
一.HDFS的本质
Hadoop Distributed File System(HDFS)是Hadoop的核心组件之一,它是一个高度容错性的分布式文件系统,能够处理超大规模数据集。HDFS被设计成运行在廉价硬件上,能够自动检测并处理硬件故障,从而提供高可用性和高可靠性。HDFS采用主/从(Master/Slave)架构,主要由NameNode和DataNode两类节点组成。它本质还是程序,主要还是以树状目录结构来管理文件(和linux类似,/表示根路径),且可以运行在多个节点上(即分布式)。
二.HDFS的架构与原理
- NameNode:即是master: - 管理HDFS的命名空间- 配置副本策略- 惯例数据块Blocks的映射欣喜- 处理客户端读写请求
- DataNode:即是slave: - master下达命令,DataNode执行操作- 存储实际的数据块- 执行数据块的读/写操作
- Clinet:客户端 - 文件切分。文件上传HDFS时,Client将文件切分成一个个Block后上传- 与NameNode交互,获取文件的位置信息- 与DataNode交互,读取或写入数据- Client提供一些命令来管理HDFS,如NameNode语法化- Client通过一些命令来访问HDFS,如HDFS增删改查操作
- Secondary NameNode: - 辅助NameNode,分单其工作量,如定期合并simage和Edits,并推送给NameNode- 在紧急情况下,可以辅助恢复NameNode

三、HDFS特性
高可靠性
HDFS通过数据块的冗余存储和NameNode的元数据备份机制来实现高可靠性。当某个DataNode出现故障时,HDFS可以从其他DataNode中读取相同的数据块来恢复数据。同时,NameNode的元数据也会被定期备份到多个节点上,以防止单点故障导致数据丢失。
高可扩展性
HDFS采用分布式架构,可以方便地添加新的DataNode来扩展存储容量。同时,HDFS的元数据管理也支持水平扩展,可以通过增加NameNode的数量来提高元数据的处理能力。
高性能
HDFS通过数据块的并行处理和传输来提高数据处理效率。同时,HDFS还采用了一些优化技术,如数据块预取、缓存机制等,来进一步提高读写性能。
易用性
HDFS提供了类似于POSIX的文件系统接口,使得用户可以像操作本地文件系统一样来操作HDFS。同时,HDFS还提供了丰富的命令行工具和API接口,方便用户进行数据的存储、管理和分析。
四.HDFS的常用命令
HDFS很多命令用法与Linux命令类似
1.显示HDFS指定路径下的所有文件
语法:hdfs dfs -ls <path>
输入命令:hdfs dfs -ls /
结果显示如下图:

2.在HDFS上创建文件夹
语法:hdfs dfs -mkdir [-p] <path>
- -p:如果要创建的目录的父目录不存在,则自动补上父目录
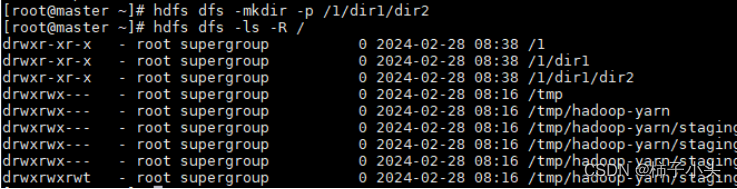
- 输入命令:hdfs dfs -mkdir -p /1/dir1/dir2
- (-ls显示补充)输入命令:hdfs dfs -ls -R /(-R:将指定目录的所有文件显示出来,包括子目录里的文件)
3.上传本地文件到HDFS
- 语法:hdfs dfs -put <local src path> <dst path>- dst path:HDFS目标路径,即文件将被上传到这个路径上- local src path:被上传的本地文件路径- 输入命令:hdfs dfs -put /usr/local/hadoop-3.1.3/test/test.txt /1/dir1/dir2

