
文章目录
一、实战概述
- 在本次实战中,我们任务是在大数据环境下使用Hive进行词频统计。首先,我们在
master虚拟机上创建了一个名为test.txt的文本文件,内容包含一些关键词的句子。接着,我们将该文本文件上传到HDFS的/hivewc/input目录,作为数据源。 - 随后,我们启动了
Hive Metastore服务和Hive客户端,为数据处理做准备。在Hive客户端中,我们创建了一个名为t_word的外部表,该表的结构包含一个字符串类型的word字段,并将其位置设置为HDFS中的/hivewc/input目录。这样,Hive就可以直接读取和处理HDFS中的文本数据。 - 为了进行词频统计,我们编写了一条Hive SQL语句。该语句首先使用
explode和split函数将每个句子拆分为单个单词,然后通过子查询对这些单词进行计数,并按单词进行分组,最终得到每个单词的出现次数。 - 通过执行这条SQL语句,我们成功地完成了词频统计任务,得到了预期的结果。这个过程展示了Hive在大数据处理中的强大能力,尤其是对于文本数据的分析和处理。同时,我们也注意到了在使用Hive时的一些细节,如子查询需要取别名等,这些经验将对今后的数据处理工作有所帮助。
二、提出任务
- 文本文件
test.txt
hello hadoop hello hive
hello hbase hello spark
we will learn hadoop
we will learn hive
we love hadoop spark
- 进行词频统计,结果如下
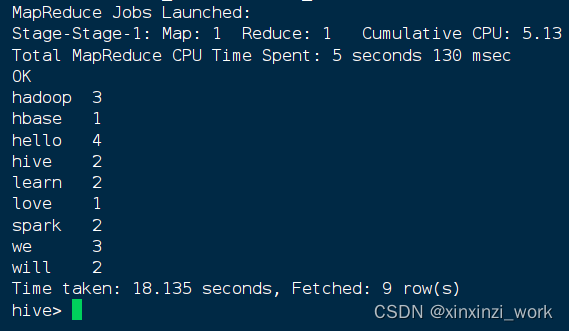
hadoop 3
hbase 1
hello 4
hive 2
learn 2
love 1
spark 2
we 3
will 2
三、完成任务
(一)准备数据文件
1、在虚拟机上创建文本文件
- 在
master虚拟机上创建test.txt文件
2、将文本文件上传到HDFS指定目录
- 在HDFS上创建
/hivewc/input目录 在这里插入图片描述

- 将
test.txt文件上传到HDFS的/hivewc/input目录
(二)实现步骤
1、启动Hive Metastore服务
