
一、Spark运行环境初始化
任何Spark程序都是以SparkContext对象开始的,因为SparkContext是Spark应用程序的上下文和入口,无论是Scala、Python、R程序,都是通过SparkContext对象的实例来创建RDD,Spark Shell中的sc就是SparkContext对象的实例。因此在实际Spark应用程序的开发中,在main方法中需要创建SparkContext对象,作为Spark应用程序的入口,并在Spark程序结束时关闭SparkContext对象。
初始化SparkContext需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数,属性参数是一种键值对的格式,一般可以通过set(属性名,属性设置值)的方法修改属性。其中还包含了设置程序名setAppName、设置运行模式setMaster等方法。
例如:

二、RDD的创建
RDD是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合。RDD的创建有3种不同的方法。
- 第一种是将程序中已存在的Seq集合(如集合、列表、数组)转换成RDD。
- 第二种是对已有RDD进行转换得到新的RDD,这两种方法都是通过内存中已有的集合创建RDD的。
- 第三种是直接读取外部存储系统的数据创建RDD。
从内存中读取数据
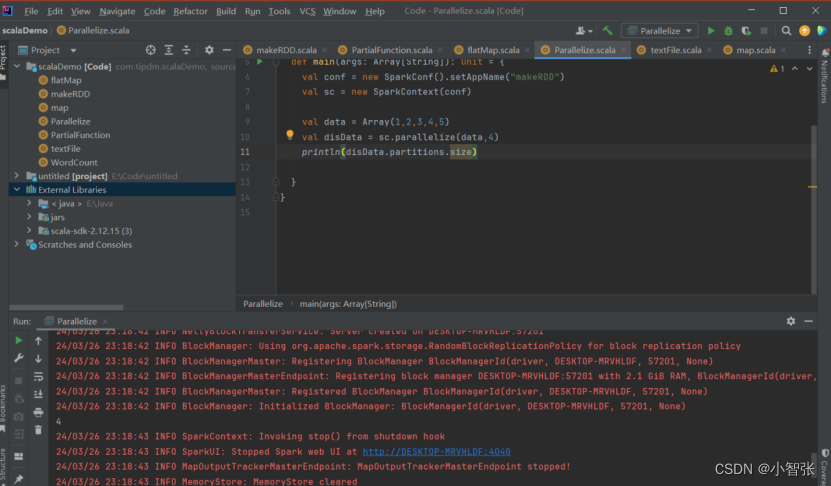
- parallelize()
parallelize()方法有两个输入参数,说明如下。
- 要转化的集合,必须是Seq集合。Seq表示序列,指的是一类具有一定长度的、可迭代访问的对象,其中每个数据元素均带有一个从0开始的、固定的索引。
- 分区数,若不设分区数,则RDD的分区数默认为该程序分配到的资源的CPU核心数。
*2*****. ****makeRDD()
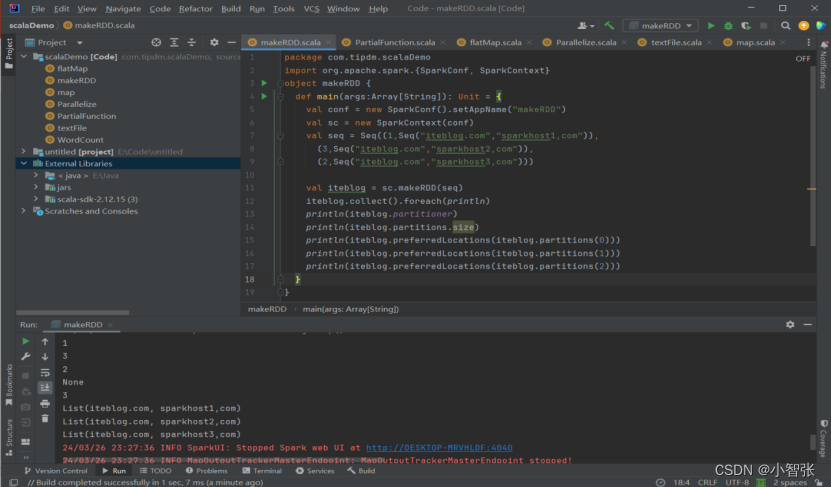
makeRDD()方法有两种使用方式。
- 第一种方式的使用与parallelize()方法一致;
- 第二种方式是通过接收一个是Seq[(T,Seq[String])]参数类型创建RDD。
生成的RDD中保存的是T的值,Seq[String]部分的数据会按照Seq[(T,Seq[String])]的顺序存放到各个分区中,一个Seq[String]对应存放至一个分区,并为数据提供位置信息,通过preferredLocations()方法可以根据位置信息查看每一个分区的值。调用makeRDD()时不可以直接指定RDD的分区个数,分区的个数与Seq[String]参数的个数是保持一致的。
从外部存储系统中读取数据
从外部存储系统中读取数据创建RDD是指直接读取存放在文件系统中的数据文件创建RDD。
从内存中读取数据创建RDD的方法常用于测试,从外部存储系统中读取数据创建RDD才是用于实践操作的常用方法。
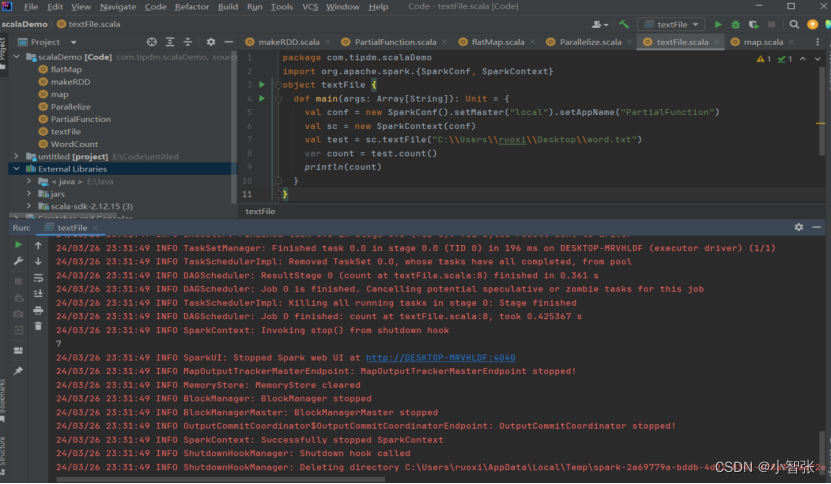
从外部存储系统中读取数据创建RDD可以有很多种数据来源,可通过SparkContext对象的textFile()方法读取数据集,该方法支持多种类型的数据集,如目录、文本文件、压缩文件和通配符匹配的文件等,并且允许设定分区个数。
分别读取HDFS文件和Linux本地文件的数据并创建RDD,具体操作如下。
通过HDFS文件创建RDD
直接通过textFile()方法读取HDFS文件的位置即可。
- 通过Linux本地文件创建RDD
本地文件的读取也是通过sc.textFile("路径")的方法实现的,在路径前面加上“file://”表示从Linux本地文件系统读取。在IntelliJ IDEA开发环境中可以直接读取本地文件;但在spark-shell中,要求在所有节点的相同位置保存该文件才可以读取它
转换操作可以将一个RDD转换为一个新的RDD,但是转换操作是懒操作,不会立刻执行计算;
行动操作是用于触发转换操作的操作,这时才会真正开始进行计算。
三、RDD常用的方法
单个RDD
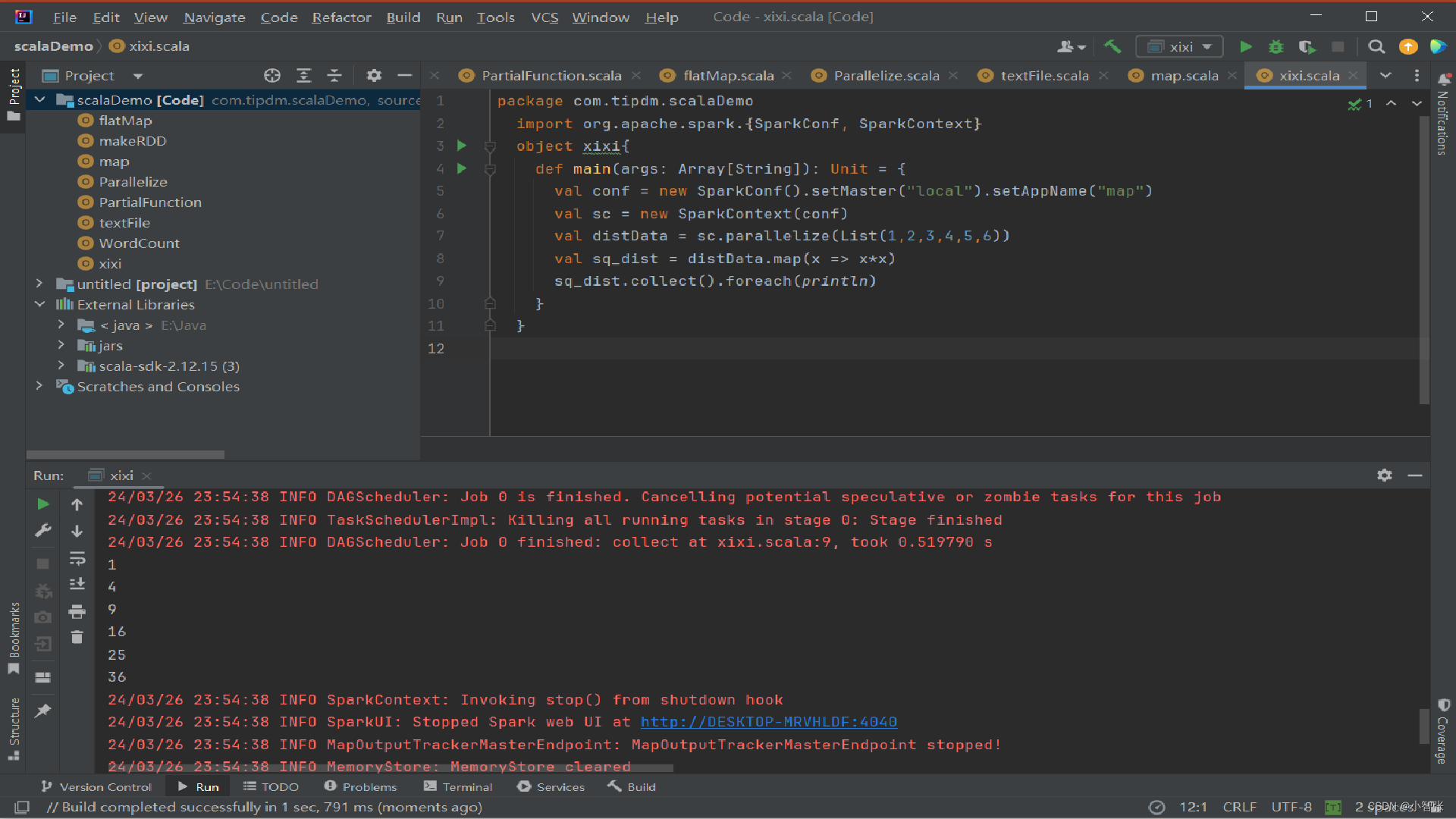
1.map()方法转换数据
map()方法是一种基础的RDD转换操作,可以对RDD中的每一个数据元素通过某种函数进行转换并返回新的RDD。 map()方法是转换操作,不会立即进行计算。
2. sortBy()方法进行排序
sortBy()方法用于对标准RDD进行排序,有3个可输入参数,说明如下。
第1个参数是一个函数f:(T) => K,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。(该参数是必须输入的)
第2个参数是ascending,决定排序后RDD中的元素是升序的还是降序的,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。
第3个参数是numPartitions,决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的分区个数相等,即this.partitions.size。
#创建RDD
val data = sc.parallelize(List((1,3),(45,3),(7,6)))
#对元组第二个值进行降序排序,分区个数设置为1
val sort_data = data.sortBy(x => x._2,false,1)
3.collect()方法查询数据
collect()方法是一种行动操作,以数组 Array 的形式返回数据集的所有元素
collect()里将生成目录方法有以下两种操作方式。
- collect:直接调用collect返回该RDD中的所有元素,返回类型是一个Array[T]数组。

