
这个是笔者大学时期的大数据课程使用三台CentOS7.6虚拟机搭建完全分布式集群的案例,已成功搭建完全分布式集群,并测试跑实例。
6.安装JDK
以下操作现在master上操作,然后远程复制到slave01、slave02即可。
6.1 将压缩包发送到master节点机器上,并解压
利用WinSCP,将JDK压缩包从windows系统传至master主节点机器上,并将其放于/opt/software目录

注意:将JDK压缩包从windows系统传至master主节点机器上,可以使用WinSCP或者Xftp实现发送。
sudo mkdir -p /usr/java
cd /usr/java
sudo tar -zxvf /opt/software/jdk-8u162-linux-x64.tar.gz -C /usr/java/
#将jdk解压到/usr/java/下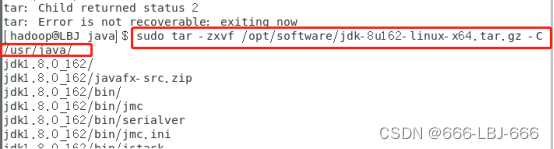
6.2 master配置/etc/profile文件
sudo vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_162
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
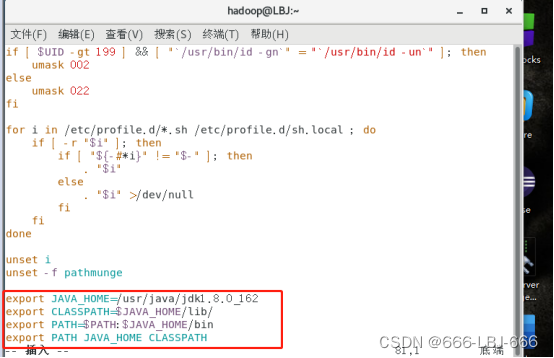
修改环境变量配置文件后,需要是配置文件生效
source /etc/profile

查看jdk版本
java -version

6.3 master配置/etc/profile文件
将JDK复制到slave1和slave2中,
sudo scp -r /usr/java root@slave01:/usr/
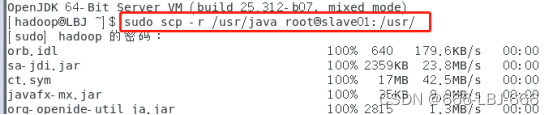
sudo scp -r /usr/java root@slave02:/usr/

在slave1和slave2上分别配置java的环境变量(即/etc/profile),并使环境变量生效,并
java -version
验证。
sudo vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_162
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
source /etc/profile
java -version
在slave1从节点机器上

在slave2从节点机器上

注意:编写jdk的环境变量时,版本号一定要一致。
7.安装zookeeper
以下操作现在master上操作,然后远程复制到slave01、slave02即可。
7.1创建工作目录
mkdir -p /usr/zookeeper
cd /usr/zookeeper

利用WinSCP,将zookeeper压缩包从windows系统传至master主节点机器上,并将其放于/opt/software目录
sudo cp /home/hadoop/tmp/zookeeper-3.4.10.tar.gz /opt/software/

解压zookeeper到/usr/zookeeper文件夹下
sudo tar -zxvf /opt/software/zookeeper-3.4.10.tar.gz -C /usr/zookeeper
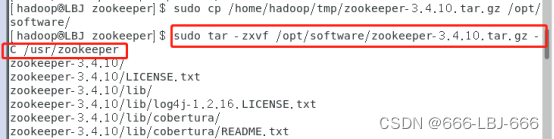
在zookeeper的目录下,创建配置中所需的zkdata和zkdatalog两个文件夹。
cd /usr/zookeeper/zookeeper-3.4.10
sudo mkdir zkdata
sudo mkdir zkdatalog

7.2配置zoo.cfg文件
由于没有zoo.cfg文件,所以进入zookeeper配置文件夹conf,将zoo_sample.cfg文件拷贝一份命名为zoo.cfg,Zookeeper 在启动时会找这个文件作为默认配置文件。
cd /usr/zookeeper/zookeeper-3.4.10/conf/
mv zoo_sample.cfg zoo.cfg

