
MapReduce程序实现词频统计
- 实验目的
1) 理解Hadoop中MapReduce模块的处理逻辑;
2)熟悉MapReduce编程;
- 实验平台
操作系统:Linux
工具:Eclipse或者Intellij Idea等Java IDE
- 实验内容
1) 在电脑上新建文件夹input,并input文件夹中创建三个文本文件:file1.txt,file2.txt,file3.txt。三个文本文件的内容分别是:
file1.txt: hello dblab world
file2.txt: hello dblab hadoop
file3.txt: hello mapreduce
2) 启动hadoop伪分布式,将input文件夹上传到HDFS上
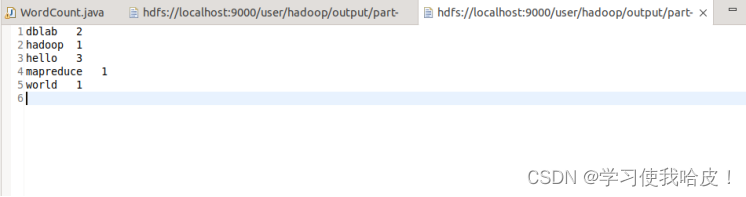
3) 编写mapreduce程序,实现单词出现次数统计(MapReduce的程序可以用Eclipse编译运行或使用命令行编译打包运行,使用其中一种即可)。统计结果保存到hdfs的output文件夹。
- 实验****代码和结果(截图展示)
(1在local下创建input文件夹,同时修改权限,再修改里面的文本文件。

(2) 启动hadoop伪分布式,将input文件夹上传到HDFS上


(3)编写mapreduce程序,实现单词出现次数统计(MapReduce的程序可以用Eclipse编译运行或使用命令行编译打包运行,使用其中一种即可)。统计结果保存到hdfs的output文件夹
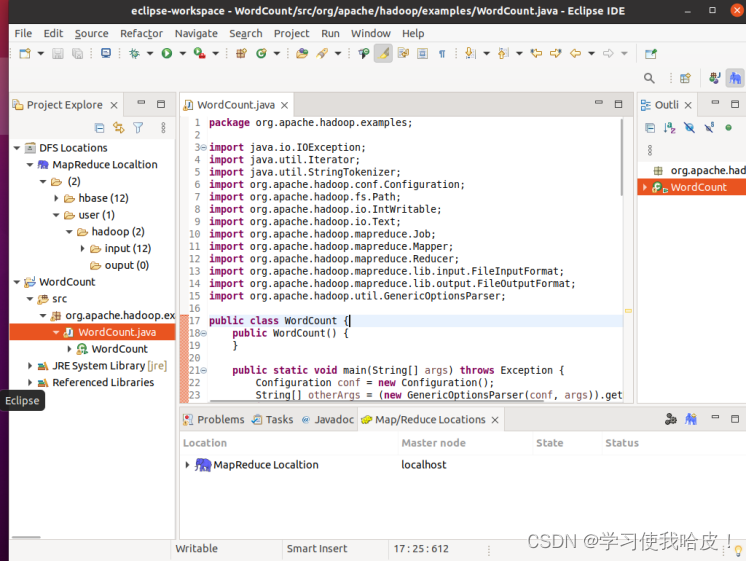
配置好参数之后,运行如下图:
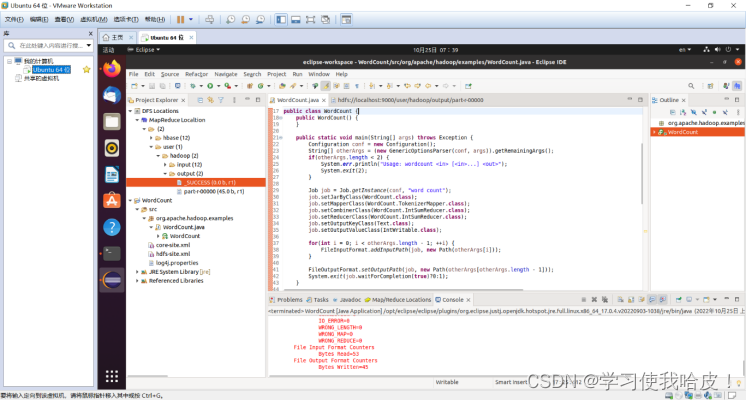
可以看见左边的MapReduce中有了output的文件夹。里面包含了程序运行之后的信息。
- 遇到的问题及如何解决
本文转载自: https://blog.csdn.net/qq_55795222/article/details/128574786
版权归原作者 学习使我哈皮! 所有, 如有侵权,请联系我们删除。
版权归原作者 学习使我哈皮! 所有, 如有侵权,请联系我们删除。