- collect[U: ClassTag](f: PartialFunction[T, U]):RDD[U]。这种方式需要提供一个标准的偏函数,将元素保存至一个RDD中。首先定义一个函数one,用于将collect方法得到的数组中数值里将生成目录为1的值替换为“one”,将其他值替换为“other”。

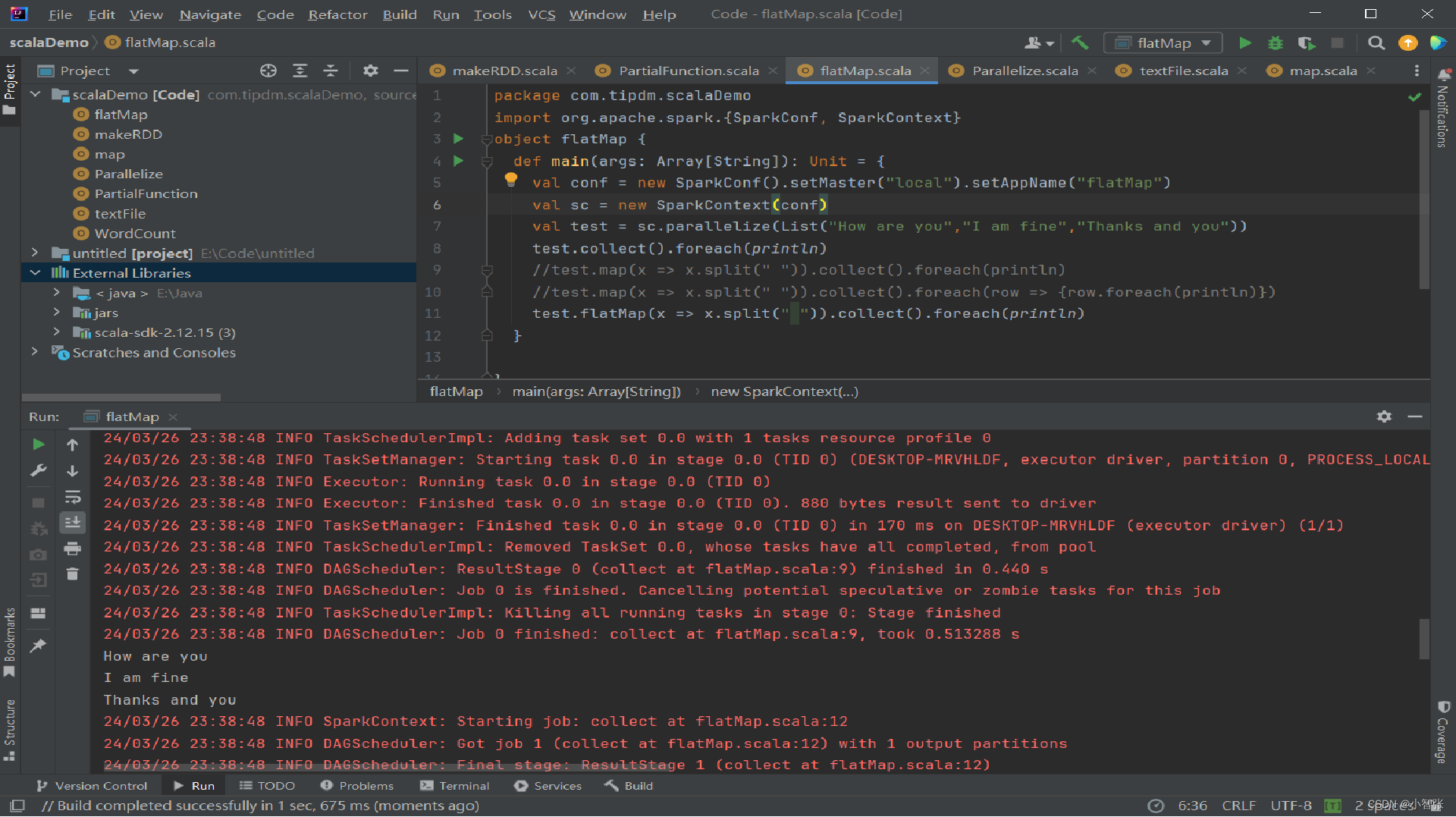
**4.flatMap()方法转换数据 **
使用flatMap()方法时先进行map(映射)再进行flat(扁平化)操作,数据会先经过跟map一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。
这个转换操作通常用来切分单词。
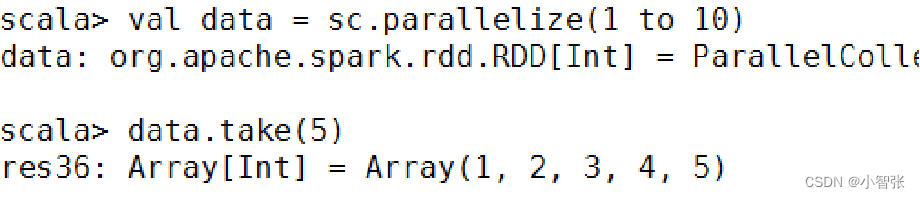
5.take()方法查询某几个值
take(N)方法用于获取RDD的前N个元素,返回数据为数组。 take()与collect()方法的原理相似,collect()方法用于获取全部数据,take()方法获取指定个数的数据。
