
Flink CDC 实现数据实时同步
1.什么是Flink_CDC
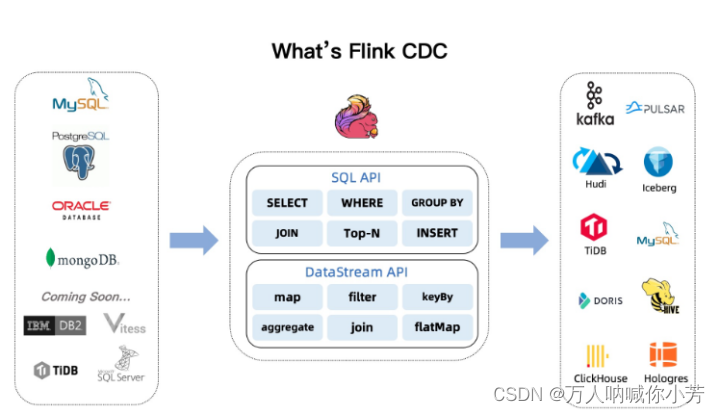
CDC 全称是 Change Data Capture(变化数据获取) ,它是一个比较广义的概念,只要能捕获变更的数据,我们都可以称为 CDC 。业界主要有基于查询的 CDC 和基于日志的 CDC ,可以从下面表格对比他们功能和差异点。
2.Flink_CDC应用场景
1.数据同步:用于备份,容灾
2.数据分发:一个数据源分发给多个下游系统
3.数据采集:面向数据仓库/数据湖的ETL数据集成,是非常重要的数据源
3.传统实时数据获取与FlinkCDC数据实时获取
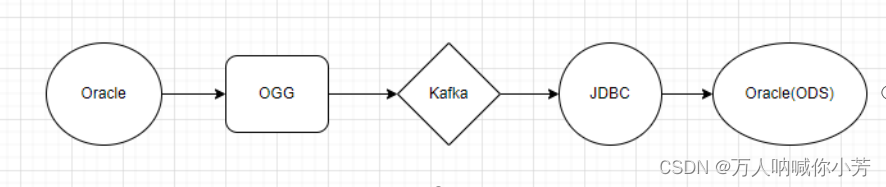
传统实时数据获取:
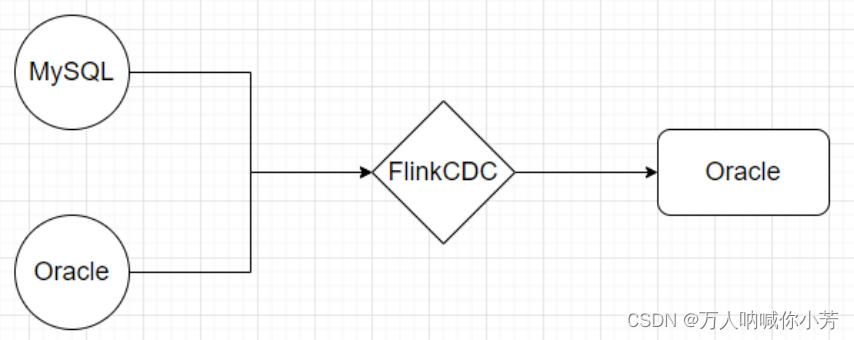
FlinkCDC实时数据获取:
对比:
Flink 1.11 引入了 Flink CDC,flink-cdc解决了普通的CDC必须通过kafka的问题,简化了流程,第一个图是普通的cdc的流程,通过cdc的工具将mysql的数据采集到kafka,在通过flink、sparkStreaming等流式计算写入到hbase、es,大数据湖等。流程相对复杂,flink-cdc做的就是可以省去普通cdc到kafka的过程。将采集、计算都在flink中完成
Flink_CDC优势:
1.Flink的操作者和SQL模块都比较成熟且易于使用
2.Flink的作业可以通过调整运算器的并行度来完成,易于扩展处理能力
3.Flink支持先进的状态后端(State Backends),允许访问大量的状态数据
4.Flink提供更多的Source和Sink等
5.Flink拥有更大的用户群和活跃的支持社区,问题更容易解决
6.Flink开源协议允许云厂商进行全托管深度定制,而Kafka Streams则只能由其自己部署和运营
7.和Flink Table/SQL模块集成了数据库表和变化记录流(例如CDC的数据流)。作为同一事物的两面,结果是Upsert Message结构(+I表示新增、-U表示记录更新前的值、+U表示记录的更新值、-D表示删除)
3.Flink CDC两种实现方式
1.FlinkDataStream_CDC实现:
利用Flink_CDC自带的连接资源,如MySQLSource通过设置hostname、port、username、password、database、table、deserializer、startupOptions等参数配置
实现获取CRUD数据变化日志
2.FlinkSQL_CDC实现:
通过FlinkSQL创建虚拟表获取关键字段的变化情况并且配置hostname、port、username、password、database、table等参数可以看到具体表数据的变化过程
注意:FlinkSQL_CDC2.0仅支持Flink1.13之后的版本
4.两种方式对比:
1.FlinkDataStream_CDC支持多库多表的操作(优点)
2.FlinkFlinkDataStream_CDC需要自定义序列化器(缺点)
3.FlinkSQL_CDC只能单表操作(缺点)
4.FlinkSQL_CDC自动序列化(优点)
5.FlinkCDC配置
·1.以DBA身份连接到数据库
su - oracle
cd /opt/oracle
sqlplus / as sysdba
·2.启用日志归档
alter system set db_recovery_file_dest_size =10G;
alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
注意:'/opt/oracle/oradata/recovery_area’对应自己的目录
·3.检查是否启用了日志归档
archive log list;
·4.为捕获日志的库或表启用日志归档
为表开启:inventory(库名).customers(表名)对应自己表
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
为库开启:--Enable supplemental logging for database
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
5.创建表空间
sqlplus /AS SYSDBA;
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/SID/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
exit;
注意:logminer_tbs用于下面
'/opt/oracle/oradata/SID/logminer_tbs.dbf’路径应该对应自己的
6.创建用户
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
7.为用户授权
CREATE TABLESPACE logminer_tbs DATAFILE '/data/dg/datafile/logminer_tbs.dbf' SIZE 1000M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
CREATE USER flinkcdc IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
GRANT CREATE SESSION TO flinkcdc;
