
** Spark系列文章:**
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
大数据 - Spark系列《八》- 闭包引用-CSDN博客
大数据 - Spark系列《九》- 广播变量-CSDN博客
大数据 - Spark系列《十》- rdd缓存详解-CSDN博客
1. 简介
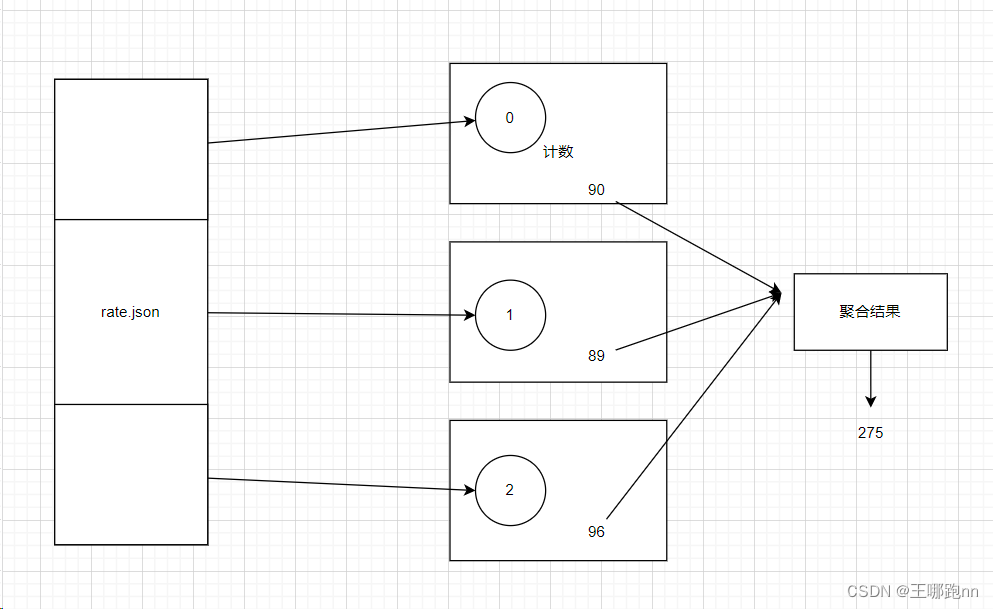 累加器用来把Executor端变量信息聚合到Driver端。在 Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回 Driver端进行merge。
累加器用来把Executor端变量信息聚合到Driver端。在 Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回 Driver端进行merge。
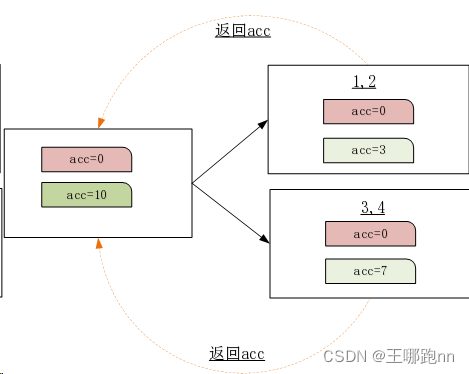
观察一个问题: 原因是数据在executor端执行完毕以后并没有将acc结果数据返回
def main(args: Array[String]): Unit = {
val sc: SparkContext = SparkUtil.getSc
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4),2)
var count:Long = 0L
//rdd.map(count+=_)
rdd.foreach(num=>{count+=num})
//计算的结果为0
println(count)
sc.stop()
}

解决方案:应该将每个executor执行的结果数据返回到Driver端进行聚合操作 , 返回最终结果数据
2. LongAccumulator
LongAccumulator
是 Spark 中的一种累加器(Accumulator)类型,用于在分布式计算中对长整型(Long)类型的数据进行累加。累加器是一种特殊的共享变量,它可以在各个节点上对其进行添加操作,并将结果汇总到驱动器程序中。
2.1 🥙主要特点:
- 分布式累加器:
LongAccumulator可以在不同节点上的任务中并行地对其进行添加操作,然后将结果汇总到驱动器程序中。 - 长整型数据类型: 适用于对长整型数据进行累加的场景,如计数器、求和等。
- 只支持累加操作:
LongAccumulator只支持累加操作,不能进行减法或其他运算。 - 原子性操作: 对累加器的操作是原子性的,可以保证在并发执行的情况下不会发生数据错误。
package com.doit.day0219
import com.alibaba.fastjson.JSON
import com.doit.day0126.Movie
import org.apache.spark.{SparkConf, SparkContext}
/**
* @日期: 2024/2/20
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description: 使用 Spark 累加器统计解析 JSON 数据失败的次数
*/
object Test02 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
// 从文件加载 JSON 数据
val rdd1 = sc.textFile("Data/movie.json")
// 定义计数器变量
//var cnt = 0
// 使用 spark 内置的全局计数器
val cnt1 = sc.longAccumulator("my long Accumulator") // 合并
// 遍历 RDD 中的每一行数据
rdd1.foreach(line => {
try {
// 尝试解析 JSON 数据
val bean = JSON.parseObject(line, classOf[Movie])
println(bean)
} catch {
case e: Exception => {
// JSON 解析失败,增加计数器
cnt1.add(1) // 计数1
}
}
})
// 打印累加器的值,即解析失败的次数
println(cnt1.value) // 合并后的结果
}
}

