
常见问题
举个例子
提交任务命令:
bin/flink run
-t yarn-per-job
-d
-p 5 \ 指定并行度
-Dyarn.application.queue=test \ 指定 yarn 队列
-Djobmanager.memory.process.size=2048mb \ JM24G 足够8G 足够
-Dtaskmanager.memory.process.size=4096mb \ 单个 TM2
-Dtaskmanager.numberOfTaskSlots=2 \ 与容器核数 1core: 1slot 或 2core: 1slot
-c com.atguigu.flink.tuning.UvDemo
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
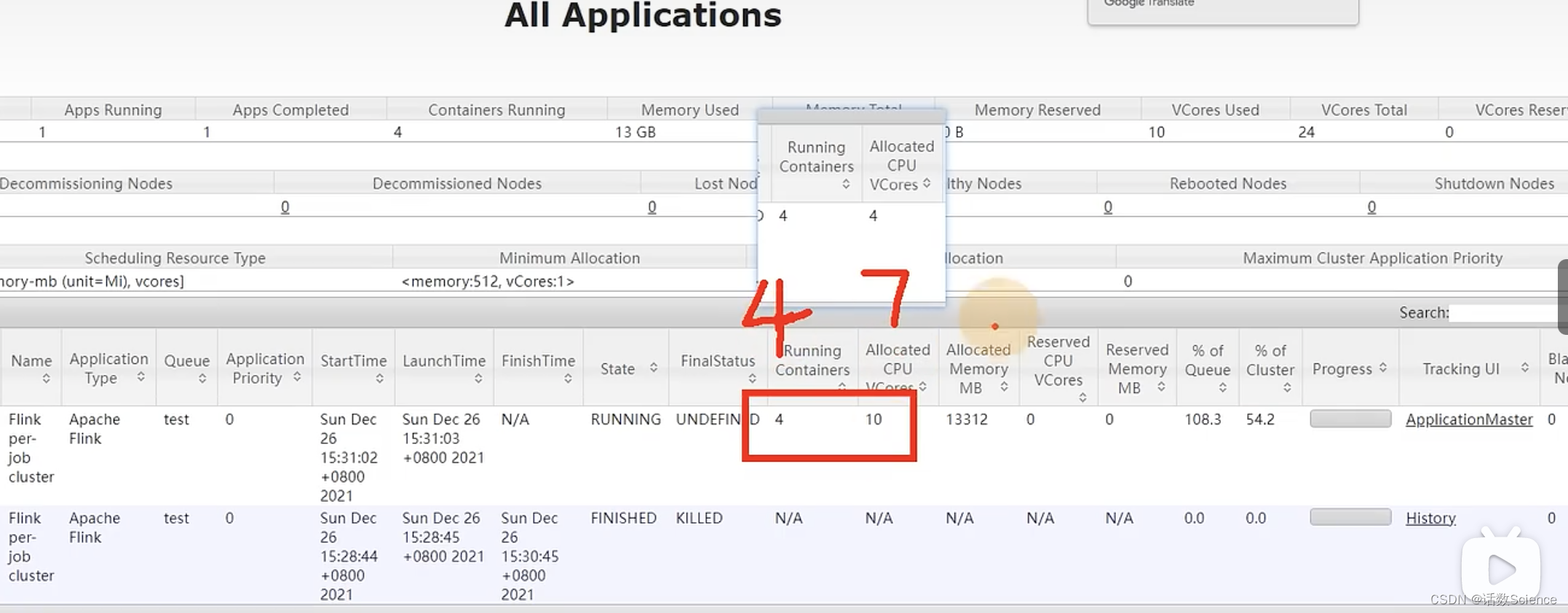
并行度为5,每个任务占用槽数为2,则需要申请3个容器(2*3=6),JobManager需要一个容器,共需要4个容器。6个vcore+JobManager的1个vcore共7个vcore。而实际上是4个容器,4个vcore,这是为什么呢?