eg:获取RDD的前5个元素:
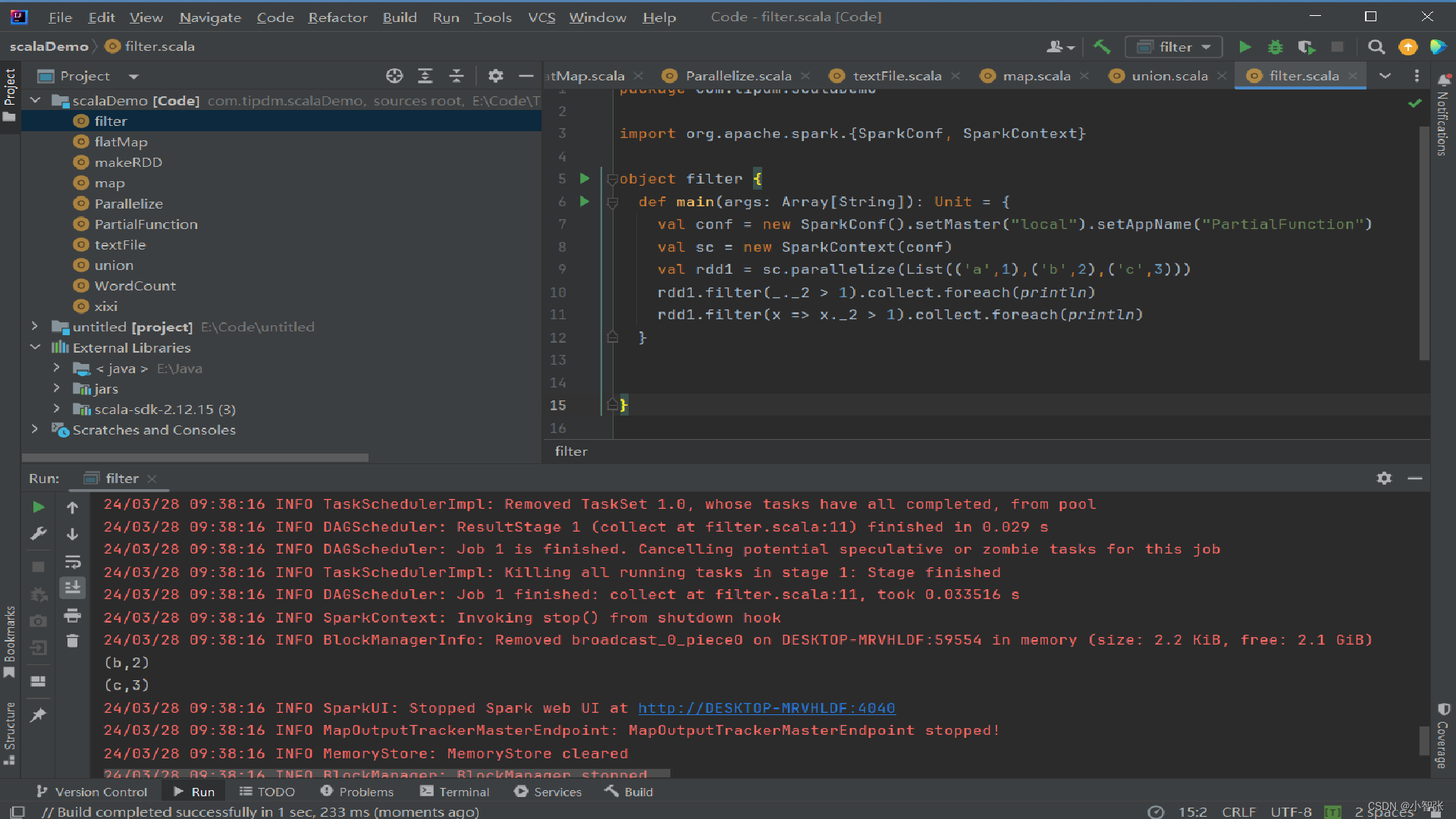
6.filter()方法进行过滤
filter()方法是一种转换操作,用于过滤RDD中的元素。
filter()方法需要一个参数,这个参数是一个用于过滤的函数,该函数的返回值为Boolean类型。 filter()方法将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
eg:创建一个RDD,并且过滤掉每个元组第二个值小于等于1的元素。
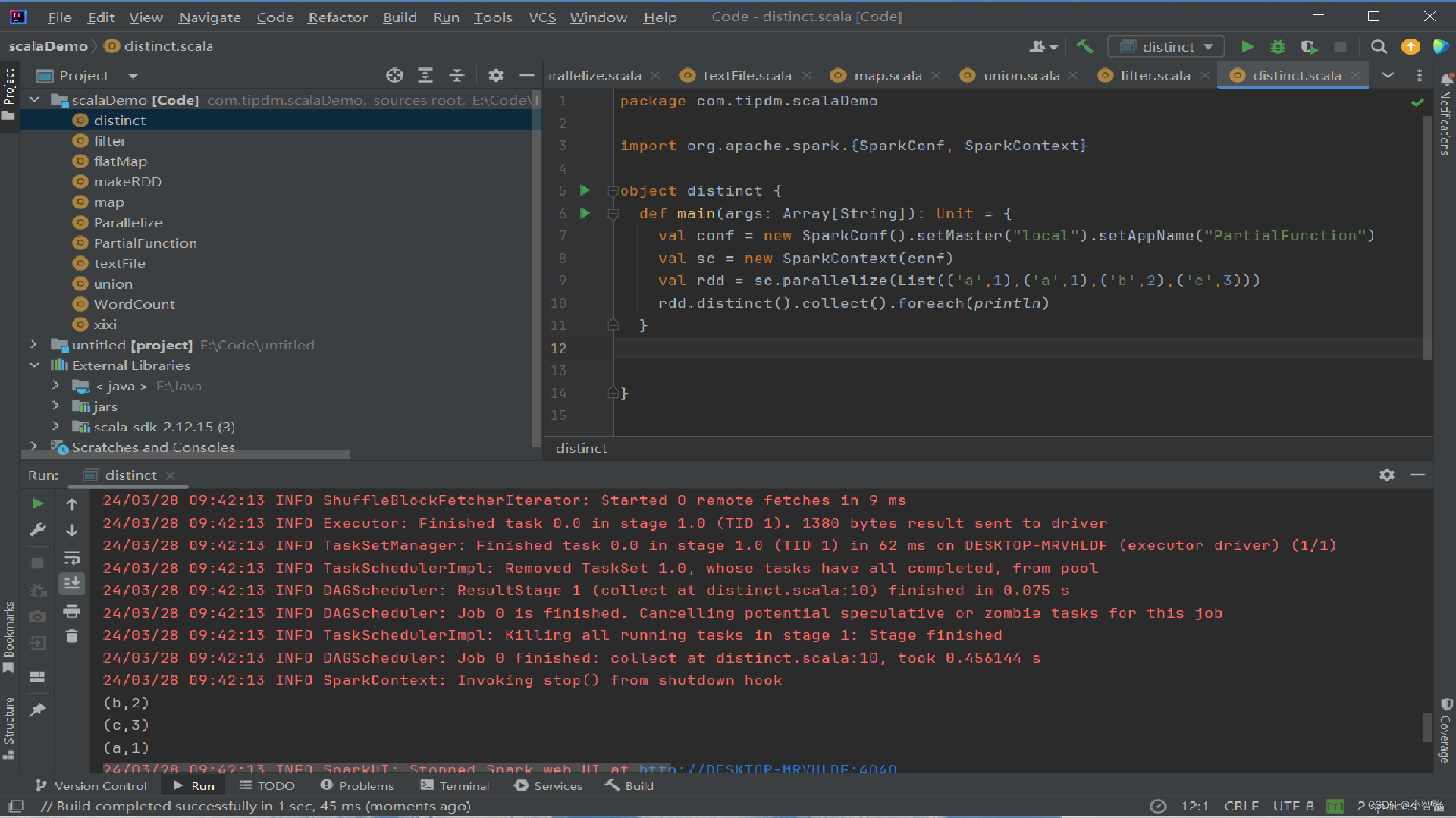
7.distinct()方法进行去重
distinct()方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。
eg:创建一个带有重复数据的RDD,并使用distinct()方法去重。
两个RDD集合操作

