
鸿蒙NEXT开发实战往期必看文章:
一分钟了解”纯血版!鸿蒙HarmonyOS Next应用开发!
“非常详细的” 鸿蒙HarmonyOS Next应用开发学习路线!(从零基础入门到精通)
HarmonyOS NEXT应用开发案例实践总结合(持续更新......)
HarmonyOS NEXT应用开发性能优化实践总结(持续更新......)
长列表优化概述
列表是应用开发中最常见的一类开发场景,它可以将杂乱的信息整理成有规律、易于理解和操作的形式,便于用户查找和获取所需要的信息。应用程序中常见的列表场景有新闻列表、购物车列表、各类排行榜等。随着信息数据的累积,特别是一些新闻应用、购物应用、聊天应用,列表数据往往会达到上万条,针对这类大量数据加载的长列表应用,如何对长列表的性能进行优化是非常重要的。一个正确、高性能的长列表应用能明显降低列表渲染时间、提升页面的滑动帧率、降低应用内存占用,大幅提升用户体验。
针对长列表加载这一场景,本文将介绍如下5种优化手段,通过这些优化手段的单个使用或组合使用,可以对列表渲染时间、页面滑动帧率、应用内存占用等方面带来优化,提升性能和用户体验:
- 懒加载:提供列表数据按需加载能力,解决一次性加载长列表数据耗时长、占用过多资源的问题,可以提升页面响应速度。
- 缓存列表项:提供屏幕可视区域外列表项长度的自定义调节能力,配合懒加载设置可缓存列表项参数,通过预加载数据提升列表滑动体验。
- 动态预加载:根据历史任务加载耗时情况,动态调整屏幕可视区域外数据预取数量,配合懒加载设置,可在列表不断滑动时,屏幕可视区外实时更新列表数据,通过预取和预渲染数据提升列表滑动体验。
- 组件复用:提供可复用组件对象的缓存资源池,通过重复使用已经创建过并缓存的组件对象,降低相同组件短时间内频繁创建和销毁的开销,提升组件渲染效率。
- 布局优化:使用扁平化布局方案,减少视图嵌套层级和组件数,避免过度绘制,提升页面渲染效率。
下文将以 “HMOS世界”中首屏的长列表加载为例,通过5个测试来验证列表优化前后性能的收益,以证明这些优化手段的可行性。综合考虑业界共识指标和实际用户使用体验,测试将对比分析如下几个关键指标,这些关键指标的测量方法可以参考《帧率和丢帧分析实践》:
- 完全显示所用时间(Time To Full Display, TTFD):表示应用生成具有完整内容的第一帧所用时间,包括在第一帧之后异步加载的内容。本文测量的是不同数据量下长列表首次加载到屏幕上所用的时间。
- 丢帧率(Janky Frames):表示一个时间周期内的丢帧比率,指一个时间周期内有问题的帧比例。HarmonyOS系统要求每一帧都要在 11.1ms(90Hz刷新率)内绘制完成,如果页面没有在 11.1ms内完成这一帧的绘制,就会出现丢帧。部分丢帧一般用户肉眼是感知不到的,只有出现连续丢帧用户才有明显感知。
- 独占内存(Unique Set Size,USS):一个进程所占用的私有内存,即该进程独占的内存。 它反映了运行一个特定进程真实的边际成本(增量成本)。当一个进程被销毁后,独占内存是真实返回给系统的内存。当进程中存在可疑的内存泄露时,独占内存是最佳观察数据。
测试表明,使用LazyForEach懒加载这项技术后,相比ForEach这种加载方式,在列表数据量较小(100条内)且数据一次性全量加载不是性能瓶颈时,两者各项性能指标差异不大。但当列表数据较长特别是达到10000条数据量后,ForEach的各项性能指标会有“指数级别”的显著劣化,滑动会出现明显的卡顿,甚至会出现应用crash等现象;而LazyForEach因为采用了懒加载、缓存列表项、组件复用等技术后,能明显减少首屏完全显示所用时间,降低应用的独占内存,提高页面滑动帧率,带来更好的性能。其对比效果如下所示:
**图1 **10000条数据量下ForEach和LazyForEach最佳实践启动对比

**图2 **10000条数据量下ForEach和LazyForEach最佳实践滑动对比

懒加载
原理介绍
HarmonyOS应用框架为容器类组件的数据加载和渲染提供了2种方式:
- 方式一,循环渲染 通过循环渲染(ForEach)从数组中获取数据,并为每个数据项创建相应的组件,可减少代码复杂度。
ForEach( arr: any[], itemGenerator: (item: any, index?: number) => void, keyGenerator?: (item: any, index?: number) => string ) - 方式二,数据懒加载 通过数据懒加载(LazyForEach)从提供的数据源中按需迭代数据,并在每次迭代过程中创建相应的组件。
LazyForEach( dataSource: IDataSource, itemGenerator: (item: any) => void, keyGenerator?: (item: any) => string ): voidinterface IDataSource { totalCount(): number; getData(index: number): any; registerDataChangeListener(listener: DataChangeListener): void; unregisterDataChangeListener(listener: DataChangeListener): void;}interface DataChangeListener { onDataReloaded(): void; onDataAdd(index: number): void; onDataMove(from: number, to: number): void; onDataDelete(index: number): void; onDataChange(index: number): void; }
ForEach
ForEach循环渲染的过程如下:
- 从列表数据源一次性加载全量数据。
- 为列表数据的每一个元素都创建对应的组件,并全部挂载在组件树上。即,ForEach遍历多少个列表元素,就创建多少个ListItem组件节点并依次挂载在List组件树根节点上。
- 列表内容显示时,只渲染屏幕可视区内的ListItem组件,可视区外的ListItem组件滑动进入屏幕内时,因为已经完成了数据加载和组件创建挂载,直接渲染即可。
其数据加载、组件树挂载、页面渲染的示意图如下所示:
**图3 **ForEach渲染过程示意图
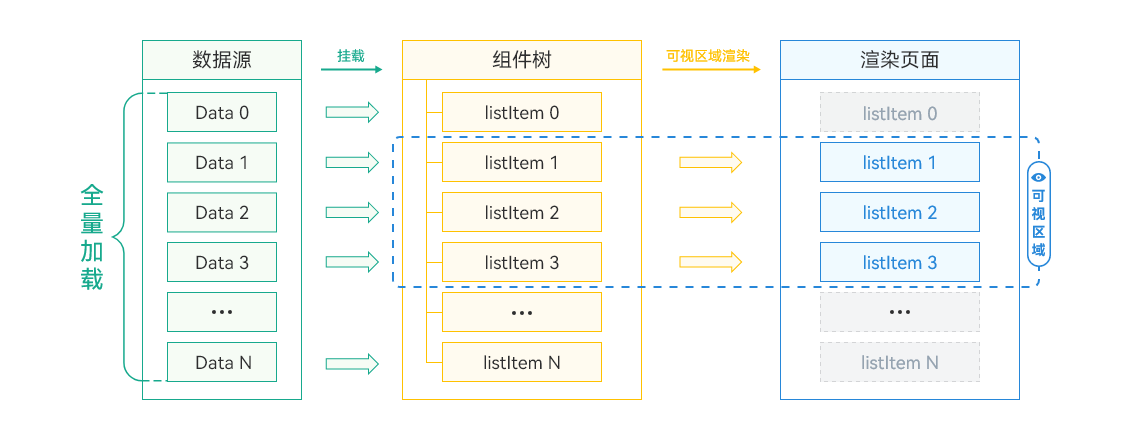
如果列表数据较少,数据一次性全量加载不是性能瓶颈时,可以直接使用ForEach;但是当数据量大、组件结构复杂的情况下ForEach会出现性能瓶颈。这是因为要一次性加载所有的列表数据,创建所有组件节点并完成组件树的构建,在数据量大时会非常耗时,从而导致页面启动时间过长。另外,屏幕可视区外的组件虽然不会显示在屏幕上,但是仍然会占用内存。在系统处于高负载的情况下,更容易出现性能问题,极限情况下甚至会导致应用异常退出。
为了解决上述可能出现的问题,HarmonyOS应用框架进一步提供了懒加载方式 。
LazyForEach
LazyForEach懒加载的原理和渲染过程如下:
- LazyForEach会根据屏幕可视区能够容纳显示的组件数量按需加载数据。
- 根据加载的数据量创建组件,挂载在组件树上,构建出一棵短小的组件树。即,屏幕可以展示多少列表项组件,就按需创建多少个ListItem组件节点挂载在List组件树根节点上。
- 屏幕可视区只展示部分组件。当可视区外的组件需要在屏幕内显示时,需要从头完成数据加载、组件创建、挂载组件树这一过程,直至渲染到屏幕上。
其数据加载、组件树挂载、页面渲染的示意图如下所示:
**图4 **LazyForEach渲染过程示意图
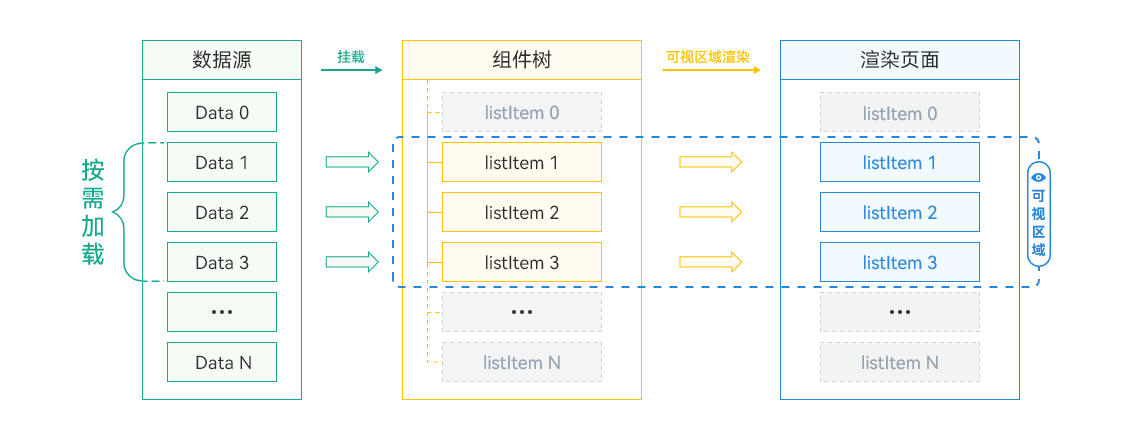
LazyForEach实现了按需加载,针对列表数据量大、列表组件复杂的场景,减少了页面首次启动时一次性加载数据的时间消耗,减少了内存峰值。不过在长列表滑动的过程中,因为需要根据用户的滑动行为不断地加载新的内容,这需要进行额外的数据请求和处理,会增加滑动时的计算量,从而对性能产生一定的影响。然而,合理使用LazyForEach的按需加载能力,通过在滑动停止或达到某个阈值时才进行加载,可以减少不必要的计算和请求,从而提高性能,给用户带来更好的体验。总之,在实现按需加载的场景中,需要综合考虑性能和用户体验的平衡,合理地优化加载逻辑和渲染方式,以提升整体的性能表现。
使用场景和规则
使用场景
上文了解到ForEach是从列表数据源一次性加载全量数据,且一次性并全部挂载在组件树上;LazyForEach是按需加载部分数据,只构建出一棵短小的组件树。针对数据加载和组件树构建这两个显著差异,可以对ForEach/LazyForEach做出如下选型判断:
**表1 **使用场景和选型原则
渲染接口
选型原则
ForEach
列表数据较少,数据一次性全量加载不是性能瓶颈时。ForEach相对LazyForEach,代码简单很多。
LazyForEach
列表数据较长,一次性加载所有的列表数据创建、渲染页面产生性能瓶颈时。
使用规则
详细的使用规则可以参考ForEach的使用建议和LazyForEach的使用限制。
场景案例
为了对比List组件在不同数据量下使用ForEach和LazyForEach的性能差异,可以对相关代码进行了改造,先用ForEach对列表进行循环,再用LazyForEach对列表进行改造,得到如下两段关键代码:
- 对比案例1:使用ForEach对List列表进行加载
// entry/src/main/ets/pages/ForEachListPage@Entry@Componentexport struct ForEachListPage { // ... build() { Column() { Header() List({ space: Constants.SPACE_16 }) { ForEach(this.articleList, (item: LearningResource) => { ListItem() { Column({ space: Constants.SPACE_12 }) { ArticleCardView({ articleItem: item, isLiked: this.isLiked(item.id), isCollected: this.isCollected(item.id) }) } } }, (item: LearningResource) => item.id) } .width(Constants.FULL_SCREEN) .height(Constants.FULL_SCREEN) .margin({ left: 10, right: 10 }) .layoutWeight(1) } .backgroundColor($r('app.color.text_background')) }} - 对比案例2:使用LazyForEach对List列表进行加载
// entry/src/main/ets/pages/LazyForEachListPage@Entry@Componentexport struct LazyForEachListPage { // ... build() { Column() { Header() List({ space: Constants.SPACE_16 }) { if (this.data !== null) { // 使用懒加载 LazyForEach(this.data, (item: LearningResource) => { ListItem() { Column({ space: Constants.SPACE_12 }) { ArticleCardView({ articleItem: item, isLiked: this.isLiked(item.id), isCollected: this.isCollected(item.id) }) } } }, (item: LearningResource) => item.id) } } .width(Constants.FULL_SCREEN) .height(Constants.FULL_SCREEN) .margin({ left: 10, right: 10 }) .layoutWeight(1) } .backgroundColor($r('app.color.text_background')) }}
说明
LazyForEach的数据源首先需要开发者实现IDataSource接口,具体实现可参考“HMOS世界”中的相关代码(DiscoverView.ets)。
性能分析
针对长列表这一场景,在本地模拟了10、100、1000、10000条数据,分别使用ForEach、LazyForEach,来测试关闭和开启懒加载情况下的完全显示所用时间、列表挂载时间、独占内存,并分析了其滑动过程中的丢帧率。其中,列表挂载时间是指创建组件和组件挂载数据的总时长。最终,使用IDE的Profiler工具检测下述指标,得到的数据如下所示:
**表2 **ForEach在不同数据量下的指标对比
ForEach对比指标
10条数据
100条数据
1000条数据
10000条数据
完全显示所用时间
1s 741ms
1s 786ms
1s 942ms
5s 841ms
列表挂载时间
87ms
88ms
135ms
3s 291ms
独占内存(滑动完成后)
38.2MB
48.7MB
83.7MB
560.1MB
丢帧率
0.0%
3.8%
4.5%
58.2%
**表3 **LazyForEach在不同数据量下的指标对比
LazyForEach对比指标
10条数据
100条数据
1000条数据
10000条数据
完全显示所用时间
1s 544ms
1s 486ms
1s 652ms
1s 707ms
列表挂载时间
88ms
89ms
94ms
97ms
独占内存(滑动完成后)
38.1MB
44.6MB
46.3MB
82.9MB
丢帧率
0.0%
2.3%
3.6%
6.6%
**图5 **ForEach和LazyForEach在不同数据量下的指标对比
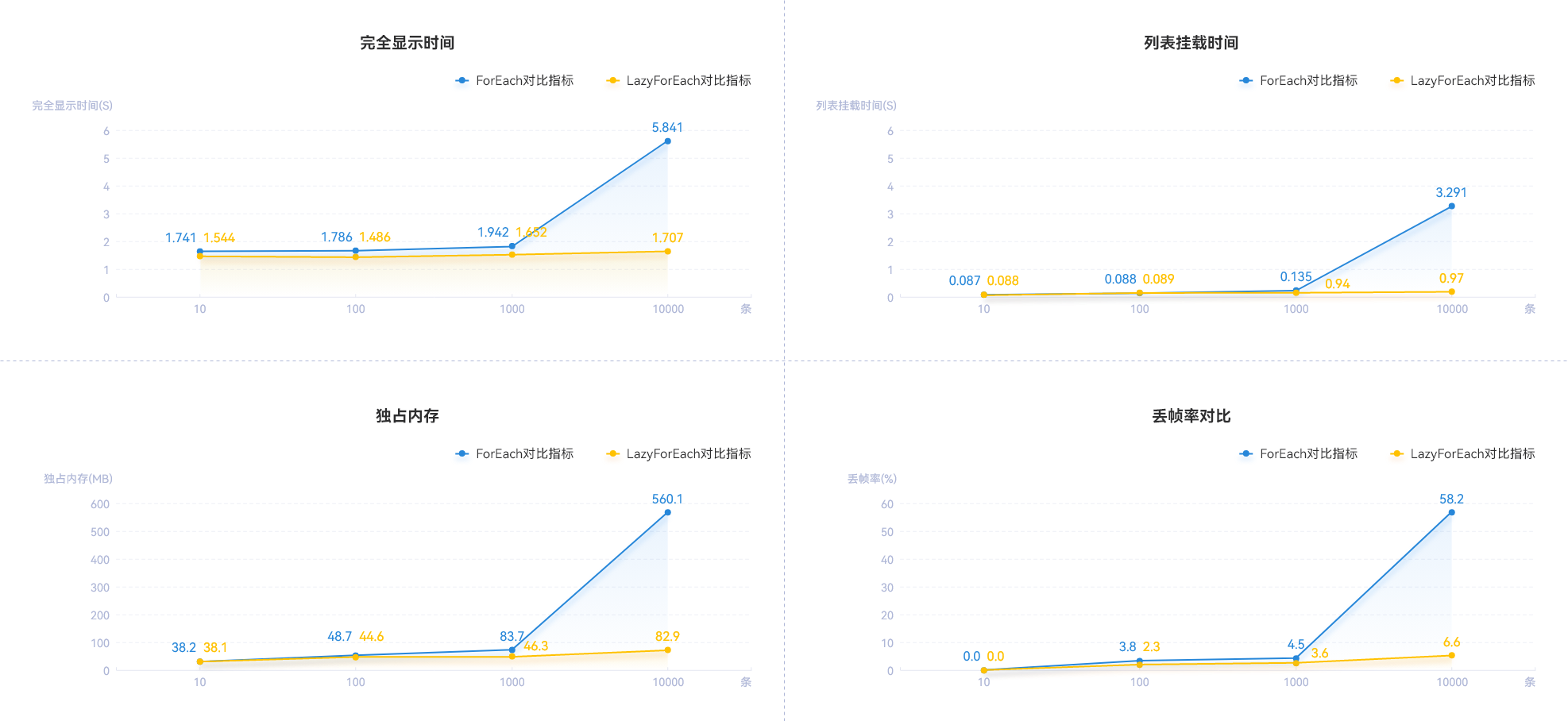
从测试数据可以看出:
- 在100条数据范围内ForEach和LazyForEach差距不大,总体而言两者各项性能指标都在可接受范围内,而ForEach代码逻辑比LazyForEach简单,此场景下使用ForEach即可。
- 当数据大于1000条,特别是当数据达到10000条时,ForEach在列表渲染、应用内存占用、丢帧率等各个方面都会有“指数级别”的显著劣化,滑动会出现明显的卡顿,甚至会出现应用crash等现象。
- 使用LazyForEach除了最后内存稍微增大以外,其列表渲染时间、丢帧率都不会出现明显变化,具有较好的性能。 说明以上数据来源均为版本DevEco Studio 4.0.3.415、SDK 4.0.10.9条件下测试得到,不同设备类型数据可能存在差异,测试数据旨在体现性能优化趋势,仅供参考。
缓存列表项
原理介绍
从上文了解到,在进行列表加载时需要尽量避免一次性加载全部列表数据项,即推荐按需加载列表数据,但实际上这个“需”是有讲究的。例如本例中,页面一次可以显示6条数据,如果不提前缓存部分数据,当下滑到列表最底端时,再快速下滑,可能会引起“滑动白块”的现象。这是因为上一次只请求了屏幕上的6条数据,如果滑动速度过快,则会导致数据来不及加载而出现白块。在追求极致性能的同时,应该避免这样糟糕的用户体验。
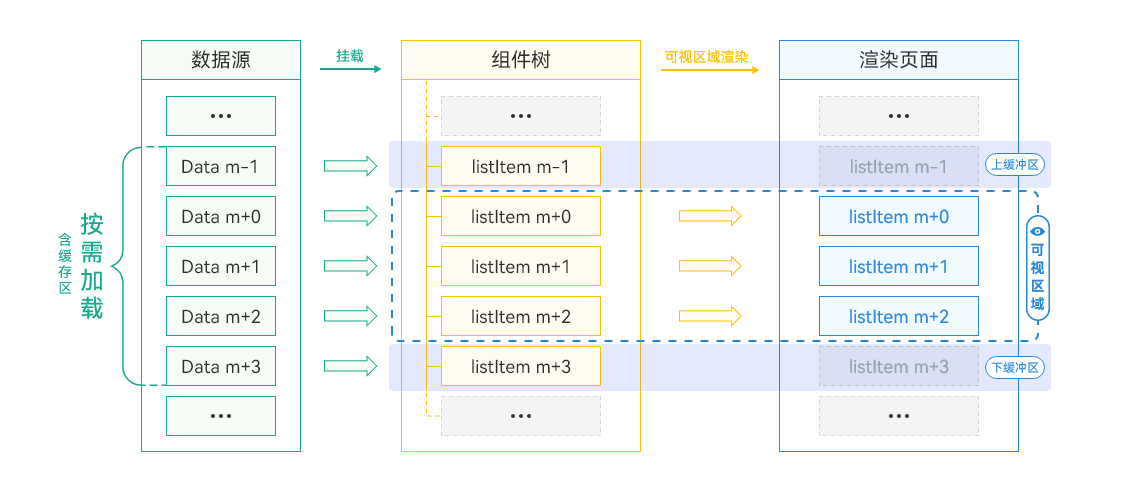
LazyForEach懒加载可以通过设置cachedCount来指定缓存数量,在设置cachedCount后,除屏幕内显示的ListItem组件外,还会预先将屏幕可视区外指定数量的列表项数据缓存。这样当一个屏幕数据加载完成后,再次向下滑动时,会先加载上一次请求的数据,加载完成后,再加载本次请求的数据。LazyForEach添加了cachedCount缓存列表项后,其渲染过程如下:
- 首先,请求n+cachedCount条数据,并在屏幕上显示n条数据。
- 当列表滑动,缓存列表项需要从屏幕可视区外进入可视区内时,此时只用渲染组件即可,相比不设置cachedCount提升了显示效率。
- 当列表不断滑动,屏幕可视区外缓存的列表项数量少于cachedCount设置数量时,会触发列表项数据加载事件,继续预加载下一组缓存列表项(cachedCount个)。
- 当上滑下滑间隔进行时,列表两个方向分别缓存cachedCount条数据。
- 如果不显式设置cachedCount,cachedCount默认为1。
其数据加载、组件树挂载、页面渲染的示意图如下所示:
**图6 **缓存作用区域与渲染过程示意图
使用场景和规则
使用场景
缓存列表项适合加载列表项数据请求比较耗时的场景。比如,滑动列表中含有短视频、高清图片等数据量比较大的资源,可以通过预先从网络加载并缓存相关数据,缩短渲染前的准备时间,提升列表响应速度。
使用规则
使用限制为:缓存列表项仅在使用LazyForEach懒加载时有效,ForEach循环渲染会一次性加载全量数据,故无法也不需要设置缓存列表项。
场景案例
在LazyForEach上添加缓存列表项后的关键代码如下所示:
// entry/src/main/ets/pages/LazyForEachListPage
@Entry
@Component
export struct LazyForEachListPage {
// ...