- 我们需要启动Hive Metastore服务,这是Hive的元数据存储服务。
- 执行命令:
hive --service metastore &
2、启动Hive客户端
- 执行命令:
cd /opt/hive - 再
bin/hive这是我的hive启动方式,有可能你们的方式不一样 - 一旦我们看到命令提示符
hive>,就表示我们已经成功进入Hive客户端。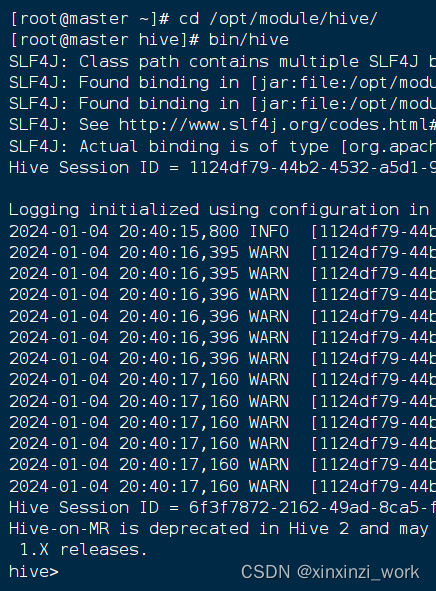
3、基于HDFS文件创建外部表
- 基于
/hivewc/input下的文件创建外部表t_word,执行命令:CREATE EXTERNAL TABLE t_word(word string) LOCATION '/hivewc/input';
- 我这个是已经创建了的,显示ok就行。
- 在MySQL的
hive数据库的TBLS表里,我们可以查看外部表t_word对应的记录。
加载成绩数据文件到内部表t_score,执行命令:
load data inpath '/hivewc/input/test.txt' into table t_word;

4、查询单词表,所有单词成一列
- 查看单词表记录,执行语句:
SELECT word FROM t_word;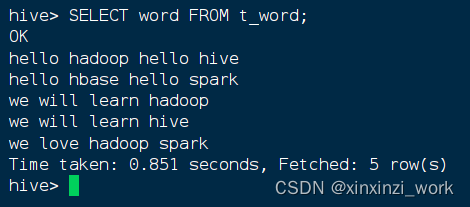
- 按空格拆分行数据,执行语句:
SELECT split(word, ' ') FROM t_word;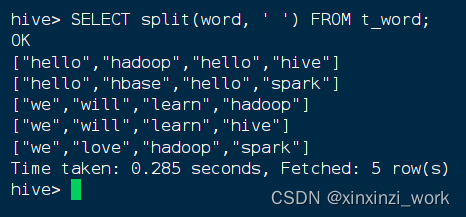
- 让单词成一列,执行语句:
SELECT explode(split(word, ' ')) AS word FROM t_word;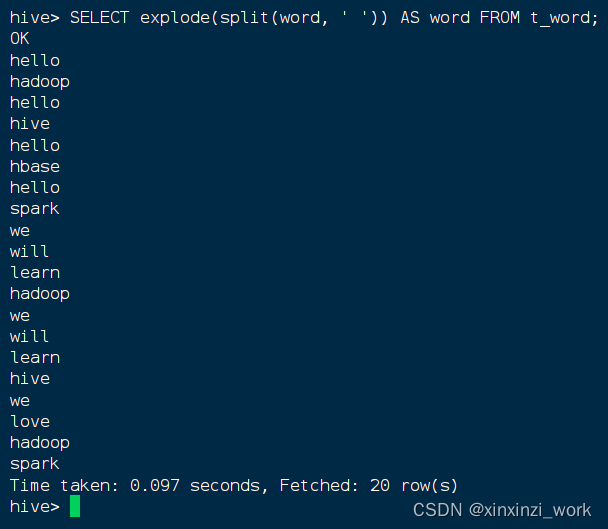
5、基于查询结果创建视图
- 基于查询结果创建了一个视图
v_word,执行语句:CREATE VIEW v_word AS SELECT explode(split(word, ' ')) AS word FROM t_word;
- 我这个表已经存在,你们显示ok就行
- 查询视图的全部记录,执行语句:
SELECT word FROM v_word;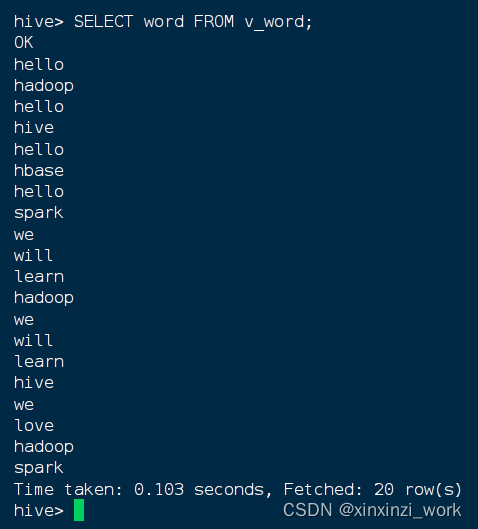