1.union()方法 合并
union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。 使用union()方法合并两个RDD
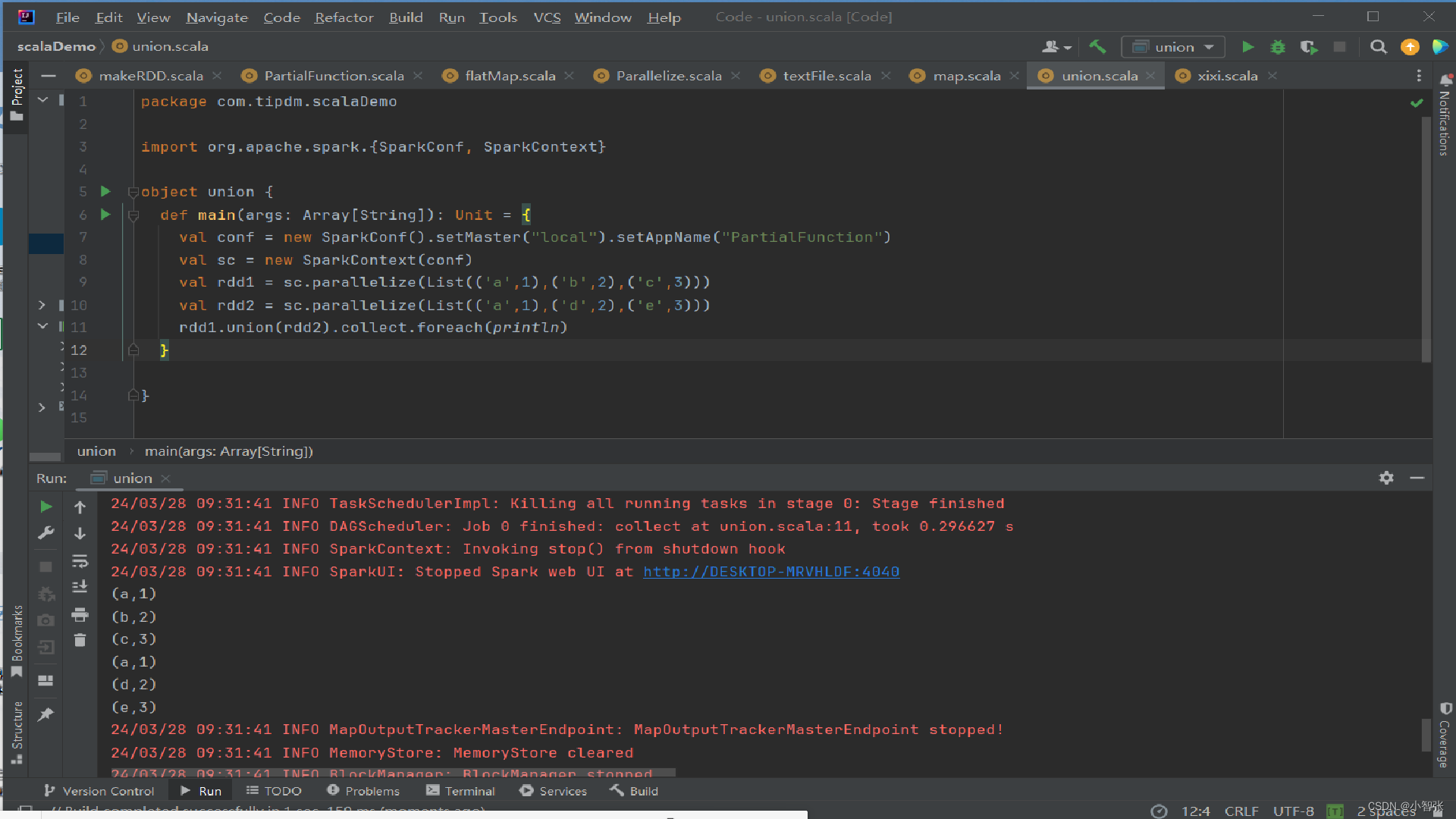
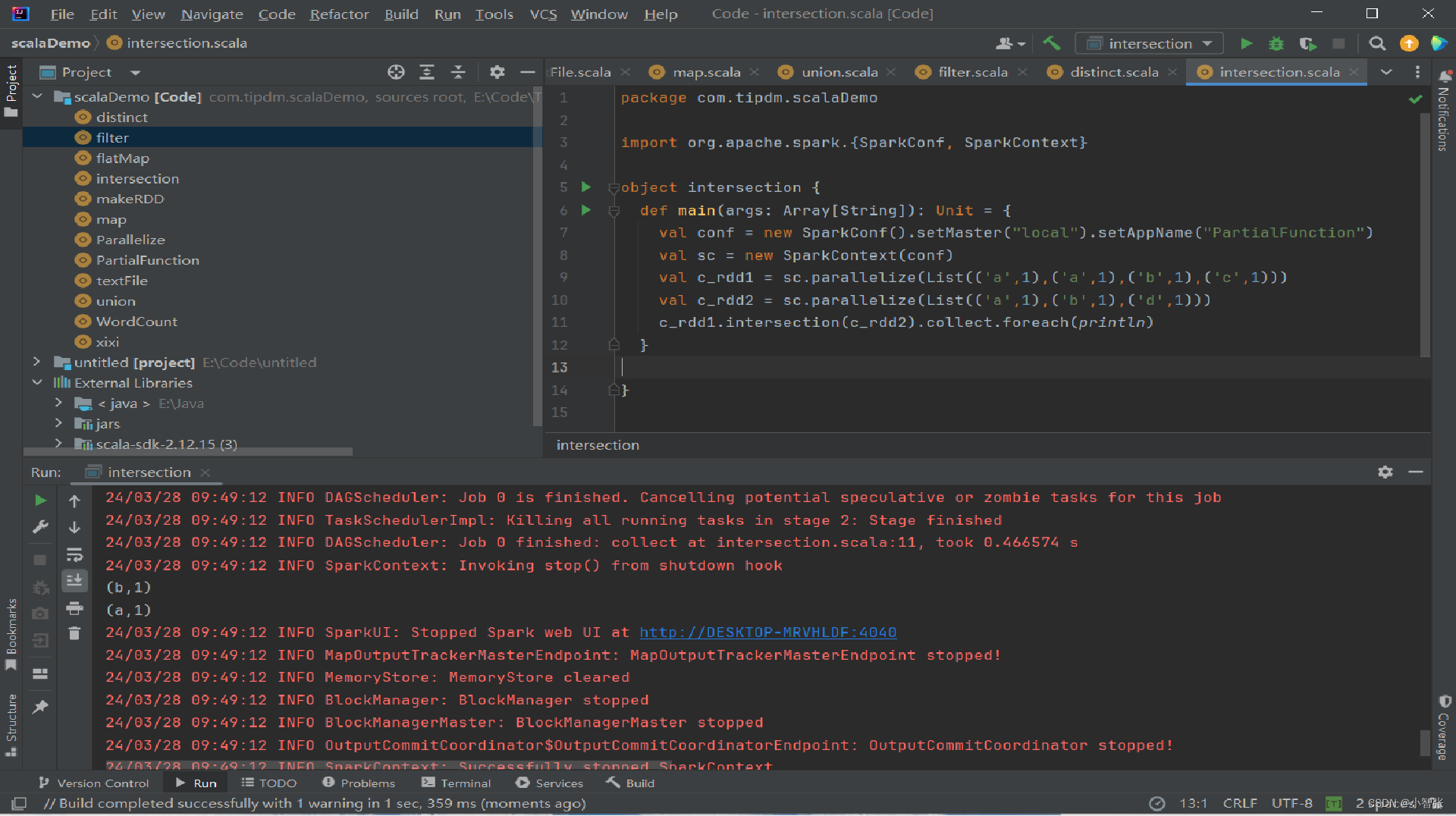
2.intersection()方法 交集
intersection()方法用于求出两个RDD的共同元素,即找出两个RDD的交集,参数是另一个RDD,先后顺序与结果无关。
eg:创建两个RDD,其中有相同的元素,通过intersection()方法求出两个RDD的交集。
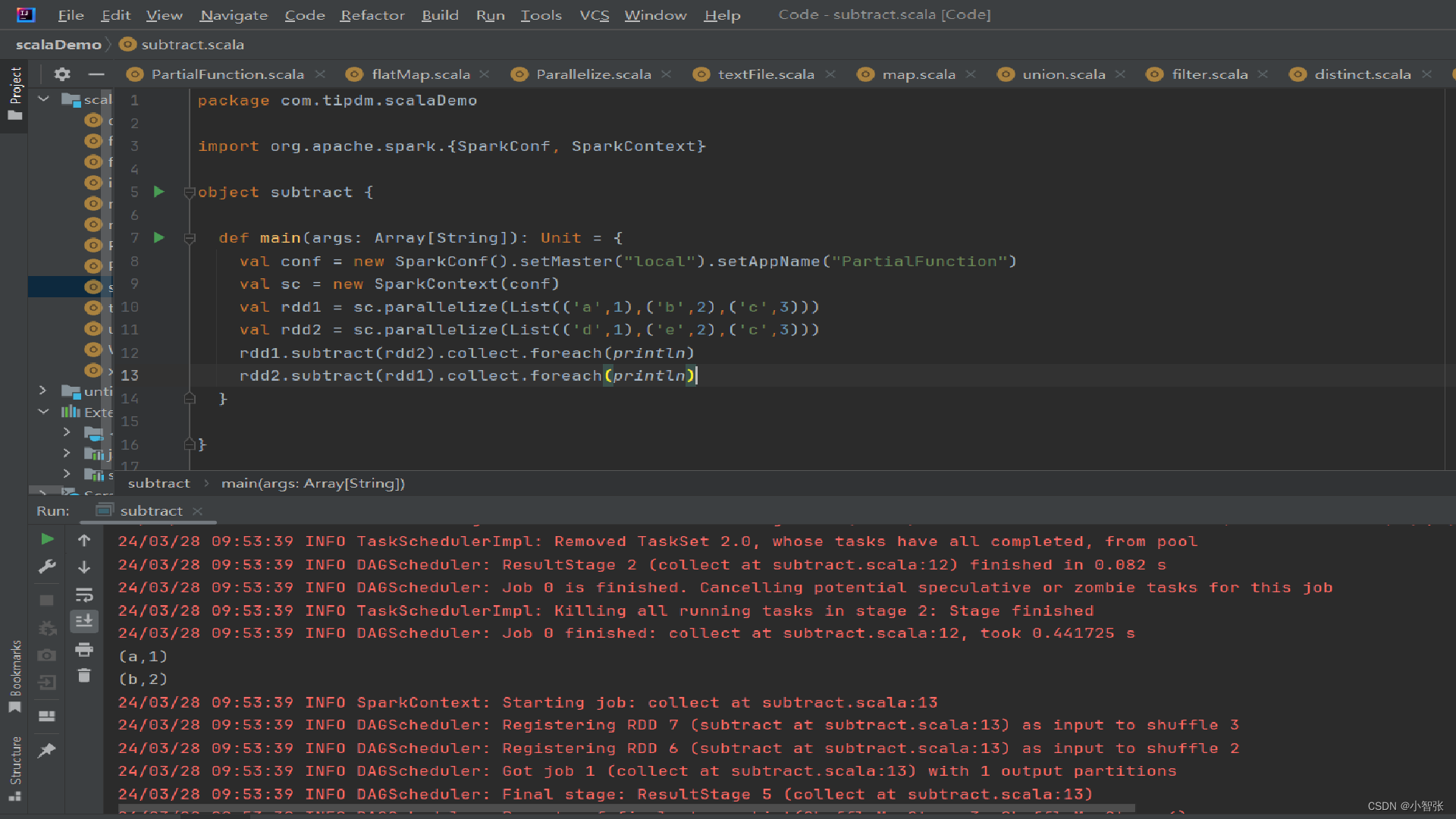
3.subtract()方法 补集
subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。两个RDD的顺序会影响结果。