build() {
Column() {
Header()
List({ space: Constants.SPACE_16 }) {
if (this.data !== null) {
// 使用懒加载
LazyForEach(this.data, (item: LearningResource) => {
ListItem() {
Column({ space: Constants.SPACE_12 }) {
ArticleCardView({
articleItem: item,
isLiked: this.isLiked(item.id),
isCollected: this.isCollected(item.id)
})
}
}
}, (item: LearningResource) => item.id)
}
}
.width(Constants.FULL_SCREEN)
.height(Constants.FULL_SCREEN)
.margin({ left: 10, right: 10 })
.layoutWeight(1)
// 使用cachedCount
.cachedCount(3);
}
.backgroundColor($r('app.color.text_background'))
}
}
性能分析
本文案例中的长列表一屏可以加载6条数据,为了测试不同缓存数量对丢帧率的影响,将cachedCount的值分别设为1、2、3、6、12、18、30个。基于示例程序,测试了不同缓存数量对帧率的影响情况,不设置缓存数量时(默认cachedCount=1),丢帧率为6.6%,当逐渐增加缓存数量时,丢帧率降低。当设置当前屏幕展示数量的一半,即缓存3个列表项时,丢帧率最低为3.7%。再增加缓存数量,丢帧率不再有显著的下降,增加缓存数量太多时,甚至会影响丢帧率。
**图7 **10000条数据量下不同cachedCount对列表滑动帧率的影响
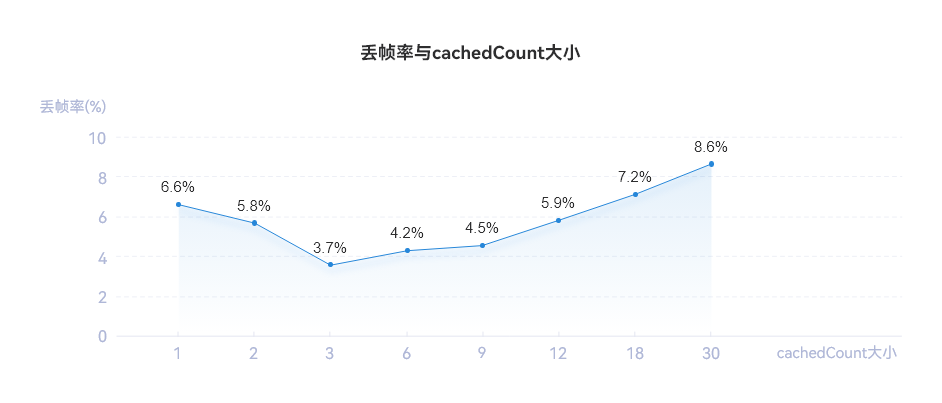
一般而言,缓存的cachedCount=n/2(n为一屏显示的列表数)的时候,效果较好。在实际开发中也要根据实际场景合理去设置缓存数量,例如列表项中需要显示网络数据,而网络数据加载较慢,为了提升列表信息的浏览效率和浏览体验,可以适当的多设置一些缓存数量(cachedCount大于n/2);如果列表中需要加载一些大图或者视频等,这些数据占用的内存较大,为了减少内存占用,需要适当减少缓存数量的设置(cachedCount小于n/2)。因此,在实际场景中,需要不断尝试验证,设置适当的缓存数量,来达到体验和内存的平衡。
说明
测试数据仅限于示例程序,不同的应用程序设置的最佳缓存数量不一致,需要针对应用程序测试得出最佳缓存数量。
动态预加载
原理介绍
从上文了解到LazyForEach懒加载可以通过设置cachedCount来指定缓存数量,解决当下滑到列表最底端时,再快速下滑,可能会引起“滑动白块”的现象。如若用户使用大量在线数据,实际上在弱网以及快速滑动的场景下依旧会在滑动过程中出现白块,如果将cachedCount设置比较大,滑动过程中可能不会出现白块,但是首屏加载时间过长。在追求极致性能的同时,应该避免这样糟糕的用户体验。
HarmonyOS提供了内容预取的能力Prefetcher,支持应用动态自适应网络状态,通过提前下载一些图片或资源,确保相关资源在需要时能立即显示,以尽可能减少白块出现的概率。
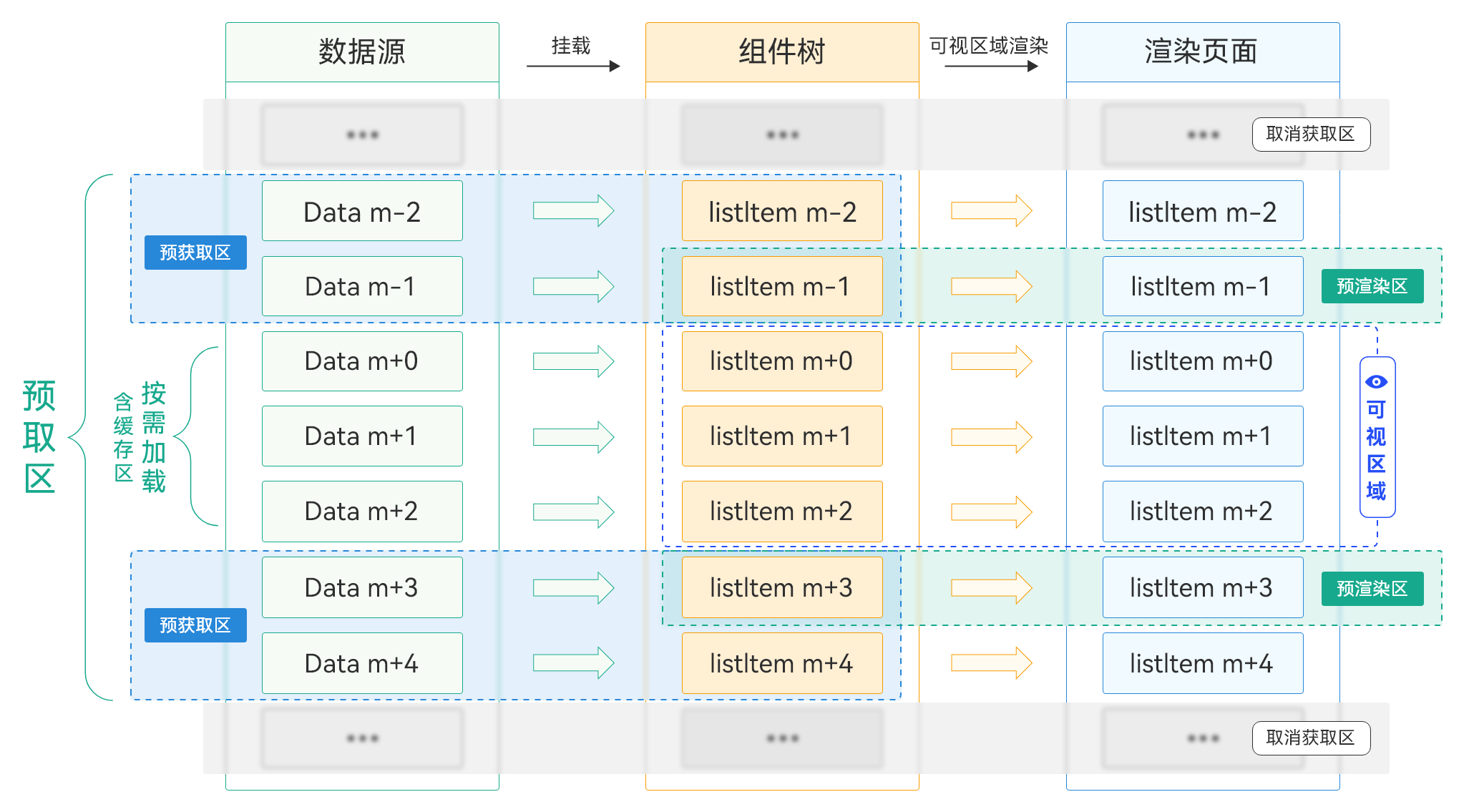
LazyForEach懒加载可以通过使用Prefetcher来预取和预渲染数据。在使用Prefetcher后,除屏幕内显示的ListItem组件外,还会预先将屏幕可视区外的部分列表项数据进行预渲染和预取。这样当列表向下滑动时,会先显示预渲染组件,屏幕可视区外会动态调整预取范围。预取逻辑在Prefetcher的BasicPrefetcher类中实现,BasicPrefetcher支持预取和预渲染(图像解码、添加到组件树等)过程分离、自适应调整预获取范围、优先加载可视区域、以及取消不必要任务(快速滚动列表的场景下,智能取消不必要任务),其渲染过程如下:
- 首先,请求n条数据,并在屏幕上显示m条数据。
- 当列表滑动,缓存列表项需要从屏幕可视区外进入可视区内时,此时显示预渲染组件,屏幕可视区外会动态调整预取范围,相比仅设置cachedCount提升了显示效率。
- 当列表不断滑动,屏幕可视区外实时更新列表项、更新预取数据和预渲染数据。
**图8 **动态预加载渲染过程示意图
使用场景
动态预加载适合加载列表项数据请求比较耗时的场景。比如,滑动列表中含有图片等数据量比较大的资源,在LazyForEach的数据源中使用IDataSourcePrefetching的prefetch提前从网络加载并缓存相关数据,BasicPrefetcher则是在滚动体验和CPU节省方面有明显的提升。从这几个方面来提升应用的响应速度。
场景案例
实现DataSourcePrefetchingRCP类,继承IDataSourcePrefetching接口,并实现prefetch和cancel方法,如下代码所示
import { SongInfoItem } from '../model/LearningResource';
import { HashMap } from '@kit.ArkTS';
import fs from '@ohos.file.fs';
import { IDataSourcePrefetching } from '@kit.ArkUI';
import { rcp } from '@kit.RemoteCommunicationKit';
let PREFETCH_ENABLED: boolean = false;
const CANCEL_CODE: number = 1007900992;
const IMADE_UNAVAILABLE = $r('app.media.startIcon');
export default class DataSourcePrefetching implements IDataSourcePrefetching {
private dataArray: Array<SongInfoItem>;
private listeners: DataChangeListener[] = [];
private readonly requestsInFlight: HashMap<number, rcp.Request> = new HashMap();
private readonly session: rcp.Session = rcp.createSession();
private readonly cachePath = getContext().getApplicationContext().cacheDir;
constructor(dataArray: Array<SongInfoItem>) {
this.dataArray = dataArray;
}
async prefetch(index: number): Promise<void> {
PREFETCH_ENABLED = true;
if (this.requestsInFlight.hasKey(index)) {
throw new Error('Already being prefetched')
}
const item = this.dataArray[index];
if (item.cachedImage) {
return;
}
// 数据请求
const request = new rcp.Request(item.albumUrl, 'GET');
// 缓存网络请求对象,便于在需要取消请求的时候进行处理
this.requestsInFlight.set(index, request);
try {
// 发送http请求获得响应
const response = await this.session.fetch(request);
if (response.statusCode !== 200 || !response.body) {
throw new Error('Bad response');
}
// 将加载的数据信息存储到缓存文件中
item.cachedImage = await this.cache(item.songId, response.body);
// 删除指定元素
this.requestsInFlight.remove(index);
} catch (err) {
if (err.code !== CANCEL_CODE) {
item.cachedImage = IMADE_UNAVAILABLE;
// 移除有异常的网络请求任务
this.requestsInFlight.remove(index);
}
throw err as Error;
}
}
cancel(index: number) {
if (this.requestsInFlight.hasKey(index)) {
// 返回MAP对象指定元素
const request = this.requestsInFlight.get(index);
// 取消数据请求
this.session.cancel(request);
// 移除被取消的网络请求对象
this.requestsInFlight.remove(index);
}
}
// ...