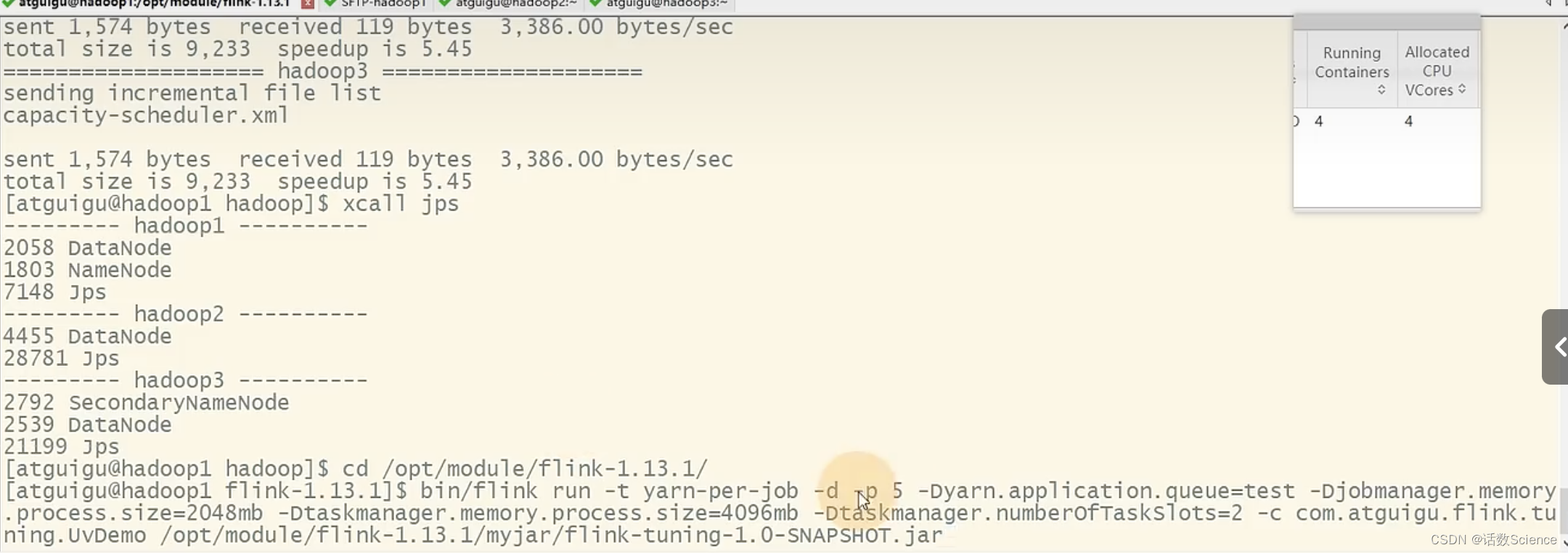
实际运行效果:
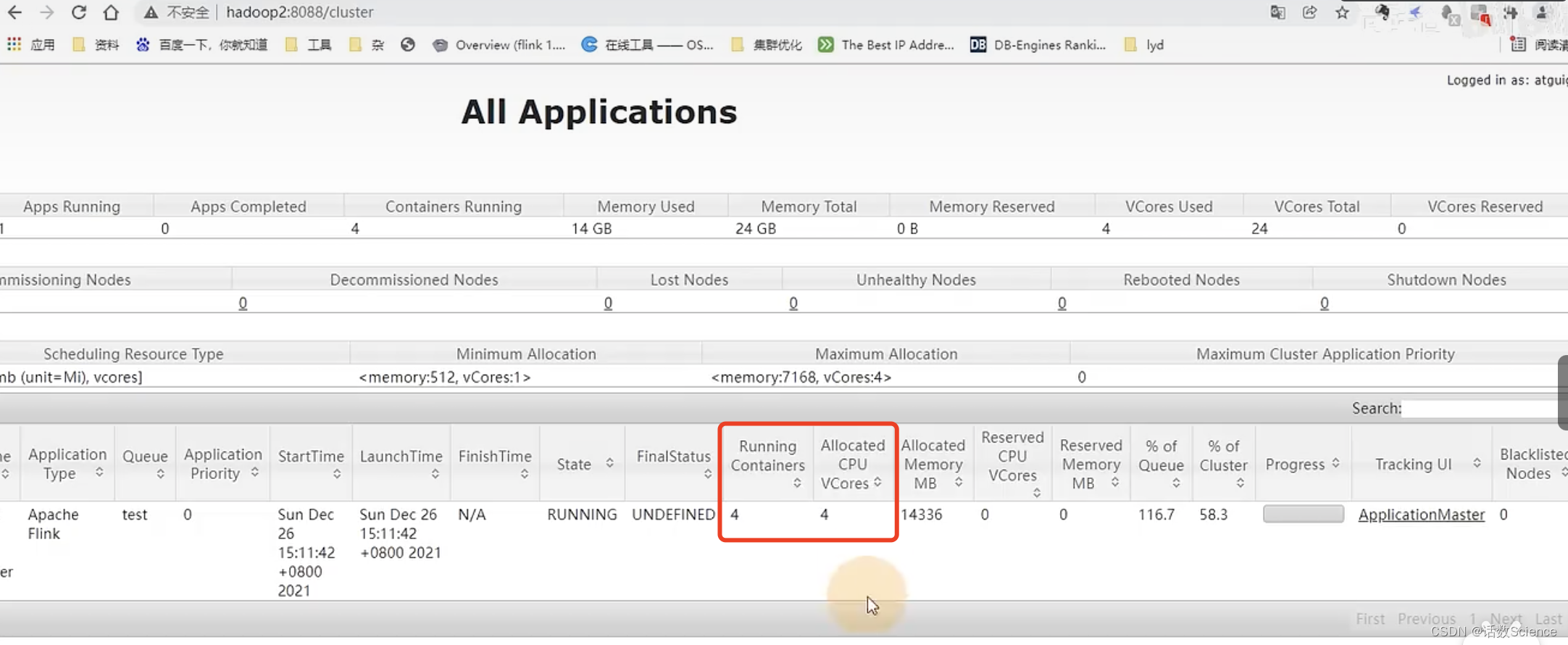
Yarn调度器设置
这跟yarn的调度器设置相关,找到capacity-scheduler.xml
- default的方式只会参考内存来申请容器,不会考虑cpu的需求。
- 调整为下面domian的方式,会综合考虑内存+CPU的需求来申请资源。
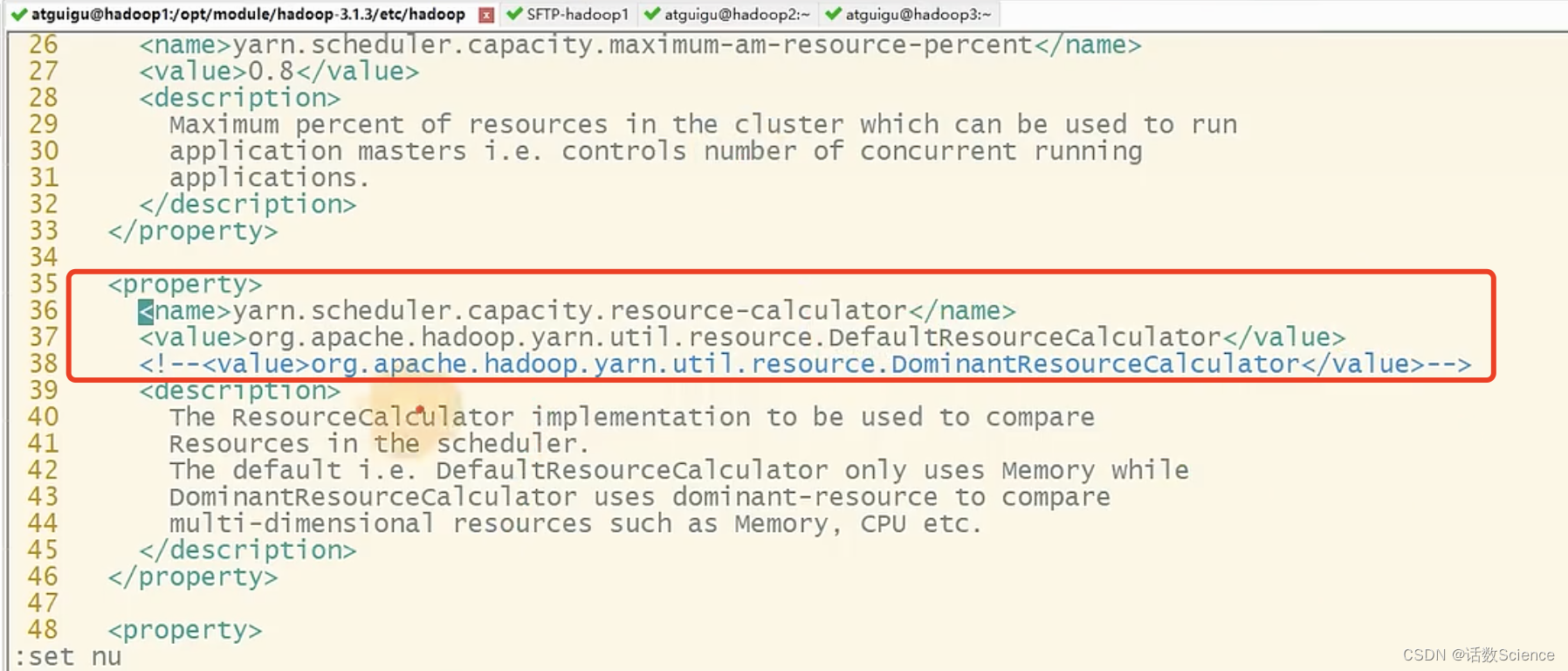
调整后运行效果:

刷新一下
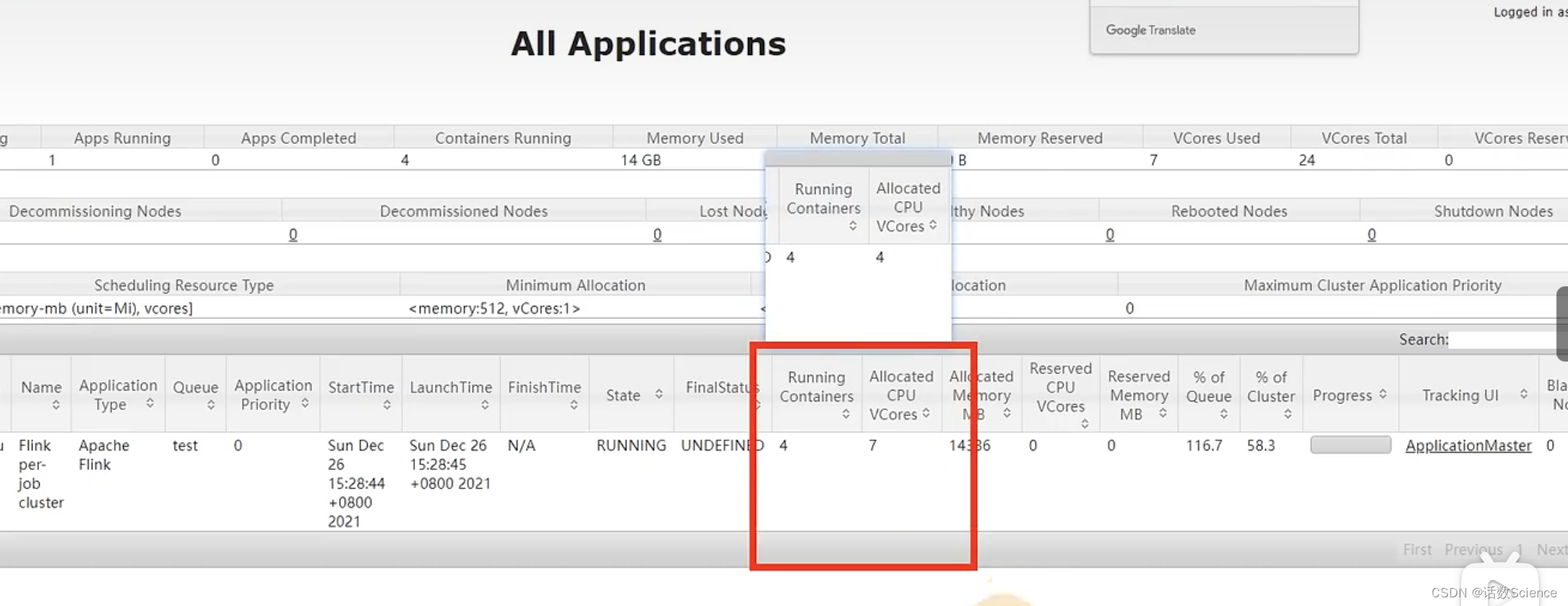 指定容器核心数
指定容器核心数
bin/flink run
-t yarn-per-job
-d
-p 5
-Drest.flamegraph.enabled=true
-Dyarn.application.queue=test