eg:创建两个RDD,分别为rdd1和rdd2,包含相同元素和不同元素,通过subtract()方法求rdd1和rdd2彼此的补集。
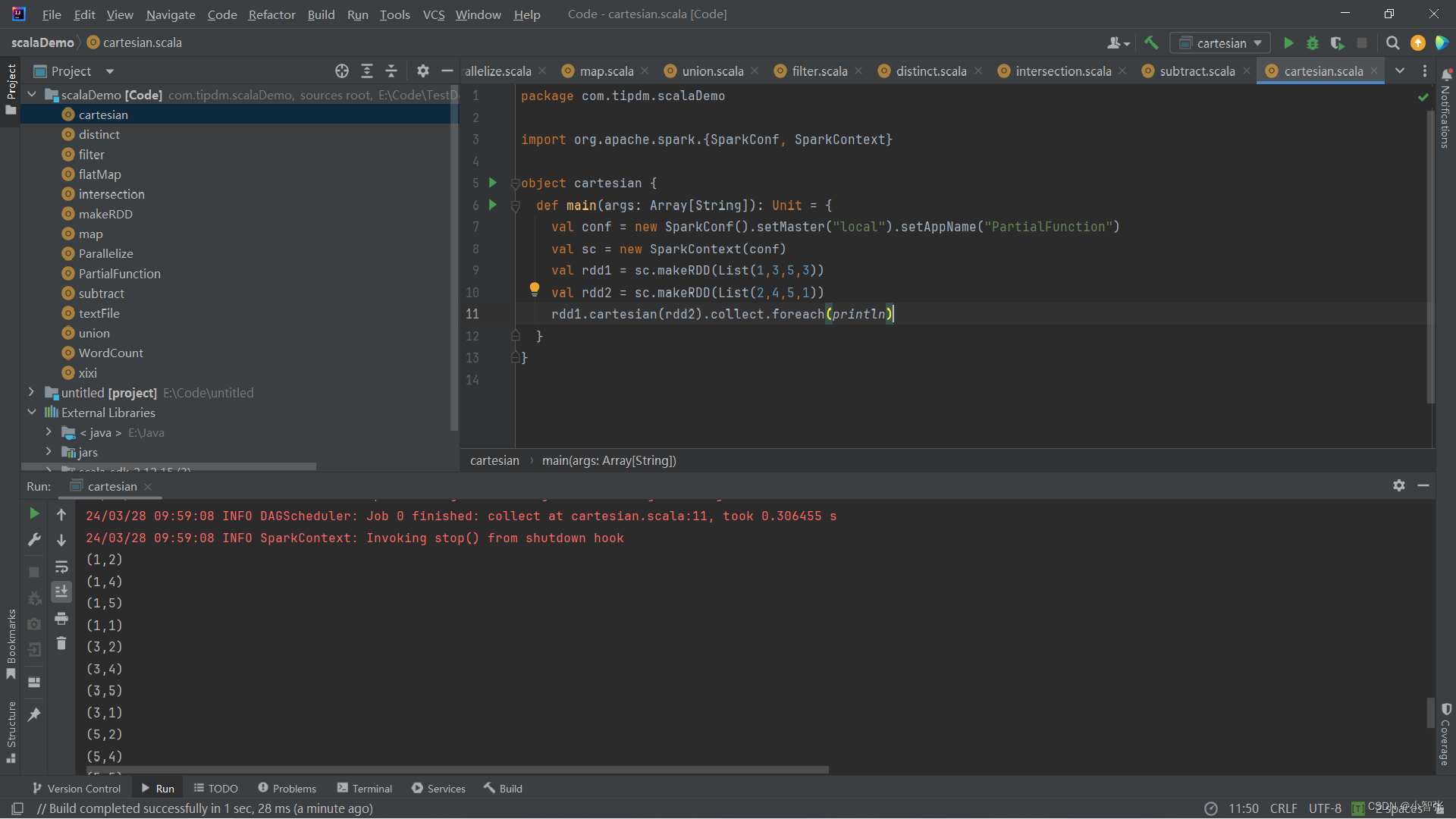
4.cartesian()方法 笛卡尔积
cartesian()方法可将两个集合的元素两两组合成一组,即求笛卡儿积。
eg:创建两个RDD,分别有4个元素,通过cartesian()方法求两个RDD的笛卡儿积。
四、键值对RDD
Spark的大部分RDD操作都支持所有种类的单值RDD,但是有少部分特殊的操作只能作用于键值对类型的RDD。
键值对RDD由一组组的键值对组成,这些RDD被称为PairRDD。PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。
创建键值对RDD
将一个普通的RDD转化为一个PairRDD时可以使用map函数

