
Hadoop完全分布式安装配置*
使用的三台主机名称分别为bigdata1,bigdata2,bigdata3。所使用的安装包名称按自己的修改,安装包可去各大官网上下载*
一.JDK:
1.解压:
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
2.修改环境变量:
vim / etc/profile
三台虚拟机都要配置
在最下面添加:
JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
刷新环境变量
source /etc/profile
3.检验JDK:
输入javac:
javac
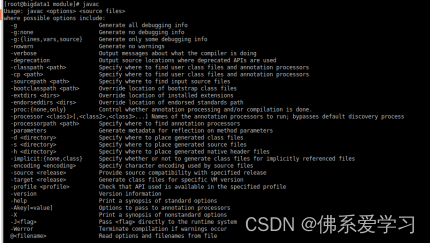
输入 java -version:
java -version

4.配置hosts
vim /etc/hosts
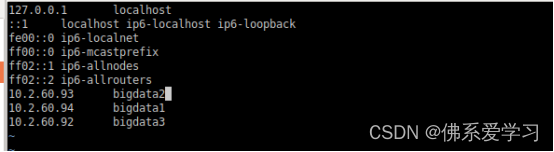
ip地址根据自己虚拟机的ip与名称进行修改
5.做免密登录:
ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
ssh-copy-id bigdata1
ssh-copy-id -i ~/.ssh/id_rsa.pub bigdata2
ssh-copy-id -i ~/.ssh/id_rsa.pub bigdata3
输入代码后根据提示输入yes或者密码
6.分发jdk:
scp -r /opt/module/jdk1.8.0_212/ root@bigdata2:/opt/module/
scp -r /opt/module/jdk1.8.0_212/ root@bigdata3:/opt/module/


二,hadoop:
7.在bigdata1将Hadoop解压到/opt/module
tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
8.添加Hadoop的环境变量
三台虚拟机都要配置
vim / etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
刷新环境变量
source / etc/proflie
9.配置文件在hadoop-3.1.3/etc/hadoop里面
①core-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata1:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
②hdfs-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>bigdata1:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata2:9868</value>
</property>
</configuration>
③yarn-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata3</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
④mapred-site.xml
vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
⑤workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
删除原有数据修改为:
bigdata1
bigdata2
bigdata3
10.分发Hadoop:
scp -r /opt/module/hadoop-3.1.3/ root@bigdata2:/opt/module/
scp -r /opt/module/hadoop-3.1.3/ root@bigdata3:/opt/module/


11.进行格式化Hadoop(三台虚拟机都要进行格式化)
hdfs namenode -format
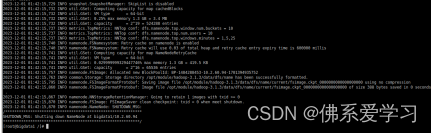
12.启动完全分布式
①在bigdata1上:
start-all.sh
②在bigdata3上:
start-yarn.sh
13.jps查看进程


本文转载自: https://blog.csdn.net/2301_77578187/article/details/135627727
版权归原作者 佛系爱学习 所有, 如有侵权,请联系我们删除。
版权归原作者 佛系爱学习 所有, 如有侵权,请联系我们删除。