-Dyarn.containers.vcores=3
-Djobmanager.memory.process.size=1024mb
-Dtaskmanager.memory.process.size=4096mb
-Dtaskmanager.numberOfTaskSlots=2
-c com.atguigu.flink.tuning.UvDemo
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
一个容器3个核,2个slot,不是1:1的关系也可以。
slot主要隔离内存,不隔离cpu资源。
solt还有一个共享机制,一个slot可以同时跑多个task,一个solt可以不只使用一个线程。
通常让系统自动来设置,通常跟solt数1比1
并行度设置
- 配置文件:默认并行度,默认1
- 提交参数:如-p 5
- 代码env
- 代码算子
优先级下面的高。
全局并行度计算
开发完成后,先进行压测。任务并行度给 10 以下,测试单个并行度的处理上限。然后
总QPS / 单并行度的处理能力 = 并行度
QPS使用高峰期的。
开发完 Flink 作业,压测的方式很简单,先在 kafka 中积压数据,之后开启 Flink 任务,
出现反压,就是处理瓶颈。相当于水库先积水,一下子泄洪。
不能只从 QPS 去得出并行度,因为有些字段少、逻辑简单的任务,单并行度一秒处理
几万条数据。 而有些数据字段多,处理逻辑复杂, 单并行度一秒只能处理 1000 条数据。
最好根据高峰期的 QPS 压测, 并行度*1.2 倍,富余一些资源。
查看单个任务的输出量:numRecordsOutPerSecond,单并行度7000条/秒,生成环境高峰期的qps:30000/s,30000/7000 = 4.x,并行度5,再乘以个冗余1.2 = 6个
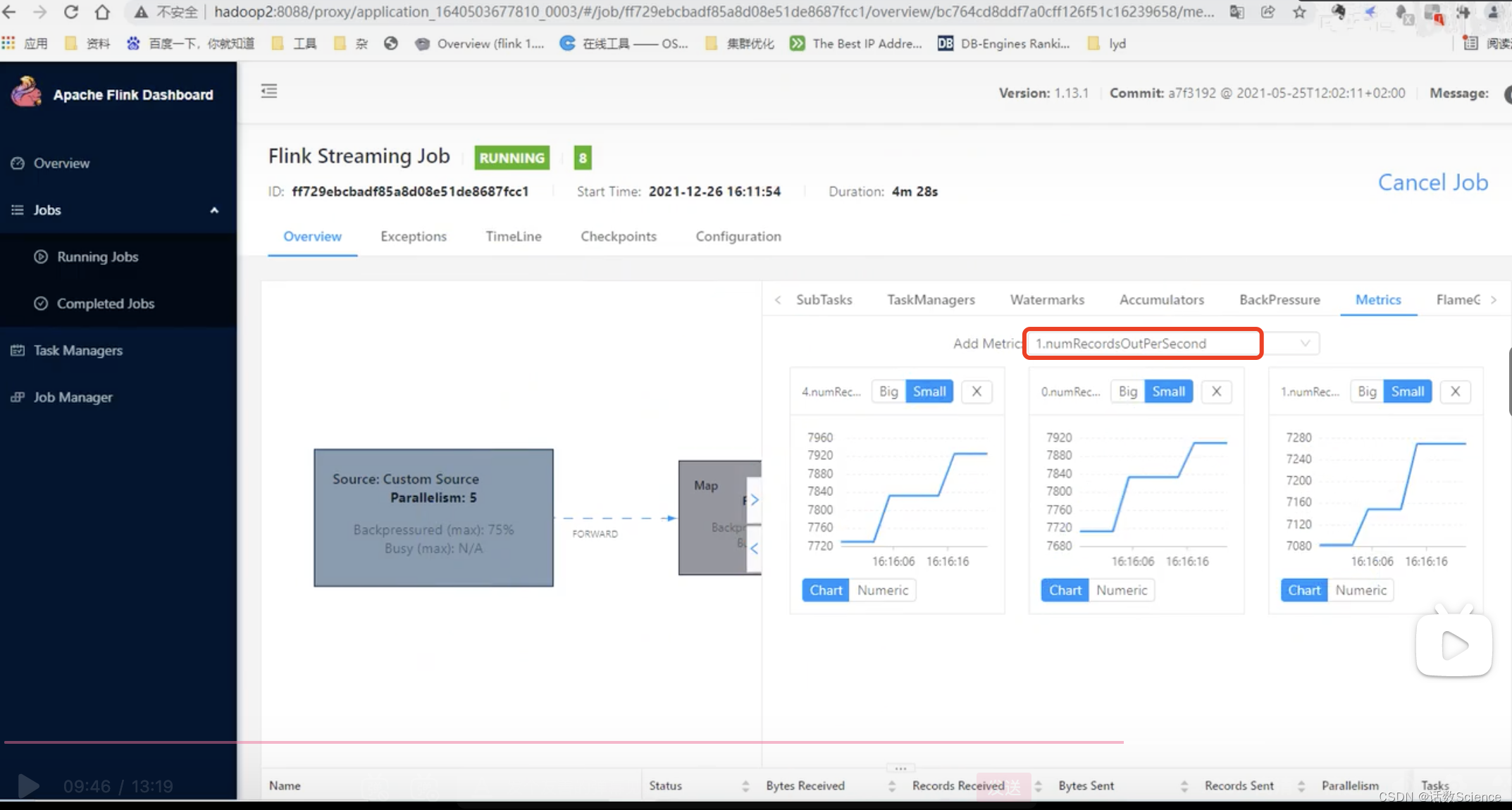
如果数据源是kafka,可以按kafka分区数来设置并行度。