}
在应用列表界面,首先创建DataSourcePrefetchingRCP、BasicPrefetcher对象,然后在List的onScrollIndex回调中调用BasicPrefetcher的visibleAreaChanged方法,传入List的可见区域起始坐标。至此完成代码的优化。
import { SongInfoItem } from '../model/LearningResource';
import DataSourcePrefetching from '../model/ArticleListData';
import { ObservedArray } from '../utils/ObservedArray';
import { ReusableArticleCardView } from '../components/ReusableArticleCardView';
import Constants from '../constants/Constants';
import { util } from '@kit.ArkTS';
import PageViewModel from '../components/PageViewModel';
import { BasicPrefetcher } from '@kit.ArkUI';
@Entry
@Component
export struct LazyForEachListPage {
@State collectedIds: ObservedArray<string> = ['1', '2', '3', '4', '5', '6'];
@State likedIds: ObservedArray<string> = ['1', '2', '3', '4', '5', '6'];
@State isListReachEnd: boolean = false;
// 创建DataSourcePrefetching对象,具备任务预取、取消能力的数据源
private readonly dataSource = new DataSourcePrefetching(PageViewModel.getItems());
// 创建BasicPrefetcher对象,默认的动态预取算法实现
private readonly prefetcher = new BasicPrefetcher(this.dataSource);
build() {
Column() {
Header()
List({ space: Constants.SPACE_16 }) {
LazyForEach(this.dataSource, (item: SongInfoItem) => {
ListItem() {
Column({ space: Constants.SPACE_12 }) {
ReusableArticleCardView({ articleItem: item })
}
}
.reuseId('article')
})
}
.cachedCount(5)
.onScrollIndex((start: number, end: number) => {
// 列表滚动触发visibleAreaChanged,实时更新预取范围,触发调用prefetch、cancel接口
this.prefetcher.visibleAreaChanged(start, end)
})
.width(Constants.FULL_SCREEN)
.height(Constants.FULL_SCREEN)
.margin({ left: 10, right: 10 })
.layoutWeight(1)
}
.backgroundColor($r('app.color.text_background'))
}
}
性能分析
本文案例中的长列表一屏可以加载6条数据,为了测试动态预加载方案与设置不同的cachedCount对应用性能的影响。来测试快速滑动场景下出现的白块数量、CPU开销占比以及首屏加载时长。如下对比场景设置数据cachedCount=5、cachedCount=40。最终,使用IDE的Profiler工具检测下述指标,得到的数据如下所示:
1.场景滑动对比
cachedCount=5
cachedCount=40
动态预加载



数据设置
首屏加载
滑动过程滑块数量
cachedCount=5
首屏加载快
滑动过程中白块很多
cachedCount=40
首屏加载慢
滑动过程中没有白块或很少
动态预加载
首屏加载快
滑动过程中没有白块或很少
