
零.数据仓库和数据库
数据仓库和数据库的区别
数据库与数据仓库的区别:实际讲的是OLTP与OLAP的区别
OLTP(On-Line Transaction Processin):叫联机事务处理,也可以称面向用户交易的处理系统, 主要面向用户进行增删改查
OLAP(On-Line Analytical Processing):叫联机分析处理,一般针对某些主题的历史数据进行分析 主要面向分析,支持管理决策。
数据仓库主要特征:面向主题的(Subject-Oriented )、集成的(Integrated)、非易失的(Non-Volatile)和时变的(Time-Variant)
数据仓库的出现,并不是要取代数据库,主要区别如下:
数据库是面向事务的设计,数据仓库是面向主题设计的。
数据库是为捕获数据而设计,数据仓库是为分析数据而设计
数据库一般存储业务数据,数据仓库存储的一般是历史数据。
数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析。
数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计。
数据仓库基础三层架构

源数据层(ODS)(Operational Data Store):此层数据无任何更改,直接沿用外围系统数据结构和数据,不对外开放;为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。
数据仓库层(DW)(Data Warehouse):也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。
数据应用层(DA或APP)(Application):前端应用直接读取的数据源;根据报表、专题分析需求而计算生成的数据。
一.HDFS、HBase、Hive的区别
1、HDFS(分布式文件系统):
- 是Hadoop两大核心组成部分之一,提供在廉价服务器集群中进行大规模分布式文件存储的能力。
- 具有很好的容错能力,并且兼容廉价的硬件设备,因此可以较低成本利用现有机器实现大流量和大数据量的读写
2、HBase(分布式数据库):