大部分情况下并行度10以下即可。
Source 端并行度的配置
数据源端是 Kafka, Source 的并行度设置为 Kafka 对应 Topic 的分区数。
如果已经等于 Kafka 的分区数, 消费速度仍跟不上数据生产速度, 考虑下 Kafka 要扩
大分区, 同时调大并行度等于分区数。
Flink 的一个并行度可以处理一至多个分区的数据,如果并行度多于 Kafka 的分区数,
那么就会造成有的并行度空闲,浪费资源。
Transform 端并行度的配置
Keyby 之前的算子
一般不会做太重的操作,都是比如 map、 filter、 flatmap 等处理较快的算子,并行度
可以和 source 保持一致。
Keyby 之后的算子
如果并发较大,建议设置并行度为 2 的整数次幂,例如: 128、 256、 512;
小并发任务的并行度不一定需要设置成 2 的整数次幂;
大并发任务如果没有 KeyBy,并行度也无需设置为 2 的整数次幂;
Sink 端并行度的配置
Sink 端是数据流向下游的地方,可以根据 Sink 端的数据量及下游的服务抗压能力进行评估。 如果 Sink 端是 Kafka,可以设为 Kafka 对应 Topic 的分区数。
Sink 端的数据量小, 比较常见的就是监控告警的场景,并行度可以设置的小一些。
Source 端的数据量是最小的,拿到 Source 端流过来的数据后做了细粒度的拆分,数据量不断的增加,到 Sink 端的数据量就非常大。那么在 Sink 到下游的存储中间件的时候就需要提高并行度。
另外 Sink 端要与下游的服务进行交互,并行度还得根据下游的服务抗压能力来设置,如果在 Flink Sink 这端的数据量过大的话, 且 Sink 处并行度也设置的很大,但下游的服务完全撑不住这么大的并发写入,可能会造成下游服务直接被写挂,所以最终还是要在 Sink处的并行度做一定的权衡。
版权归原作者 话数Science 所有, 如有侵权,请联系我们删除。