对zoo.cfg文件进行配置:
vim zoo.cfg
修改如下:(红色为增加内容)
tickTime=2000
initLimit=10
syncLimit=5
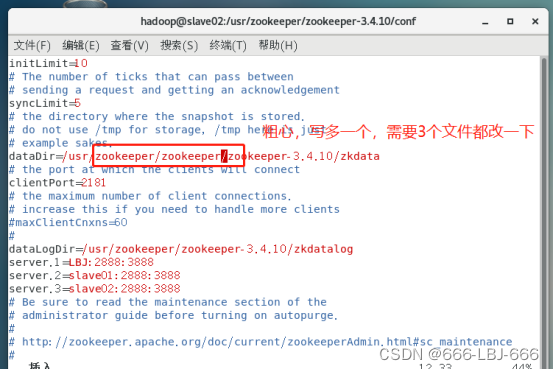
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata
clientPort=2181
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
server.1=LBJ:2888:3888
server.2=slave01:2888:3888
`server.3=slave02:2888:3888``
7.3进入zkdata文件夹,创建文件myid,用于表示是几号服务器
在master主机中,设置服务器id为1。(集群中设置LBJ为1号服务器,slave01为2号服务器,slave02为3号服务器)
cd /usr/zookeeper/zookeeper-3.4.10/zkdata
sudo vim myid


7.4远程复制分发安装文件
配置好的zookeeper,拷贝到集群中的各个结点对应的目录下:
sudo scp -r /usr/zookeeper root@slave01:/usr/
sudo scp -r /usr/zookeeper root@slave02:/usr/


7.5 slave01、slave02设置myid
分别在我们配置的dataDir指定的目录即:zkdata下面,没有myid,自己创建一个myid文件,里面内容为一个数字,用来标识当前主机,这个数字要与zoo.cfg文件中配置的server.x中的x 一一对应。
cd /usr/zookeeper/zookeeper-3.4.10/zkdata
sudo vim myid
在slave01上

在slave02上

7.6 三台机器配置zookeeper环境变量
三台机器同步操作
修改/etc/profile文件,配置zookeeper环境变量。
sudo vim /etc/profile
#zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
在master主节点上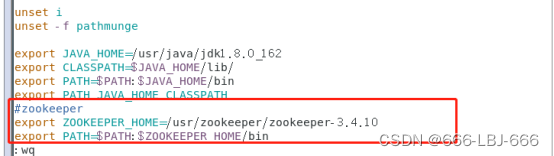
使环境变量生效:
source /etc/profile