2. CPU开销对比
利用Profiler工具分析得到相关trace图,追踪流程为应用侧的APP_LIST_FLING(列表从开始滚动到结束)的整个过程,从而观察应用的CPU占比。(注:不同设备特性和具体应用场景的多样性,所获得的性能数据存在差异,提供的数值仅供参考)
**图9 **cachedCount=5 CPU占比trace图
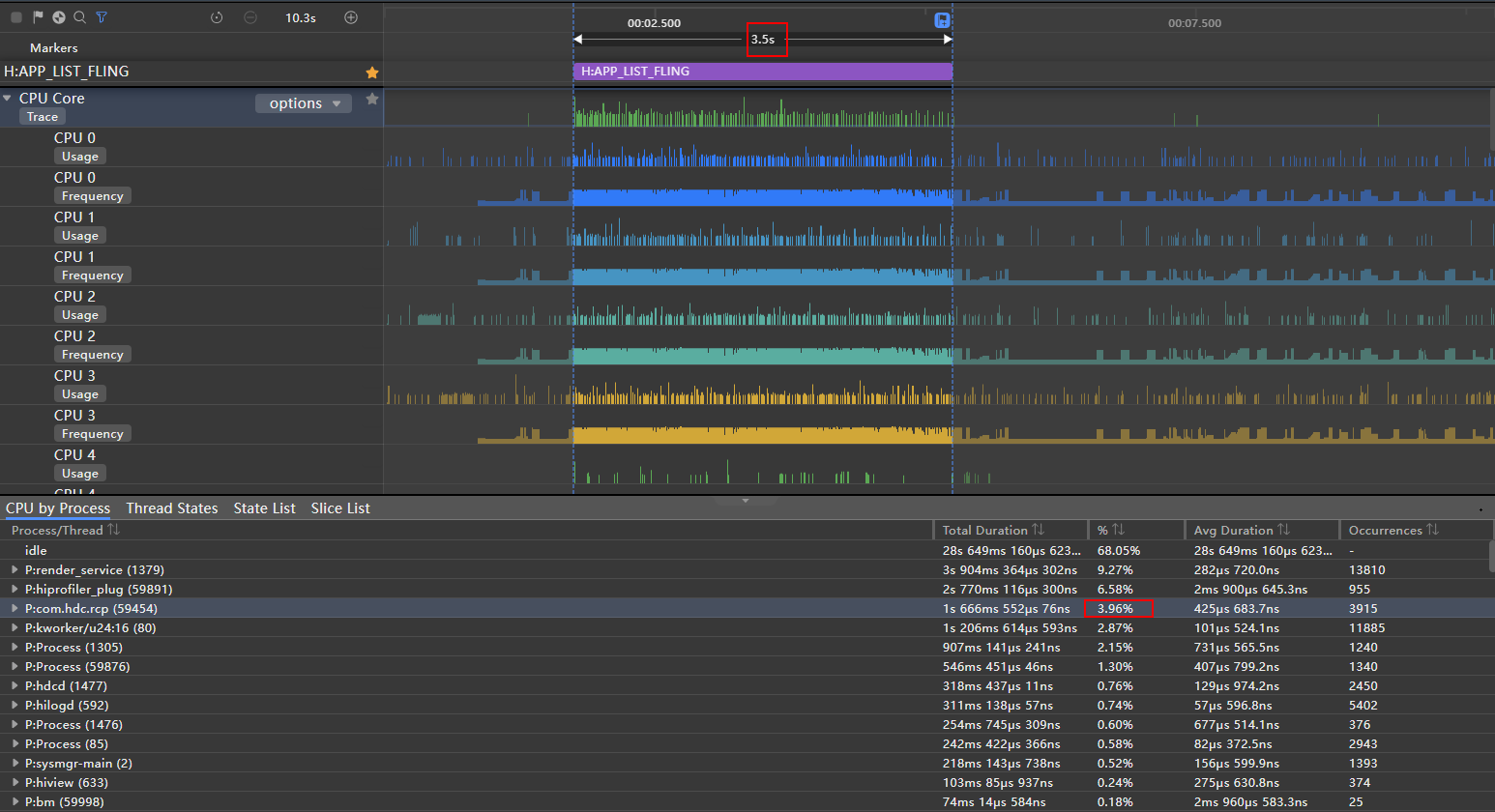
cachedCount=5 CPU占比为3.96%
**图10 **cachedCount=40 CPU占比trace图
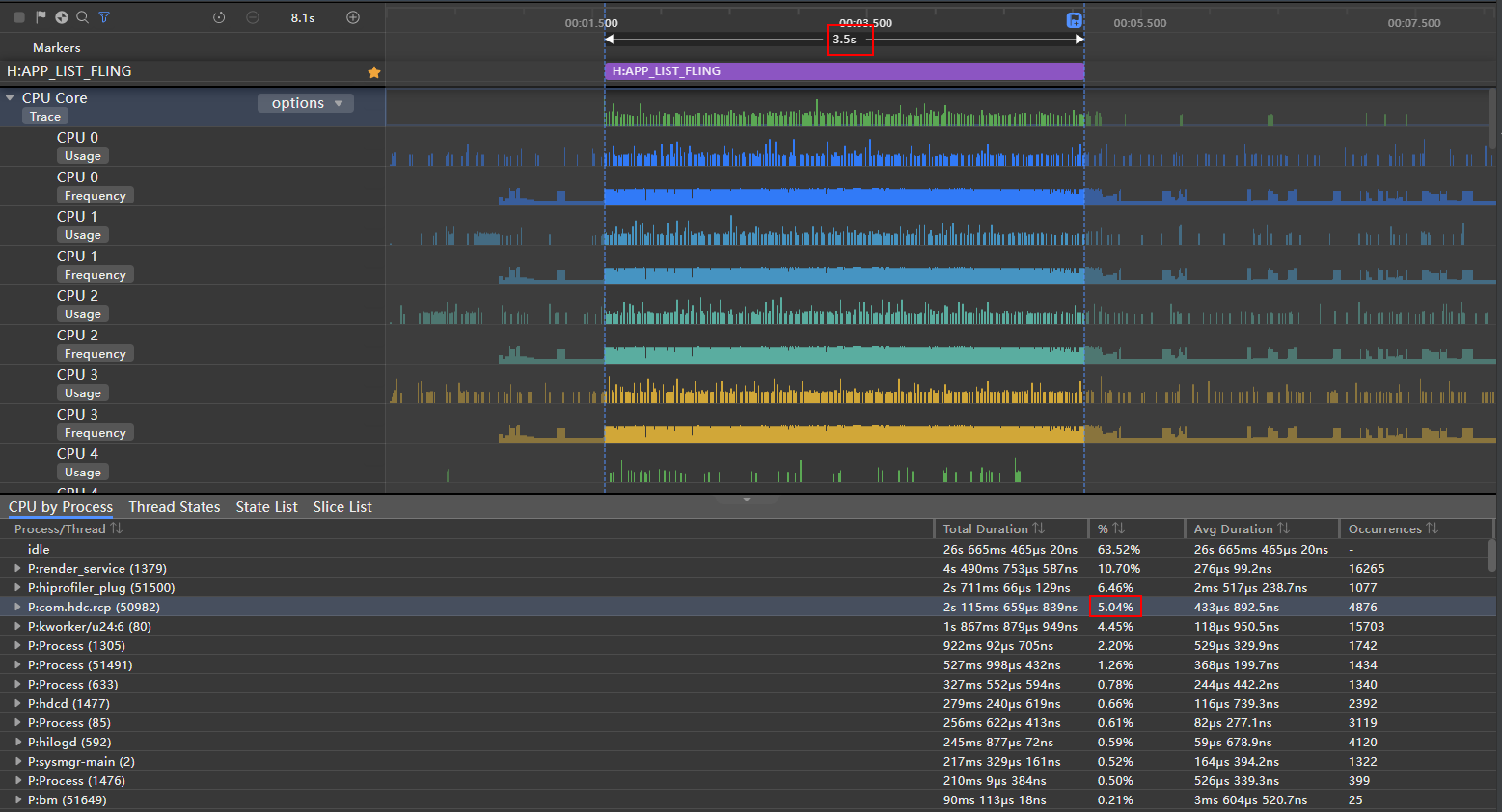
cachedCount=40 CPU占比为5.04%
**图11 **动态预加载 CPU占比trace图
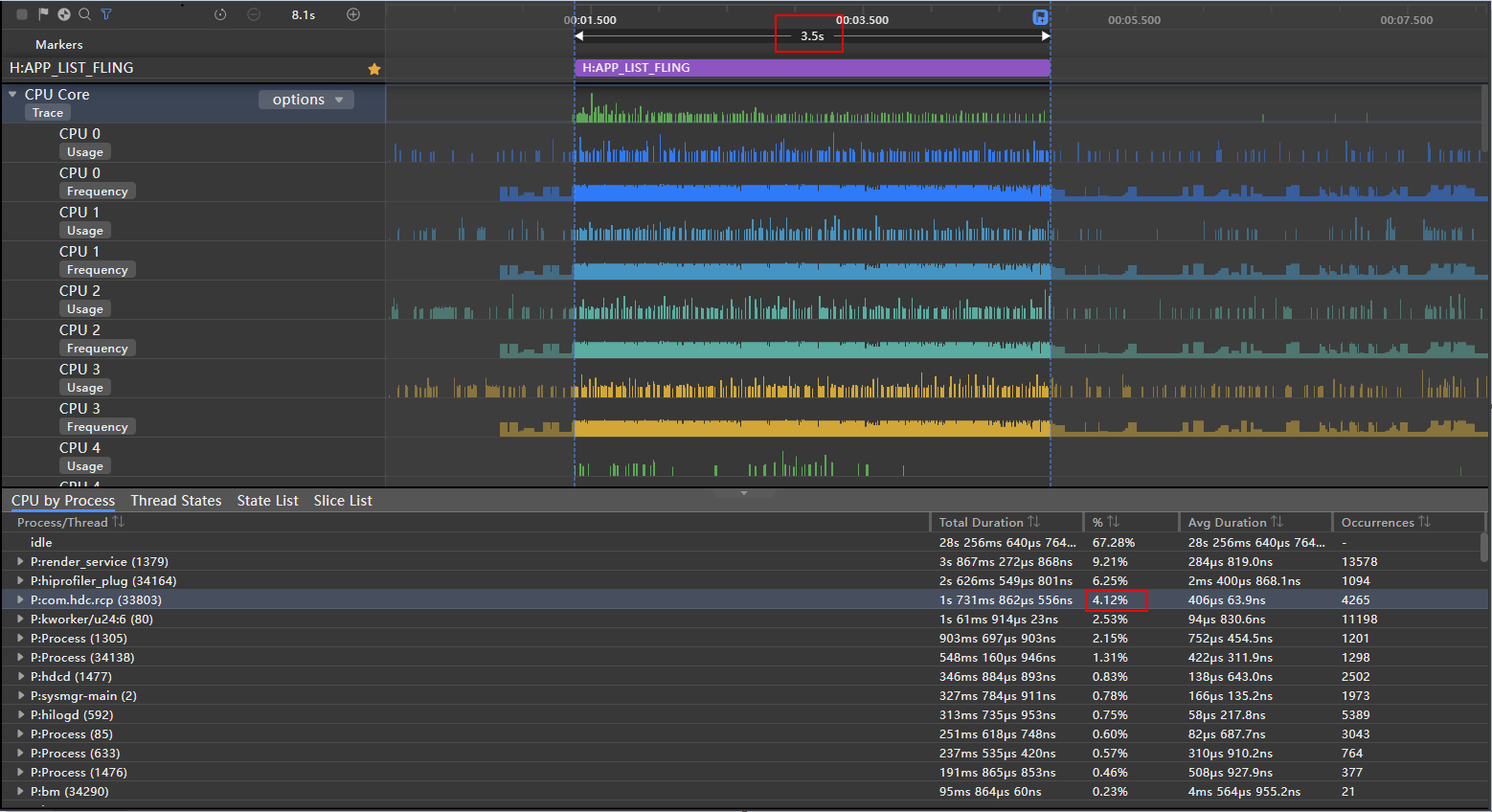
动态预加载CPU占比为4.12%
数据设置
CPU占比
cachedCount=5
3.96%
cachedCount=40
5.04%
动态预加载
4.12%
3. 首屏加载时长对比
利用Profiler工具分析得到相关trace图,追踪流程从Create Process(应用进程创建阶段)标签开始,到首屏全部图片加载完毕结束,从而观察应用的首屏加载时长。(注:不同设备特性和具体应用场景的多样性,所获得的性能数据存在差异,提供的数值仅供参考)
**图12 **cachedCount=5 首屏加载时长trace图
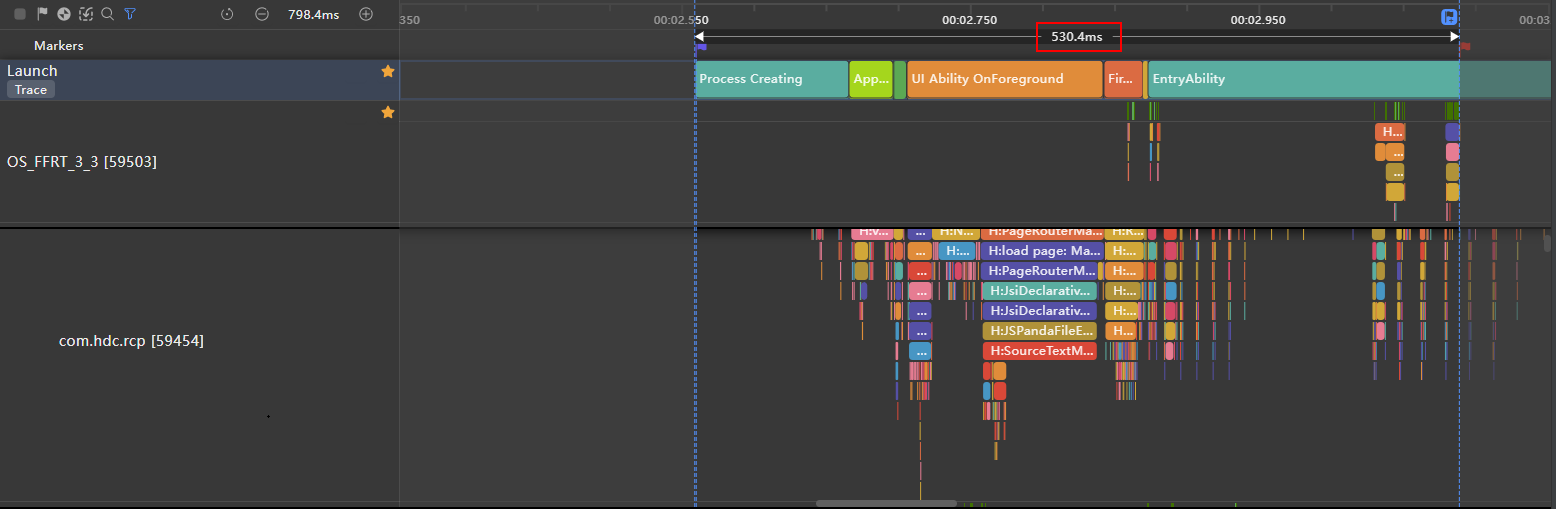
cachedCount=5 首屏加载时长为530.4ms
**图13 **cachedCount=40 首屏加载时长trace图
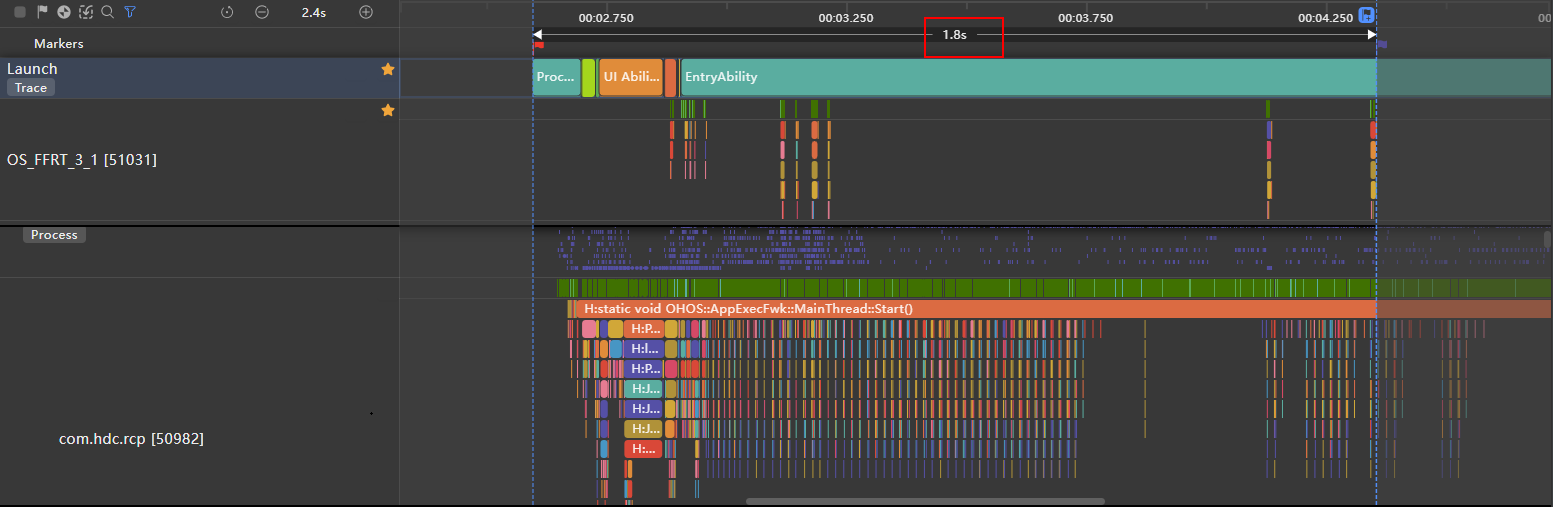
cachedCount=40 首屏加载时长为1.8s
**图14 **动态预加载 首屏加载时长trace图
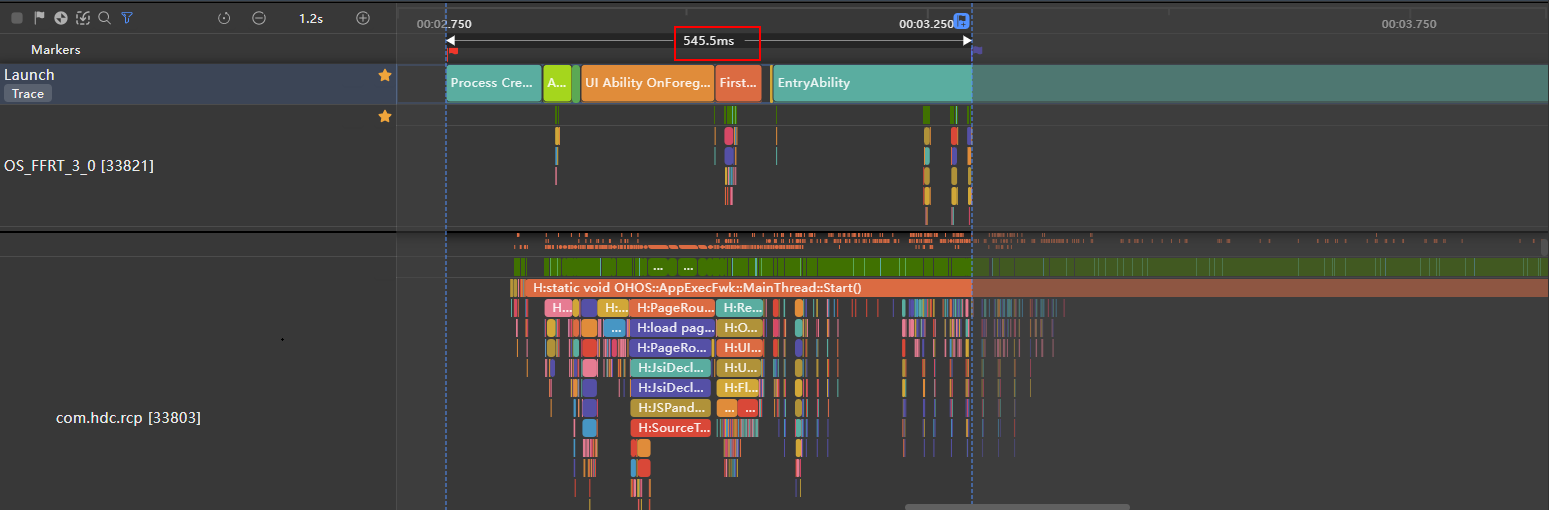
动态预加载首屏加载时长为545.5ms
数据设置
首屏加载时长
cachedCount=5
530.4ms
cachedCount=40
1.8s
动态预加载
545.5ms
从实验数据可以看出:
1)当cachedCount=5时,首屏加载时间短,滑动过程中出现大量白块,滑动时CPU占比较小。
2)当cachedCount=40时,首屏加载时间过长,滑动过程中并未出现白块,滑动时CPU占比较大。
3)当在cachedCount=5时的基础上设置动态预加载时,首屏加载时间短,滑动过程中并未出现白块,滑动时CPU占比较小。
因此当用户使用LazyForEach在线加载含有图片等数据量比较大的资源时,可以考虑使用动态预加载来预防弱网以及快速滑动场景中出现的白块问题。
说明
测试数据仅限于示例程序,不同设备特性和具体应用场景的多样性,所获得的性能数据存在差异,提供的数值仅供参考。
组件复用
原理介绍
HarmonyOS应用框架提供了组件复用能力,可复用组件从组件树上移除时,会进入到一个回收缓存区。后续创建新组件节点时,会复用缓存区中的节点,节约组件重新创建的时间。尤其在列表等场景下,其自定义子组件具有相同的组件布局结构,列表更新时仅有状态变量等数据差异。通过组件复用可以提高列表页面的加载速度和响应速度。
组件复用机制如下:
- 标记为@Reusable的组件从组件树上被移除时,组件和其对应的JSView对象都会被放入复用缓存中。
- 当列表滑动新的ListItem将要被显示,List组件树上需要新建节点时,将会从复用缓存中查找可复用的组件节点。
- 找到可复用节点并对其进行更新后添加到组件树中。从而节省了组件节点和JSView对象的创建时间。
**图15 **组件复用原理图
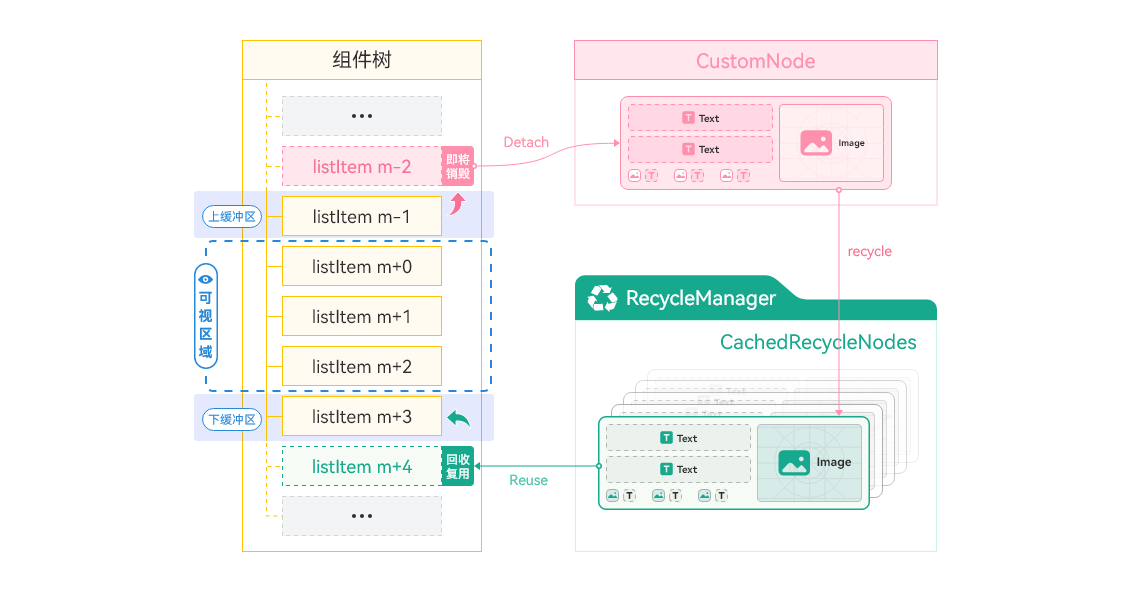
组件复用生效的条件是:
- 自定义组件被@Reusable装饰器修饰,即表示其具备组件复用的能力;
- 在一个自定义父组件下创建出来的具备组件复用能力的自定义子组件,在可复用自定义组件从组件树上移除之后,会被加入到其自定义父组件的可复用节点缓存中;
- 在一个自定义父组件下创建可复用的子组件时,若其父自定义组件的可复用节点缓存中有对应类型的可复用子组件,会通过更新可复用子组件的方式,快速创建可复用子组件;
- ForEach循环渲染会一次性加载全量数据,因此不支持组件复用。
说明
名词介绍:
- @Reusable表示组件可以被复用,结合LazyForEach懒加载一起使用,可以进一步解决列表滑动场景的瓶颈问题,提供滑动场景下高性能创建组件的方式来提升滑动帧率。