GRANT SET CONTAINER TO flinkcdc;
GRANT SELECT ON V_$DATABASE toflinkcdc;
GRANT FLASHBACK ANY TABLE TO flinkcdc;
GRANT SELECT ANY TABLE TO flinkcdc;
GRANT SELECT_CATALOG_ROLE TO flinkcdc;
GRANT EXECUTE_CATALOG_ROLE TO flinkcdc;
GRANT SELECT ANY TRANSACTION TO flinkcdc;
GRANT LOGMINING TO flinkcdc;
GRANT CREATE TABLE TO flinkcdc;
GRANT LOCK ANY TABLE TO flinkcdc;
GRANT ALTER ANY TABLE TO flinkcdc;
GRANT CREATE SEQUENCE TO flinkcdc;
GRANT EXECUTE ON DBMS_LOGMNR TO flinkcdc;
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkcdc;
GRANT SELECT ON V_$LOG TO flinkcdc;
GRANT SELECT ON V_$LOG_HISTORY TO flinkcdc;
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkcdc;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkcdc;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkcdc;
GRANT SELECT ON V_$LOGFILE TO flinkcdc;
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkcdc;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkcdc;
#其中有两条未执行成功,替换为下面两条
GRANT EXECUTE ON SYS.DBMS_LOGMNR TO flinkcdc
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkcdc
exit;
到此CDC配置结束
7.DataStream模式代码演示
importorg.apache.flink.configuration.Configuration;importorg.apache.flink.streaming.api.datastream.DataStreamSource;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.sink.RichSinkFunction;importscala.Tuple7;importjava.sql.Connection;importjava.sql.DriverManager;importjava.sql.PreparedStatement;/**
* @since JDK 1.8
*/publicclassFlinkToOracle_2{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);DataStreamSource<Tuple7<Integer,String,String,Integer,String,String,Integer>> stream = env.addSource(newsource());
stream.addSink(newSinkOracle());
stream.print();
env.execute();}publicstaticclassSinkOracleextendsRichSinkFunction<Tuple7<Integer,String,String,Integer,String,String,Integer>>{privateConnection conn;privatePreparedStatement ps;@Overridepublicvoidopen(Configuration parameters)throwsException{super.open(parameters);Class.forName("oracle.jdbc.driver.OracleDriver");
conn=DriverManager.getConnection("jdbc:oracle:thin:@10.158.5.111:1521/orcl","ods","ods");
ps = conn.prepareStatement("insert into TEST_OGG.WORKER(ID,NAME,SEX,AGE,DEPT,WORK,SALARY) values(?,?,?,?,?,?,?)");}@Overridepublicvoidinvoke(Tuple7<Integer,String,String,Integer,String,String,Integer> value,Context context)throwsException{
ps.setInt(1, value._1());
ps.setString(2, value._2());
ps.setString(3, value._3());
ps.setInt(4, value._4());