在slave01上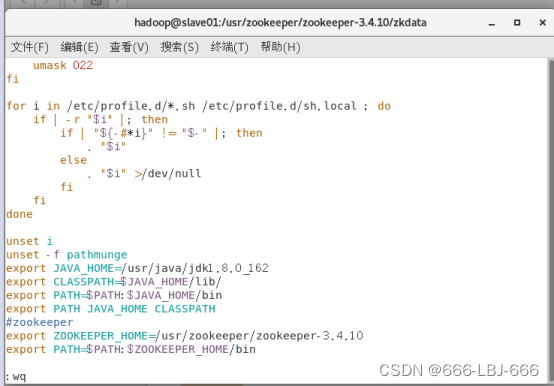

在slave02上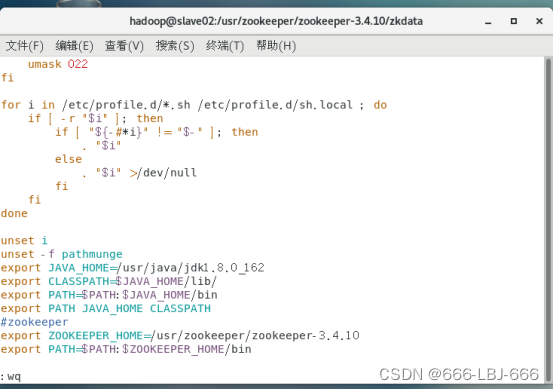

7.7 开启zookeeper集群
三台机器都切换到zookeeper/zookeeper-3.4.10目录下,执行启动zookeeper集群的脚本
cd /usr/zookeeper/zookeeper-3.4.10
bin/zkServer.sh start
#开启zookeeper集群操作
在master上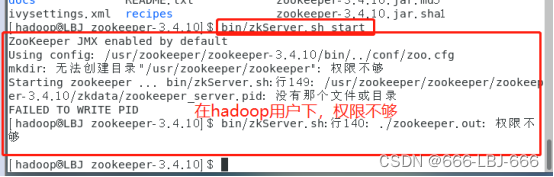
hadoop用户权限不够,需要切换到root用户下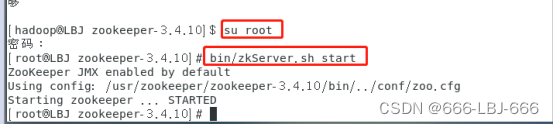
在slave01上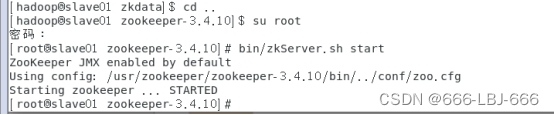
在slave02上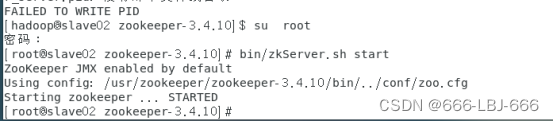
7.8 查看开启zookeeper后三台机器zookeeper集群状态
bin /zkServer.sh status
#查看状态
在master上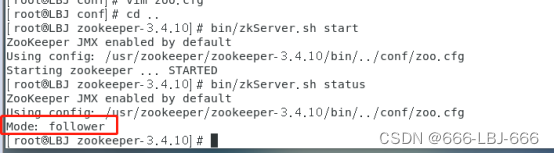
在slave01上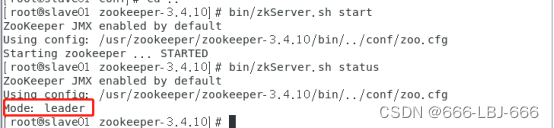
在slave02上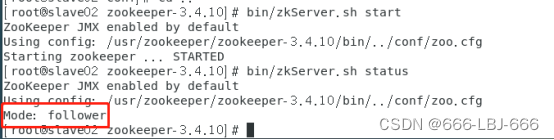
小结:三个节点的zookeeper状态是随机选定的,一个是leader,两个是follower,到这,zookeeper安装成功。
7.9 安装zookeeper遇到问题
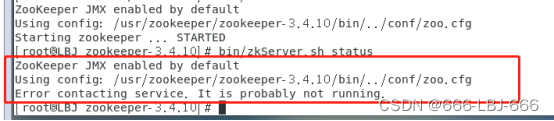
开启zookeeper集群过程中,我遇到了上述问题,我猜想肯定是我的配置文件出错了,所以我回去仔细检查,果然发现了问题,原来我的目录写错了,多了一个zookeeper。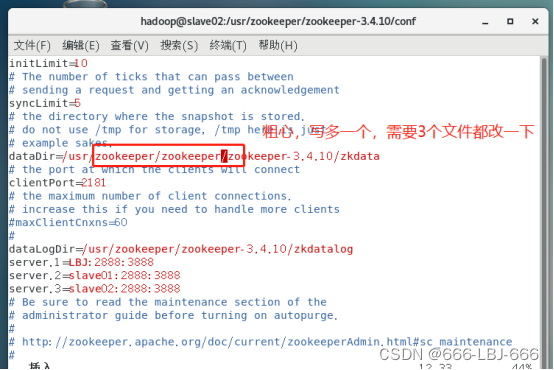
小结:这提醒我们一定要注意配置文件的正确性,少一个字母,多一个字母都不行。
8 安装hadoop集群
温馨提示:在老师和同学们反复建议下,我们最好使用hadoop-2.7.3版本,否则使用的版本过高,后续的操作会不一样,我这里使用的是hadoop-2.7.3版本,后面还要解决hadoop与hive版本的jar包冲突问题。安装hadoop先在master上配置,然后远程复制到slave01或slave02 即可。
8.1 解压hadoop安装包并配置环境变量
使用WinSCP将hadoop-2.7.3的压缩包从windows系统传至master主节点机器上,并放置在/opt/software目录中,同时创建 /usr/hadoop目录,后续将hadoop-2.7.3的压缩包解压到/usr/hadoop 即可。
将hadoop-2.7.3.tar.gz 复制到/opt/software/下
cp /tmp/hadoop-2.7.3.tar.gz /opt/software/

