
maven:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
MapAction
package com.item.test;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class MapAction extends Mapper<LongWritable, Text, Text, LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
for (String s : split) {
context.write(new Text(s), new LongWritable(1));
}
}
}
ReduceAction
package com.item.test;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class ReduceAction extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long count = 0;
for (LongWritable value : values) {
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
Action
package com.item.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Action {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(Action.class);
job.setMapperClass(MapAction.class);
job.setReducerClass(ReduceAction.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.setInputPaths(job,new Path("/abcd/info.txt"));
FileOutputFormat.setOutputPath(job,new Path("/infos"));
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
生成jar包
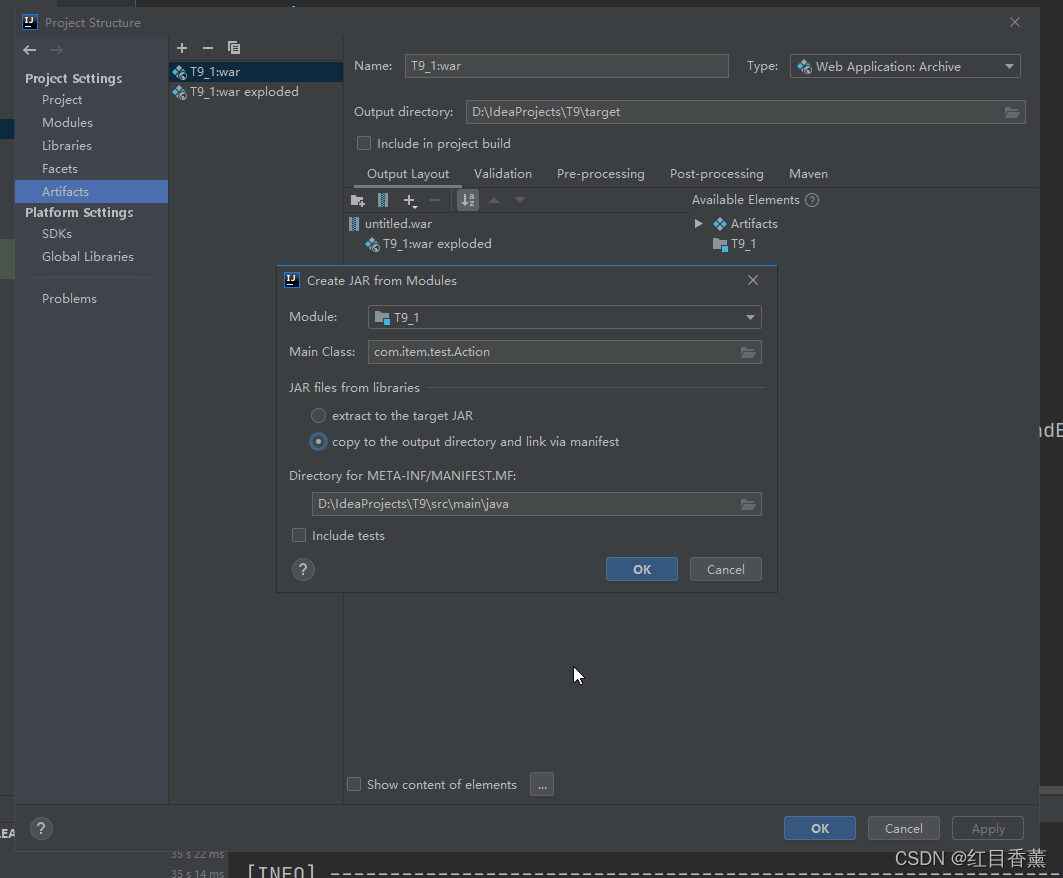
讲jar放在【/opt/soft/hadoop/share/hadoop/mapreduce】中
预先上传文件作用记录【info.txt】
asdasd asd asdhkajshas jdhasjk djkas hdas hdj sa
dashkj dajks d jksa hdas hjkd haksj dsa
dsaji djkas kjdsah jdh askjdhkjash kj
adhjks djak dja hsjkdsakhd
hadoop fs -mkdir /abcd
hadoop fs -put info.txt /abcd
执行
hadoop jar T9_1.jar com/item.test/Action /abcde/info.txt /infos
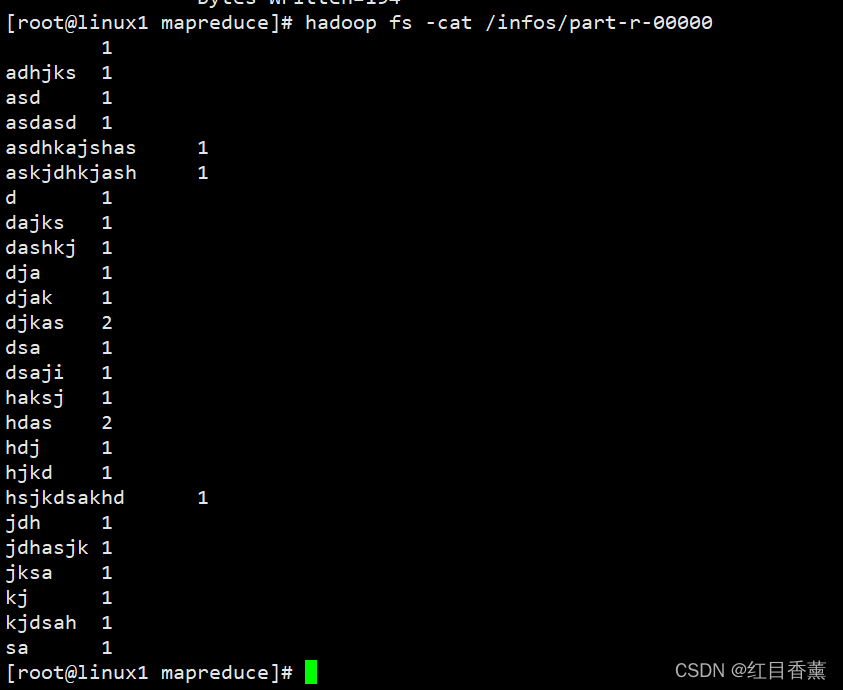
查看结果
hadoop fs -cat /infos/part-r-00000
标签:
hadoop
本文转载自: https://blog.csdn.net/feng8403000/article/details/124417203
版权归原作者 红目香薰 所有, 如有侵权,请联系我们删除。
版权归原作者 红目香薰 所有, 如有侵权,请联系我们删除。