4.查看文件
- 语法:hdfs dfs -cat <path>
- 输入命令:hdfs dfs -cat /1/dir1/dir2/test.txt

将HDFS的****<src path>文件下载到本地文件系统的<local dst>路径****
- 语法:hdfs dfs -get <src path> <local dst>
- local dst:本地文件系统目标路径,即文件将被下载到这个路径
- src path:被下载的HDFS文件路径
- 输入命令:hdfs dfs -get /1/dir1/dir2/test.txt ~
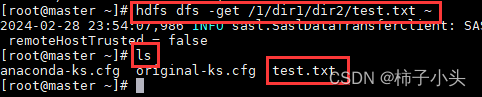
将HDFS的****<src path>文件下载到本地文件系统的<local dst>路径
- 语法:hdfs dfs -get <src path> <local dst>
- local dst:本地文件系统目标路径,即文件将被下载到这个路径
- src path:被下载的HDFS文件路径
- 输入命令:hdfs dfs -get /1/dir1/dir2/test.txt ~

5.删除HDFS上的文件或者目录
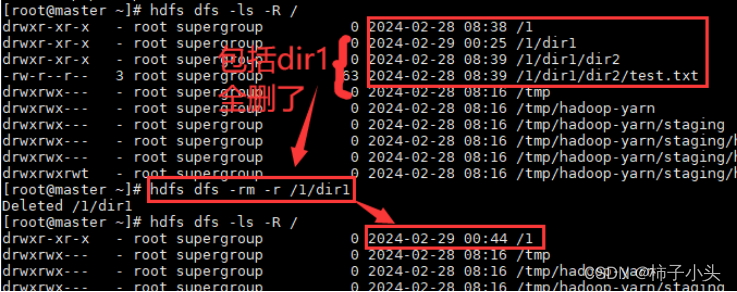
- 语法:hdfs dfs -rm [-r] <path>
- -r : 表示递归删除,即连同子目录一同删除
- 例1:不带-r的。输入命令: hdfs dfs -rm /1/dir1/test.txt

例2:
- 带-r的。输入命令:hdfs dfs -rm /1/dir1/
6.修改指定文件的权限信息(读、写、执行)
一般语法:chmod [可选项] <mode> <path>
- 可选项,常见的如-R:递归修改子目录
- mode:权限设定字符串。语法:[ugoa][+-=][rwx]
- rwx:r表示可读取,w表示可写入,x表示可执行
- +-=:+表示增加权限、-表示取消权限、=表示唯一设定权限
- ugoa:u表示该文件的所有者,g表示所属组,o表示其他以外的人,a表示这三者皆是
- 回顾:Linux、hdfs通过所有者(user)、所属组(group)、其他(other)这三个角色来管理文件权限,如果当前登录的用户没有相应权限,那么执行某些命令就会报错。常见的三种权限: - 执行execute,用x表示- 写write,用w表示- 读read,用r表示
五、HDFS实战应用
1.数据存储
HDFS可以用于存储各种类型的数据文件,如日志文件、图片文件、视频文件等。通过将数据存储在HDFS中,可以方便地进行数据的备份、恢复和共享。
2.数据处理
HDFS可以与Hadoop的其他组件(如MapReduce、Spark等)结合使用,进行大规模数据的批处理、实时计算和分析。通过利用HDFS的分布式存储和并行处理能力,可以显著提高数据处理效率和准确性。
3.数据仓库
HDFS可以作为数据仓库的底层存储系统,为数据仓库提供高效、可靠的数据存储服务。通过将数据存储在HDFS中,并结合Hive等SQL引擎进行查询和分析,可以实现高效的数据仓库解决方案。
六、总结
HDFS作为Hadoop生态中的核心组件之一,提供了可靠、高效、可扩展的数据存储服务。通过深入了解HDFS的原理、架构、特性和实战应用,我们可以更好地利用HDFS来处理和分析大数据,为企业创造更大的价值。同时,随着大数据技术的不断发展,HDFS也在不断地演进和完善,相信未来HDFS将在大数据领域发挥更加重要的作用。
版权归原作者 柿子小头 所有, 如有侵权,请联系我们删除。