解压到/usr/hadoop
tar -zxvf /opt/software/hadoop-2.7.3.tar.gz -C /usr/hadoop/
配置环境变量
vim /etc/profile
#大多数的环境变量都在这里配置,标明注释,以免混乱
在
/etc/profile
的后面加上:
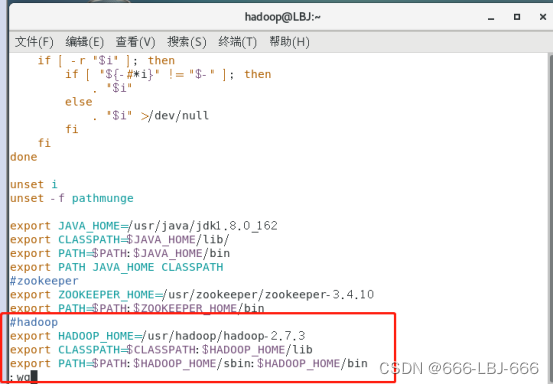
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
配置文件生效:
source /etc/profile
8.2 修改hadoop的各配置文件
配置hadoop的配置文件需要在
$HADOOP_HOME/etc/hadoop
下
cd $HADOOP_HOME/etc/hadoop
8.2.1 修改hadoop的hadoop-env.sh、yarn-env.sh环境配置文件
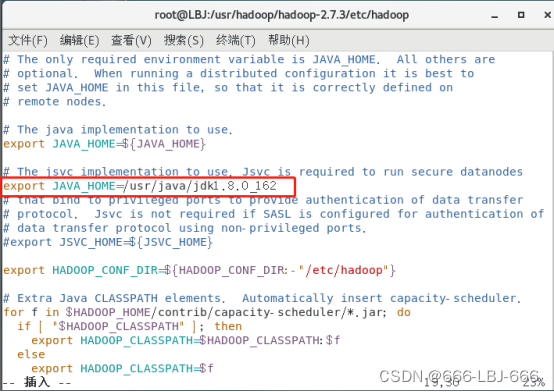
1.修改hadoop的hadoop-env.sh
vim hadoop-env.sh
修改JAVA_HOME内容:
export JAVA_HOME=/usr/java/jdk1.8.0_162
2.修改hadoop的yarn-env.sh
vim yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_162

