
一、hbase数据导入hive
hive通过建立外部表和普通表加载hbase表数据到hive表中。
两种方式加载hbase中的表到hive中,一是hive创建外部表关联hbase表数据,是hive创建普通表将hbase的数据加载到本地。
1.创建外部表
hbase中创建test表,且插入两条数据,内容如下
put 'test','001','info:name','tom'
put 'test','001','info:age',18
put 'test','002','info:name','jerry'
put 'test','002','info:age',19
hbase(main):012:0* scan 'test'ROWCOLUMN+CELL
001column=info:age,timestamp=1526563694645,value=18001column=info:name,timestamp=1526563629119,value=tom
002column=info:age,timestamp=1526563723288,value=19002column=info:name,timestamp=1526563706773,value=jerry
2row(s)in0.4320 seconds
接下来创建一个hive的外部表
CREATE EXTERNAL TABLE test_external (keyint, name string,age int)
STORED BY'org.apache.hadoop.hive.hbase.HBaseStorageHandler'WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:name,info:age")
TBLPROPERTIES ("hbase.table.name"="test");
注:EXTERNAL 关键字指定创建一个外部表
进入hive shell,执行上面的建表语句
hive> CREATE EXTERNAL TABLE test_external (key int, name string,age int)> STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'> WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,info:name,info:age")> TBLPROPERTIES ("hbase.table.name"="test");
OK
Time taken: 0.331 seconds
hive可以使用类sql语句执行查询命令
hive>select*from test_external;
OK
1 tom 182 jerry 19Time taken: 0.313 seconds, Fetched: 2row(s)
2. 创建普通表
hive外部表,仅记录数据所在的路径, 不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除, 而外部表只删除元数据,不删除数据。接下来创建普通表(内部表),并将hbase表数据加载到内部表中。
hive>createtable test (key string, name string,age string)>ROW FORMAT DELIMITED FIELDSTERMINATEDBY'\t'> STORED AS TEXTFILE;
OK
Time taken: 0.154 seconds
执行sql命令
INSERT OVERWRITE TABLE test SELECT*FROM test_external
通过外部表将hbase中的表数据加载到hive本地表
hive> INSERT OVERWRITE TABLE test SELECT * FROM test_external;
Query ID = hadoop20240410102929_b52c1820-7d93-4baf-a410-8604bfd0e43b
Total jobs=3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1525962191655_0030, Tracking URL = http://SHQZ-PS-IOT-TEST-WEB01:8088/proxy/application_1525962191655_0030/
Kill Command = /opt/cloudera/parcels/CDH-5.8.4-1.cdh5.8.4.p0.5/lib/hadoop/bin/hadoop job -kill job_1525962191655_0030
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 02024-04-10 10:30:18,571 Stage-1 map =0%, reduce =0%
2024-04-10 10:30:31,505 Stage-1 map =100%, reduce =0%, Cumulative CPU 4.68 sec
MapReduce Total cumulative CPU time: 4 seconds 680 msec
Ended Job = job_1525962191655_0030
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://nameservice1/user/hive/warehouse/test/.hive-staging_hive_2024-04-10_10-29-59_285_1972684120193290878-1/-ext-10000