键值对RDD的常用方法
1.keys()和values()方法
Spark提供了两种方法,分别获取键值对RDD的键和值。
keys()返回一个仅包含键的RDD。
values()返回一个仅包含值的RDD。

2.reduceByKey()方法
reduceByKey()方法,一种转换操作,用于合并具有相同键的值,作用对象是键值对,并且只对每个键的值进行处理,当RDD中有多个键相同的键值对时,则会对每个键对应的值进行处理。

3.groupByKey()方法
groupByKey()方法用于对具有相同键的值进行分组,可以对同一组的数据进行计数、求和等操作。

多个RDD键的连接方法
与合并不同,连接会对键相同的值进行合并,连接方式多种多样,包含内连接、右外连接、左外连接、全外连接,不同的连接方式需要使用不同的连接方法。

1.join()方法连接两个RDD
join()方法用于根据键对两个RDD进行内连接,将两个RDD中键相同的数据的值存放在一个元组中,最后只返回两个RDD中都存在的键的连接结果。
例如,在两个RDD中分别有键值对(K,V)和(K,W),通过join()方法连接会返回(K,(V,W))。

2.rightOuterJoin()方法
rightOuterJoin()方法用于根据键对两个RDD进行右外连接,连接结果是右边RDD的所有键的连接结果,不管这些键在左边RDD中是否存在。
在rightOuterJoin()方法中,如果在左边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。

3.leftOuterJoin()方法
leftOuterJoin()方法用于根据键对两个RDD进行左外连接,与rightOuterJoin()方法相反,返回结果保留左边RDD的所有键。

4.fullOuterJoin()方法
fullOuterJoin()方法用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。