8.2.2 配置hadoop的配置文件(均为核心文件)
hadoop的各个组件的都是使用XML进行配置,这些文件存放在hadoop的etc/hadoop目录下。
Common组件 core-site.xml
HDFS组件 hdfs-site.xml
MapReduce组件 mapred-site.xml
yarn组件 yarn-site.xml
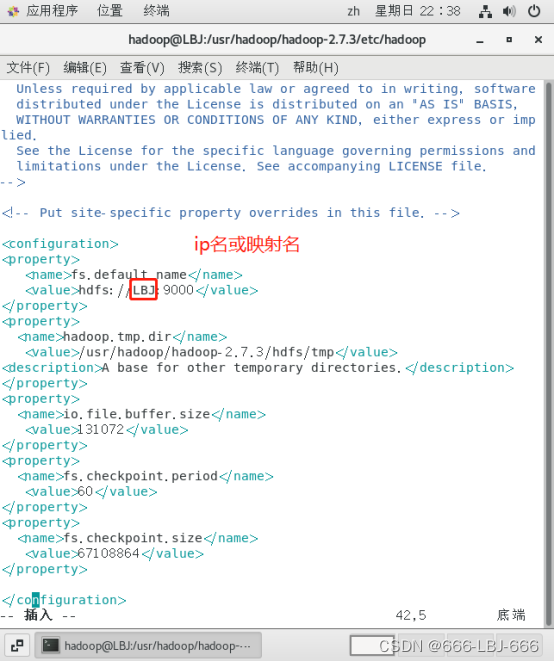
1.编辑 core-site.xml
vim core-site.xml
(节点地址文件名与临时文件地址)
<property><name>fs.default.name</name><value>hdfs://LBJ:9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value><description>A base for other temporary directories.</description></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>fs.checkpoint.period</name><value>60</value></property><property><name>fs.checkpoint.size</name><value>67108864</value></property>
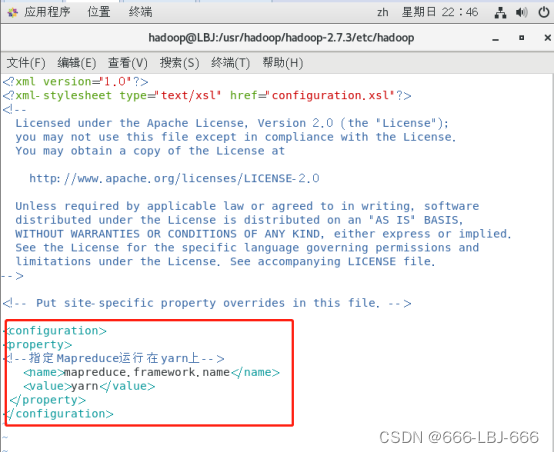
2.编辑 mapred-site.xml
hadoop配置文件中是没有这个文件的,所以需要将mapred-site.xml.template样本文件复制为mapred-site.xml,对其进行编辑: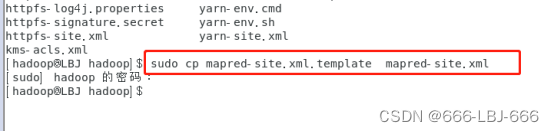
vim mapred-site.xml
<property><!--指定Mapreduce运行在yarn上--><name>mapreduce.framework.name</name><value>yarn</value></property>
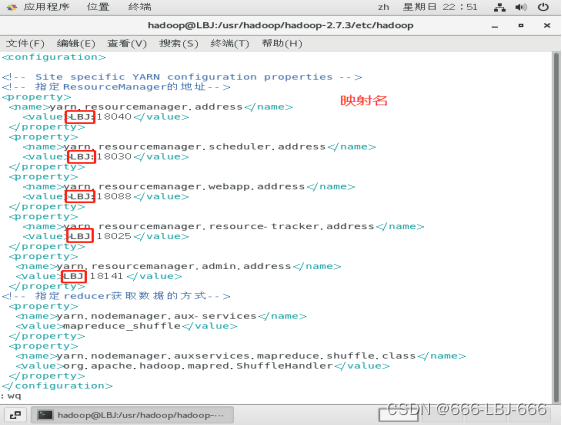
3.编辑 vim yarn-site.xml
vim yarn-site.xml
<!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.address</name><value>LBJ:18040</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>LBJ:18030</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>LBJ:18088</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>LBJ:18025</value></property><property><name>yarn.resourcemanager.admin.address</name><value>LBJ:18141</value></property><!-- 指定reducer获取数据的方式--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><!-- Site specific YARN configuration properties -->
4.编辑 hdfs-site.xml
vim hdfs-site.xml
<property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value><final>true</final></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value><final>true</final></property><property><name>dfs.namenode.secondary.http-address</name><value>LBJ:9001</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property><property><name>dfs.permissions</name><value>false</value></property>