- CustomNode是一种自定义的虚拟节点,它可以用来缓存列表中的某些内容,以提高性能和减少不必要的渲染。通过使用CustomNode,可以实现只渲染当前可见区域内的数据项,将未显示的数据项缓存起来,从而减少渲染的数量,提高性能。
- RecycleManager是一种用于优化资源利用的回收管理器。当一个数据项滚出屏幕时,不会立即销毁对应的视图对象,而是将该视图对象放入复用池中。当新的数据项需要在屏幕上展示时,RecycleManager会从复用池中取出一个已经存在的视图对象,并将新的数据绑定到该视图上,从而避免频繁的创建和销毁过程。通过使用RecycleManager,可以大大减少创建和销毁视图的次数,提高列表的滚动流畅度和性能表现。
- CachedRecycleNodes是CustomNode的一个集合,常是用于存储被回收的CustomNode对象,以便在需要时进行复用。
使用场景和规则
使用场景
若业务实现中存在以下场景,并成为UI线程的帧率瓶颈,推荐使用组件复用:
- 列表滚动(本例中的场景):当应用需要展示大量数据的列表,并且用户进行滚动操作时,频繁创建和销毁列表项的视图可能导致卡顿和性能问题。在这种情况下,使用列表组件的组件复用机制可以重用已经创建的列表项视图,提高滚动的流畅度。
- 动态布局更新:如果应用中的界面需要频繁地进行布局更新,例如根据用户的操作或数据变化动态改变视图结构和样式,重复创建和销毁视图可能导致频繁的布局计算,影响帧率。在这种情况下,使用组件复用可以避免不必要的视图创建和布局计算,提高性能。
- 地图渲染:在地图渲染这种场景下,频繁创建和销毁数据项的视图可能导致性能问题。使用组件复用可以重用已创建的视图,只更新数据的内容,减少视图的创建和销毁,能有效提高性能。
以上场景中,为了避免UI线程的帧率瓶颈问题,推荐使用组件复用来提高应用的性能和用户体验。组件复用可以避免不必要的视图创建和销毁,减少布局计算和绘制操作,从而提高界面的流畅度和响应速度。
使用规则
组件复用的使用规则如下:
- 使用 @Reusable标识:@Reusable标识自定义组件具备可复用的能力,它可以被添加到任意的自定义组件上,但是开发者需要小心处理自定义组件的创建流程和更新流程以确保自定义组件在复用之后能展示出正确的行为;
- 缓存和复用范围:可复用自定义组件的缓存和复用只能发生在同一父组件下,无法在不同的父组件下复用同一自定义节点的实例。e.g. A组件是可复用组件,其也是B组件的子组件,并进入了B组件的可复用节点缓存中,但是在C组件中创建A组件时,无法使用B组件缓存的A组件;
- 组件结构无显著变化:自定义组件的复用带来的性能提升主要体现在节省了自定义组件的JS对象的创建时间并复用了自定义组件的组件树结构,若应用开发者在自定义组件复用的前后使用渲染控制语法显著的改变了自定义组件的组件树结构,那么将无法享受到组件复用带来的性能提升;
- 仅在特定场景触发:组件复用仅发生在存在可复用组件从组件树上移除并再次加入到组件树的场景中,若不存在上述场景,将无法触发组件复用。e.g. 使用ForEach渲染控制语法创建可复用的自定义组件,由于ForEach渲染控制语法的全展开属性,不能触发组件复用。
组件复用可以节省创建时间和复用组件树结构,提高应用性能。开发者需要注意处理自定义组件的创建和更新流程,以及限制复用范围和特定触发场景,才能实现组件复用的效果。
场景案例
下面的代码片段是在缓存列表项的基础上增加的组件复用的相关代码,组件复用需要首先在复用的组件上添加@Reusable注解,然后实现aboutToReuse方法,关键代码如下:
@Component
@Reusable
export struct ReusableArticleCardView {
@Prop articleItem: LearningResource = new LearningResource();
@Prop isCollected: boolean = false;
@Prop isLiked: boolean = false;
onCollected?: () => void;
onLiked?: () => void;
aboutToReuse(params: Record<string, Object>): void {
this.onCollected = params.onCollected as () => void;
this.onLiked = params.onLiked as () => void;
}
build() {
// ...