- 是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据
- 支持超大规模数据存储,可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行数据和数百万列元素组成的数据表
3、Hive(数据仓库):
- 基于Hadoop的数据仓库工具,可以用于对存储在Hadoop文件中的数据集进行数据整理、特殊查询和分析处理。
- hive是基于hadoop的数据仓库工具,可以对于存储在hadoop文件中的数据集进行数据整理,特殊查询和分析处理
- Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
二.大数据相关软件
HDFS:负责最终数据的存储 YARN:主要提供资源的分配
Hive:用于编写SQL进行数据分析 oozie:用来做自动化定时调度
Sqoop:用于数据的导入导出 HUE:提升操作Hadoop的用户体验,基于HUE操作HDFS、Hive......
三. Hive 的优缺点
1)优点
- 操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写 MapReduce,减少开发人员的学习成本。
- Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
- Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
- Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
2)缺点
- Hive 的 HQL 表达能力有限1. 迭代式算法无法表达2. 数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却无法实现。
- Hive 的效率比较低1. Hive 自动生成的 MapReduce 作业,通常情况下不够智能化2. Hive 调优比较困难,粒度较粗
四. Hive 和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。 本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
1)查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
2)数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修 改数据。
3)执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。 当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
4)数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
五.hive架构流程
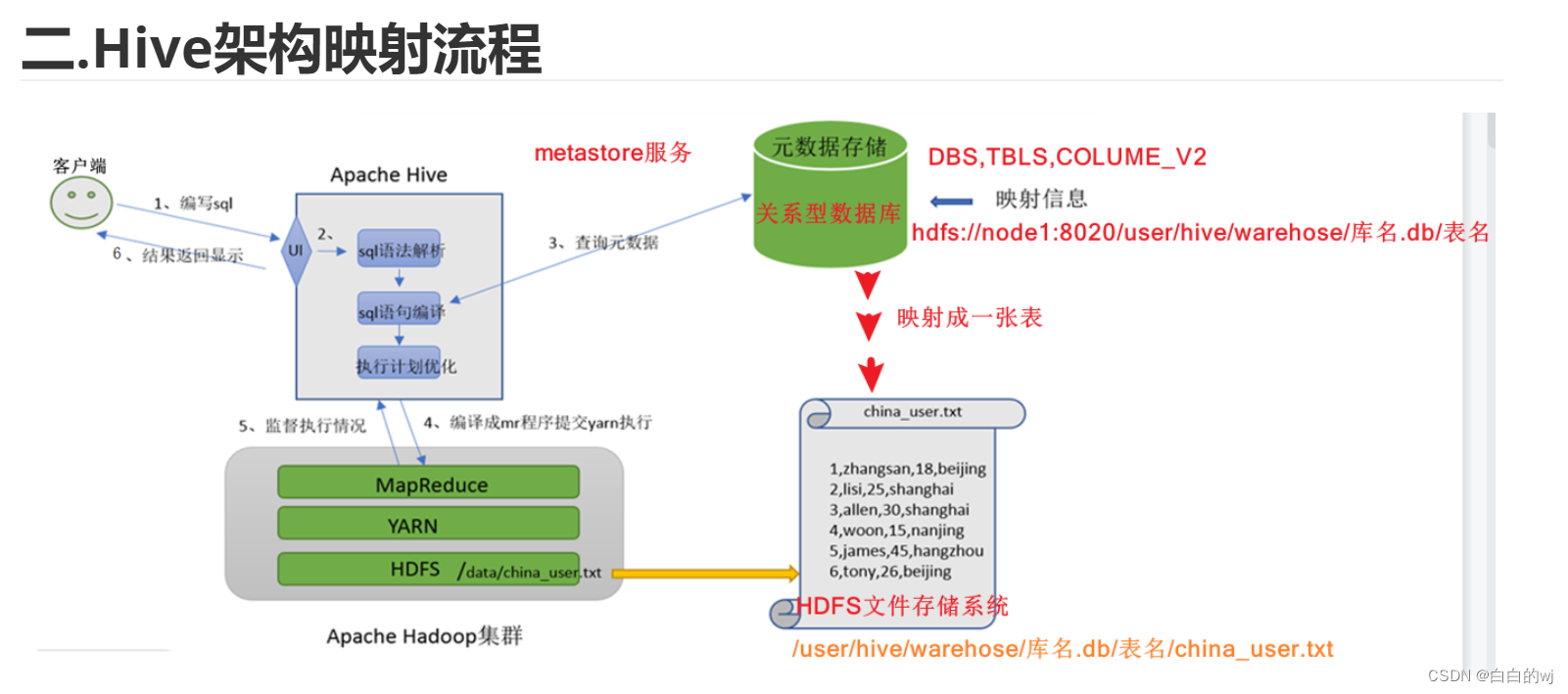

六.MetaStore服务,元数据管理三种模式
metastore服务配置有3种模式: 内嵌模式、本地模式、远程模式

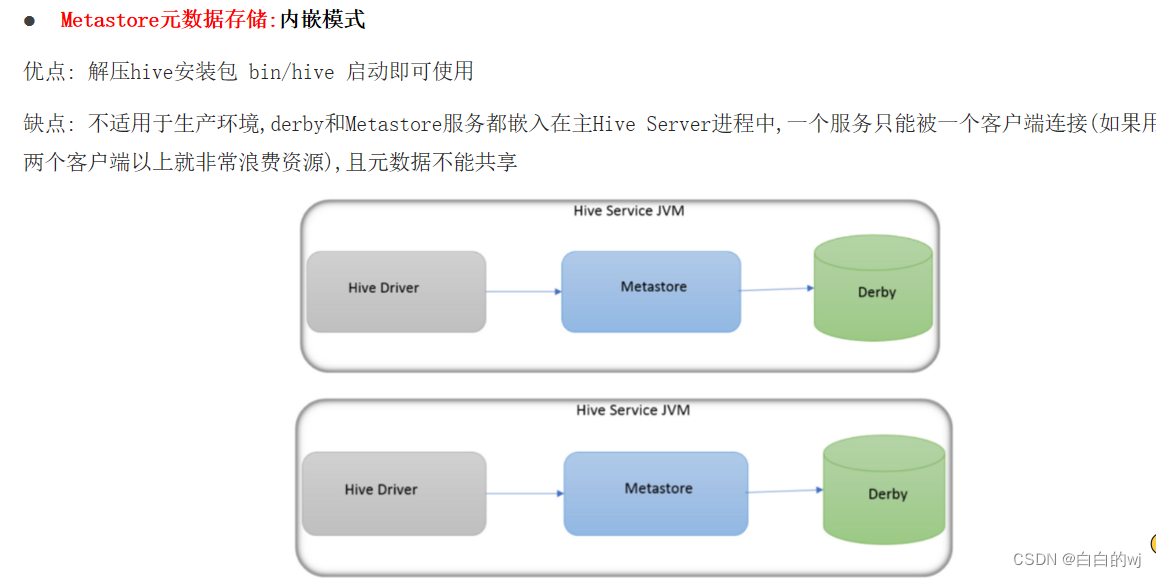
内嵌模式:
优点: 配置简单 hive命令直接可以使用
缺点: 不适用于生产环境,derby和Metastore服务都嵌入在主Hive Server进程中,一个服务只能被一个客户端连接(如果用两个客户端以上就非常浪费资源),且元数据不能共享
本地模式:
优点:可以单独使用外部的数据库(mysql),元数据共享
缺点:相对浪费资源,metastore嵌入到了hive进程中,每启动一次hive服务,都内置启动了一个metastore。

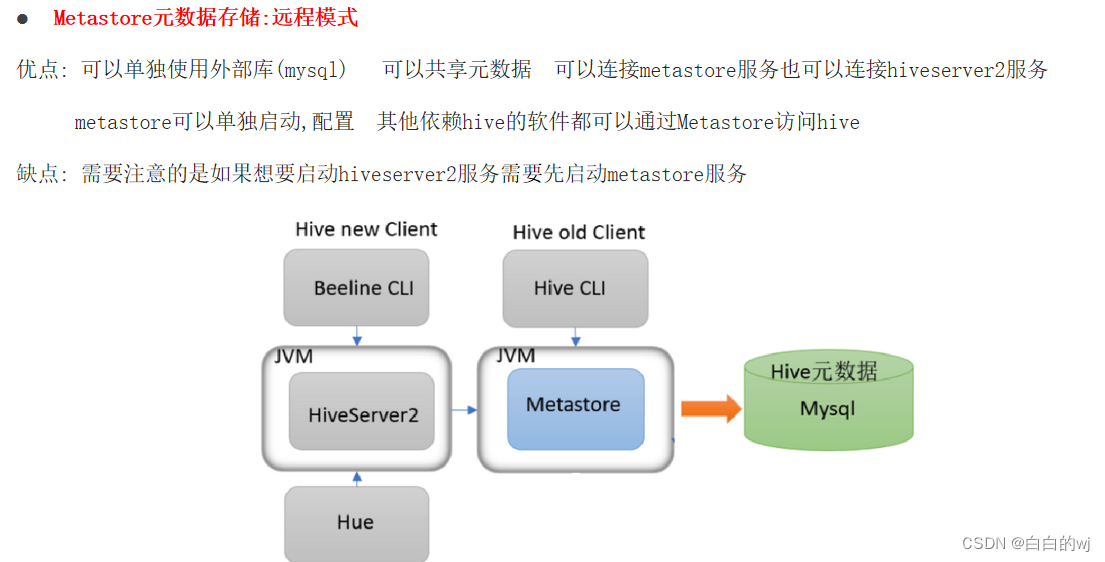
远程模式:
优点:可以单独使用外部库(mysql),可以共享元数据,本地可以连接metastore服务也可以连接hiveserver2服务,增加了扩展性(其他依赖hive的软件都可以通过Metastore访问hive)
缺点:需要注意的是如果想要启动hiveserver2服务需要先启动metastore服务
版权归原作者 白白的wj 所有, 如有侵权,请联系我们删除。