5.zip()方法
zip()方法用于将两个RDD组合成键值对RDD,要求两个RDD的分区数量以及元素数量相同,否则会抛出异常。

6.combineByKey()方法
combineByKey()方法用于将键相同的数据聚合,并且允许返回类型与输入数据的类型不同的返回值。
combineByKey()方法接收3个重要的参数,具体说明如下。
- createCombiner:V=>C,V是键值对RDD中的值部分,将该值转换为另一种类型的值C,C会作为每一个键的累加器的初始值。
- mergeValue:(C,V)=>C,该函数将元素V聚合到之前的元素C(createCombiner)上(这个操作在每个分区内进行)。
- mergeCombiners:(C,C)=>C,该函数将两个元素C进行合并(这个操作在不同分区间进行)。
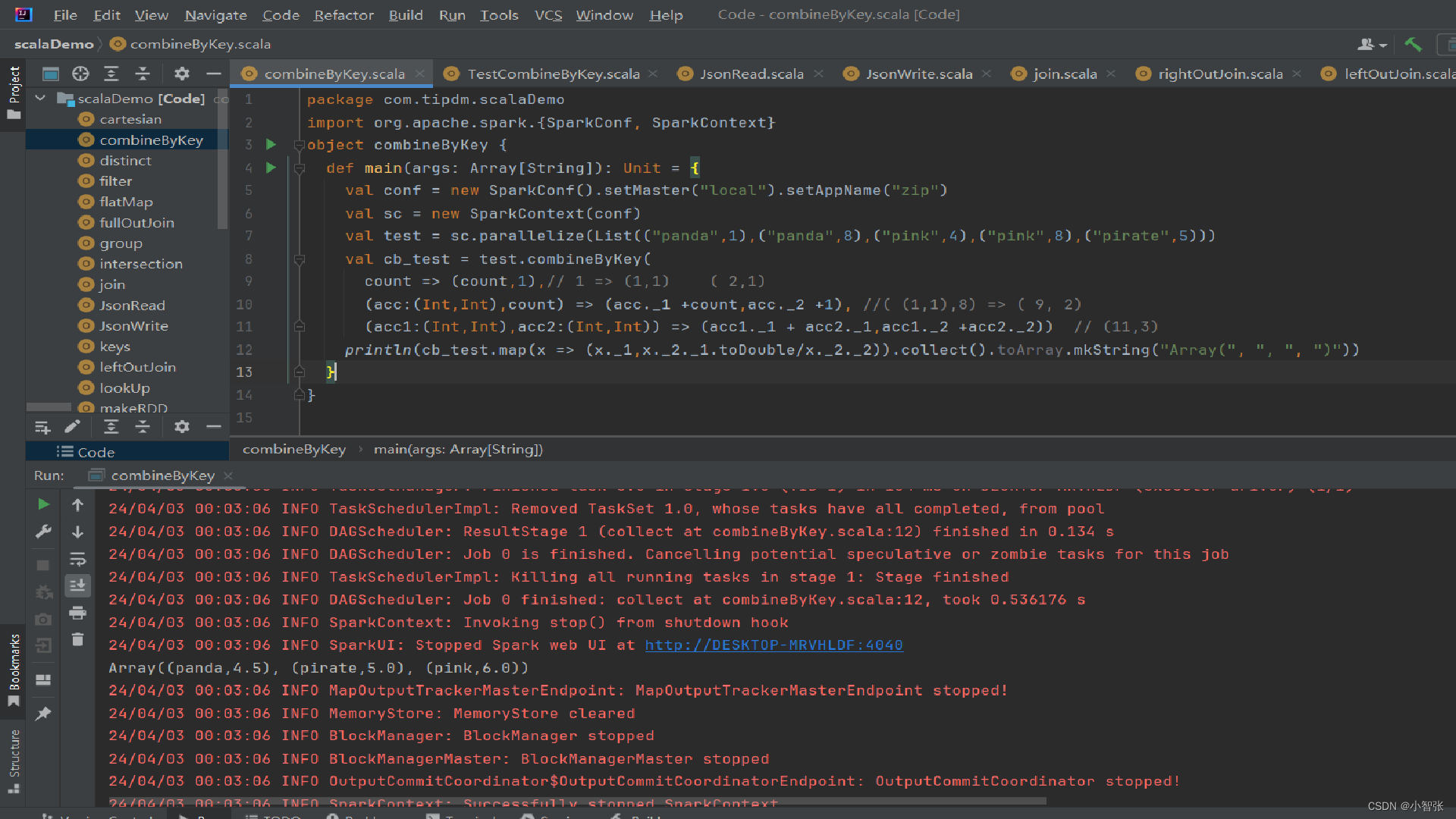
7.lookup()方法
lookup(key:K)方法作用于键值对RDD,返回指定键的所有值。