}
}
说明
无需对@Prop修饰的变量进行赋值,因为这些变量是由父组件传递给子组件的。如果在子组件中重新赋值这些变量,会导致重用的组件的内容重新触发状态刷新,从而降低组件的复用性能。相反,只需要在aboutToReuse方法中对onCollected和onLiked这两个函数进行重新赋值即可。
最后,还需要去设置可复用组件的reuseId,关键代码如下所示:
// entry/src/main/ets/pages/LazyForEachListPage
@Entry
@Component
export struct LazyForEachListPage {
// ...
build() {
Column() {
Header()
List({ space: Constants.SPACE_16 }) {
if (this.data !== null) {
// 使用懒加载
LazyForEach(this.data, (item: LearningResource) => {
ListItem() {
Column({ space: Constants.SPACE_12 }) {
// 使用组件复用
ReusableArticleCardView({
articleItem: item,
isLiked: this.isLiked(item.id),
isCollected: this.isCollected(item.id)
})
}
}
// 如果只有一个复用的组件,可以不用设置reuseId
.reuseId('article')
}, (item: LearningResource) => item.id)
}
}
.width(Constants.FULL_SCREEN)
.height(Constants.FULL_SCREEN)
.margin({ left: 10, right: 10 })
.layoutWeight(1)
// 使用cachedCount
.cachedCount(3);
}
.backgroundColor($r('app.color.text_background'))
}
}
说明
需要注意的是复用组件中有@Builder自定义构建函数时,状态变量推荐使用按引用传递。@Builder装饰的函数默认按值传递,当传递的参数为状态变量时,状态变量的改变不会引起@Builder方法内的UI刷新。
性能分析
组件未复用时
上文已经将ForEach改造为了LazyForEach,并且添加了缓存项(cachedCount=3),当匀速滑动这个列表时,每隔若干帧时会稳定的丢帧,且会规律、重复的出现这个问题,如下图所示:
**图16 **未进行组件复用(均匀丢帧)

从图中可以看见,泳道中红色和绿色间隔出现,其中红色区域表示丢帧,绿色表示正常,对红色丢帧区域进行耗时分析:
**图17 **丢帧耗时分析
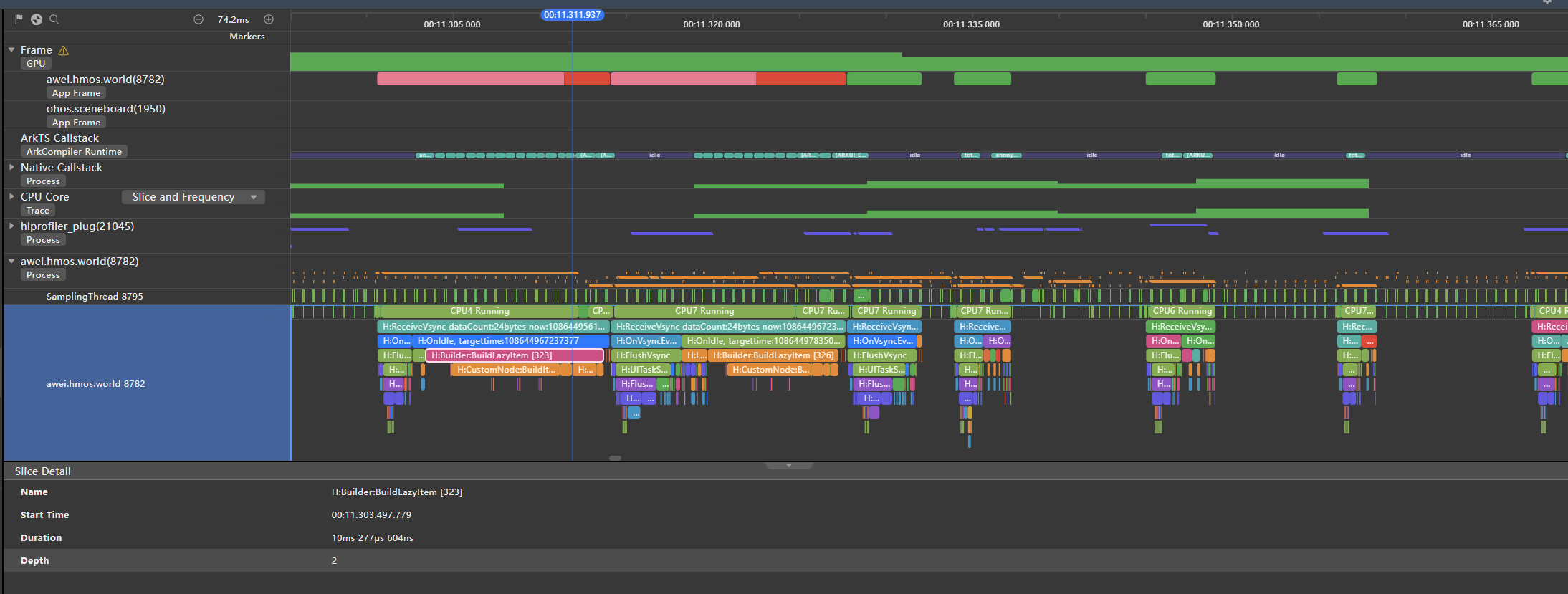
**图18 **对丢帧部分的放大分析(整体耗时13.430ms)
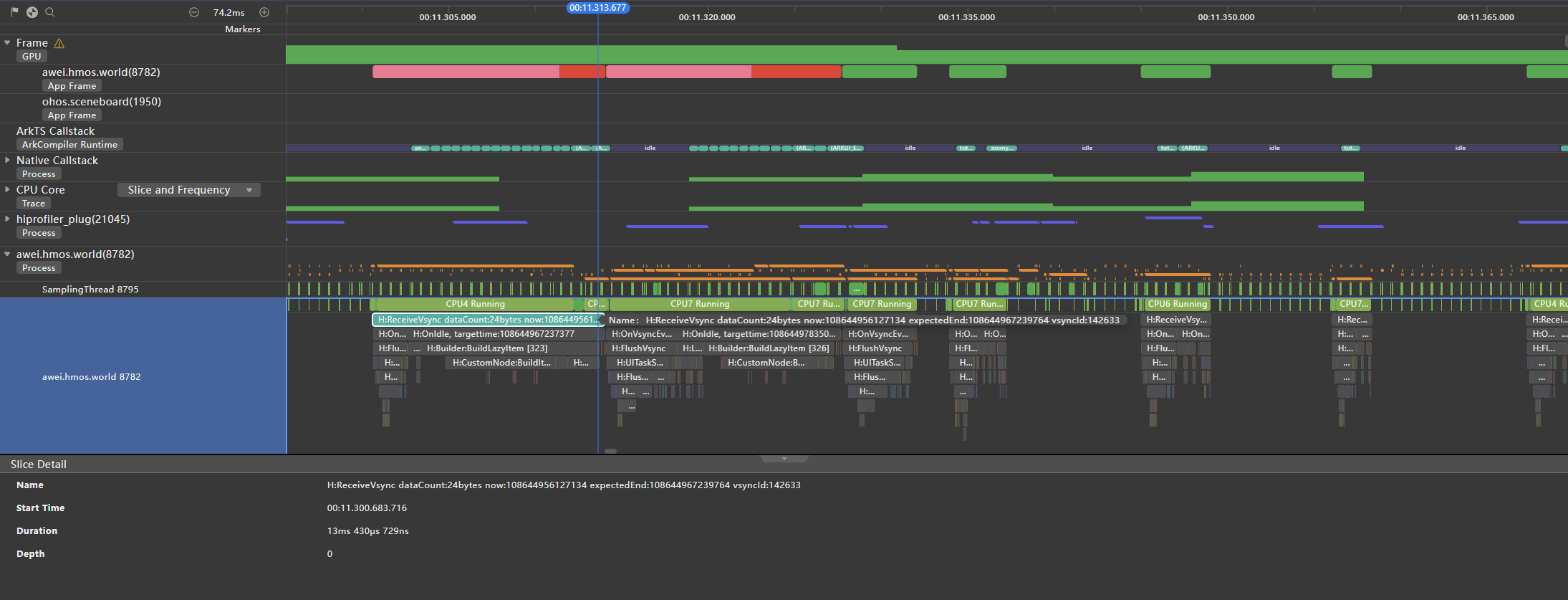
图中红色区域出现了丢帧,这是因为缓存区中的最上面的一个ListItem渲染到页面上时,会执行BuildLazyItem操作,此部分会耗时10.277ms,导致本帧总体耗时达到了13.430ms,超过了11.1ms而丢帧。
组件复用后
将代码进行改造,对复用组件ArticleCardView添加@Reusable注解,启用组件复用的相关代码后,以相同均匀速度滑动这个列表,得到的应用帧率检测情况如下:
**图19 **组件复用后(无丢帧)

上图中列表快速滑动了15.8s,泳道中全是绿色表示无丢帧出现,丢帧率为0%。对其中某一帧放大分析,得到如下图:
**图20 **组件复用后某帧耗时分析
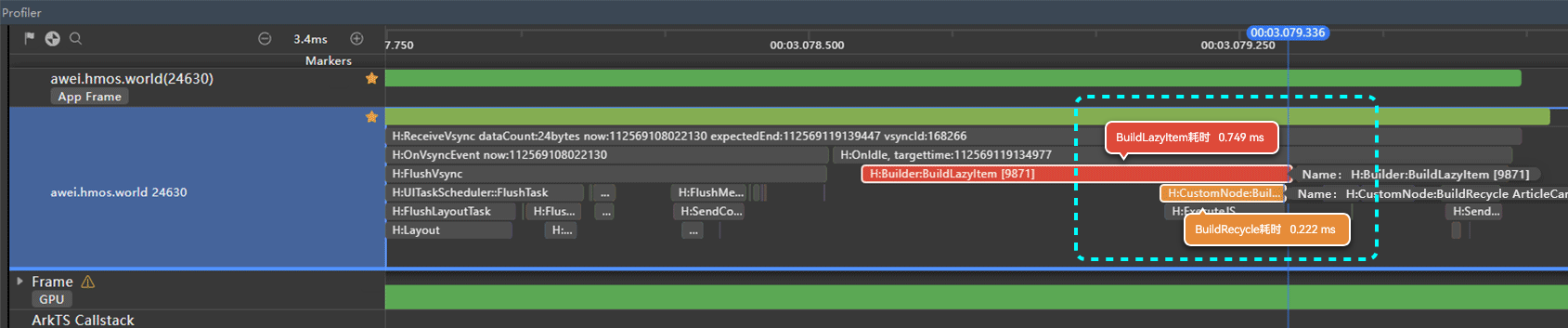
此部分的BuildLazyItem只耗时0.749ms,远远低于之前未进行复用的10.277ms,对复用前后的耗时进行分析,得到的数据如下表所示:
**表4 **组件复用前后丢帧率和耗时分析
组件复用
组件复用前
组件复用后
丢帧率
3.7%
0%
BuildLazyItem耗时
10.277ms
0.749ms
BuildRecycle耗时
不涉及
0.221ms
总耗时
13.430ms
7.310ms
可以发现之前的丢帧情况得到明显缓解,从图19可以看出,列表滑动时(15.8s的区间段内)都是绿色,丢帧率为0%,不会出现图16中“有规律、且重复”的红色丢帧情况。这是因为,List列表开启了组件复用,不会执行BuildLazyItem这个耗时操作(耗时10.277ms),后续创建新组件节点时,会直接复用缓存区中的节点(耗时0.97ms),这样就大幅节约了组件重新创建的时间。
说明
以上数据来源均为版本DevEco Studio 4.0.3.415、SDK 4.0.10.9条件下测试得到,不同设备类型数据可能存在差异,测试数据旨在体现性能优化趋势,仅供参考。
布局优化
原理介绍
列表不同于其他布局,包含了大量重复循环的ListItem,所以对每一个ListItem的布局优化格外重要。错误的布局方式可能会导致组件树和嵌套层数过多,在创建和布局绘制阶段产生较大的性能开销,导致界面卡顿。合理使用布局,减少嵌套层数,能提高布局效率。
针对“HMOS世界” 中首屏的长列表,可以对ListItem进行布局优化,把线性布局修改为相对布局,就可以将最大嵌套层级从5层降低到2层。当进行列表循环渲染的时候,特别是当数据量大时,就能对页面性能产生一定的优化。当然这个例子还过于简单,优化空间是有限的;但是当列表元素较为复杂时,通过减少布局嵌套层级,减少过度绘制可以产生较大的性能收益。