ps.setString(5, value._5());
ps.setString(6, value._6());
ps.setInt(7, value._7());
ps.execute();
8.Flink SQL 模式代码演示
importorg.apache.flink.api.common.functions.MapFunction;importorg.apache.flink.api.java.tuple.Tuple2;importorg.apache.flink.streaming.api.datastream.DataStream;importorg.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;importorg.apache.flink.table.api.Table;importorg.apache.flink.table.api.TableResult;importorg.apache.flink.table.api.bridge.java.StreamTableEnvironment;importorg.apache.flink.types.Row;importscala.Tuple7;importorg.apache.flink.configuration.Configuration;importorg.apache.flink.streaming.api.environment.StreamExecutionEnvironment;importorg.apache.flink.streaming.api.functions.sink.RichSinkFunction;importjava.sql.Connection;importjava.sql.DriverManager;importjava.sql.PreparedStatement;/**
* @since JDK 1.8
*/publicclassFlinkSQL_CDC{publicstaticvoidmain(String[] args)throwsException{StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);StreamTableEnvironment tableEnv =StreamTableEnvironment.create(env);TableResult tableResult = tableEnv.executeSql("CREATE TABLE WORK("+"ID INT,"+"NAME STRING,"+"SEX STRING,"+"AGE INT,"+"DEPT STRING,"+"WORK STRING,"+"SALARY INT"+") WITH ("+"'connector'='oracle-cdc',"+"'hostname'='10.158.5.88',"+"'port'='1521',"+"'username'='ods',"+"'passwordd'='ods',"+"'database-name'='orcl',"+"'schema-name'='TEST_OGG',"+"'table-name'='WORKER',"+"'debezium.log.mining.continuous.mine'='true',"+"'debezium.log.mining.strategy'='online_catalog',"+"'debezium.database.tablename.case.insensitive'='false',"+"'scan.startup.mode'='latest-offset')"+"");Table resultTable = tableEnv.sqlQuery("select * from WORK");DataStream<Tuple2<Boolean,Row>> table2Datstream = tableEnv.toRetractStream(resultTable,Row.class);SingleOutputStreamOperator<Tuple7<String,String,String,String,String,String,String>> outputStream = table2Datstream.map(newMapFunction<Tuple2<Boolean,Row>,Tuple7<String,String,String,String,String,String,String>>(){@OverridepublicTuple7<String,String,String,String,String,String,String>map(Tuple2<Boolean,Row> s)throwsException{String s1 = s.f1.getField(0).toString();String s2 = s.f1.getField(1).toString();String s3 = s.f1.getField(2).toString();String s4 = s.f1.getField(3).toString();String s5 = s.f1.getField(4).toString();String s6 = s.f1.getField(5).toString();String s7 = s.f1.getField(6).toString();returnnewTuple7<String,String,String,String,String,String,String>(s1,s2,s3,s4,s5,s6,s7);}});
