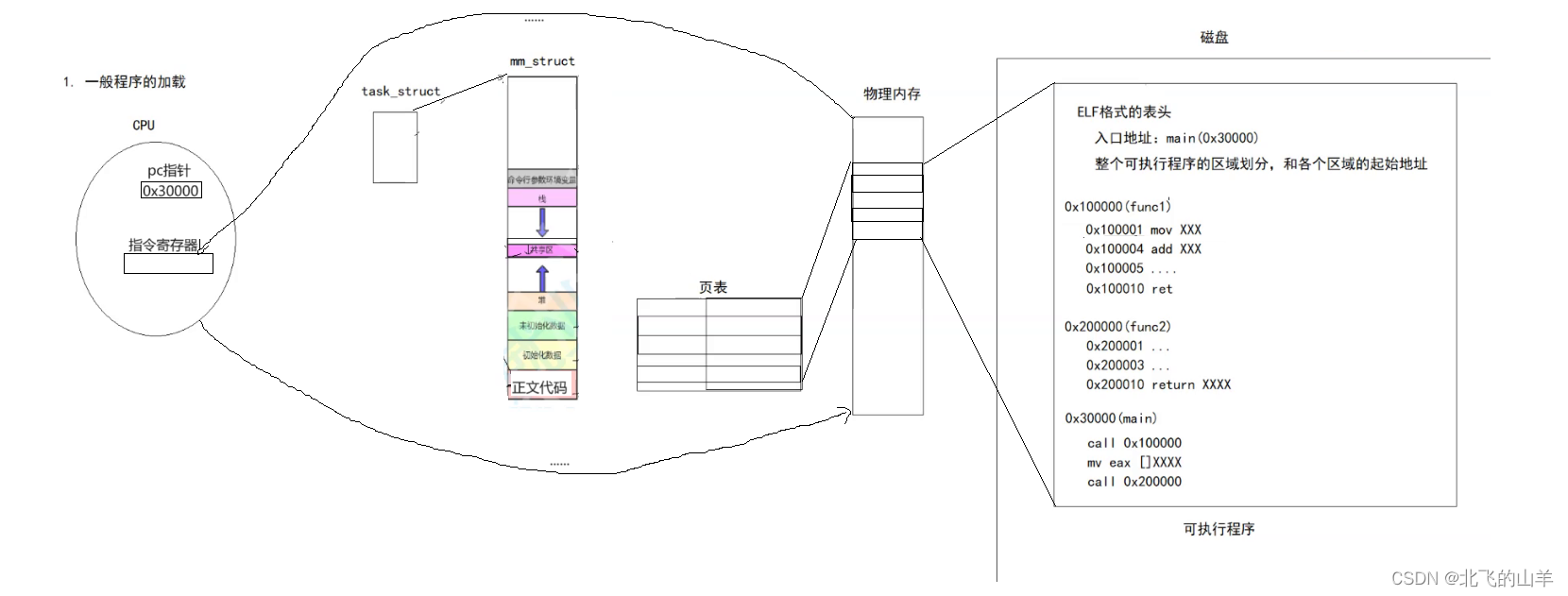
**在进程在被创建的时候是要先创建PCB,初始化它对应的进程地址空间,然后再将磁盘中的数据加载到内存的。为了初始化进程地址空间,操作系统读取可执行程序的表头。在磁盘中存放着的可执行程序的表头中就包含了关于程序执行所必需的一系列元数据和结构信息,操作系统通过读取表头中的信息初始化对应地址空间中的正文代码,已初始化数据和未初始化数据,所以我们也就能理解了为什么不同可执行程序加载完进程地址空间中有数据的地址范围不一样了。**
** 当可执行程序的代码和数据加载到内存中时,因为可执行程序的每一行对应一个虚拟地址,加载到内存中又有了一个实际的物理地址,拿着物理地址和虚拟地址操作系统就可以填写页表对应的映射关系了。当这个进程要被CPU调度执行时,CPU的pc指针就保存了main函数的入口地址(pc指针内保存的是虚拟地址),CPU内部可以帮我们读取页表的内容将虚拟地址转换为物理地址,CPU去到相应的物理地址取到指令放到CPU内部的指令寄存器中,通过解析指令完成工作或是指明下一个虚拟地址,再让CPU解析虚拟地址找到物理地址中的内容,这样周而复始,我们的程序就跑起来了。**
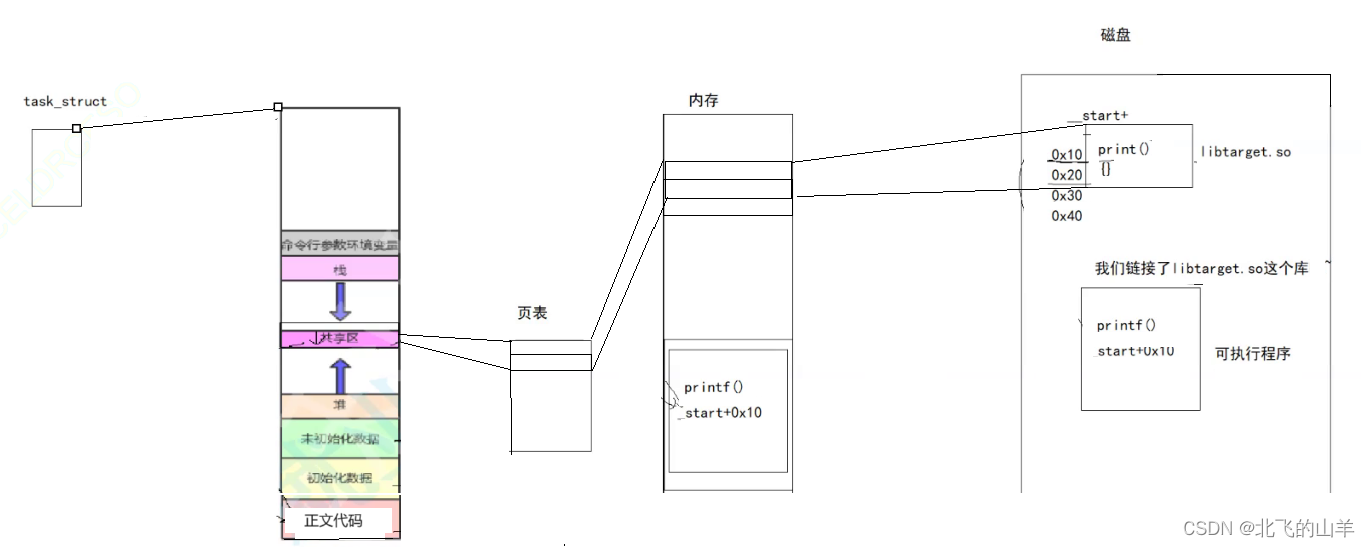
**现在假设我们的可执行程序调用了某一个动态库,在我们程序的就会有这个动态库的调用信息(比如说_start(这里的_start可以看成库名,最后会被转换成库在共享区中的地址)+0x10,print,就是指我们的可执行程序调用了动态库中相对动态库首地址偏移量为0x10处的print函数),可执行程序的表头会记录调用了这个动态库。 我们调用的动态库也是要被加载到内存中的,并被映射到进程地址空间的共享区中。当我们的程序执行到动态库调用处,就会根据动态库首地址加偏移量找到页表中在内存中的物理地址,进而就能调用动态库中的方法了。所以****库中代码和数据的访问,都是可以通过库在地址空间上的起始地址加上我们程序内部的偏移量就可以访问**。
本文转载自: https://blog.csdn.net/m0_74265792/article/details/137358359
版权归原作者 北飞的山羊 所有, 如有侵权,请联系我们删除。
版权归原作者 北飞的山羊 所有, 如有侵权,请联系我们删除。