Loading data to table default.test
Table default.test stats: [numFiles=1, numRows=2, totalSize=20, rawDataSize=18]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 4.68 sec HDFS Read: 3811 HDFS Write: 88 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 680 msec
OK
Time taken: 34.13 seconds
加载hbase表数据到hive内部表中,是通过启动一个mapreduce任务来进行的;另外hive的sql基本上都是转换成mapreduce任务来执行。
hive>select*from test;
OK
1 tom 182 jerry 19Time taken: 0.194 seconds, Fetched: 2row(s)
3.使用DataX将HBase数据导入Hive
需要创建一个DataX作业,并配置相应的源(HBase)和目标(Hive)。涉及到指定 HBase 的表结构、Hive 的表结构以及数据转换逻辑。
{"job":{"setting":{"speed":{"channel":1}},"content":[{"reader":{"name":"hbase191reader","parameter":{"hbaseConfig":{"hbase.zookeeper.quorum":"your_zookeeper_quorum","hbase.zookeeper.property.clientPort":"2181","zookeeper.znode.parent":"/hbase"},"table":"your_hbase_table","encoding":"UTF-8","column":[{"name":"rowkey","type":"string"},{"name":"column1","type":"string"},// ... 定义其他列],"range":{"startRow":"","endRow":""}}},"writer":{"name":"hive","parameter":{"defaultFS":"hdfs://your_namenode:8020","fileType":"orc","path":"/user/hive/warehouse/your_hive_table","column":[{"name":"rowkey","type":"string"},{"name":"column1","type":"string"},// ... 定义其他列],"writeMode":"append","fieldDelimiter":"\t","compress":"zip"}}}]}}
二、Hive数据导入HBase
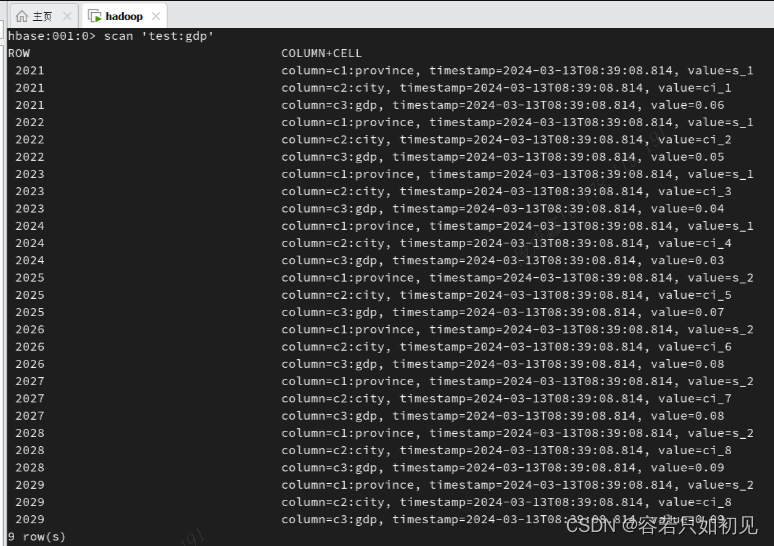
通过外部表的方式,首先在hbase中要先存在一张表:namespace(命名空间)是test,表名是gdp,有三个列,c1,c2,c3
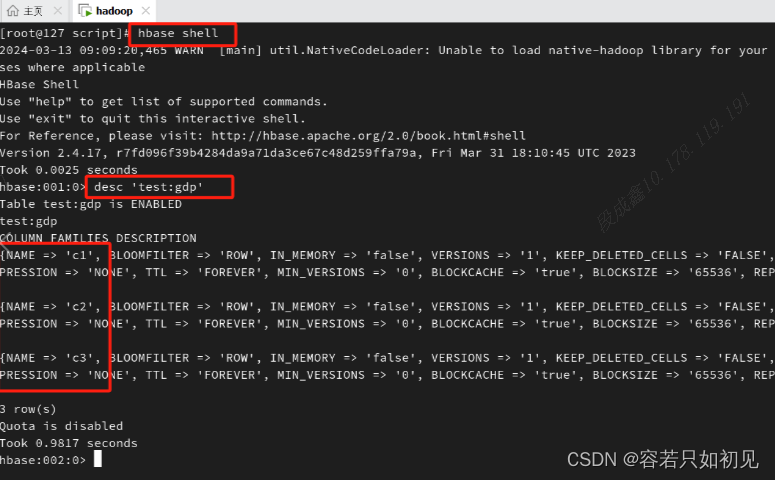
去hive中创建对应的映射表
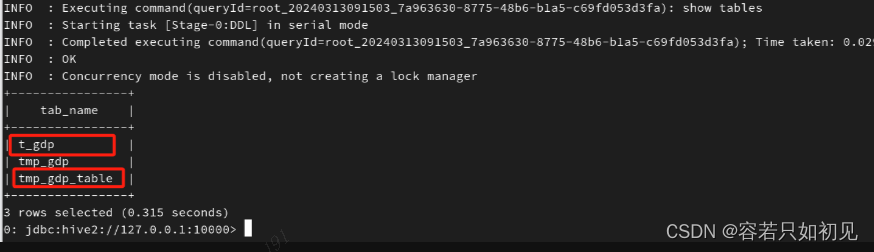
其中t_gdp是原始数据表,tmp_gdp_table是和hbase中gdp表关联的外部表,将t_gdp表中的数据insert到了tmp_gdp_table表中,正常的业务中,可能是查询了多个表,通过sql处理将数据存到tmp_gdp_table中,然后通过外部表映射的方式同步到habse的gdp表中。
hive中创建外部关联表的命令:
CREATE EXTERNAL TABLE tmp_gdp_table(keyvarchar(100), province varchar(100),city varchar(100),gdp double)
STORED BY'org.apache.hadoop.hive.hbase.HBaseStorageHandler'WITH SERDEPROPERTIES ("hbase.columns.mapping"=":key,c1:province,c2:city,c3:gdp")
TBLPROPERTIES ("hbase.table.name"="test:gdp","hbase.mapred.output.outputtable"="test:gdp");
创建好关联表之后,将t_gdp中的数据insert到tmp_gdp_table表中:
insertinto tmp_gdp_table (select f_year,f_province,f_city,f_gdp from t_gdp);
在实际的业务开发中一般是通过定时任务执行脚本的方式来执行上面的sql,脚本命令如下:
#!/bin/bash
hive -e'insert into tmp_gdp_table (select f_year,f_province,f_city,f_gdp from t_gdp);'
通过执行脚本,在实际业务开发中就可以通过linux里的crontab或者公司的调度平台来执行
原始数据表t_gdp中的数据:
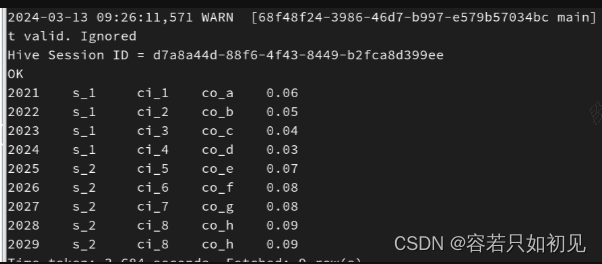
hive中的关联表tmp_gdp_table中的数据:
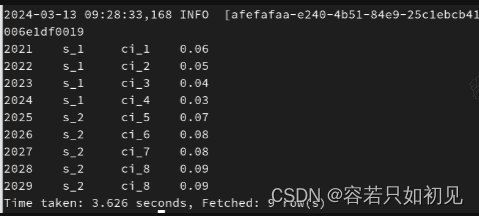
hbase中的表test:gdp中的数据:
版权归原作者 容若只如初见 所有, 如有侵权,请联系我们删除。