2.2 🥙注意事项:
- 累加器数据属于全局变量 ,由行动算子触发执行 , 没有触发不执行累加 没算
- 如果多次触发行动算子 , 累加器会执行多次
- 建议将累加器的变化操作编写在行动算子中
2.3 🥙累加器方法
add(value: T)
向累加器中添加一个值,将这个值与累加器中已有的值进行累加。累加器的值类型必须与添加的值类型相符合。
package com.doit.day0219
import com.alibaba.fastjson.JSON
import com.doit.day0126.Movie
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @日期: 2024/2/20
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test05 {
def main(args: Array[String]): Unit = {
// 创建 SparkConf 对象,设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建 SparkContext 对象,传入 SparkConf 对象
val sc = new SparkContext(conf)
val sumAccumulate = sc.longAccumulator("sumAccumulate")
val rdd = sc.parallelize(Seq(1, 2, 3, 4, 5))
rdd.foreach(x=>sumAccumulate.add(x))
println("累加器的值:"+sumAccumulate.value) //15
sc.stop()
}
}
reset()
重置累加器的值为初始值,通常是零或空。
// 重置累加器的值为初始值
accumulator.reset()
value
获取累加器的当前值。
// 获取累加器的当前值
val currentValue = accumulator.value
println("当前累加器的值:" + currentValue)
2.3 🧀实例1
累加器,主要用于正常业务作业过程中的一些附属信息统计
(比如程序遇到的脏数据条数,程序处理的数据总行数,程序处理的特定数据条数,程序处理所花费的时长)
业务上需要对如下数据进行统计:比如统计每个city的用户数
"1,Mr.duan,18,beijing"
"2,Mr.zhao,28,beijing"
"b,Mr.liu,24,shanghai"
"4,Mr.nai,22,shanghai"
"a,Mr.liu,24,shanghai"
"6,Mr.ma"
同时,还想在业务统计的过程中,附带统计出原始数据中的脏数据条数,并按多种不正确的格式进行分别统计,如:id字段无法数字化的条数,字段数量不够的条数,其他不正确的条数
package com.doit.day0219
import com.alibaba.fastjson.JSON
import com.doit.day0126.Movie
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @日期: 2024/2/20
* @作者: Wang NaPao
* @博客: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @描述: 这个对象包含了一个 Spark 应用程序的入口点,用于处理从文件加载 JSON 数据的场景,统计每个城市的用户数量,并且附带统计原始数据中的脏数据条数。
*/
object Test03 {
def main(args: Array[String]): Unit = {
// 创建 SparkConf 对象,设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("Starting...") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
// 创建 SparkContext 对象,传入 SparkConf 对象
val sc = new SparkContext(conf)
// 从文件加载 JSON 数据
val rdd1 = sc.textFile("Data/city.txt")
// 创建一个累加器用于统计脏数据条数
val cnt1 = sc.longAccumulator("dirtyDataCount")
// 对 RDD 进行处理:将每行数据拆分为数组,判断数组长度,若为4则返回 (城市, 1),否则更新累加器并返回 None
val rdd2 = rdd1.map(line => {
try {
val arr1 = line.split(",")
val no = arr1(0).toInt
val name = arr1(1)
val age = arr1(2).toInt
val city = arr1(3)
(city,1)
} catch {
case exception: Exception => {
cnt1.add(1)
("error", 1)
}
}
}).filter(e=>{e._1!="error"}) // 过滤掉脏数据
.reduceByKey(_ + _) // 对相同键的值进行累加
.foreach(println) // 打印结果
// 打印脏数据条数
println("脏数据条数为:" + cnt1.value)
}
}

版权归原作者 王哪跑nn 所有, 如有侵权,请联系我们删除。