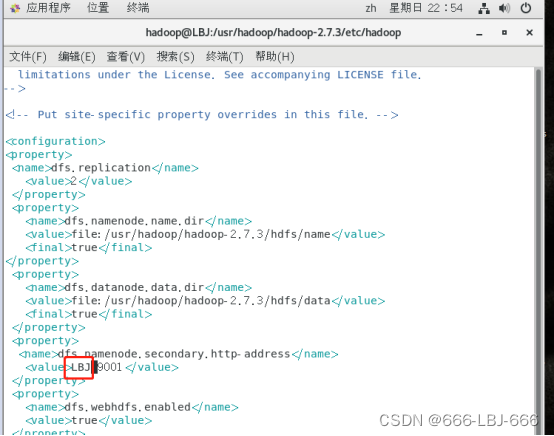
注:dfs.replication:因为hadoop是具有可靠性的,它会备份多个文本,这里value就是指备份的数量(小于等于从节点的数量)。
8.2.3 编辑slaves、master文件
v i slaves
v i master
#如果没有这个该文件创建即可,编辑添加主节点LBJ
注:这里的命令是vi而不是vim,不然会导致子节点启动不起来。
8.2.4 远程分发hadoop给slave01、slave02
sudo scp -r /usr/hadoop root@slave01:/usr/
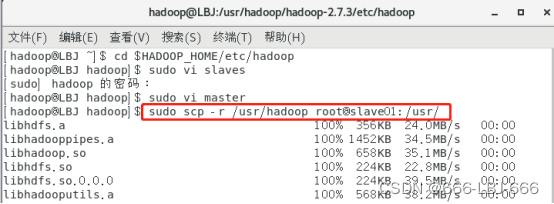
sudo scp -r /usr/hadoop root@slave02:/usr/
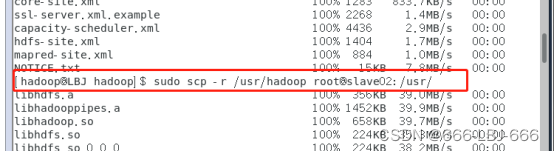
8.2.5 配置slave01、slave02的hadoop环境变量
1.在slave01上
vim /etc/profile
在/etc/profile的末尾添加:
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
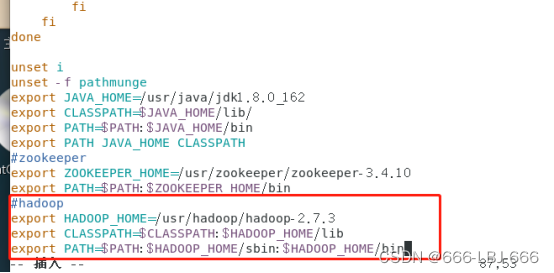
生效:
source /etc/profile
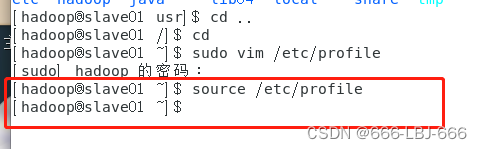
2.在slave02上
vim /etc/profile
在
/etc/profile
的末尾添加:
#hadoop
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export CLASSPATH=$CLASSPATH:$HADOOP_HOME/lib
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
8.3 在主节点上格式化hadoop和开启hadoop,并查看结点状态
注:以下操作,仅在master主节点上进行。
8.3.1格式化hadoop
hadoop namenode -format
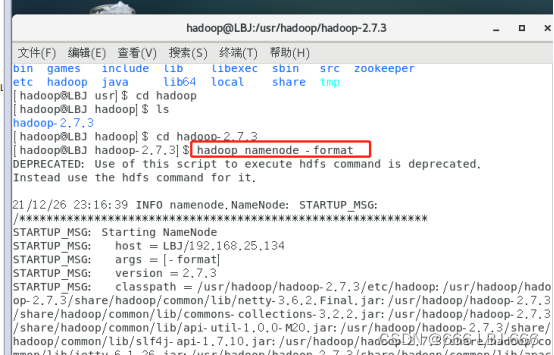
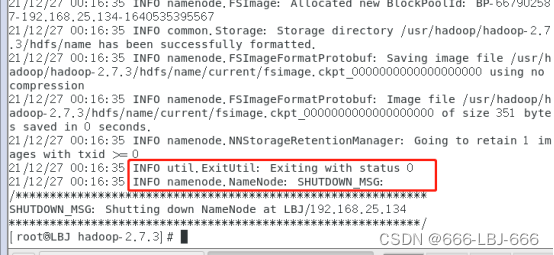
hadoop格式化成功!!!
8.3.2 开启hadoop
在 /usr/hadoop/hadoop-2.7.3下
cd /usr/hadoop/hadoop-2.7.3
开启hadoop
sbin/start-all.sh
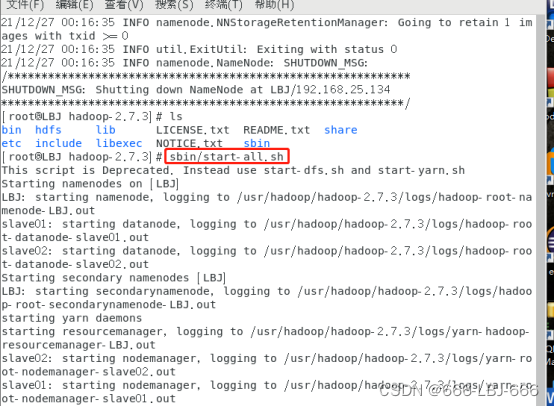
8.3.3 在各主从机上查看hadoop结点的状态
jps
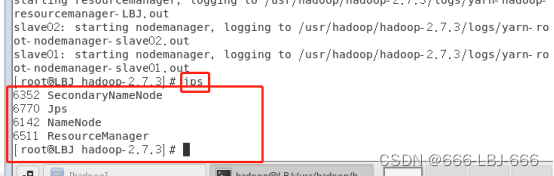
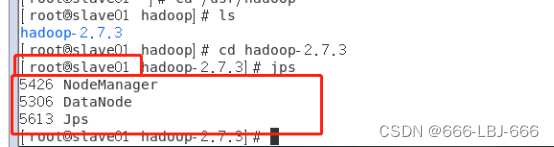
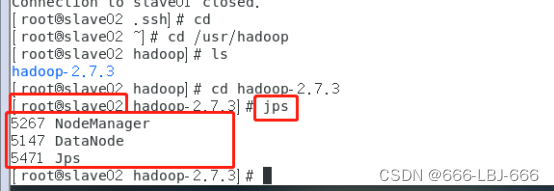
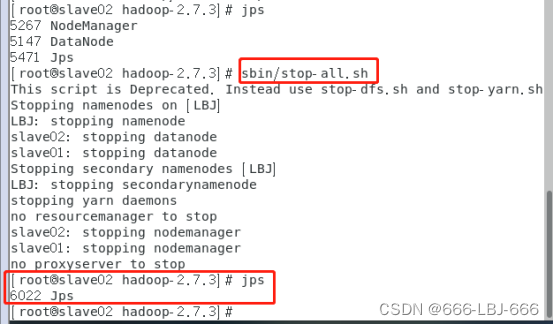
8.3.4 关闭hadoop集群
sbin/stop-all.sh
8.4 运行完全分布式例程(参考厦门大学大数据库实验室博客)
1)切换到hadoop-2.7.3目录:
cd /usr/hadoop/hadoop-2.7.3/
2)先开启集群:
./sbin/start-all.sh
3)并开启historyserver:
sbin/mr-jobhistory-daemon.sh start historyserver
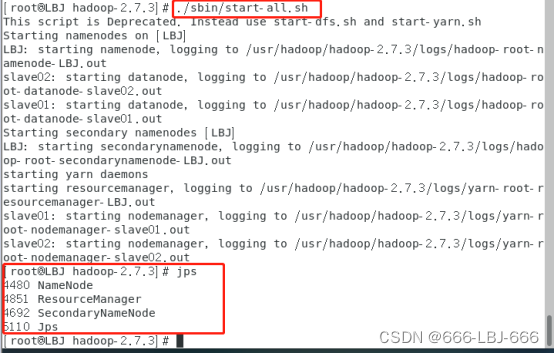