outputStream.addSink(newMySinkOracle220());
outputStream.print();
env.execute();}publicstaticclassMySinkOracle220extendsRichSinkFunction<Tuple7<String,String,String,String,String,String,String>>{privateConnection conn;privatePreparedStatement ps;@Overridepublicvoidopen(Configuration parameters)throwsException{super.open(parameters);Class.forName("oracle.jdbc.driver.OracleDriver");
conn=DriverManager.getConnection("jdbc:oracle:thin:@10.158.5.222:1521/dbm","ods","123456");
ps = conn.prepareStatement("insert into OGG.WORKER(ID,NAME,SEX,AGE,DEPT,WORK,SALARY) values(?,?,?,?,?,?,?)");}@Overridepublicvoidinvoke(scala.Tuple7<String,String,String,String,String,String,String> value,Context context)throwsException{
ps.setString(1, value._1());
ps.setString(2, value._2());
ps.setString(3, value._3());
ps.setString(4, value._4());
ps.setString(5, value._5());
ps.setString(6, value._6());
ps.setString(7, value._7());
ps.execute();}@Overridepublicvoidclose()throwsException{super.close();if(ps !=null)
ps.close();if(conn !=null)
conn.close();}}}
9 ·删除日志命令
su - oracle
rman target /
delete archivelog u ntil time 'sysdate' ;
crosscheck archivelog all;
delete noprompt expired archivelog all;
10.FlinkCDC问题总结
10.1CDC捕获日志问题
·initial()模式即获取创建表有史以来的日志,但是遇见布置CDC后的日志就报错
·latest()模式即获取最新的日志,但运行就报错
以上两个错误都是以下显示
错误说明:提示没有为该表设置日志归档
错误原因:cdc底层自动将配置的表名转为小写,而oracle日志的表名是大写,导致cdc无法找到配置表的日志,所以就报没有为该表配置日志归档,但这一步确实已经做过了
解决办法:
1.加配置文件
a)Stream模式:“database.tablename.case.insensitive”,“false”
b)SQL模式:‘debezium.database.tablename.case.insensitive’=‘false’
2.修改jar包底层源码,经测试失败,可能jar包依赖重,修改不到位,修改后整个项目都报错
3.升级oracle版本,据说12c版本不会出现该异常
10.2捕获数据延迟
OracleCDC的归档日志增长很快,且读取log慢,导致捕捉数据变化延迟较大
解决办法:
Stream模式:“log.mining.strategy”,“online_catalog”
“log.mining.continuous.mine” ,“true”
SQL模式: ‘debezium.log.mining.strategy’ = ‘online_catalog’
‘debezium.log.mining.continuous.mine’ = ‘true’、
10.3 日志乱码问题
如:{“scale”:0,“value”:“F3A=”},原值为6000
解决办法:
配置文件添加如下
properties.setProperty(“decimal.handling.mode”,“string”);
10.4 日志存储问题
配置时给定归档日志存储空间为10G,经测试,10G的内存很快就存满了,同时FlinkCDC官网也提示了归档日志会占用大量磁盘空间,建议定期清理过期的日志。是给予更大的内存还是定期删除日志?无论给予多大的磁盘,如果不定期清理,磁盘也会很快占满
总结
FlinkCDC有两种模式实现,FlinkDataStream模式相比FlinkSQL模式好处是可以监听多库和多表的组合,而FlinkSQL模式只能对单独一张表可进行监听;FlinkDataStream需要自己序列化,而FlinkSQL模式可以具体到关心变化的字段,不需要自己序列化。从这来看,两种模式均有优劣,从业务库的表较多来看,肯定FlinkDataStream模式更适合我们使用,直接对库进行设置日志归档,不用对每个表都设置归档日志,也不用对每个表都进行单独的监控。
版权归原作者 夜未央,温柔乡 所有, 如有侵权,请联系我们删除。