
文章目录
前言
RPA,是Robotic Process Automation的英文缩写,中文是机器人流程自动化。一款优秀的RPA软件,可以实现所有桌面应用程序的自动化,包括ERP、浏览器、CRM、微信、钉钉或你日常使用的任何其他应用程序;支持任何网页的自动化,如网页JS脚本,数据提取,数据抓取、Web表单填写、网页操作,API调用等,轻松实现自动化的Web任务。
Selenium模块是一个用电脑模拟人操作浏览器网页,可以实现自动化,测试等。
提示:我使用的python版本为3.7,开发工具为PyCharm,Google Chrome版本为98.0.4758.102
一、环境搭建
1.安装seleniumm
pip install selenium
2.下载驱动
Chrome浏览器驱动:chromedriver
请将下载后的驱动解压后,放到指定目录(如 D:\WebDriver),然后将目录加入到环境变量的PATH中。
如果不行就将驱动chromedriver.exe放到安装目录,和python.exe一起就行
二、使用步骤
1.引入库
代码如下(示例):
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
2.启动浏览器
代码如下(示例):
browser = webdriver.Chrome()
browser.get('https://cn.bing.com/')
# 局最长等待时长5秒,局部刷新不管用
browser.implicitly_wait(5)
3.填文本并点击
提示:浏览器 F12,可以进入开发模式,查找网页对应元素,查看ID,XPATH,CLASS_NAME,CSS_SELECTOR等
根据ID来查找元素
browser.find_element(By.ID,"sb_form_q").send_keys("rpa")
browser.find_element(By.ID,"search_icon").click()
sleep(1)
清除内容,再次查询
browser.find_element(By.ID,"sb_form_q").clear()
browser.find_element(By.ID,"sb_form_q").send_keys("selenium")
browser.find_element(By.ID,"sb_form_go").click()
根据CSS_SELECTOR定位,点击第3条
browser.find_element(By.CSS_SELECTOR,'#b_results > li:nth-child(3) > div.b_title > h2 > a').click()
sleep(1)
其它查找方式类似,如果查找的是多条,可以用find_elements方法,然后遍历执行。
4.切换标签页
# 切换标签页
handles = browser.window_handles
print(handles)
browser.switch_to.window(handles[-1])# 切换标签页 简便写法
browser.switch_to.window(browser.window_handles[-1])# 结束工作,关闭
browser.close()# 切换回标签页
browser.switch_to.window(browser.window_handles[-1])
5.获取文本
# 查找元素,textprint(browser.find_element(By.ID,'est_cn').text)# 根据类获取表格的一列文本数据
titles = browser.find_elements(By.CLASS_NAME,'subjecthead')for title in titles:print(title.text)
# 获取输入框的内容
value = browser.find_element(By.ID,"sb_form_q").get_attribute('value')print(value)
# 获取所有超链接的href,也可以取局部的超链接
elements = browser.find_elements(By.CSS_SELECTOR,'a')for e in elements:print(e.get_attribute('href'))
6.选择框,下拉框
都是查找到元素,点击就行
browser.find_element(By.ID,'protocolCheckbox').click()
7.智能等待
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 等待wait。。。until,# WebDriverWait类,最长等待时间,多久询问一次。until,直到该元素出现为止
element = WebDriverWait(browser,10,0.5).until(# 等到元素可以被定位
EC.visibility_of_element_located((By.ID,'search-input')))# EC当某个自定义元素出现
8. 浏览器滚动到最后
# 将滚动条下拉至最低
js="window.scrollTo(0,document.body.scrollHeight)"
browser.execute_script(js)
9. 取消 DevTools listening on ws://127.0.0.1
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches',['enable-logging'])
browser = webdriver.Chrome(options=options)# browser = webdriver.Chrome(executable_path='D:\WebDriver', options=options)
10.退出
# 结束工作,关闭for h in browser.window_handles:
browser.switch_to.window(h)
browser.close()# 一定要加,不然Windows任务计划执行后,不退出黑窗口
browser.quit()
三、Windows任务计划(定时任务)
1、打开任务计划程序
2、新建任务
3、说重点,主要是操作设置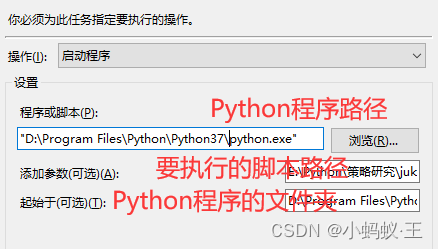
如果不知道自己的安装路径,在cmd窗口执行 where python,选择自己需要的路径
总结
本文仅仅简单介绍了selenium的使用,而selenium提供了大量能使我们快速便捷地操作网页的函数和方法。后续会继续完善。
本文转载自: https://blog.csdn.net/m0_68640362/article/details/123726892
版权归原作者 小蚂蚁·王 所有, 如有侵权,请联系我们删除。
版权归原作者 小蚂蚁·王 所有, 如有侵权,请联系我们删除。