4)在master上
bin/hdfs dfs -mkdir -p /user/hadoop
bin/hdfs dfs -mkdir -p input
bin/hdfs dfs -put /usr/hadoop/hadoop-2.7.3/etc/hadoop/*.xml input
bin/hdfs dfs -ls ./input #查看传输的文件
5)运行例程:
hadoop jar /usr/hadoop/hadoop-2.7.3/share/hadoop/
mapreduce/hadoop-mapreduce-examples-2.7.3.jar grep input output 'dfs[a-z.]+'
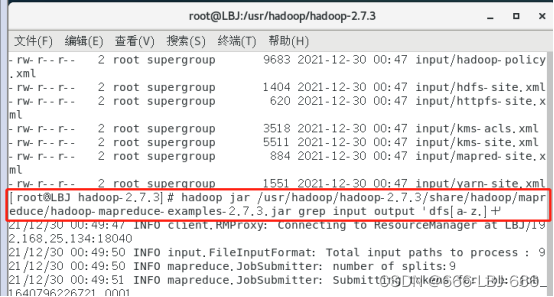
注:结果需要等待几分钟
结果:
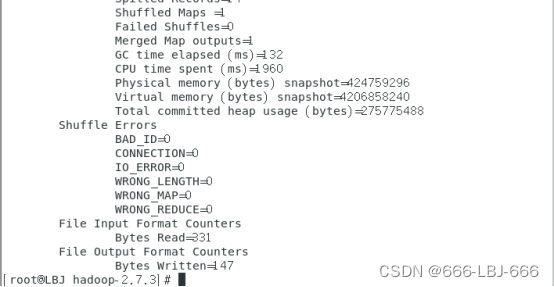
6)查看运行结果:
bin/hdfs dfs -cat output/*
三台CentOS7.6虚拟机搭建Hadoop完全分布式集群(二)笔记到此完结,笔者归纳、创作不易,大佬们给个3连再起飞吧
版权归原作者 666-LBJ-666 所有, 如有侵权,请联系我们删除。