6、基于视图进行分组统计
- 基于视图分组统计操作,执行语句:
SELECT word, COUNT(*) FROM v_word GROUP BY word;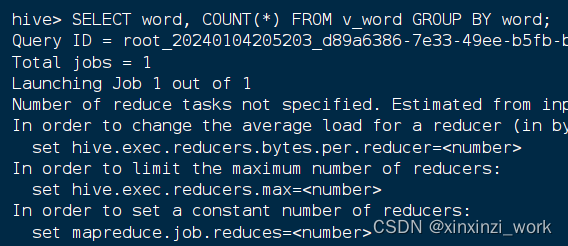
7、基于嵌套查询一步搞定
- 为了更简便地实现相同的效果,使用嵌套查询:
SELECT word, COUNT(*) FROM (SELECT explode(split(word, ' ')) AS word FROM t_word) AS v_word GROUP BY word;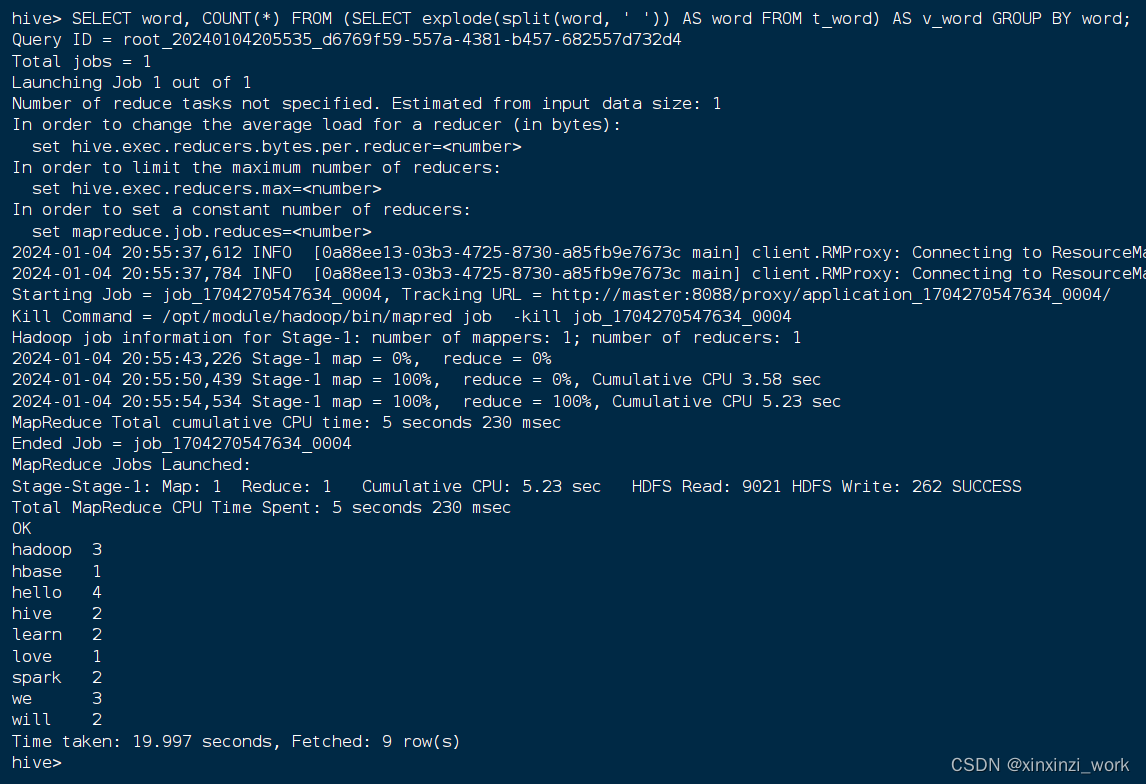
- 注意,这里在嵌套查询中,我们为子查询取了一个别名,这个别名是v_word。
- 这条SQL语句是在处理一个名为
t_word的表,该表中有一个word字段,该字段存储的是由空格分隔的单词字符串。 - 首先,使用
explode(split(word, ' ')) AS word从t_word表中的每一行word字段创建一个新的临时表(别名v_word)。这里split(word, ' ')函数将每个word字段的内容按照空格分割成多个单词,并生成一个多行的结果集,每行包含一个单词。 explode函数则将这个分割后的数组转换为多行记录,即每一行对应原字符串中的一个单词。- 然后,通过
GROUP BY word对新生成的临时表v_word中的word字段进行分组,即将所有相同的单词归为一组。 - 最后,使用
COUNT(*)统计每个单词分组的数量,结果将展示每个单词及其在原始数据集中出现的次数。 - 整个查询的目的在于统计
t_word表中各个单词出现的频率。 - 通过这一系列的操作,我们深入学习了Hive的外部表创建、数据加载、查询、视图创建以及统计分析的操作。希望大家能够在实际应用中灵活运用这些知识。
标签:
hive
本文转载自: https://blog.csdn.net/youxin2024520/article/details/135359881
版权归原作者 xinxinzi_work 所有, 如有侵权,请联系我们删除。
版权归原作者 xinxinzi_work 所有, 如有侵权,请联系我们删除。