**图21 **布局优化前后的层级变化

场景案例
为了对比布局嵌套层级对List列表滑动性能的影响,对相关代码进行了改造,原始代码是线性布局,最大嵌套层级为5层;通过相对布局对代码进行优化,使得其最大嵌套层级为2层;同时,刻意将布局进行过度嵌套,使得其最大嵌套层级为25层。案例的示例代码如下所示:
- 对比案例1:线性布局,最大嵌套层级为5层
@Componentexport struct ArticleCardView { build() { Row() { // 线性布局,第1层 Column() { // 线性布局,第2层 Column() { Text() Text() } Row() { // 线性布局,第3层 Row(){ // 线性布局,第4层 Image() // 线性布局,第5层 Text() } Row(){ Image() Text() } Row(){ Image() Text() } } } Image() } }} - 对比案例2:相对布局,最大嵌套层级为2层
@Componentstruct ArticleCardView { build() { RelativeContainer() { // 相对布局,第1层 Text()// ... Text()// ... Image()// ... Text()// ... // 相对布局,第2层 Image()// ... Text()// ... Image()// ... Text()// ... Image()// ... } }} - 对比案例3:刻意嵌套20层,最大嵌套层级为25层
@Componentstruct ArticleCardView { build() { Column() { Column() { Column() { // ... // 刻意嵌套,最大嵌套层级为25层 }.width("100%") }.width("100%") }.width("100%") }}
性能分析
本文案例中刻意将布局进行嵌套,分析正常情况和过度嵌套情况下应用独占内存、页面滑动帧率、丢帧率的情况对比,开发者可以使用IDE中ArkUI Inspector查看页面的嵌套层级,如下所示:
**图22 **额外嵌套后的布局层级
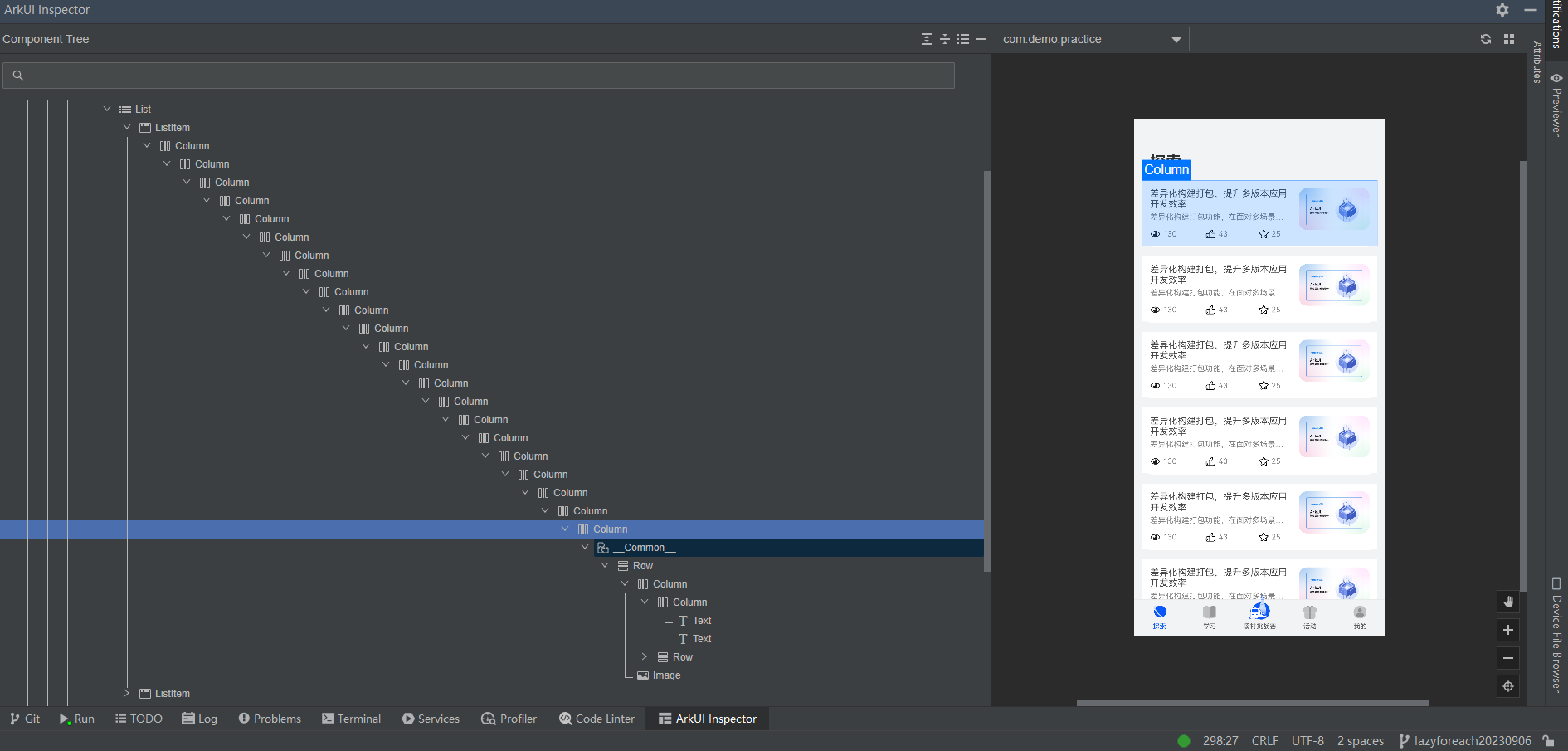
快速滑动10000条数据后,得到了布局嵌套层级对列表性能影响对比,如下所示:
**表5 **布局嵌套对应用性能的影响分析
布局
相对布局(2层)
线性布局(5层)
额外嵌套的线性布局(25层)
独占内存
78.4MB
80.1MB
153.7MB
丢帧率
0%
0%
2.3%
可以看出,因为布局过度嵌套会导致应用内存增加,且会影响应用的帧率导致丢帧增加,所以开发者在写列表这类循环组件的代码时,需要特别考虑对其布局进行优化。一般而言布局的最大嵌套层级控制在5-8层左右即可,过度的优化布局会导致代码开发难度加大,代码不易于阅读理解,增加后续的维护成本,不利于多设备的适配,且也不会带来特别显著的性能提升。
总结与回顾
针对长列表这一场景,在本地模拟了10、100、1000、10000条数据,分别使用ForEach、LazyForEach,测试关闭和开启懒加载的完全显示所用时间、丢帧率、应用独占内存等各项指标。测试表明,使用LazyForEach懒加载这项技术后,相比ForEach这种加载方式,在列表数据量较小(100条内)且数据一次性全量加载不是性能瓶颈时,两者各项性能指标差异不大。但当列表数据较长特别是达到10000条数据量后,ForEach的上述4项性能指标会有“指数级别”的显著劣化,滑动会出现明显的卡顿,甚至会出现应用crash等现象;而LazyForEach因为采用了懒加载技术能明显减少首屏完全显示所用时间,降低应用的独占内存,提高页面滑动帧率,带来更好的性能。在10000条数据量下,其各项对比指标数据如下所示:
**表6 **10000条数据量性能优化对比(因动态预加载使用的是网络数据,所以不参与该表格的比较)
性能指标
ForEach
LazyForEach
缓存列表项
组件复用后
布局优化后
完全显示所用时间
5s 841ms
1s 707ms
1s 658ms
1s 564ms
1s 339ms
丢帧率
58.2%
6.6%
3.7%
0.0%
0.0%
独占内存
560.1MB
82.9MB
81.7MB
80.1MB
78.4MB
另外测试还表明,在使用LazyForEach时,合理添加缓存列表项,能带来列表滑动帧率的提升(提升2.9%),减少“滑动白块”的出现;使用组件复用这项技术后,因省去了组件频繁创建这一耗时操作,故能明显减少“有规律、且重复”的丢帧现象,提高列表页面的加载速度和响应速度,丢帧率会降低3.7%。测试还证明了对页面进行布局优化在大数据量下能对页面性能产生一定的优化。
需要指出的是,ForEach、LazyForEach、缓存列表项、组件复用、布局优化是在本地模拟的10000条数据,是在同等情况下,采用控制变量的方法对ForEach和LazyForEach进行压力测试而得出的数据结论。动态预加载则是模拟在弱网以及快速滑动的状态下加载数据测试而得出的数据结论。当利用网络数据来探讨LazyForEach代码如何进行网络数据的加载和优化时,可以使用动态预加载,使用动态预加载这项技术后,因将预取和预渲染分离且在滑动过程中实时更新列表项、预取数据和预渲染数据,故能在弱网和快速滑动场景中明显减少滑动过程中出现的白块现象。
说明
以上数据来源均为版本DevEco Studio 4.0.3.415、SDK 4.0.10.9条件下测试得到,不同设备类型数据可能存在差异,测试数据旨在体现性能优化趋势,仅供参考。

版权归原作者 取什么名字好呢~ 所有, 如有侵权,请联系我们删除。