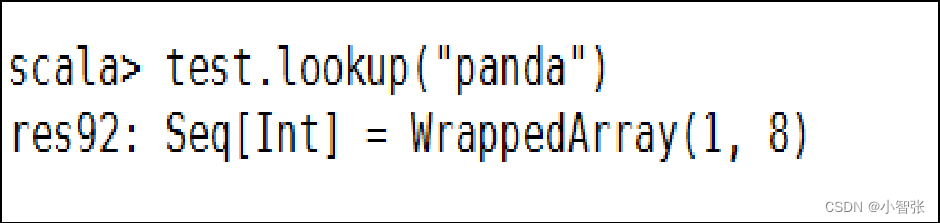
五、数据读取和保存
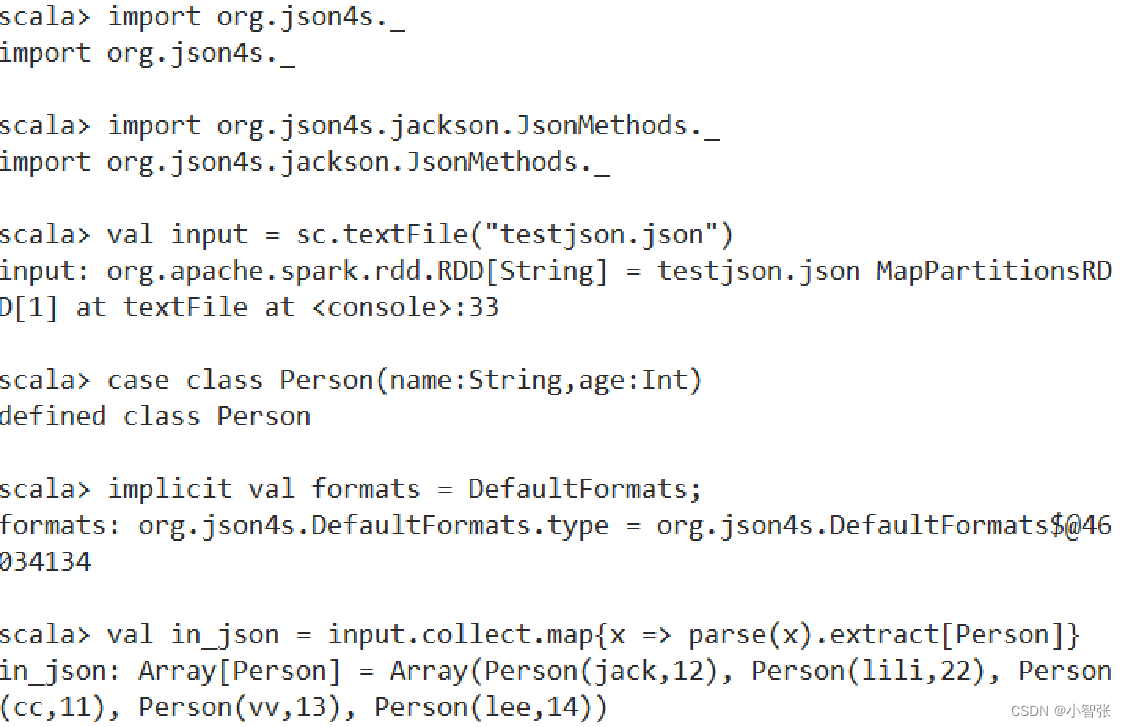
1.JSON文件
读取:
存储:
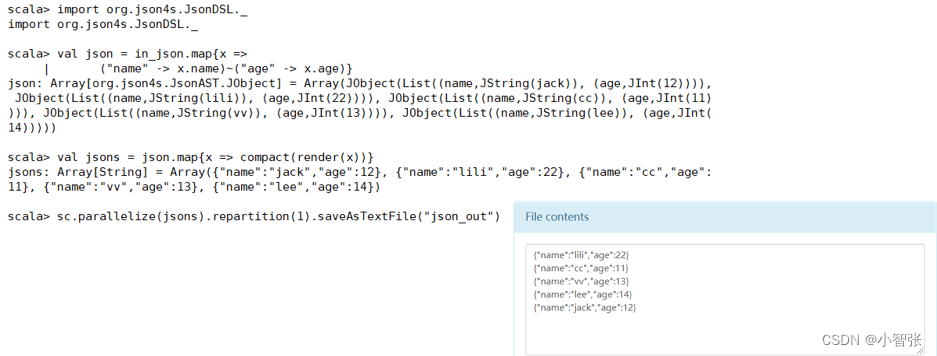
2.CSV文件
读取:
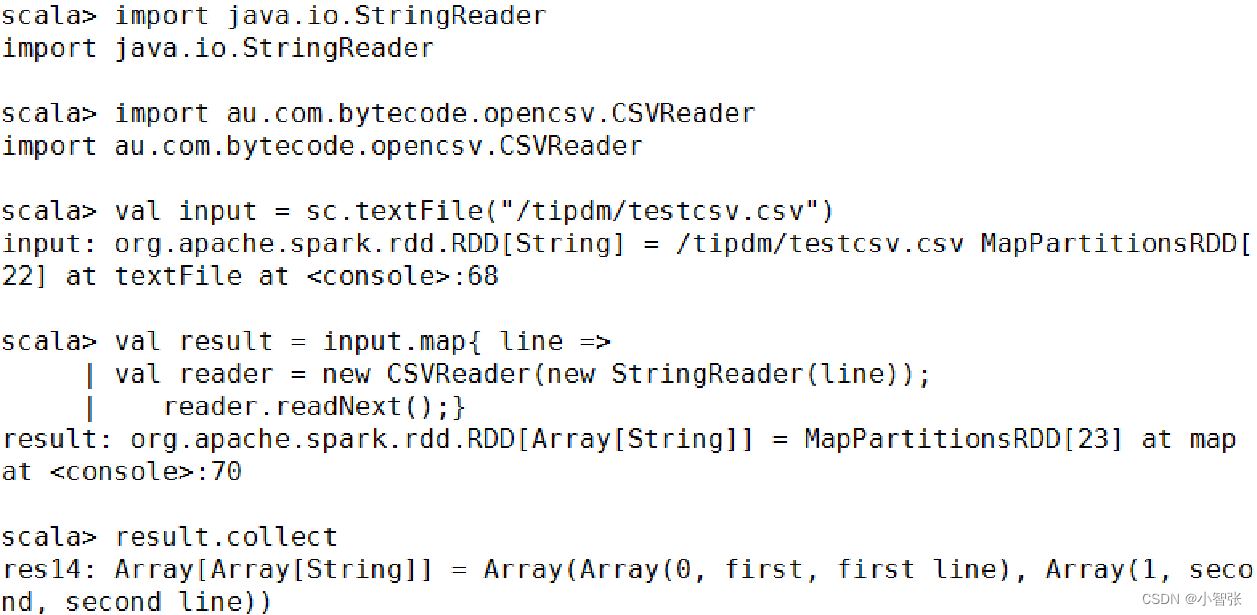
存储:
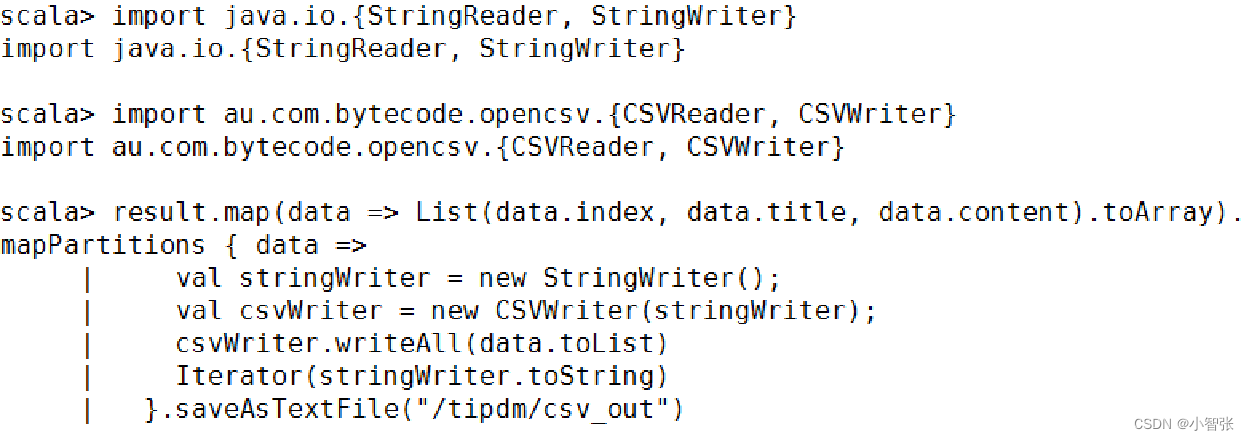
3.SequenceFile文件
读取:
 存储:
存储:
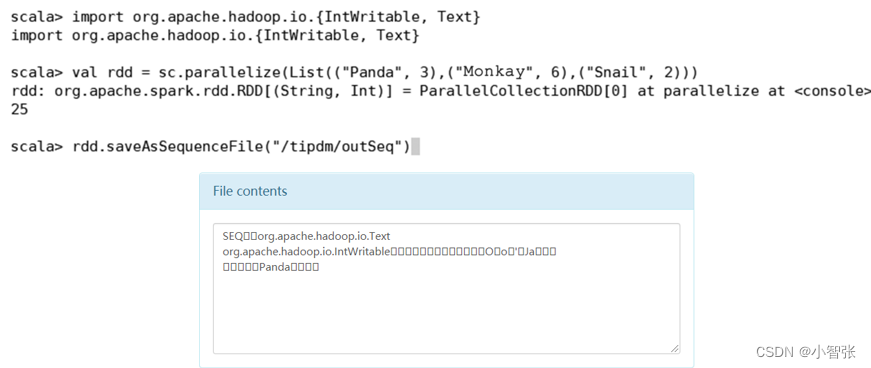 4.文本文件
4.文本文件
读取:
通过textFile()方法即可直接读取,一条记录(一行)作为一个元素。

存储:
RDD数据可以直接调用saveAsTextFile()方法将数据存储为文本文件。
版权归原作者 小智张 所有, 如有侵权,请联系我们删除。